
从零开始行人重识别学习笔记
原文:从零开始行人重识别(本文在原文的基础上增加了一些操作步骤截图、代码注释等等一些自己做的笔记补充,由于本人是新手,第一次接触reid和pytorch,有错误谢谢指出)准备步骤:Anaconda、pytorch和torchvision安装下载数据集和本次实践的代码:Code:Practical-Bas...
原文:从零开始行人重识别
(本文在原文的基础上增加了一些操作步骤截图、代码注释等等一些自己做的笔记补充,由于本人是新手,第一次接触reid和pytorch,有错误谢谢指出)
准备步骤:Anaconda、pytorch和torchvision安装
下载数据集和本次实践的代码:
Code: Practical-Baseline Data: Market-1501
目录
Part 1: 训练 ——将一批数据输入网络模型,得到模型最终的参数权重
Part 1.1: 准备数据集 (python prepare.py)
Part 1.2: Build Neural Network (model.py)
Part 1.3: 训练 (python train.py)
Part 2: 测试 ——将另一批数据输入训练好的网络模型,根据输出特征求距离对图片间的相似度排序,并求rank和mAP
Part 2.1: 特征提取 (python test.py)
Part 3: 一个简单的可视化程序 (python demo.py)
Part 1: 训练
Part 1.1: 准备数据集 (python prepare.py)
打开刚刚下载的代码prepare.py。 将第五行的地址改为你本地的地址。
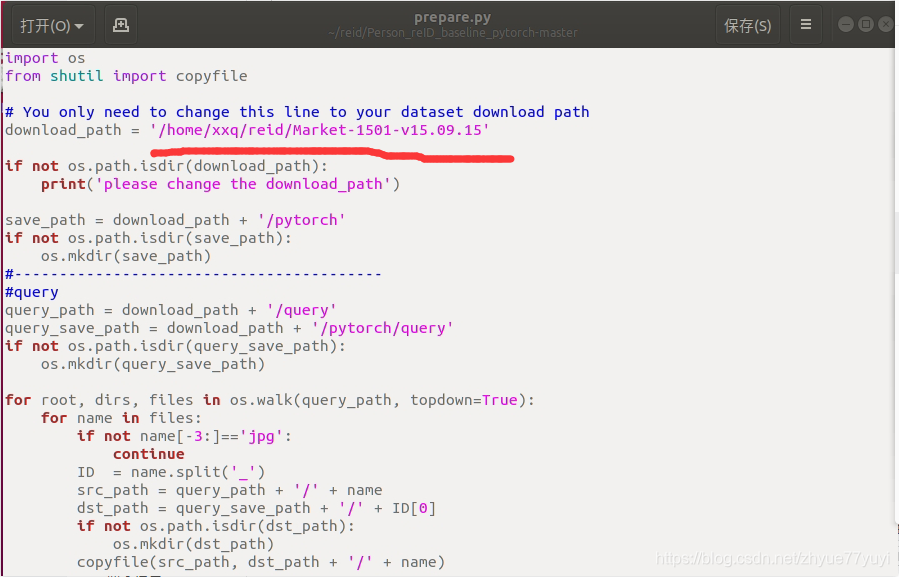
运行或者执行以下命令:
python prepare.py
数据集里会多一个文件夹pytorch,在pytorch的每个子文件夹中,图像都是按ID来排列的。
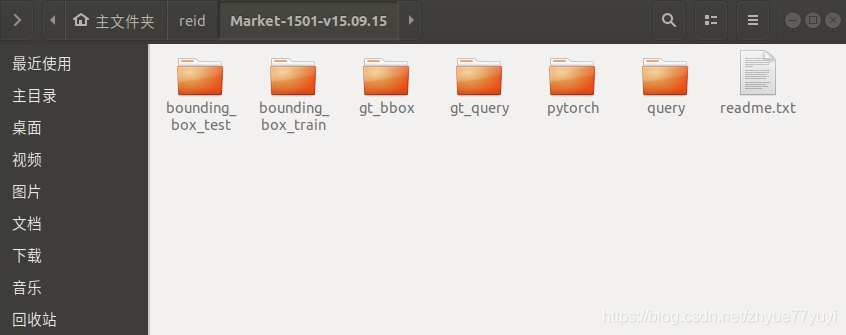
现在我们已经成功准备好了图像来做后面的训练了。
- 快速问答:prepare.py 是如何识别同ID的图像?
+ Quick Question. How to recognize the images of the same ID?【解答】数据集Market-1501, DukeMTMC-reID, VeRi-776 和 CUHK03-NP等等都在文件名中插入了ID名。正如准备中所示,在这里,我们使用DukeMTMC-relD数据集的命名规则作为一个例子。 对于图片"0005_c2_f0046985.jpg", "0005"表示人的身份,“c2”表示Camera 2的图像,“f0046985”是Camera 2视频中的46985帧。
即对于Market1501这个数据集而言,图像的文件名中就包含了 ID label 和 CameraID, 具体命名可在这个链接看到here.
Part 1.2: Build Neural Network (model.py)
在pytorch里,我们可以通过两行代码来引入预训练模型resnet50。
from torchvision import models
model = models.resnet50(pretrained=True)你可以使用下面这行代码来简单检查网络结构
print(model)但在实际使用中,我们需要修改网络。因为Market1501中有751个种类(不同的人)。 而不是像ImageNet一样有1000类。所以我们需要改变我们的模型来训练我们的分类器。
import torch
import torch.nn as nn
from torchvision import models
# Define the ResNet50-based Model
class ft_net(nn.Module): # torch.nn是专门为神经网络设计的模块化接口。nn.Module是nn中十分重要的类,包含网络各层的定义及forward方法。
# 定义自己的网络需要需要继承nn.Module类,并实现forward方法。
def __init__(self, class_num = 751):
# nn.Module的子类函数必须在构造函数中执行父类的构造函数
super(ft_net, self).__init__() # 等价与nn.Module.__init__()
#load the model
model_ft = models.resnet50(pretrained=True) # pretrained=True表示既需要网络结构,也需要用预训练模型的参数来初始化,若不需要参数则改为False
# change avg pooling to global pooling
model_ft.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.model = model_ft
self.classifier = ClassBlock(2048, class_num) #define our classifier.
def forward(self, x):
x = self.model.conv1(x)
x = self.model.bn1(x)
x = self.model.relu(x)
x = self.model.maxpool(x)
x = self.model.layer1(x)
x = self.model.layer2(x)
x = self.model.layer3(x)
x = self.model.layer4(x)
x = self.model.avgpool(x)
x = torch.squeeze(x) # 对数据的维度进行压缩,去掉维数为1的的维度
x = self.classifier(x) #use our classifier.
return x
+ Quick Question. Why we use AdaptiveAvgPool2d? What is the difference between the AvgPool2d and AdaptiveAvgPool2d?
+ Quick Question. Does the model have parameters now? How to initialize the parameter in the new layer?- 快速问题
1.为什么我们使用AdaptiveAvgPool2d? AvgPool2d和 AdaptiveAvgPool2d区别在哪里?
【解答】对于行人图像,其中的高度大于宽度,我们需要为AvgPool2d指定池内核。因此,AdaptiveAvgPool2d更容易实现。当然,您仍然可以使用AvgPool2d。区别:AdaptiveAvgPool2d需要输出维度作为参数,而AvgPool2d需要stride, padding作为参数,类似conv层。如果您想了解更多的技术细节,请参考这里的官方文件。
2.模型现在有参数么?我们怎么初始化参数?
【解答】有。但是,我们应该注意到,如果您没有指定如何初始化模型,那么模型是随机初始化的。在我们的例子中,我们的模型由model_ft和分类器组成,我们部署了两个初始化方法。对于model_ft,我们设置参数pretrained=True,设置为在ImageNet上预训练的模型的参数。对于附加分类器,我们在model.py中使用了weights_init_kaiming函数。
更多细节在 model.py中. 你可以等看完这个实践再回过头去看一下代码。
Part 1.3: 训练 (python train.py)
好的。现在我们准备好了训练数据 和定义好的网络结构。
我们可以输入如下命令开始训练:
python train.py --gpu_ids 0 --name ft_ResNet50 --train_all --batchsize 32 --data_dir your_data_path--gpu_ids which gpu to run.
--name the name of the model.
--data_dir the path of the training data.
--train_all using all images to train.
--batchsize batch size.
--erasing_p random erasing probability.
让我们来看一下train.py.当中我们做了什么。第一件事情是如何读数据和他们的label. 我们使用了 torch.utils.data.DataLoader, 可以获得两个迭代器dataloaders['train'] and dataloaders['val'] 来读数据.。
详解:前面torchvision.datasets.ImageFolder得到的image_datasets[x]只是list,list是不能作为模型输入的,因此在PyTorch中需要用另一个类来封装list,那就是:torch.utils.data.DataLoader。torch.utils.data.DataLoader类可以将list类型的输入数据封装成Tensor数据格式,以备模型使用。注意,这里是对图像和标签分别封装成一个Tensor。这里要提到另一个很重要的类:torch.utils.data.Dataset,这是一个抽象类,在pytorch中所有和数据相关的类都要继承这个类来实现。比如前面说的torchvision.datasets.ImageFolder类是这样的,以及这里的torch.util.data.DataLoader类也是这样的。所以当你的数据不是按照一个类别一个文件夹这种方式存储时,你就要自定义一个类来读取数据,自定义的这个类必须继承自torch.utils.data.Dataset这个基类,最后同样用torch.utils.data.DataLoader封装成Tensor。
image_datasets = {}
image_datasets['train'] = datasets.ImageFolder(os.path.join(data_dir, 'train'),
data_transforms['train'])
# os.path.join(“home”, "me", "mywork")即"home\me\mywork",拼接路径作用
image_datasets['val'] = datasets.ImageFolder(os.path.join(data_dir, 'val'),
data_transforms['val'])
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=opt.batchsize,
shuffle=True, num_workers=8) # 8 workers may work faster
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}这里data_dir目录下一般包括两个文件夹:train和val,每个文件夹下面包含N个子文件夹,N是你的分类类别数,且每个子文件夹里存放的就是这个类别的图像。在之前的数据集准备中已经创建好train的val文件夹了,所以我输入的地址data_dir应该是/home/xxq/reid/Market-1501-v15.09.15/pytorch。
以下则是主要的代码来训练模型。是的,一共只有20行,但确保你要理解每一行。
# Iterate over data.遍历数据。
for data in dataloaders[phase]:
# get a batch of inputs 获得一批输入,从dataloders[]中读取batch_size个数据
inputs, labels = data
now_batch_size,c,h,w = inputs.shape
if now_batch_size<opt.batchsize: # skip the last batch 跳过最后一批,最后一批的batchsize一定比原设定的要小
continue
# print(inputs.shape)
# wrap them in Variable, if gpu is used, we transform the data to cuda.
# 用变量包装它们,将Tensor封装成模型真正可以用的Variable数据类型
# 如果使用gpu,我们将数据转换为cuda。
if use_gpu:
inputs = Variable(inputs.cuda())
labels = Variable(labels.cuda())
else:
inputs, labels = Variable(inputs), Variable(labels)
# Variable可以看成是tensor的一种包装,其不仅包含了tensor的内容,还包含了梯度等信息,因此在神经网络中常常用Variable数据结构。
# 封装后的inputs是一个Variable,那么inputs.data就是对应的tensor。
# zero the parameter gradients
optimizer.zero_grad() # 把梯度置零,也就是把loss关于weight的导数变成0
# 因为一个batch的loss关于weight的导数是所有sample的loss关于weight的导数的累加和,所以要将梯度d_weights初始化为零
#-------- forward --------
outputs = model(inputs) # 即前向传播求出预测的值
# 得到输出后还希望能到到模型预测该样本属于哪个类别的信息,这里采用torch.max。
_, preds = torch.max(outputs.data, 1)
# 输出的outputs也是torch.autograd.Variable格式,torch.max()的第一个输入是tensor格式,所以用outputs.data作为输入
# 第二个参数1是代表dim的意思,也就是取每一行的最大值,其实就是我们常见的取概率最大的那个index
loss = criterion(outputs, labels) # 将输出的outputs和原来导入的labels作为loss函数的输入得到损失
#-------- backward + optimize --------
# only if in training phase 计算得到loss后就要回传损失。要注意的是这是在训练的时候才会有的操作,测试时候只有forward过程。
if phase == 'train':
loss.backward() # 即反向传播求梯度
optimizer.step() # 即根据梯度更新所有参数
+ Quick Question. Why we need optimizer.zero_grad()? What happens if we remove it?
+ Quick Question. The dimension of the outputs is batchsize*751. Why?- 快速问答。
1.为什么我们需要optimizer.zero_grad() ? 如果我们去掉这一行会发生什么?
【解答】zero_grad()将变量的梯度设置为0。在每次迭代中,我们都会使用梯度来更新网络,所以我们需要在更新后清除梯度。否则会积累梯度。
2.输出的维度是batchsize*751. 为什么?
【解答】输出的是所有种类样本的可能性,Market-1501中的训练样本的类数为751。
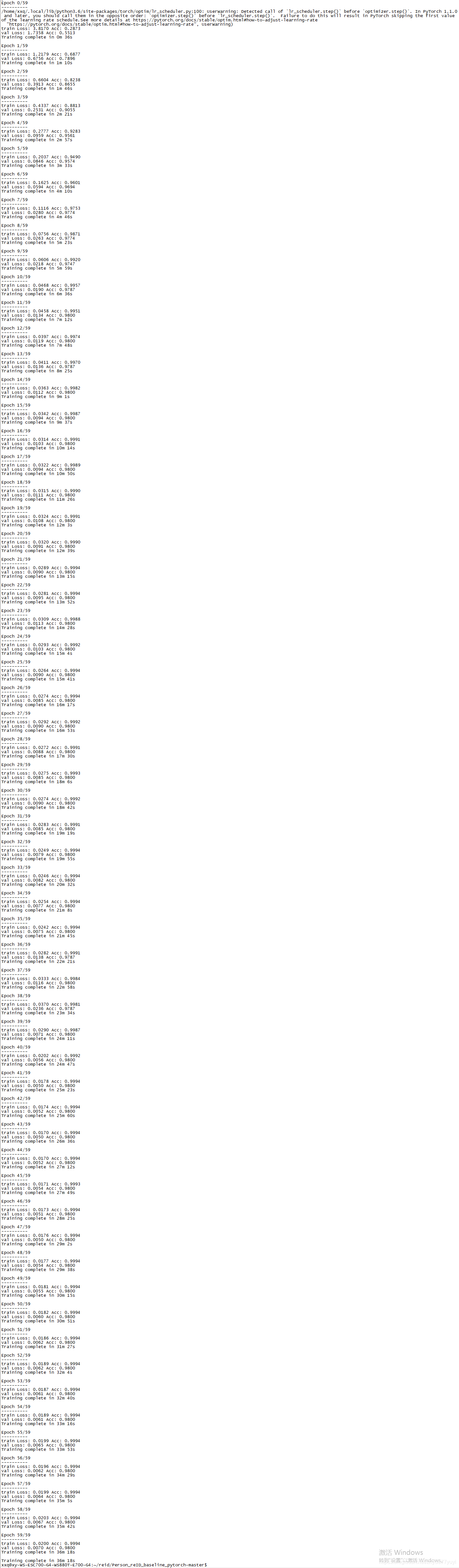
if epoch%10 == 9:
save_network(model, epoch)
draw_curve(epoch)每十轮,我们会保存网络和更新loss曲线。可以去看看这两个函数具体怎么写。
接下来使用以下命令运行:
python train.py --gpu_ids 0 --name ft_ResNet50 --train_all --batchsize 32 --data_dir /home/xxq/reid/Market-1501-v15.09.15/pytorch如果出现提示:“no module named pretrainedmodels”

代码作者在知乎上说这个库是为了兼容之后的NAS网络,使用 pip install pretrainedmodels 命令进行安装。
再运行代码(会先下载resnet50模型):
Part 2: 测试
Part 2.1: 特征提取 (python test.py)
这一部分, 我们载入我们刚刚训练的模型 来抽取每张图片的视觉特征
python test.py --gpu_ids 0 --name ft_ResNet50 --test_dir your_data_path --batchsize 32 --which_epoch 59--gpu_ids which gpu to run.
--name the dir name of the trained model.
--batchsize batch size.
--which_epoch select the i-th model.
--data_dir the path of the testing data.
让我们看看我们在 test.py中做了什么。 首先,我们需要载入模型的结构,然后载入weight。
model_structure = ft_net(751)
model = load_network(model_structure)对于每张查询图片(query)和 查询库图像(gallery),我们抽取特征通过简单的前向传播.
outputs = model(input_img)
# ---- L2-norm Feature ------
ff = outputs.data.cpu() # 把输出变量转化为tensor并放在CPU上
fnorm = torch.norm(ff, p=2, dim=1, keepdim=True) # 对ff的每行的每个数据进行2范数运算
ff = ff.div(fnorm.expand_as(ff)) # expand_as()把一个tensor变成和函数括号内一样形状的tensor
# div()对数据进行标准化,使得各行的和为1,并生成图表
+ Quick Question. Why we flip the test image horizontally when testing? How to fliplr in pytorch?
+ Quick Question. Why we L2-norm the feature?!注释:torch.norm()函数的用法:
一个3×4矩阵inputs,如下:
tensor([[ 1., 2., 3., 4.],
[ 2., 4., 6., 8.],
[ 3., 6., 9., 12.]])
接着我们分别对其行和列分别求2范数
inputs1 = torch.norm(inputs, p=2, dim=1, keepdim=True)
print(inputs1)
inputs2 = torch.norm(inputs, p=2, dim=0, keepdim=True)
print(inputs2)
结果分别为
tensor([[ 5.4772],
[10.9545],
[16.4317]])
tensor([[ 3.7417, 7.4833, 11.2250, 14.9666]])
怎么来的?
inputs1:(p = 2,dim = 1)每行的每一列数据进行2范数运算
inputs2:(p = 2,dim = 0)每列的每一行数据进行2范数运算
关注keepdim = False这个参数
inputs3 = inputs.norm(p=2, dim=1, keepdim=False)
print(inputs3)inputs3为
tensor([ 5.4772, 10.9545, 16.4317])输出inputs1和inputs3的shape
print(inputs1.shape)
print(inputs3.shape)torch.Size([3, 1])
torch.Size([3])可以看到inputs3少了一维,其实就是dim=1(求范数)那一维(列)少了,因为从4列变成1列,就是3行中求每一行的2范数,就剩1列了,不保持这一维不会对数据产生影响。
或者也可以这么理解,就是数据每个数据有没有用[]扩起来。
keepdim = True,用[]扩起来;
keepdim = False,不用[]括起来~;
不写keepdim,则默认keepdim = False
不写dim,则计算Tensor中所有元素的范数
!注释:tensor.expand_as()函数示例:
tensor.expand_as()这个函数就是把一个tensor变成和函数括号内一样形状的tensor,用法与expand()类似。
差别是expand括号里为size,expand_as括号里为其他tensor。
举例:
import torch
x = torch.tensor([[1], [2], [3]])
print('xsize:',x.size())
print('x:',x)
x_expand=x.expand(3,4)
print('x_expand:',x_expand)
输出为:
xsize: torch.Size([3, 1])
x: tensor([[1],
[2],
[3]])
x_expand: tensor([[1, 1, 1, 1],
[2, 2, 2, 2],
[3, 3, 3, 3]])问题1:为什么我们在测试时水平翻转测试图像?如何在pytorch里fliplr?
【解答】Please refer to this issue.
问题2:为什么我们使用L2 -范数特征?
【解答】我们对特征进行l2 -范数,以便在下一步中应用余弦距离。您也可以使用欧几里德距离,但是余弦距离更容易实现(使用度量乘法)。
ps:欧氏距离通常用于衡量2个点之间的距离,注意这2个点可以是定义在2维空间的,也可以是定义在3维空间或者n维空间的。
二维的公式
ρ = sqrt( (x1-x2)^2+(y1-y2)^2 )
三维的公式
ρ = sqrt( (x1-x2)^2+(y1-y2)^2+(z1-z2)^2 )
将your_data_path改为我的查询图片(query)和 查询库图像(gallery)所在的地址/home/xxq/reid/Market-1501-v15.09.15/pytorch,运行以下指令:
python test.py --gpu_ids 0 --name ft_ResNet50 --test_dir /home/xxq/reid/Market-1501-v15.09.15/pytorch --batchsize 32 --which_epoch 59若出现提示:No module named scipy,通过 pip install scipy 安装一下:

继续运行
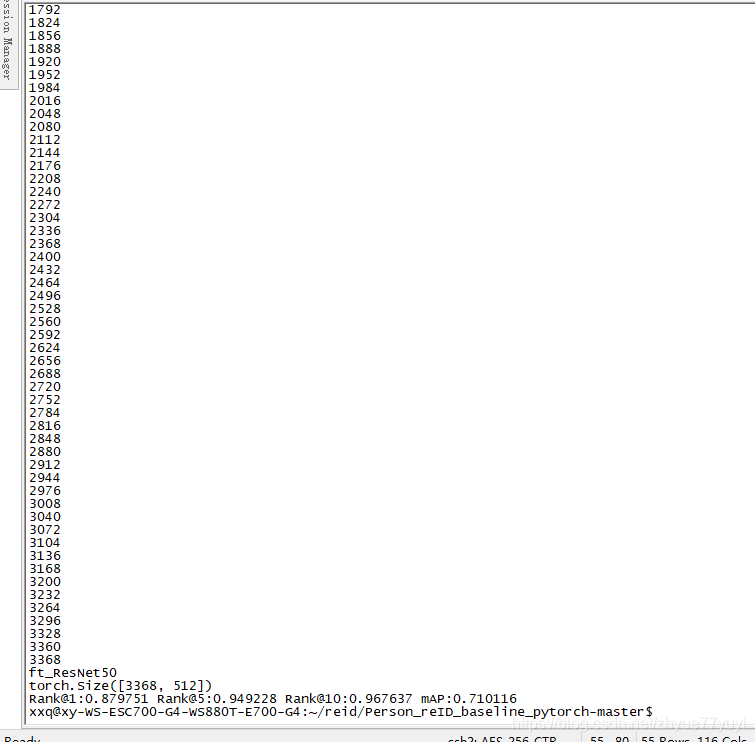
test.py中是没有print Rank、mAP的语句的,可在test.py找到以下语句,执行了evaluate_gpu.py计算了Rank和mAP:
print(opt.name)
result = './model/%s/result.txt'%opt.name
os.system('python evaluate_gpu.py | tee -a %s'%result)Part 2.2: 评测(evaluate_gpu.py)
是的,现在我们有了每张图片的特征。 我们需要做的事情只有用特征去匹配图像。
python evaluate_gpu.py让我们看看我们在 evaluate_gpu.py做了什么. 我们将图像按他们的相似度排序。
query = qf.view(-1,1) # 通过view改变tensor的形状,-1是自适应的调整,这里把所有数据放到一列上
# print(query.shape) qf:query查询图像,gf:gallery中的图像
score = torch.mm(gf,query) # Cosine Distance 余弦距离等价于L2归一化后的内积
# torch.mm表示两个张量的矩阵相乘,因为query只有一列,所以相乘的结果也只有一列
score = score.squeeze(1).cpu() # queeze()功能:去除size为1的维度,包括行和列。当维度大于等于2时,squeeze()无作用。
# 其中squeeze(0)代表若第一维度值为1则去除第一维度,squeeze(1)代表若第二维度值为1则去除第二维度。
# a.cpu()是把a放在cpu上
score = score.numpy() # 把tensor转换成numpy的格式,为了做后面的排序
# predict index
index = np.argsort(score) #from small to large
# argsort()函数是将x中的元素从小到大排列,提取其对应的index(索引),然后输出到y。例如:x[3]=-1最小,所以y[0]=3,x[5]=9最大,所以y[5]=5。
index = index[::-1] # -1是指步长为-1,也就是从最后一个元素到第一个元素逆序输出其实做的就是下面的事情,只不过一张gallery图片的维度可能复杂一些。
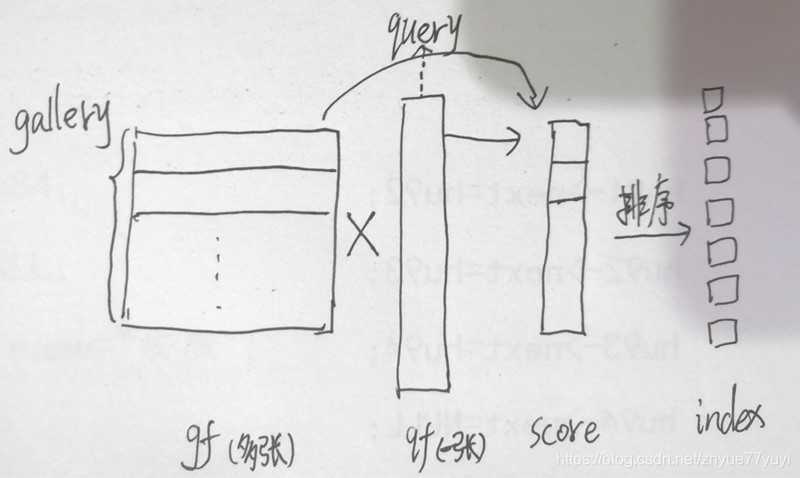
其中的gf,qf是通过
result = scipy.io.loadmat('pytorch_result.mat') #.mat为test.py中保存的数据文件
query_feature = result['query_f']
query_cam = result['query_cam'][0]
query_label = result['query_label'][0]
gallery_feature = result['gallery_f']
gallery_cam = result['gallery_cam'][0]
gallery_label = result['gallery_label'][0]
for i in range(len(query_label)):
ap_tmp, CMC_tmp = evaluate(query_feature[i],query_label[i],query_cam[i],gallery_feature,gallery_label,gallery_cam)调用
evaluate(qf,ql,qc,gf,gl,gc) # 函数功能就是上面做的按距离排序这件事函数传入的。
#test.py中保存了.mat数据文件,并在evaluate.py中使用
result = {'gallery_f':gallery_feature.numpy(),'gallery_label':gallery_label,'gallery_cam':gallery_cam,'query_f':query_feature.numpy(),'query_label':query_label,'query_cam':query_cam}
scipy.io.savemat('pytorch_result.mat',result)所以,qf来自于query_feature[i],query_feature来自于test.py中一批图片传入模型得到的特征数组query_feature.numpy()
同样,gf来自于gallery_feature,来自于test.py中一批图片传入模型得到的特征数组gallery_feature.numpy()注意到有两种图像我们不把他们考虑为正确匹配true-matches
- 一种是Junk_index1 错误检测的图像,主要是包含一些人的部件。
- 一种是Junk_index2 相同的人在同一摄像头下,按照reid的定义,我们不需要检索这一类图像。
query_index = np.argwhere(gl==ql) # 返回满足gl==ql的数组元组的索引,即query和gallery图像所属类别相同。
camera_index = np.argwhere(gc==qc) # 所属摄像头相同
# The images of the same identity in different cameras 只能匹配相同类别不同摄像头的图
good_index = np.setdiff1d(query_index, camera_index, assume_unique=True) # 返回在query_index中但不在camera_index中的值
# assume_unique为True,表示假定输入数组是唯一的,即不合并重复元素
# Only part of body is detected.
junk_index1 = np.argwhere(gl==-1) # 类别为-1表示图片中无具体的人
# The images of the same identity in same cameras
junk_index2 = np.intersect1d(query_index, camera_index) # 计算query_index和camera_index的公共元素 我们可以使用 compute_mAP 来计算最后的结果. 在这个函数中,我们忽略了junk_index带来的影响。
CMC_tmp = compute_mAP(index, good_index, junk_index)运行 python evaluate_gpu.py 指令,发现结果与上述 test结果相同。

!注释:pytorch view():
返回一个新张量,它的数据与 self 张量相同,但 shape 不同。
>>> x = torch.randn(4, 4)
>>> x.size()
torch.Size([4, 4]) # x 为4*4的张量
>>> y = x.view(16)
>>> y.size()
torch.Size([16]) # y为1*16的张量
>>> z = x.view(-1, 8) # -1的大小是从其他维度推断出来的
>>> z.size()
torch.Size([2, 8]) # z为2*8的张量
"""
输出:
tensor([[-0.6413, 1.0150, 1.1099, 0.1736],
[ 0.6944, 1.1347, 0.3699, -0.1459],
[ 0.6396, 1.0228, -1.3372, -0.8312],
[ 0.1817, 1.3849, 0.0417, -0.1628]]) torch.Size([4, 4])
tensor([-0.6413, 1.0150, 1.1099, 0.1736, 0.6944, 1.1347, 0.3699, -0.1459,
0.6396, 1.0228, -1.3372, -0.8312, 0.1817, 1.3849, 0.0417, -0.1628]) torch.Size([16])
tensor([[-0.6413, 1.0150, 1.1099, 0.1736, 0.6944, 1.1347, 0.3699, -0.1459],
[ 0.6396, 1.0228, -1.3372, -0.8312, 0.1817, 1.3849, 0.0417, -0.1628]]) torch.Size([2, 8])
"""
!注释:torch.squeeze()
函数功能:去除size为1的维度,包括行和列。当维度大于等于2时,squeeze()无作用。
其中squeeze(0)代表若第一维度值为1则去除第一维度,squeeze(1)代表若第二维度值为1则去除第二维度。
如果输入是形如(A×1×B×1×C×1×D)(A×1×B×1×C×1×D),那么输出形状就为: (A×B×C×D)
a = torch.Tensor(1,3)
print a
tensor([[-1.37,4.56,-3.57]])print a.squeeze(0)
tensor([-1.37,4.56,-3.57])!注释:对于两个特征,它们的余弦相似度就是两个特征在经过L2归一化之后的矩阵内积。
两个特征的余弦相似度计算出来的范围是**[-1,1]**
代码举例:
import torch
import torch.nn.functional as F
#假设feature1为N*C*W*H, feature2也为N*C*W*H(基本网络中的tensor都是这样)
feature1 = feature1.view(feature1.shape[0], -1)#将特征转换为N*(C*W*H),即两维
feature2 = feature2.view(feature2.shape[0], -1)
feature1 = F.normalize(feature1) #F.normalize只能处理两维的数据,L2归一化
feature2 = F.normalize(feature2)
distance = feature1.mm(feature2.t())#计算余弦相似度
!注释:np.argwhere()的用法
np.argwhere( a )
返回非0的数组元组的索引,其中a是要索引数组的条件。
举例:返回 Array a 中所有大于1的值的索引
>>> x = np.arange(6).reshape(2,3)
>>> x
array([[0, 1, 2],
[3, 4, 5]])
>>> np.argwhere(x>1)
array([[0, 2],
[1, 0],
[1, 1],
[1, 2]])
!注释:np.setdiff1d()的用法
setdiff1d(ar1, ar2, assume_unique=False)
返回值:在ar1中但不在ar2中的从小到大排序的唯一值。
1.assume_unique = False的情况:(从小到大排序,合并重复元素)
a = np.array([1,2,3,4])
b = np.array([3,4,5,6])
c = np.setdiff1d(a, b)
print(c)#[1 2]
a = np.array([8,2,3,2,4,1])
b = np.array([7,4,5,6,3])
c = np.setdiff1d(a, b)
print(c)#[1 2 8]2.assume_unique = True的情况:(按a中的顺序排序,并且不合并重复的元素)
a = np.array([8,2,3,4,2,4,1])
b = np.array([7,9,5,6,3])
c = np.setdiff1d(a, b,True)
print(c)#[8 2 4 2 4 1]
Part 3: 一个简单的可视化程序 (python demo.py)
可视化结果,
python demo.py --query_index 777--query_index which query you want to test. You may select a number in the range of 0 ~ 3367.【因为原query文件夹里有3368张图片】
代码类似 evaluate.py. 我们加入了可视化的部分。
try: # Visualize Ranking Result 可视化结果排名
# Graphical User Interface is needed 需要图形用户界面
fig = plt.figure(figsize=(16,4)) # 显示的尺寸为16*4
ax = plt.subplot(1,11,1) # 显示为1行,每行11个,表示这是第一张图
ax.axis('off') # 不显示坐标轴
imshow(query_path,'query') # 显示查询图片,总共显示11张图,查询图为第一张
# 代码中有具体的imshow函数定义
for i in range(10): #Show top-10 images i从0到9
ax = plt.subplot(1,11,i+2) #循环画剩下的第2到第11张图
ax.axis('off')
img_path, _ = image_datasets['gallery'].imgs[index[i]] # index为已排好序的索引
label = gallery_label[index[i]]
imshow(img_path)
if label == query_label: # 显示是查到的第几张图片,正确的是绿色,错误的是红色
ax.set_title('%d'%(i+1), color='green') # true matching
else:
ax.set_title('%d'%(i+1), color='red') # false matching
print(img_path) # 打印每一张图片的路径
except RuntimeError:
for i in range(10):
img_path = image_datasets.imgs[index[i]]
print(img_path[0])
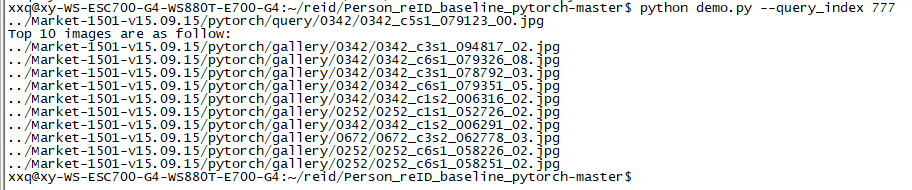
print('If you want to see the visualization of the ranking result, graphical user interface is needed.') # 如果你想看到排名结果的可视化,图形用户界面是必要的运行 python demo.py --query_index 777 指令:
出现个小问题:
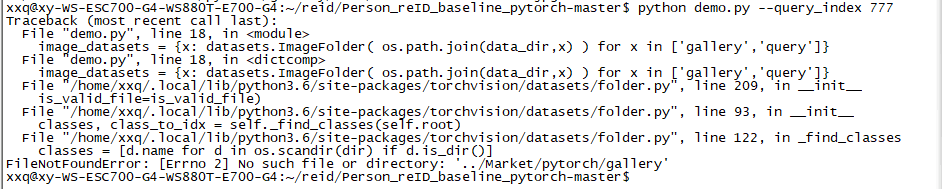
其实原因就是我的数据集文件夹名是Market-1501-v15.09.15而不是Market,在代码里修改数据集所在的目录就好。
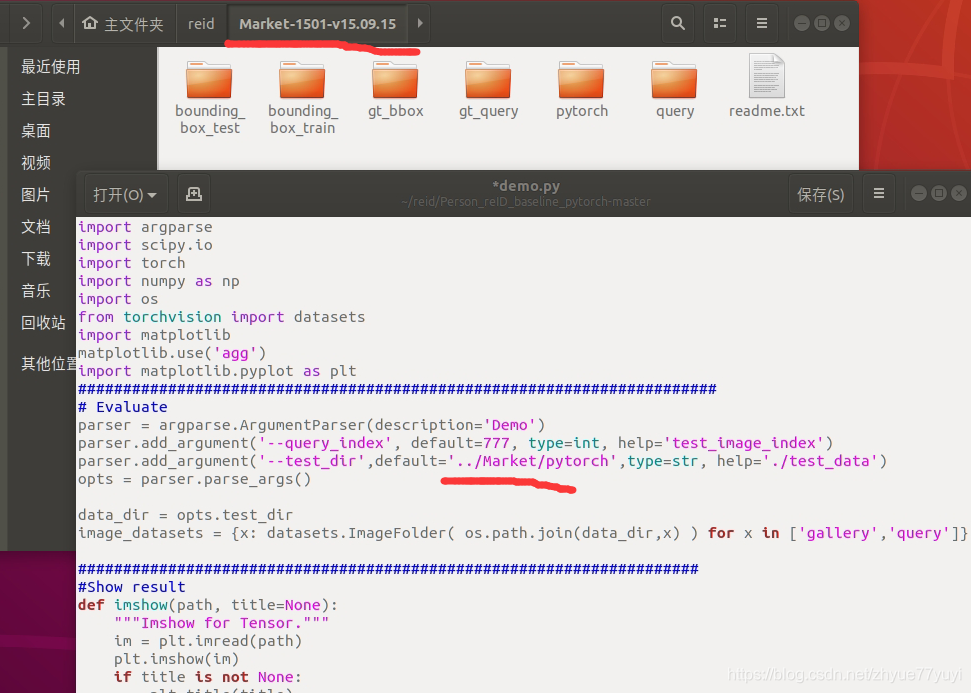
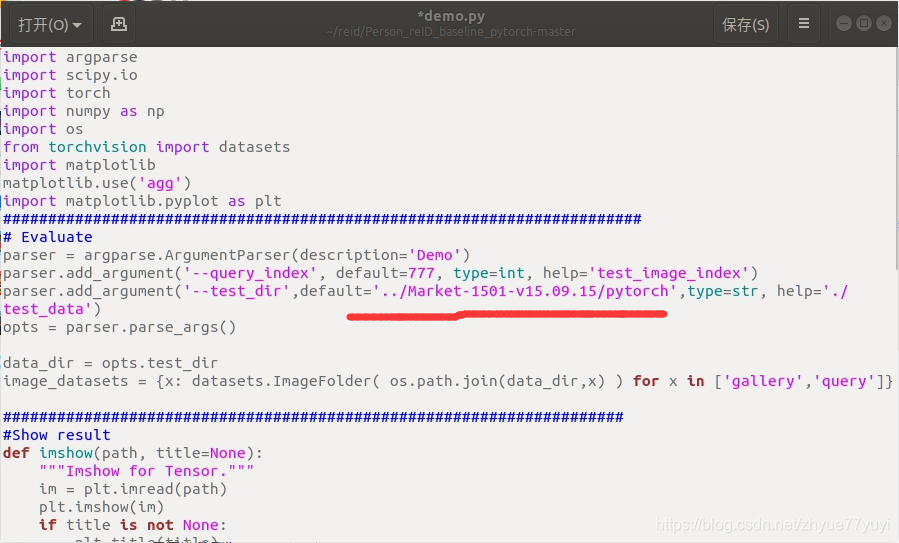
继续执行指令,成功输出十一张图片的路径:
代码通过 fig.savefig("show.png") 将这十一张图片保存在文件夹目录中:

ps:运行demo.py 时agg可能出现问题,将语句 atplotlib.use('agg') 删除就好。
删除后,运行demo.py会直接显示图片
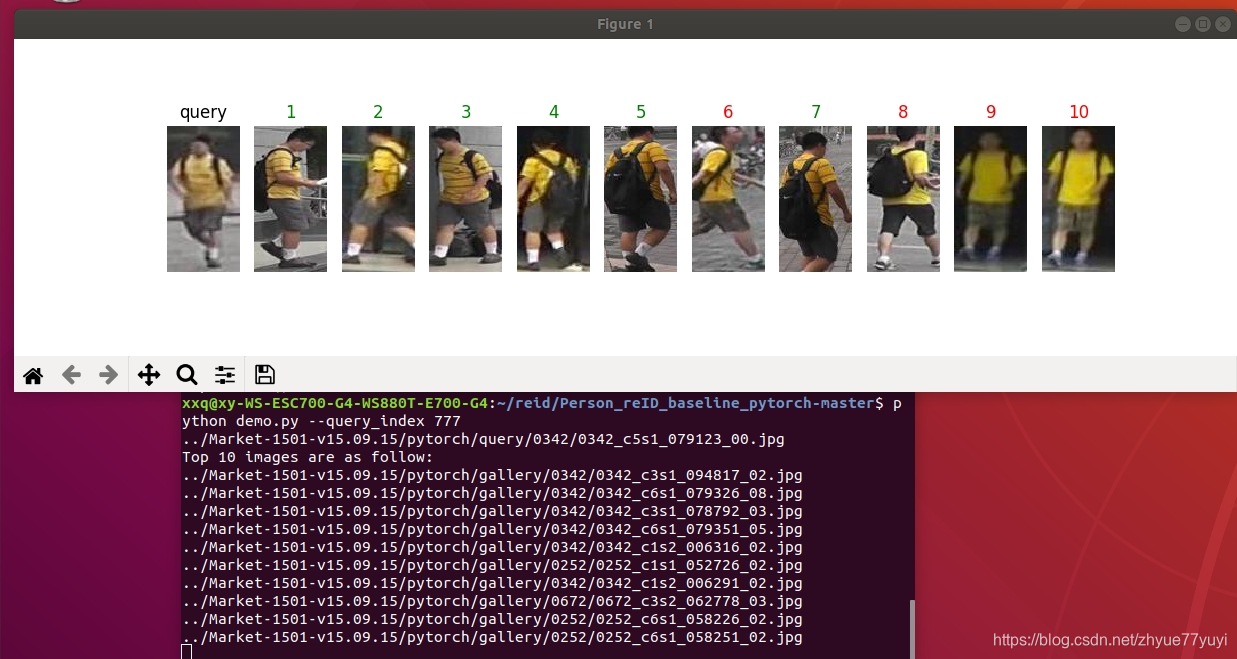
不过。画完之后图就马上消失了。
可在代码倒数第二行加入plt.show() ,因为plt.imshow()函数负责对图像进行处理,并显示其格式,但是不能显示。其后跟着plt.show()才能显示出来。
Part 4: 轮到你了.
- Market-1501 是一个在清华大学夏天收集的数据集.
让我们试试另一个数据集 DukeMTMC-reID, 是在Duke大学冬天采集的。
你可以在这里 Here 下到数据集. 试试去训练这个数据集
这个数据集和Market类似. 你可以 Here 看SOTA的结果
+ Quick Question. Could we directly apply the model trained on Market-1501 to DukeMTMC-reID? Why?- 快速问答。我们能直接用Market训好的模型放到DukeMTMC-reID上测试么? 为什么?
【解答】可以,但是结果还不够好。在许多文献中,不同的数据集通常会有区域间隙,这可能是由不同的因素造成的,如不同的光照和不同的遮挡。为了进一步的参考,您可以查看市场上在数据集Market-1501到DukeMTMC-reid迁移学习的排行榜。 (https://github.com/layumi/dukemtmc-reid_evaluation/tree/master/# transfer-learning)。
- 试试 Triplet Loss. Triplet loss是另一种广泛使用的目标函数. 你可以看看 https://github.com/layumi/Person-reID-triplet-loss. 我把代码风格和本实践保持了一致, 你可以看看我改了什么.
参考资料: Pytorch 03: nn.Module模块了解
PyTorch源码解读之torchvision.models
torch代码解析 为什么要使用optimizer.zero_grad()
PyTorch学习之路(level1)——训练一个图像分类模型
Pytorch——tensor.expand_as()函数示例
文中问题的答案:Answers to Quick Questions

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)