
可解释性人工智能初步学习
本文综述了卷积神经网络可解释性研究的现状与发展。文章首先将可解释性方法分为基于网络和基于输入的两大分支,重点介绍了CAM家族、AM算法、多模态分析等典型方法。在评价指标方面,讨论了相似度对比、IoU等量化标准以及人工评价准则。最后指出当前面临的挑战,包括模型复杂性和不透明性等问题。研究为理解神经网络决策过程提供了方法论指导,同时指出了未来改进方向。
前言
本文为继CAM论文阅读后,对可解释性人工智能进一步的学习了解,有以下几个目的:
- 了解可解释性这一个领域还有哪些典型方法
- 了解可解释性这一个领域有哪些评价指标
- 了解可解释性这一个领域有哪些不足和跳转
本次阅读的综述论文是Dou H, Zhang LM, Han F, Shen FR, Zhao J. Survey on Convolutional Neural Network Interpretability. Ruan Jian Xue Bao/Journal of Software, 2024, 35(1): 159–184 (in Chinese). http://www.jos.org.cn/1000-9825/6758.htm
典型方法
概述
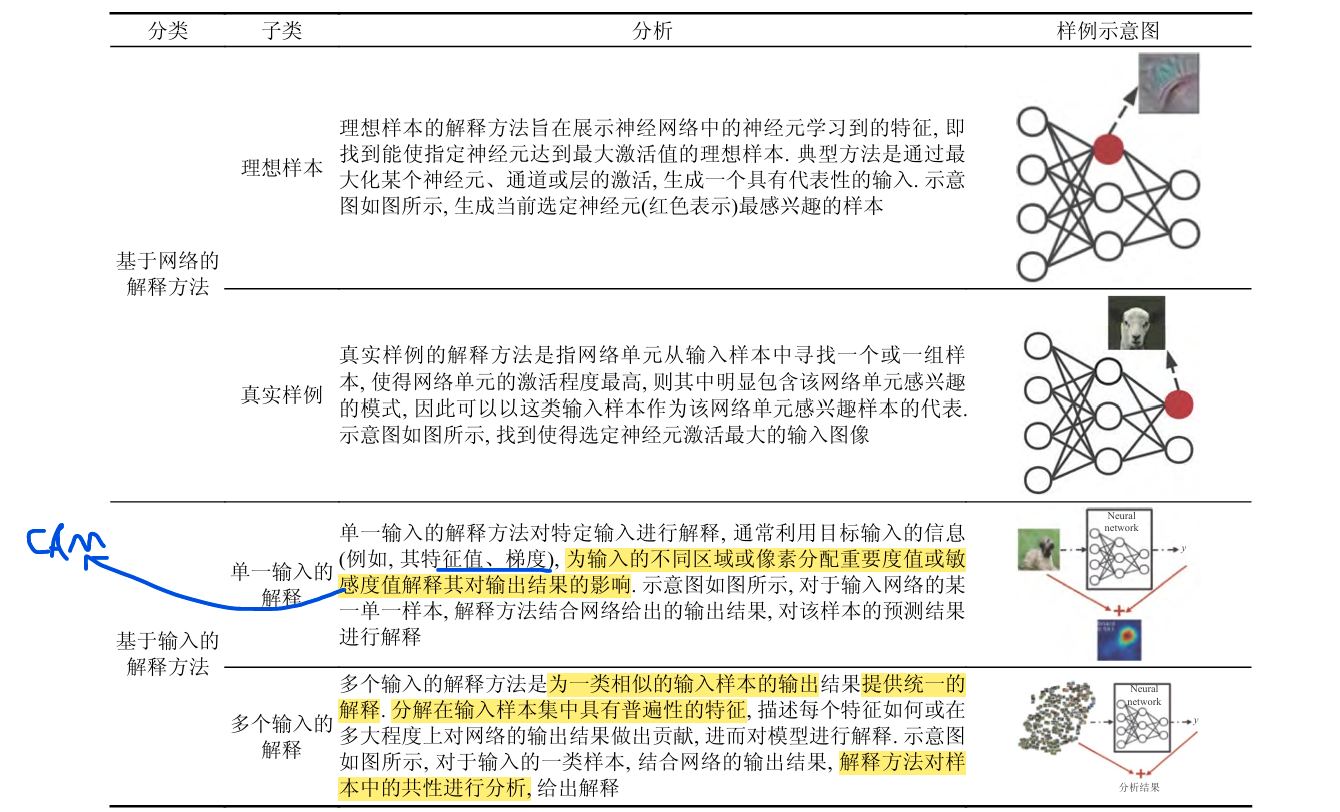
包括CAM大家族,可解释性领域一共有两大分支,我的理解是:可解释性可以类比数学里面的拟合,比如用任意多项式拟合一条曲线,而对于拟合本身,我们要么要明确数据,要么要明确模型,而可解释性方法就是大概可以从这里进行分类的。明确数据在论文中的概括是基于输入的解释法,明确模型在论文中的概括是基于网络的解释方法,这里截取论文图片进行展示
经典方法理解
这里举例几个论文中的经典方法,目前阅读完综述有个大概了解
基于网络的解释方法
对理想样本和真实样本的一句话总结,就是该方法通过"最大化"这一个技术来对无用特征进行屏蔽,关注重点特征,就好像老师总是关注班级的尖子生一样,基于理想样本的解释方法是对“神经元”这一个特征进行最大化,基于真实样例的解释方法是对输入样例进行观察,找到使得网络单元激活程度最高的样例
这两种方法的着重点都在与"网络"本身,而不是输入,我们关注的是网络对于输入是如何解释的
基于理想样本的解释方法
AM算法
原文中对于AM算法的简要解释是这样:

这里有几个关键词需要理解:激活值,迭代优化
激活值:我的理解就是模型对于这一份数据的输出,迭代优化:我的理解就是不断的迭代使得损失函数最小,大概可以用以下伪代码概括
ya=model(xa)
#一般的损失函数是
##Loss=CrossEntropy(),交叉熵损失函数
##Loss=pow(),差值平方
#这里的损失函数
Loss=torch.argmax(ya-dropout)#dropout为特定正则化项
基于真实样例的解释方法
多模态分析方法
原论文中介绍了一种方法

这里这一个链接可能可以对大家有点帮助
【人工智能系列经典图书翻译】可解释机器学习(第二版) 第10章 神经网络的可解释性_神经网络可解释性-CSDN博客
其中Borden数据集大概是文章里说的这张图,长这样
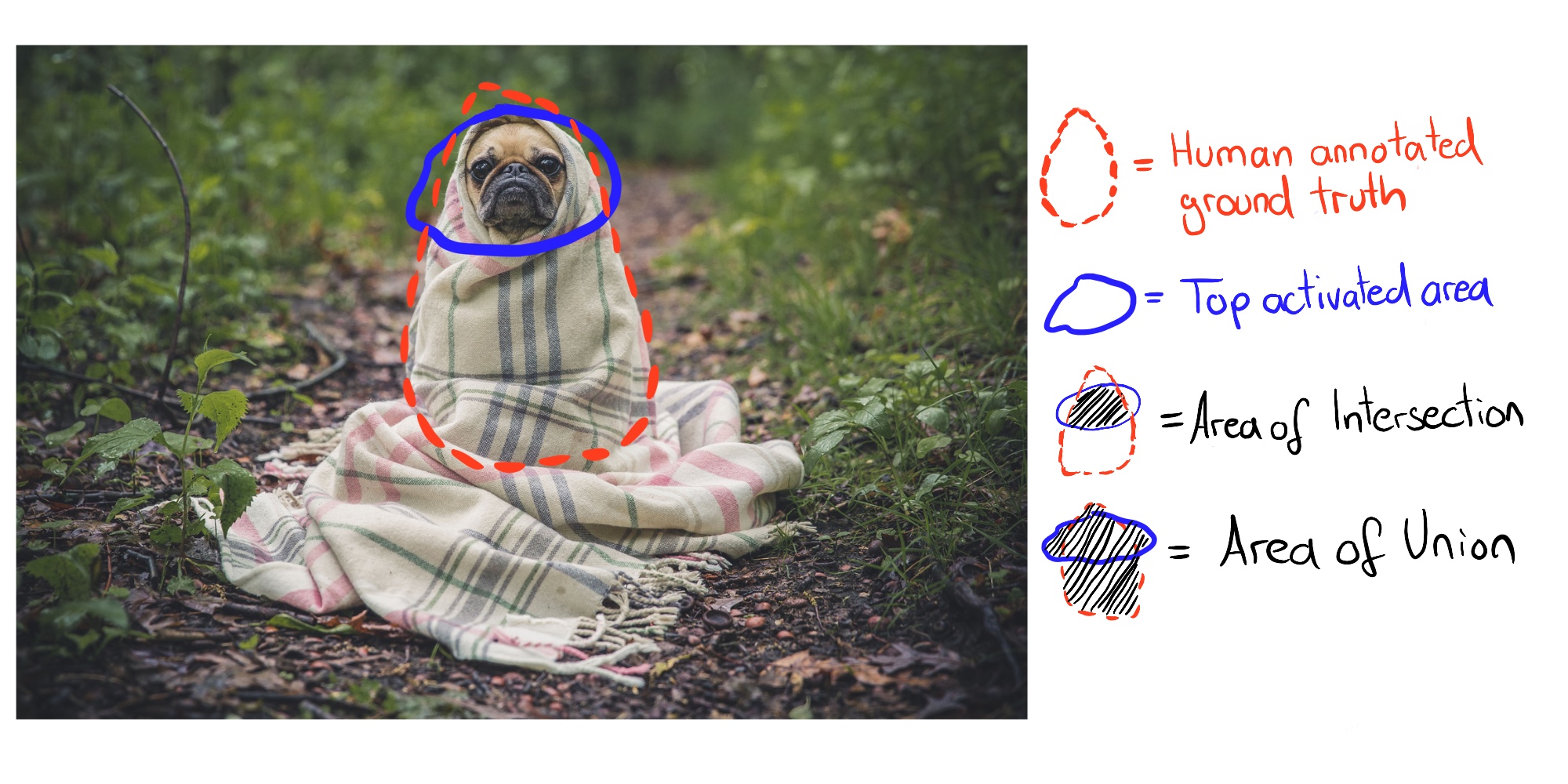
其中蓝色的是我们后面标注的,红色的是数据集本身的标注,红色范围以内的就是属于这一个特征的像素点的集合。对于这方法,我理解是以下几个步骤的集合,下面这些均是我理解的伪代码,如有错误欢迎大家指正
#1:计算论文中的Lc(x)
for piex in inputs:
if piex in c:
Lc[piex]=1
#2:计算Mk(x)
Akx=model(inputs)
Mkx=F(Akx)#其中,F表示进行线性插值操作
#3:计算Iou
for piex in inputs:
Iou=G(Mkx,Lc[piex])#其中,G表示进行Iou的计算
if Iou>default: #如果计算的Iou大于给定值
return True #则说明图像有可解释性的能力
特征提取方法
这里重点理解了以下论文中文献79讲的方法

这里有个表述很抽象,就是我们怎样实现"为高层卷积层中的每个卷积核分配一个对象部分",这里参考Kimi给出的代码
# ---------- 1. 可解释卷积层 ----------
class InterpretableConv2d(nn.Module):
"""
每个卷积核对应一个对象部分
输出: feat_map (B,C,H,W) + mask (B,C,H,W) 0~1
"""
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super().__init__()
# 普通卷积核
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# 1×1 生成分割 mask(对应原文“分割支路”)
self.mask_head = nn.Sequential(
nn.Conv2d(out_channels, 128, 1), nn.ReLU(),
nn.Conv2d(128, out_channels, 1), nn.Sigmoid()
)
# 部分分配表:训练时可更新(C 个核 → C 个部分 ID)
self.register_buffer('part_id', torch.arange(out_channels)) # 长度=C
def forward(self, x):
feat = self.conv(x) # (B,C,H,W)
mask = self.mask_head(feat) # (B,C,H,W) 0~1
# 抑制跨部分激活:feat 只保留对应 mask 区域
feat = feat * mask
return feat, mask利用Sequential形成序列,然后每一次激活序列中的一个层,就实现了为高层卷积层中的每个卷积核分配一个对象部分,相当于我们通过随机激活卷积核来实现"分配"这一个功能,同时利用mask,我们可以分配mask=1或mask=0,来对输出进行控制,这样就实现了"突出"和"隐藏"的功能
其中pytorch的register_buffer以及后续的hook钩子系列,我会继续阅读,深入理解,这里先放上regsiter_buffer的链接
深入理解Pytorch之register_buffer_pytorch buffer-CSDN博客
基于单一输入的解释方法
类激活映射方法
话不多说,就是大名鼎鼎的CAM家族系列
模型未知方法
LIME方法
我对LIME方法的理解,就是在局部生成一个简单的解释模型,这模型的输出基本与我们目标模型在这数据条件下输出的结果一致,有点像我们利用多项式取拟合任意一条曲线一样,这里放上链接
其他方法
论文在之后还介绍了基于多个输入的解释方法,并详细说了以下MAME方法,通过递归分区进行全局解释的GIRP方法,TCAV算法,但是目前这些方法适用范围还不算很大,因为模型的不透明度和复杂性等问题
评价指标
论文详细讲了几种常见的评估方法,在这里的学习目标就是懂得有什么指标,然后到时候写作的时候在具体了解要怎么用这些指标,怎么计算这些指标
- 通过对解释方法生成的理想样本与自然图像的相似程度对比
- 敏感度分数
- IoU
- 指向游戏
此外,论文中还讲了可解释性评价指标的一般准则
- 代理模型的相似性
- 替代任务的完整性
- 对有偏差的模型的检测
- 人工评价的合理性
这里放上原论文截图比较详细一点

面临的挑战
这里论文部分比较容易理解,就不过多赘述

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)