
综述阅读-Manipulating Recommender Systems - A Survey of Poisoning Attacks and Countermeasures
这篇综述文章系统性地探讨了推荐系统中的投毒攻击及其防御措施。文章首先定义了投毒攻击的概念,即攻击者通过注入恶意训练数据来操纵推荐结果的行为。与对抗性攻击不同,投毒攻击针对的是模型的训练阶段而非推理阶段。 作者提出了一个五维分类法来分析投毒攻击,包括攻击目标(目标性/非目标性)、攻击知识(黑盒/灰盒/白盒)等维度。文章还详细比较了基于经典启发式和人工智能的两类攻击方法,并分析了推荐系统特有的安全挑战
参考
-
综述地址: Manipulating Recommender Systems: A Survey of Poisoning Attacks and Countermeasures
-
与投毒相关的资源: awesome-recsys-poisoning
-
阅读工具: 靠岸学术
摘要
推荐系统已成为在线服务中不可或缺的一部分,以帮助用户在数据的海洋中定位到特定的信息。然而,现有的研究表明一些推荐系统易受到投毒攻击(poisoning attacks),特别是涉及学习方案的推荐系统
什么是投毒攻击(poisoning attack)?
投毒攻击指的是攻击者将精心构造的恶意数据注入到模型的训练过程中,目的是操纵系统最终的推荐结果
基于人工智能的最新进展,此类攻击近来变得越来越重要。
本综述旨在通过主要关注投毒攻击及其对策来填补对攻击者攻击的目的、投毒攻击破坏力的认识,系统联系针对攻击的对策和攻击的属性,评估策略风险和潜在成功率等方面的空白
关键词
可信推荐系统,可信人工智能,投毒攻击,模型损坏,对策,投毒防御
1.引言
在数据洪流时代,识别相关信息以支持决策已成为在线服务用户面临的一项具有挑战性的任务。通过帮助用户找到有用的、个性化的信息,推荐系统不仅可以提高服务的可用性,还可以直接为平台提供商的最终成功做出贡献
在许多实际场景中,推荐系统是在一个相对开放的环境中运行的。也就是说,这些系统依赖于其他用户生成的数据,无论是通过评论、发帖和评分等主动方式,还是通过点击、浏览或者购买等被动方式
鉴于推荐的质量通常取决于从大量的候选数据中提取,这种开放性是许多系统成功的关键,但也使得推荐系统容易受到操纵。更具体的说,易受到投毒攻击,攻击者将精心制作的数据注入到模型的训练数据中,从而改变模型的行为
显然,在某种程度上,这种漏洞是不可避免的(推荐系统运营商很清楚会发生此类攻击);但是投毒攻击仍是一种非常强大的操纵用户的方式,可能会严重损害受害者公司的商业成功(比如去发大量的欺诈性信息使别人的产品受影响)
因此,全面了解可以针对推荐系统发起的不同类型的投毒攻击——以及它们的目标、能力和影响——是设计稳健模型的重要先决条件。
1.1 推荐系统的先前分类与综述
推荐系统通常分为三类:
- 基于内容的过滤
- 协同过滤
- 混合系统
在这些方法中,协同过滤由于其产生的推荐质量高而成为推荐系统研究的主流;因此,作者在这篇综述中重点关注基于协同过滤(CF)的推荐系统,并按照所使用的学习方案将其分解如下:
- 基于内存的协同过滤推荐系统:依赖于最近邻搜索,该搜索直接应用于用户的交互历史。因此这些方法不使用显式模型(个人理解是类似KNN那样的懒学习);例如,推荐算法找到与给定目标用户最接近的用户,识别他们的共同偏好,并基于这些共享偏好为目标用户得出推荐
- 基于模型的协同过滤推荐系统:假定了一个潜在的“生成”模型,该模型解释了用户-物品交互,这些系统试图估计一个为给定目标用户生成推荐的模型
在过去的二十年中,协同过滤推荐系统采用的模型变得越来越先进,针对它们的攻击也随之发生了变化。这些攻击可以分为两大类:人工智能攻击和经典启发式攻击
- 经典启发式攻击:这类攻击遵循的策略包含两个策略:(1)检测恶意用户,这被表述为一个优化问题;(2)解决该问题,通过一种启发式技术来完成
- 基于AI的攻击:这些攻击训练一个端到端框架来伪造用户资料并模仿真实的用户行为;例如基于生成对抗网络GAN的方案,该方案自动模仿真实用户的行为以影响目标系统。另一种技术是利用强化学习方案中的奖励信号作为推荐系统模型的后门
虽然基于人工智能的投毒攻击对推荐系统构成严重威胁,但现有对这些系统攻击的综述主要集中在经典启发式攻击及其各自的对策
最近的研究涵盖了启发式攻击和基于人工智能的攻击的组合。此外,一些调查涵盖了一般的投毒攻击,而另一些调查则研究特定领域的这些攻击。然而,到目前为止,还没有人进行专门针对推荐系统的调查。在本次综述中,我们通过全面概述推荐系统上的最新攻击以及可以采取的预防措施来弥补这一差距。正如下表中总结的那样
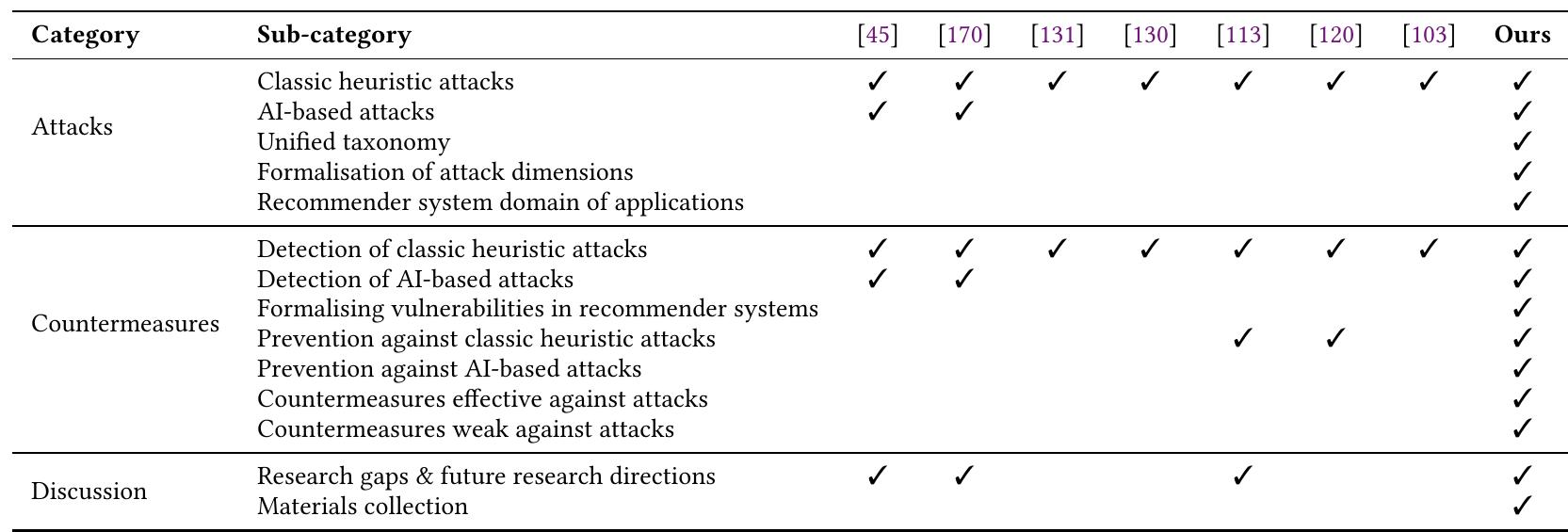
作者还通过以下方式超越了现有的调查:
- 为投毒攻击提供通用分类法
- 形式化此分类法的维度
- 将攻击与对策联系起来(突出了哪些措施可以有效地检测和预防某些攻击,而且还揭示了攻击抵抗某些对策的能力)
投毒攻击与对抗性攻击的对比
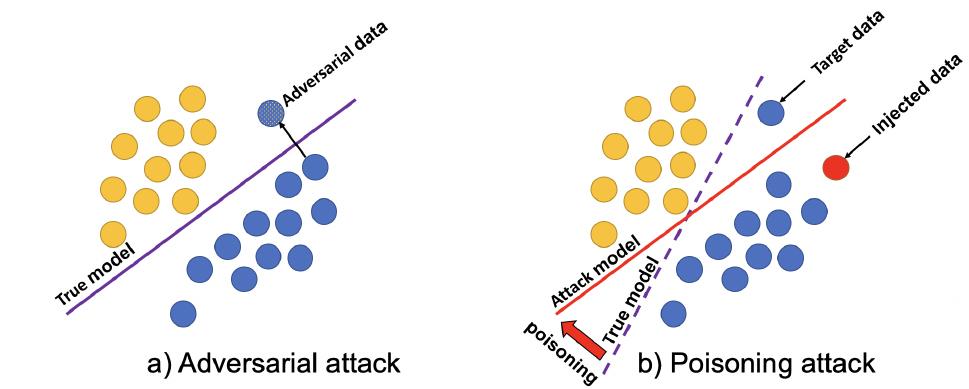
作者提到,现有的几项综述考虑到了对于推荐系统的对抗性攻击(adversarial attacks);虽然对抗性攻击与投毒攻击之间存在一些概念上的相似之处,但是它们确实存在着根本差异
- 对抗性攻击:目的是找到一些对抗性样本,这些样本在推理时破坏推荐系统的结果,而不改变底层模型。这类攻击操纵输入数据,暂时欺骗系统,使其在攻击期间产生不准确的预测或推荐(比如暂时修改用户的浏览历史以推广特定商品)
- 投毒攻击:在模型的训练阶段发起。攻击者将精心构造的恶意数据注入到模型训练数据中,目的是从根本上将真实模型转换为攻击模型,从而产生有利于攻击者目标的结果;通过在训练阶段注入恶意数据,攻击者旨在使系统的学习过程发生偏置,并持续地操纵其推荐(比如直接注入欺诈性评论到系统训练数据中)
1.2 主要贡献
- 我们讨论了攻击者在推荐系统领域面临的挑战,同时将对推荐系统的攻击与机器学习和计算机视觉等领域中的相关方法区分开来
- 我们首次对推荐系统上的投毒攻击进行了全面的综述,涵盖了经典的启发式攻击模式以及基于人工智能的攻击
- 我们对已识别的投毒攻击的40多种防御措施进行了广泛的回顾
2. 背景
2.1 推荐系统概述
基于CF的推荐器可以根据用于捕获用户-物品之间历史互动的底层策略分为以下几类:
2.1.1 基于矩阵分解
基于矩阵分解的推荐系统假设少量潜在因子足以代表用户过去的行为。基于该假设,使用低秩矩阵来估计完整的用户-物品评分矩阵。更具体地说,该低秩矩阵作为推断完整用户-物品评分矩阵中缺失值的基础。然后,针对目标用户的推荐被导出为具有最高预测分数的项目列表,即使该用户之前从未与这些项目进行过交互。一些方法更进一步,通过基于用户的活跃度和项目的受欢迎程度分配不同的权重来提高预测结果
2.1.2 基于图
基于图的方法。基于图的推荐系统将用户和物品之间的历史交互建模为一个加权二分图(有点像LightGT的思路),称为用户偏好图。然后在用户偏好图上执行随机游走以生成推荐
2.1.3 基于关联规则
基于关联规则的推荐系统的思想是根据用户给出的评分,找到项目中共同出现的模式
比如:许多用户对两个物品(物品X和物品Y)给出了高评分。由于许多用户都喜欢这两个物品,系统会假设这两个物品之间一定存在某种隐藏的关联。因此,当用户对物品X给予高评分时,系统会推荐物品Y。
2.1.4 基于邻域
对于基于用户的相似性,系统找到最相似的用户,并聚合他们的评分来推荐物品
2.1.5 基于深度学习
基于深度学习对用户物品之间的交互进行建模
2.2 投毒攻击
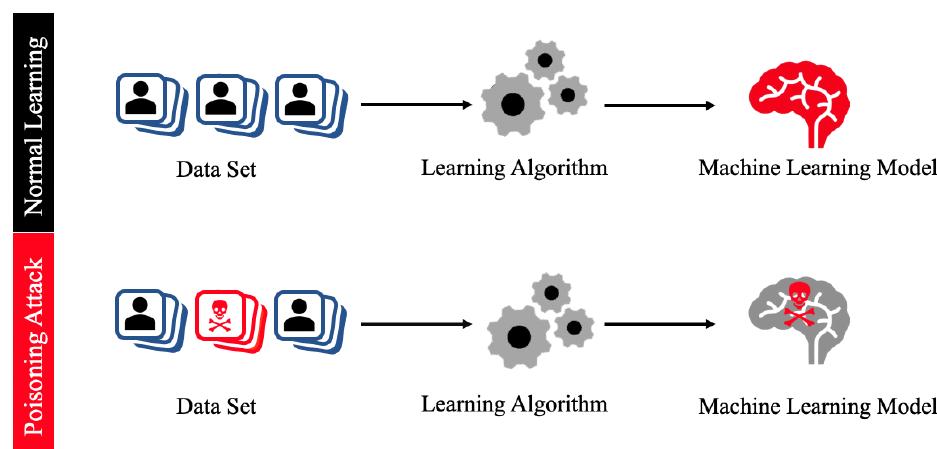
在投毒攻击中,恶意数据被注入到训练集中,从而注入到模型中,以产生意想不到的或有害的结论
针对推荐系统的投毒攻击中,注入到训练集中的数据通常与虚假用户及其虚假评分有关,目的是修改最终的推荐结果
攻击者的一般行动方案是通过注册大量虚假用户来渗透推荐系统。然后,这些用户将对一部分项目进行评分,以强制产生期望的结果。无论攻击策略如何,也无论它是经典启发式攻击还是基于人工智能的攻击,虚假数据(可以手动或自动制作)都会影响任何从数据中学习的模型
对推荐系统的投毒攻击进行分类的一种方法是根据它们旨在攻击的推荐系统类型进行划分
- 模型无关型攻击:忽略了底层模型和用于构建它的任何算法。攻击者无需知道推荐系统基于什么CF推荐策略构建,攻击者通过注入恶意的虚假数据来影响模型的训练过程,从而偏离预期的推荐行为。因此,这些类型攻击的有效性通常是有限的(不针对特定模型,通用性较强,但是攻击效率和准确率可能相对较低)
- 模型内生型攻击:针对特定类型(基于矩阵分解、基于图等特定方法)的训练过程进行优化的。因此,这些攻击可能会对底层模型造成重大损害
如上所述,投毒攻击会将虚假用户及其虚假评分注入系统,从而使模型学习到有偏差的行为。这些攻击不仅可以大规模执行,而且攻击者还可以将多个不同的目标纳入其攻击中
2.3 推荐系统投毒攻击的特征
投毒攻击不仅仅是对在线系统的恶意攻击。事实上,投毒攻击对于机器学习模型的可持续性具有重要意义,因为它们是评估模型对噪声或污染数据鲁棒性的事实标准程序
- 数据相关:推荐系统需要从两个数据源(用户与物品)的交互中学习用户偏好;所以针对推荐系统的投毒攻击不同于对传统机器学习模型的攻击;比如对于CV系统的投毒攻击,可能改变几个像素就足够了,但是对于推荐系统,一次成功的投毒攻击需要注入许多用户-物品相关性
- 缺乏先验知识:机器学习领域中另一种流行的投毒攻击方法是利用梯度下降来发现专用扰动,然后将其与常规样本相结合。由于这些组合是无法检测的,因此它们会严重影响学习模型的质量。通过相比之下,推荐系统通常是黑盒系统,不提供对底层模型的访问。这意味着攻击通常必须仅基于训练数据(即,评分矩阵)。此外,推荐系统的用户通常有隐私方面的顾虑,因此不愿公开他们的偏好。这意味着攻击通常将仅基于训练推荐模型的一小部分数据。
- 多重攻击目标:比如一个目标是推广一组物品,另一个目标是损害竞争对手物品的声誉
2.4 保护推荐系统免受投毒攻击的挑战
- 开放性:推荐系统通常是公开的,即它可以被大量的用户访问;同时用于影响推荐的数据也是开放的,无法先验地根据数量或者分布来表征这些数据,这为数据操纵提供了许多自由度
- 概念漂移:由于季节性或者趋势偏好,用户行为会不断演变;因此真实用户容易被错误地归类为虚假用户
- 数据不平衡:攻击者可以注入到系统中的虚假用户/评分的数量是有限的,而且,这些虚假用户的数量通常只是整个用户群的一小部分
3. 威胁模型与分类
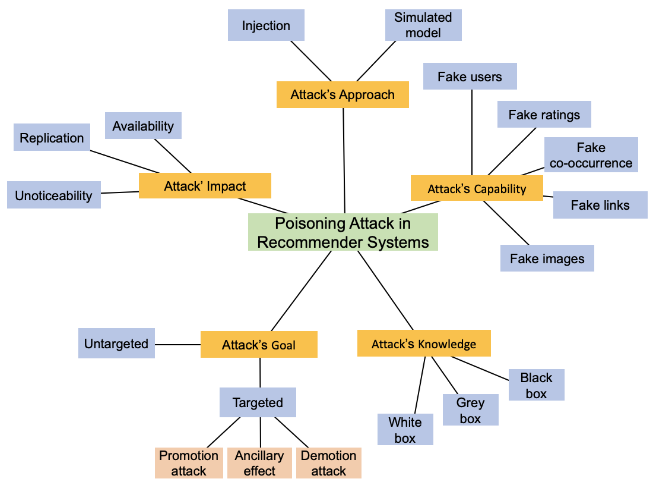
该针对推荐系统投毒攻击的分类方法包含5个不同的维度
- Attack’s Goal
- 非目标性投毒攻击:目的是最大化推荐系统的误差最终使其失效
- 目标性投毒攻击:目标是增加或减少目标物品的受欢迎程度
- Attack’s Knowlegde
- 黑盒攻击:攻击者不知道目标系统的细节(系统架构,预测函数或其参数,用户的历史行为等)
- 灰盒攻击:攻击者掌握有限的知识
- 白盒攻击:攻击者对系统有透彻的理解
- Attack’s Impact攻击影响
- 可用性:推荐系统基于过去积累的数据做出决策。白盒和灰盒攻击会扰乱这些算法的输入数据。首先,攻击者会注入虚假用户来操纵推荐系统,削弱底层模型的准确性。然而,这种被削弱的模型最终将充当后门,帮助攻击者获得对系统的完全控制,从而损害其可用性
- 复制:复制。虽然黑盒攻击在损害系统可用性方面的效率较低,但它们可能会复制系统。一种常见的策略是逆向工程底层模型作为模拟。一旦已知,该模型就可以被复制和利用
- 不易察觉性:一些投毒攻击通过在注入虚假数据时保留关键数据特征,来确保其方法不被察觉
- Attack’s Capability
- 虚假用户
- 虚假评分
- 虚假共现:攻击者不直接为虚假用户插入虚假评分,还可以通过引入项目之间的虚假共现来操纵推荐模型
- 伪造链接
- 伪造图像
- Attack’s Approach攻击方法
- 注入
- 模拟:在黑盒设置中,当攻击者没有足够的知识来进行注入时,攻击通常基于模拟目标推荐系统。更准确地说,代理模型是使用从推荐系统收集的数据进行训练,以重现目标系统的行为。
4. 投毒攻击
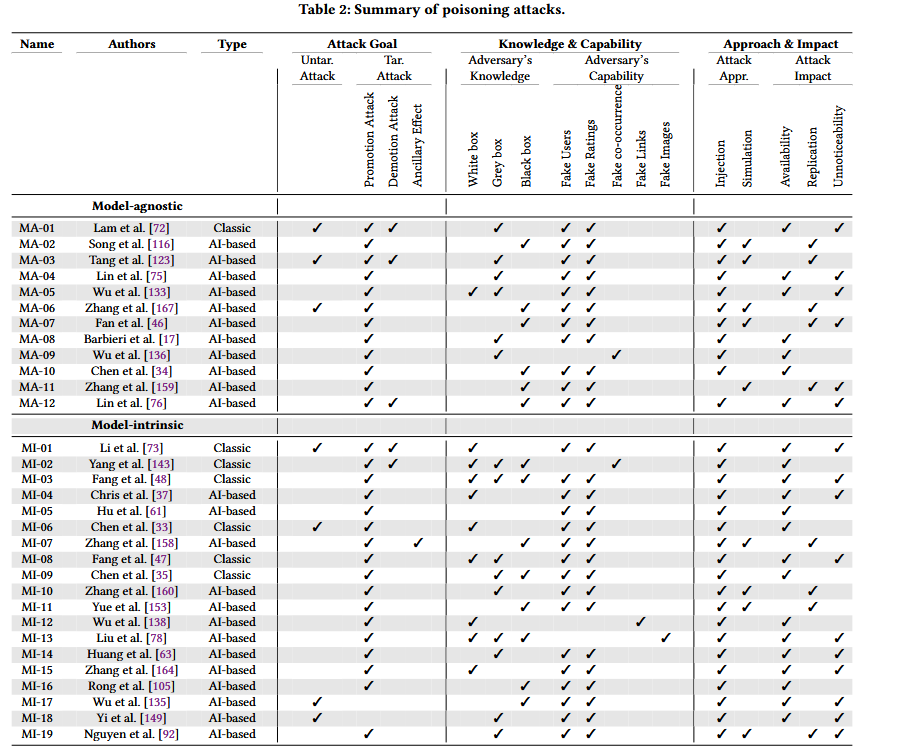
4.1 模型无关型攻击 - Model-agnostic Poisoning Attacks
适用于任意推荐系统,不依赖特定模型细节,核心是通过优化注入数据与原始数据的相似度(如 L2 范数)实现隐蔽性。(注入的数据需要呈现为合法的,从而欺骗推荐系统将其视为真实信息)
代表攻击:
- [MA-01] Lam等人的的shilling攻击(shilling可以理解成水军,托) [Shyong K Lam and John Riedl. 2004. Shilling recommender systems for fun and profit. In WWW. 393–402.],通过注入虚假用户推广特定物品
- [MA-02] Song等人的PoisonRec[PoisonRec: An Adaptive Data Poisoning Framework for Attacking Black-box Recommender Systems],基于强化学习的自适应投毒攻击;通过主动地将虚假用户的交互注入到系统中,PoisonRec通过奖励信号动态地改进其自身的攻击策略,使用了有偏完全二叉树(Biased Complete Binary Tree, BCBT)来重新构建动作空间,以获得更好的攻击性能
- [MA-03] Tang等人的对抗学习的注入攻击[Revisiting Adversarially Learned Injection Attacks Against Recommender Systems];专注于从一个单独的模型中自动学习虚假用户的行为
- [MA-04] Lin等人将GAN(生成式对抗网络)与增强Shilling攻击框架(AUSH)相结合[Attacking Recommender Systems with Augmented User Profiles]
4.2 模型内生型攻击/模型固有型攻击 - Model-intrinsic Poisoning Attacks
- 基于矩阵分解的推荐系统
- [MI-01] Li等人的[Data Poisoning Attacks on Factorization-Based Collaborative Filtering],模仿正常用户的行为,生成未被检测到的虚假数据
- [MI-02] Yang等人的[Fake Co-visitation Injection Attacks to Recommender Systems],将虚假的物品共现数据注入到训练集中
- 基于图的推荐系统
- [MI-03] Fang等人的[Poisoning Attacks to Graph-Based Recommender Systems],注入虚假用户与评分,优化评分以最大化影响并降低检测率
- 基于邻域的推荐系统
- [MI-09] Chen等人的[Data poisoning attacks on neighborhood‐based recommender systems],提出了UNAttack框架,注入伪造用户使目标物品优先推荐给普通用户
- 基于深度学习的推荐系统
- [MI-14] Huang等人的[Data Poisoning Attacks to Deep Learning Based Recommender Systems],将注入评分定义为优化问题,少量交互数据即可实现有效攻击
4.3 投毒攻击对比
从前面图中的五个维度以及投毒攻击总结表对文献投毒攻击特征进行对比
- Attack’s goal:目标性投毒占主导地位
- Attack’s impact:2/3的攻击集中于目标系统的可用性,1/3的攻击同时关注攻击和复制受害者模型
- Attack’s approach:所有方法都以某种形式依赖于将虚假用户和评分注入到训练数据中(注入),一些系统还依赖于模拟目标推荐系统,主要是为了推导出用于注入的用户配置文件。
- Attack’s Capability:80%+ 的攻击依赖 “注入虚假用户 + 虚假评分”,仅少数攻击利用虚假共现关系(如 MI-02)、虚假图像(如 MI-13)
5.防御措施
投毒攻击的防御措施可以分为两类:
- 检测方法:旨在识别在投毒攻击中被伪造的用户资料
- 预防方法:旨在使推荐系统对投毒攻击更具有健壮性,且无需明确识别被篡改的资料
5.1 检测方法
5.1.1 检测特征 - Detection Features
现有检测特征可以依赖于两类特征:模型无关特征,模型固有特征
模型无关特征 - Model-agnostic features
模型无关特征旨在提取通用的异常行为,其涉及不依赖于所针对的攻击模型类型
这类特征包括:
均值一致性评分偏差(RDMA):
该指标用于衡量特定用户对若干特定物品的评分与其他用户对这些物品评分的平均偏差,计算时会以这些物品的评分频率倒数为权重。
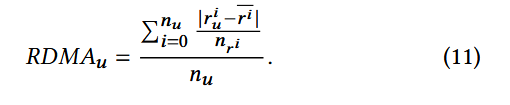
其中: r u i r_{u}^i rui 是用户u对物品i的评分, r ˉ i \bar{r}_{i} rˉi 为所有用户对物品i的评分的平均值, n r i n_{r^{i}} nri 为物品i获得的总评分次数, n u n_{u} nu 代表用户u已评分的物品总数
均值一致性加权偏差(WDMA):
该特征是RDMA的加权方差,主要用于捕捉用户对稀疏物品(评分数量少的物品)的评分累积差异
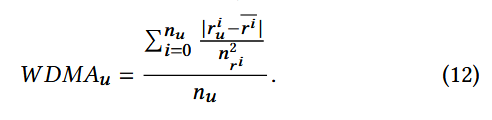
通过平方权重强化稀疏物品( n r i n_{r^i} nri 小, n r i 2 n_{r^i}^2 nri2 更小)
长度方差(LengthVar):
该指标用于衡量用户档案长度的差异,其中档案长度指某一用户档案所评分的物品数量
n u n_{u} nu 为用户u的档案长度, n ˉ u \bar{n}_{u} nˉu 是所有用户档案的平均长度
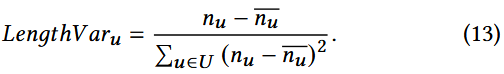
与top-k邻居的相似度(DegSim):
s i m u , v sim_{u,v} simu,v 是用户u和v之间的相似度
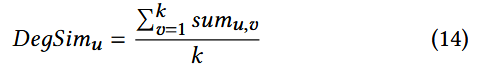
模型固有特征 - Model-intrinsic features
均值方差MeanVar:
该指标将恶意用户档案划分为不同组成部分,包括:极端评分(针对目标物品的评分)、其他评分(仅用于填充档案的物品评分,即所谓的 “填充物品评分”)以及未评分物品。此特征通过计算 “其他评分” 与所有物品平均评分之间的均值方差来估算。
P u , F P_{u,F} Pu,F 代表用户u的填充物品集合F, r u , j r_{u,j} ru,j 代表用户u对物品j的评分, r ˉ u \bar{r}_{u} rˉu 代表用户u对所有物品给出的平均评分
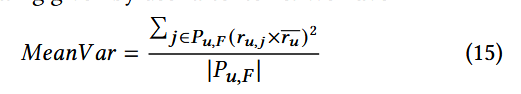
填充均值差异模型FMTD:
该指标用于评估目标物品分组评分与填充物品分组评分之间的差异程度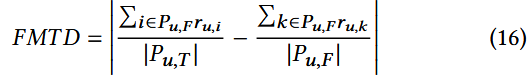
填充平均相关性FAC:
该特征反映某一用户档案中的评分与所有物品平均评分之间的相关性
其中, I u I_{u} Iu 是用户u已评分的物品集合
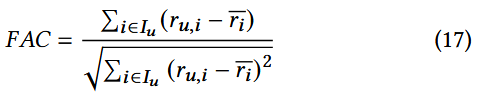
填充均值差异FMD:
该特征用于衡量某一用户档案的评分与所有物品平均评分之间绝对差值的平均值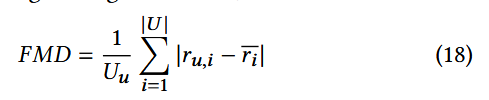
5.1.2 检测特征属性 - Detection Traits
扩展了Sundar等人的开发的检测特征属性的基础框架[Understanding Shilling Attacks and Their Detection Traits: A Comprehensive Survey]
该框架将攻击检测特征属性划分为4类: (i)用户档案、(ii)目标物品评分、(iii)填充物品评分、(iv)辅助信息
(i)
此类特征被检测方法用于区分异常用户资料和真正的用户资料,本文新增了用于对比分析的特征:
- 相似度:某一用户档案与其邻居越相似,该档案作为攻击的一部分被创建的可能性就越大
- 攻击规模:注入的恶意档案数量,若高度相似的档案规模远小于用户档案总集合,则表明存在攻击行为。
- 群组行为:通常,用户行为拥有隐藏的特征;比如一群恶意用户在评分的方差上拥有正相关
- 属性:真实档案与注入的档案在用户属性上往往呈现不同的分布特征
(ii)
目标评分是攻击者为了推广或者贬低某一物品给出的评分
- 聚集性:投毒攻击升高后,目标物品的评分的频率通常会异常的升高
- 评分偏移:攻击者的最终目的是操控用户对目标物品的态度。因此,虚假评分往往会偏离平均评分
(iii)
填充物品评分指的是在攻击行为中,攻击者为伪装身份而对普通物品(非目标物品)给出的评分,而非针对目标物品的评分
- 评分特征:为通过最大化相似度来伪装攻击行为,攻击者给填充物品打的评分通常会接近当前的平均评分。基于这一观察,一种有效的策略或许是先评估填充物品的评分,再据此识别出攻击者
- 档案长度:某一用户档案所评分的物品数量被称为档案的长度;鉴于攻击者会试图创建与真实档案尽可能相似的(恶意)档案,恶意档案的长度通常会远长于普通(真实)档案。因此,通过档案长度可识别出攻击者
(iv)
- 共现性
- 用户-用户图
5.1.3 检测方法概述
检测推荐系统上的投毒攻击的方法概述表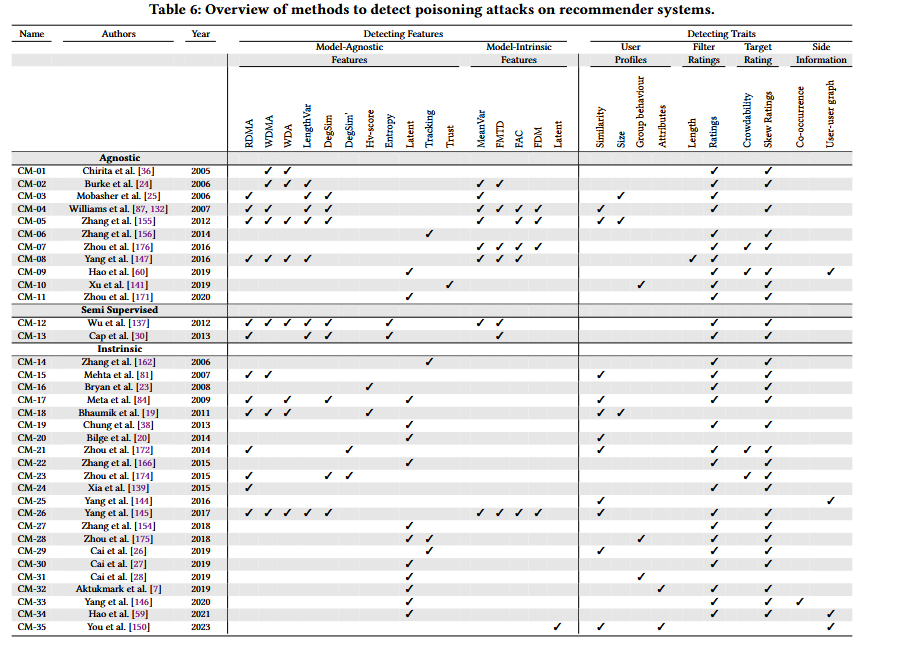
监督方法:
- [Paul-Alexandru Chirita, Wolfgang Nejdl, and Cristian Zamfir. 2005. Preventing shilling attacks in online recommender systems. In WIDM. 67–74.] ,使用RDMA和DegSim特征成功验证检测恶意资料
- [Robin Burke, Bamshad Mobasher, Chad Williams, and Runa Bhaumik.2006. Classification features for attack detection in collaborative recommender systems. In KDD. 542–547.]
- [Robin Burke, Bamshad Mobasher, Chad Williams, and Runa Bhaumik. 2006. Detecting profile injection attacks in collaborative recommender systems. In CEC/EEE). 23–23.]
半监督方法:在大多数推荐系统中,已标记用户的数量通常非常少。此外,为剩余用户标注标签通常是不切实际的,因为它成本太高,而且,对数据的访问通常受到限制
- [Zhiang Wu, Junjie Wu, Jie Cao, and Dacheng Tao. 2012. HySAD: A semisupervised hybrid shilling attack detector for trustworthy product recommendation. In KDD. 985–993.]
- [Jie Cao, Zhiang Wu, Bo Mao, and Yanchun Zhang. 2013. Shilling attack detection utilizing semi-supervised learning method for collaborative recommender system. World Wide Web 16, 5-6 (2013), 729–748.]
无监督方法: - [Sheng Zhang, Amit Chakrabarti, James Ford, and Fillia Makedon. 2006. Attack detection in time series for recommender systems. In KDD. 809–814.]
5.2 预防方法
5.2.1 预防策略
防御措施旨在降低投毒攻击的影响,其中一种有效的防御方式是采用鲁棒优化方法[Bhaskar Mehta and Wolfgang Nejdl.2008. Attack resistant collaborative filtering. In SIGIR. 75–82.]
形式上: R \mathcal{R} R 是用户物品交互矩阵中观察到的评分集合; L \mathcal{L} L 是推荐系统原有的损失函数,用于衡量推荐评分与真实评分的误差; λ \lambda λ 是正则化系数,用于平衡推荐精度与系统抗攻击能力
得到目标函数的形式:

5.2.2 应对挑战以实现鲁棒性
大多数防御方法依赖多种技术的组合。例如,针对 “开放性” 问题,可通过异常值检测、数据清洗和预处理技术来解决 [113 Mingdan Si and Qingshan Li. 2020. Shilling attacks against collaborative recommender systems: a review. Artificial Intelligence Review 53, 1 (2020), 291–319.]。借助这类方法,能够识别并过滤掉被篡改的数据。
再如,对于 “概念漂移” 问题,通常采用动态学习算法来应对,该算法可适配不断变化的用户行为 [120 Agnideven Palanisamy Sundar, Feng Li, Xukai Zou, Tianchong Gao, and Evan D Russomanno. 2020. Understanding shilling attacks and their detection traits: a comprehensive survey. IEEE Access 8 (2020), 171703–171715.]。这种适应性使系统能够区分用户行为的真实变化与伪造用户,从而助力维持推荐的准确性。
而对于 “数据不平衡” 问题,一般通过集成方法来解决 [103 Fatemeh Rezaimehr and Chitra Dadkhah. 2021. A survey of attack detection approaches in collaborative filtering recommender systems. Artificial Intelligence Review 54, 3 (2021), 2011–2066.]—— 这类方法会为少数类分配更高权重,并采用过采样或欠采样技术来平衡数据集。
5.2.3 相关工作
Sandvig等人发现基于模型的推荐系统比基于记忆的推荐系统更稳定更具有鲁棒性
在此基础上,他们设计了一种基于关联规则挖掘的鲁棒推荐系统,该系统相较于基于邻域和基于模型的推荐系统有显著改进。他们提出的算法通过用户画像中的物品共现模式捕捉物品间的关联关系,既能生成更精准的推荐,又能减轻投毒攻击的影响 [Jeff J Sandvig, Bamshad Mobasher, and Robin Burke. 2007. Robustness of collaborative recommendation based on association rule mining. In RecSys. 105–112.]
Mehta等人开展的另一项研究,则探索了利用统计技术(具体为鲁棒 M 估计器)提升推荐系统鲁棒性的方法。他们借助鲁棒 M 估计器提出了一种矩阵分解算法,该算法的性能优于概率潜在语义分析(PLSA)、奇异值分解(SVD)等其他基于潜在语义的算法 [Bhaskar Mehta, Thomas Hofmann, and Wolfgang Nejdl. 2007. Robust collaborative filtering. In RecSys. 49–56.]
5.3 哪些对策对哪些攻击有效?
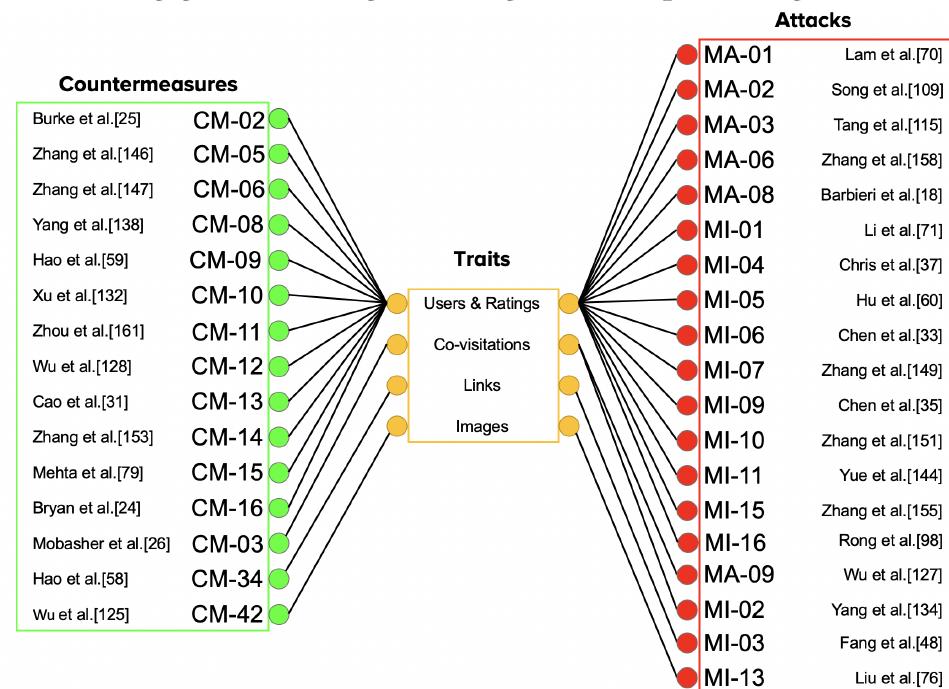
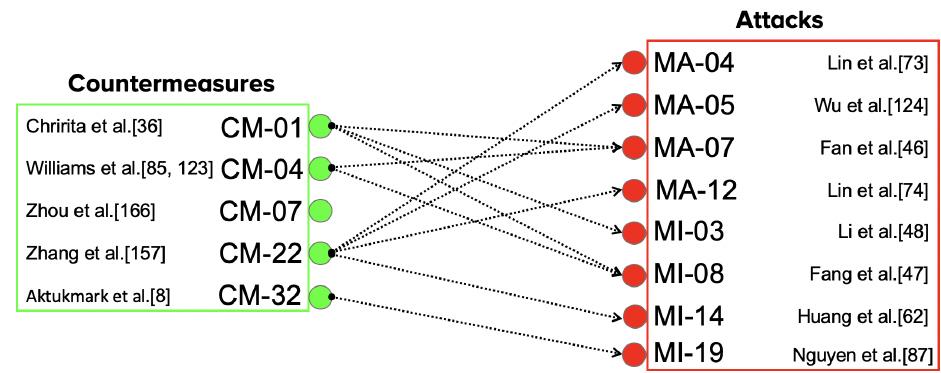
6. 研究空白与未来方向
-
攻击相关空白
- 黑盒攻击防御:现有攻击多依赖白盒 / 灰盒知识,黑盒攻击(隐私场景常见)的防御研究不足;
- 模型无关攻击:当前以模型固有攻击为主,需加强模型无关攻击研究以评估新兴推荐系统鲁棒性;
- 辅助信息融合:推荐系统日益依赖领域超图、用户社交属性等辅助信息,针对这些信息的投毒攻击需重点关注。
-
防御相关空白
- 攻击前检测:现有防御多在攻击造成损失后检测,需研发实时监测攻击准备行为的方法;
- 多特征融合:防御多聚焦评分特征,需结合用户属性、物品属性等辅助特征提升检测率;
- 公平性与可解释性:防御仅关注精度,需兼顾公平性(避免误判真实用户)与可解释性(理解攻击生成机制);
- 开销优化:现有防御特征提取开销大,需降低开销以适配实时推荐场景。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)