
大数据毕业设计hadoop+spark+hive小说数据分析可视化大屏 小说推荐系统 小说爬虫 小说大数据 机器学习 知识图谱 小说网站 计算机毕业设计
大数据毕业设计hadoop+spark+hive小说数据分析可视化大屏 小说推荐系统 小说爬虫 小说大数据 机器学习 知识图谱 小说网站 计算机毕业设计
·
博主介绍:✌全网粉丝100W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
🍅由于篇幅限制,想要获取完整文章或者源码,或者代做,可以给我留言或者找我聊天。🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
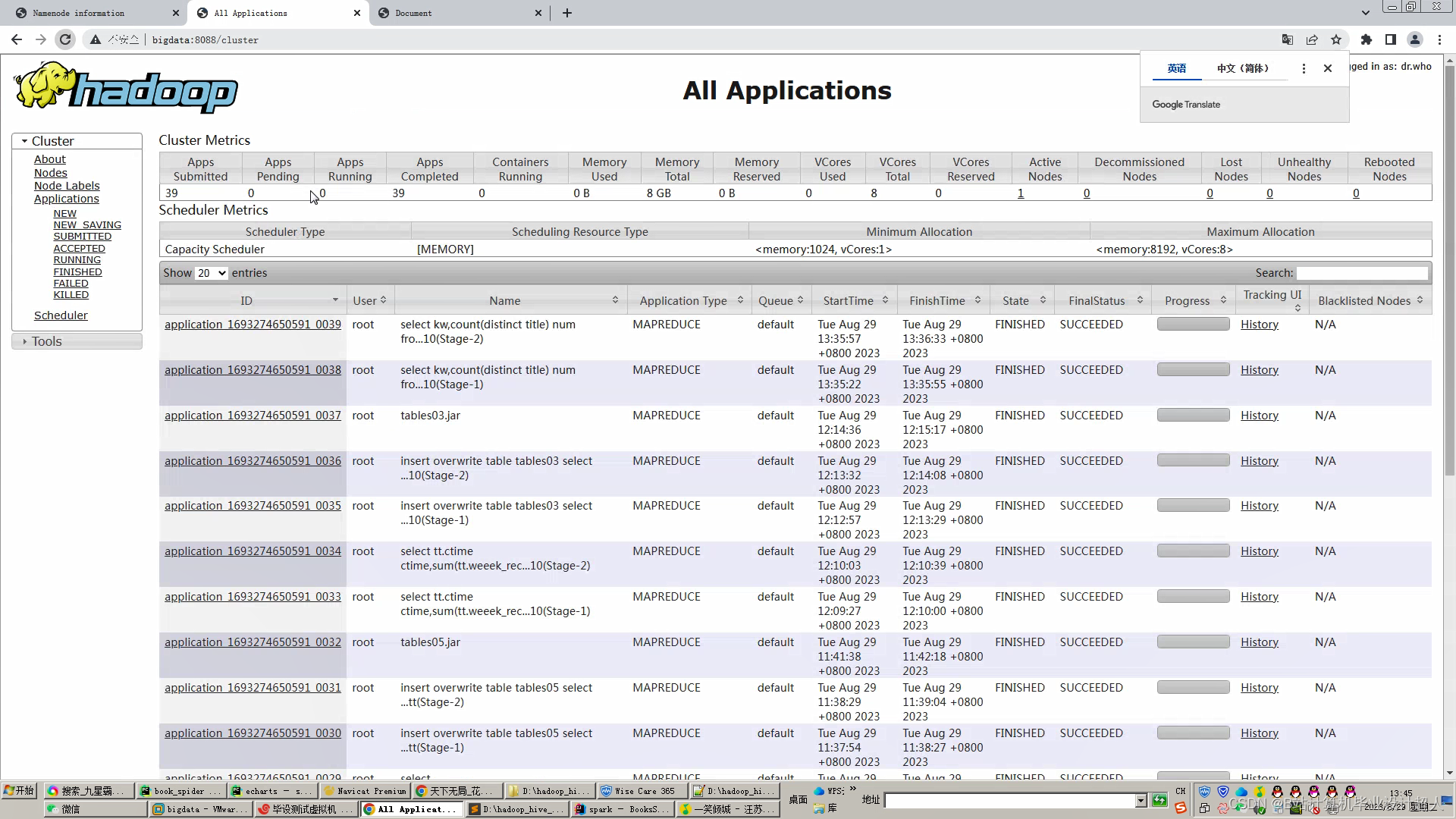
文章包含:项目选题 + 项目展示图片 (必看)
流程:
1.爬取17k.com的小说数据约5-10万,存入mysql数据库;
2.使用mapreduce对mysql中的小说数据集进行数据清洗,转为.csv文件上传至hdfs文件系统;
3.根据.csv文件结构,使用hive建库建表;
4.一半分析指标使用hive_sql完成,一半分析指标使用Spark-Scala完成;
5.将分析结果使用sqoop导入mysql数据库;
6.使用Flask+echarts构建可视化大屏;
创新点:Python爬虫、海量数据、可视化、实时计算spark+离线计算hive双实现
可选装知识图谱、推荐系统、后台管理、预测系统等,实现界面如下(可0秒无缝衔接选装上)
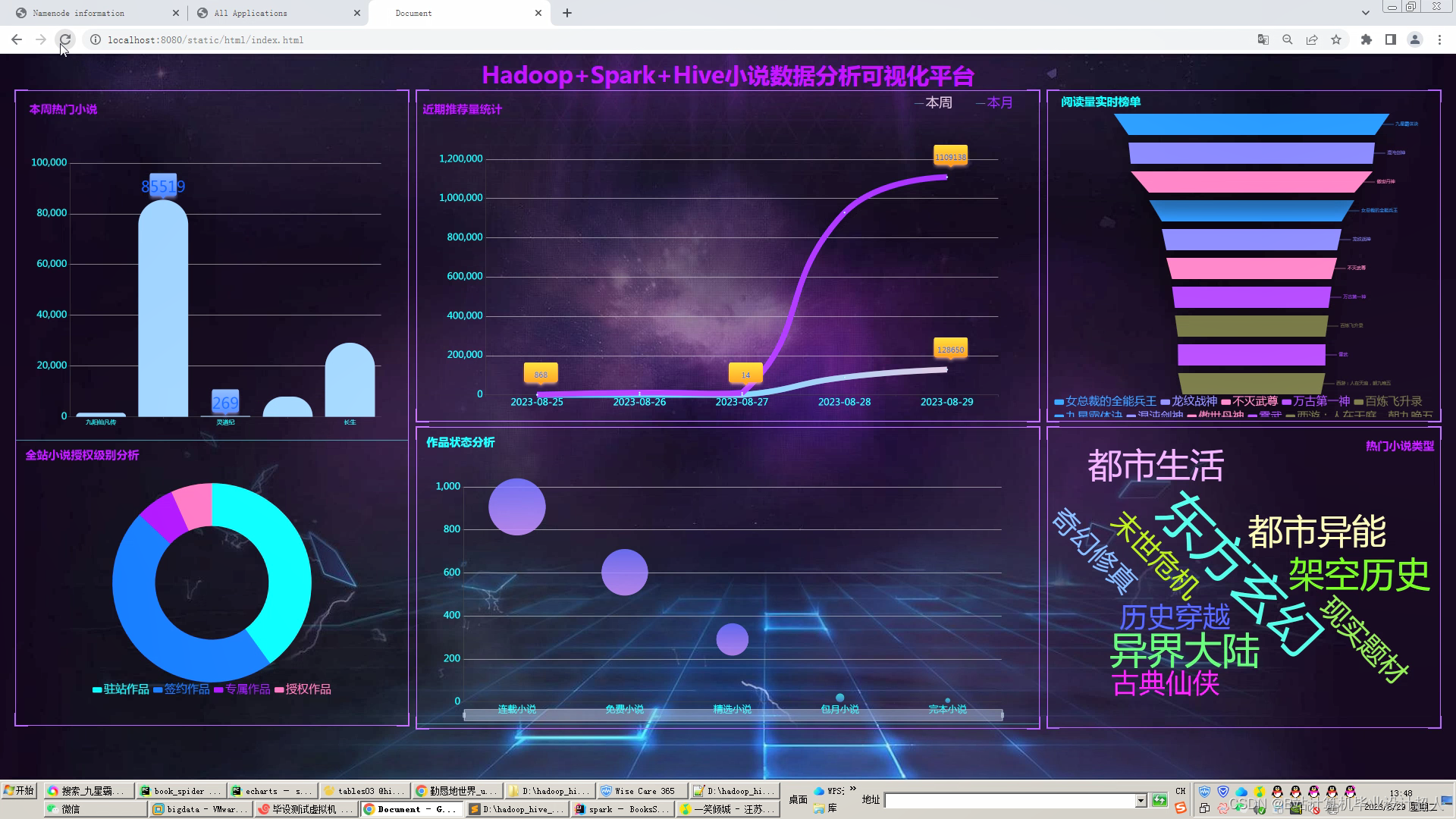
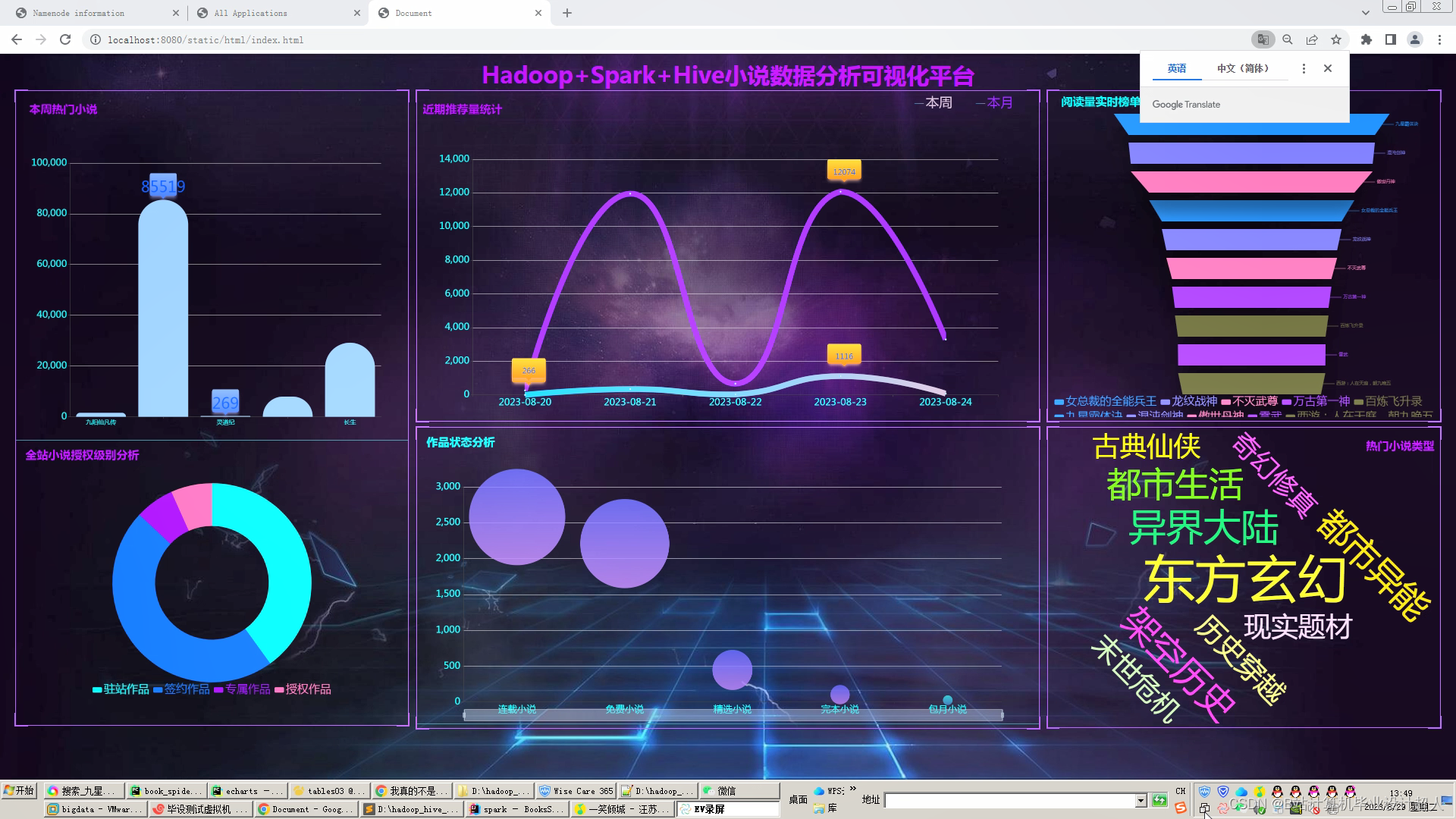
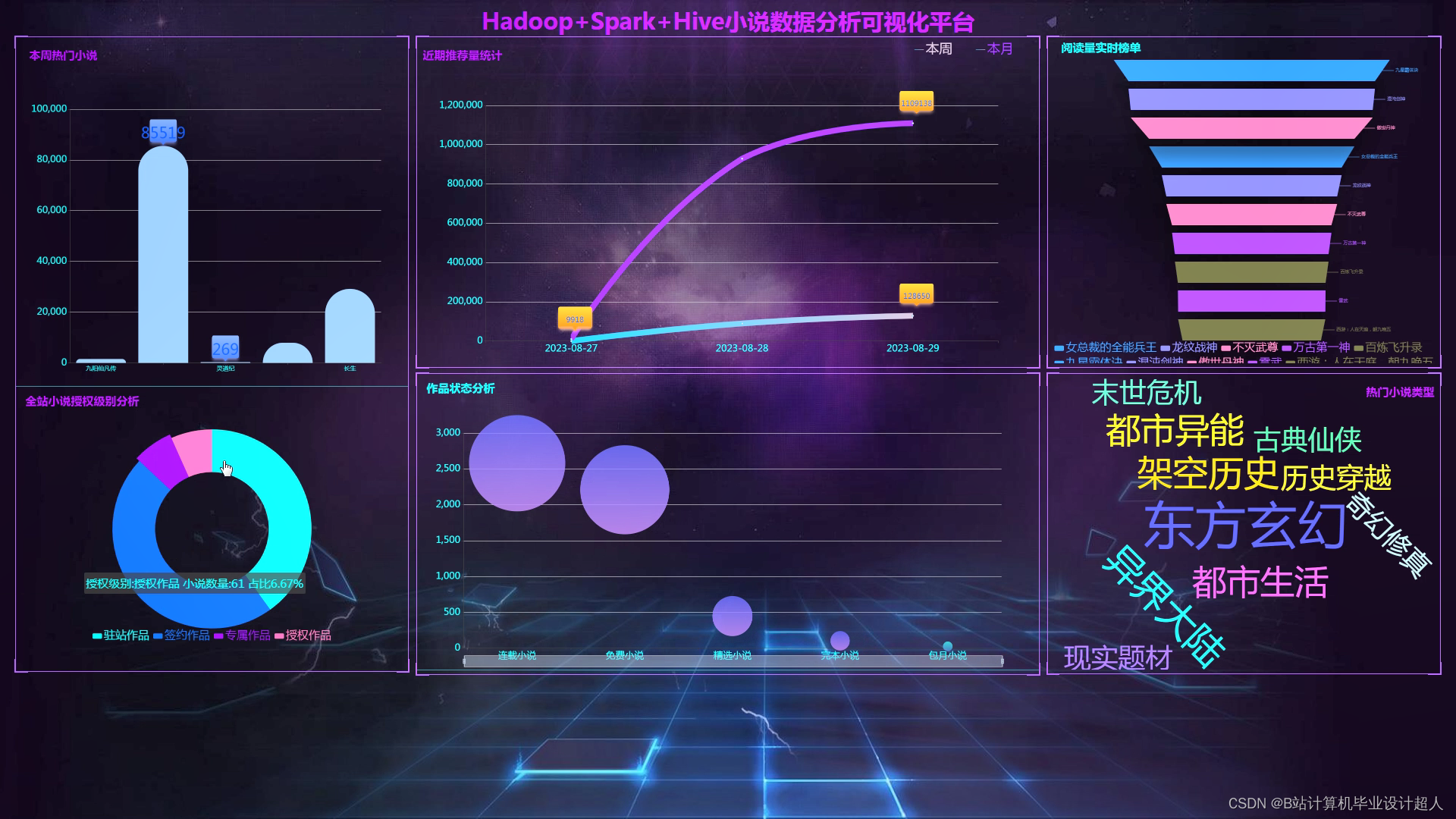
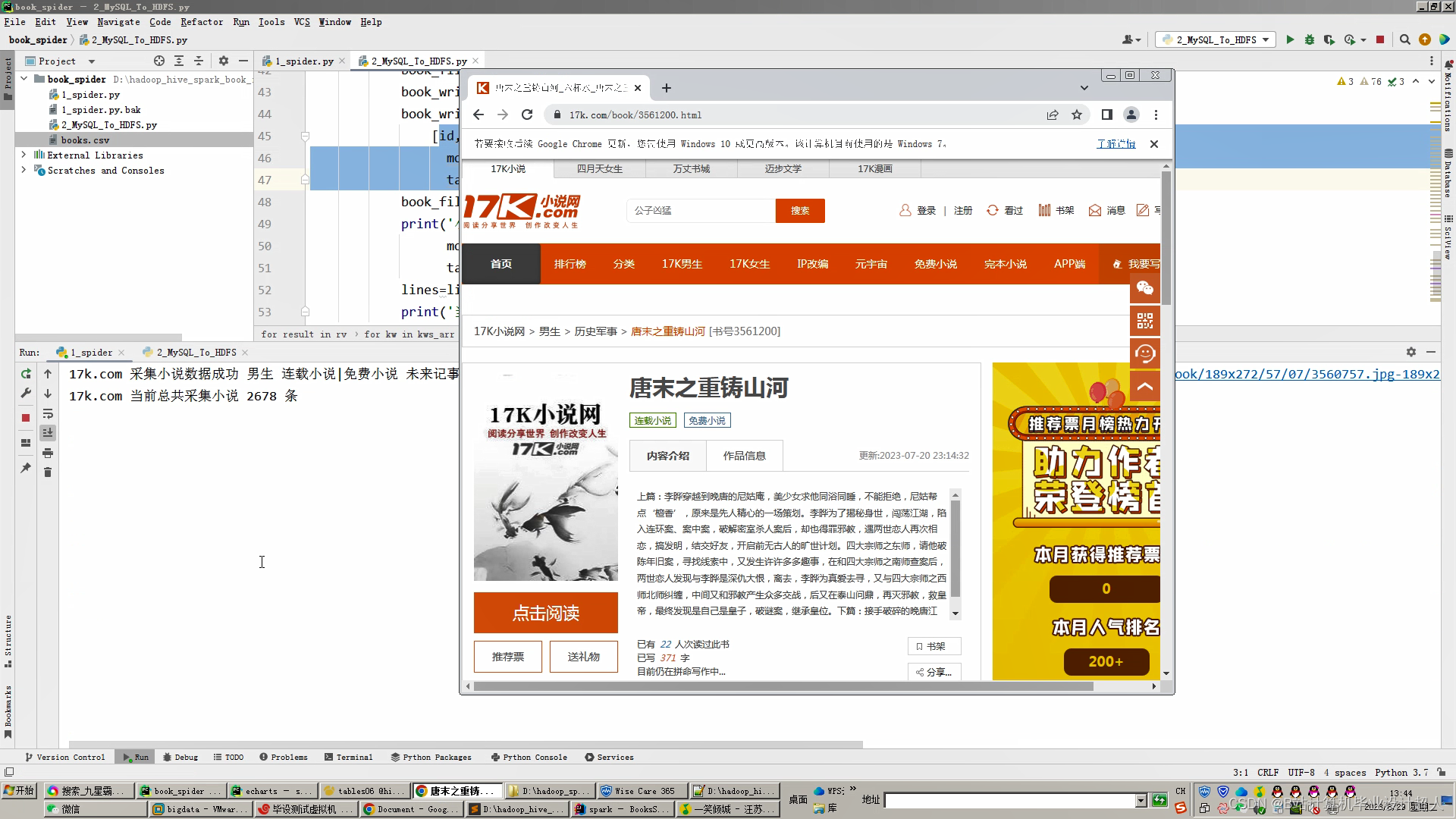
核心代码如下:
import requests
from bs4 import BeautifulSoup
def get_novel_chapters(novel_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
response = requests.get(novel_url, headers=headers)
response.raise_for_status() # 检查请求是否成功
soup = BeautifulSoup(response.text, 'html.parser')
# 假设小说章节列表的XPath是'.//ul[@class="chapter-list"]/li/a'
chapter_links = soup.select('.//ul[@class="chapter-list"]/li/a')
chapters = []
for link in chapter_links:
chapter_url = link.get('href')
chapter_title = link.text
chapter_content = get_chapter_content(chapter_url)
chapters.append({
'title': chapter_title,
'content': chapter_content
})
return chapters
def get_chapter_content(chapter_url):
response = requests.get(chapter_url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# 假设章节内容的XPath是'.//div[@class="chapter-content"]'
content = soup.select_one('.//div[@class="chapter-content"]').text
return content.strip()
# 示例小说URL
novel_url = 'https://example.com/novel'
# 获取小说所有章节
chapters = get_novel_chapters(novel_url)
# 打印章节信息
for chapter in chapters:
print(chapter['title'])
print(chapter['content'])
print('-' * 80)

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 6
6 0
0- 0



 已为社区贡献606条内容
已为社区贡献606条内容

所有评论(0)