
LangGraph构建多智能体
LangGraph 是一个专为构建复杂、多智能体(Multi-Agent)语言模型应用而设计的开源框架。它由 LangChain Inc. 开发,灵感来源于 Pregel 和 Apache Beam,接口设计借鉴了 NetworkX。LangGraph 允许开发者以图结构的方式定义和编排代理的行为流程,提供了高度的可控性和灵活性。

一、LangGraph 的核心概念
LangGraph 是一个专为构建复杂、多智能体(Multi-Agent)语言模型应用而设计的开源框架。它由 LangChain Inc. 开发,灵感来源于 Pregel 和 Apache Beam,接口设计借鉴了 NetworkX。LangGraph 允许开发者以图结构的方式定义和编排代理的行为流程,提供了高度的可控性和灵活性。
1. 图结构的Agent编排
在 LangGraph 中,应用被建模为一个有向图(Directed Graph):
-
节点(Node):代表一个操作步骤,如调用 LLM、执行工具函数等。
-
边(Edge):定义节点之间的执行顺序和条件逻辑,支持循环和分支。
这种结构使得复杂的工作流(如多轮对话、任务分解与执行)可以被清晰地表达和管理。
2. 状态管理与持久化
LangGraph 内置了状态管理机制,允许在图的每一步之后自动保存状态。这支持:
-
错误恢复:在出现异常时从最近的检查点恢复执行。
-
人工干预:在关键节点暂停,等待人工审核或输入。
-
“时间旅行”:回溯到某个状态,修改后重新执行。
状态的持久化使得应用具有更高的可靠性和可调试性。
3. 人机协作(Human-in-the-Loop)
LangGraph 支持在执行过程中引入人工决策,特别适用于需要专家判断的场景,如医疗诊断、金融分析等。系统可以在某些节点暂停,等待人工输入后再继续执行。
4. 流式输出与实时反馈
通过支持逐个令牌的流式传输,LangGraph 提供了更好的用户体验。用户可以实时看到代理的思考过程和中间结果,增强了交互性和透明度。
官网:
https://www.langchain.com/langgraph
github地址:
GitHub - langchain-ai/langgraph: Build resilient language agents as graphs.
官方文档(英文):
https://langchain-ai.github.io/langgraph/
LangGraph的架构说明
https://langchain-ai.github.io/langgraph/concepts/agentic_concepts/
5、langgraph与dify,coze对比
LangGraph、Dify 和 Coze 是三种用于构建 AI 应用的工具,它们在定位、目标用户、开发方式和适用场景等方面各有特色。以下是对这三者的深入对比,帮助你根据自身需求做出选择。
| 特性 | LangGraph | Dify | Coze |
|---|---|---|---|
| 开发方式 | 原生代码(Python) | 低代码(可视化 + 配置) | 无代码(可视化 + 模板) |
| 灵活性 | 高 | 中 | 低 |
| 学习曲线 | 陡峭 | 中等 | 平缓 |
| 适用用户 | 开发者、AI 工程师、研究人员 | 企业用户、开发者、产品经理 | 初级用户、C 端用户、非技术背景人员 |
| 适用场景 | 复杂 AI 应用、企业级应用、研究项目 | 企业级 AI 应用开发、生产环境部署 | 快速构建聊天机器人、简单 AI 应用 |
| 部署方式 | 本地部署、云部署 | 本地部署、云部署 | 云部署 |
| 可定制性 | 高 | 中 | 低 |
| 社区支持 | 活跃 | 活跃 | 活跃 |
二、LangGraph 的主要功能
-
循环与分支逻辑:支持复杂的控制流,包括条件判断和循环结构。
-
多代理协作:允许多个代理共享状态,协同完成任务。
-
持久化机制:自动保存和恢复状态,支持长时间运行的任务。
-
人工干预支持:在关键节点引入人工审核,提高决策质量。
-
流式输出:实时传输生成内容,提升用户体验。
-
与 LangChain 集成:无缝结合 LangChain 和 LangSmith,构建完整的 LLM 应用生态。
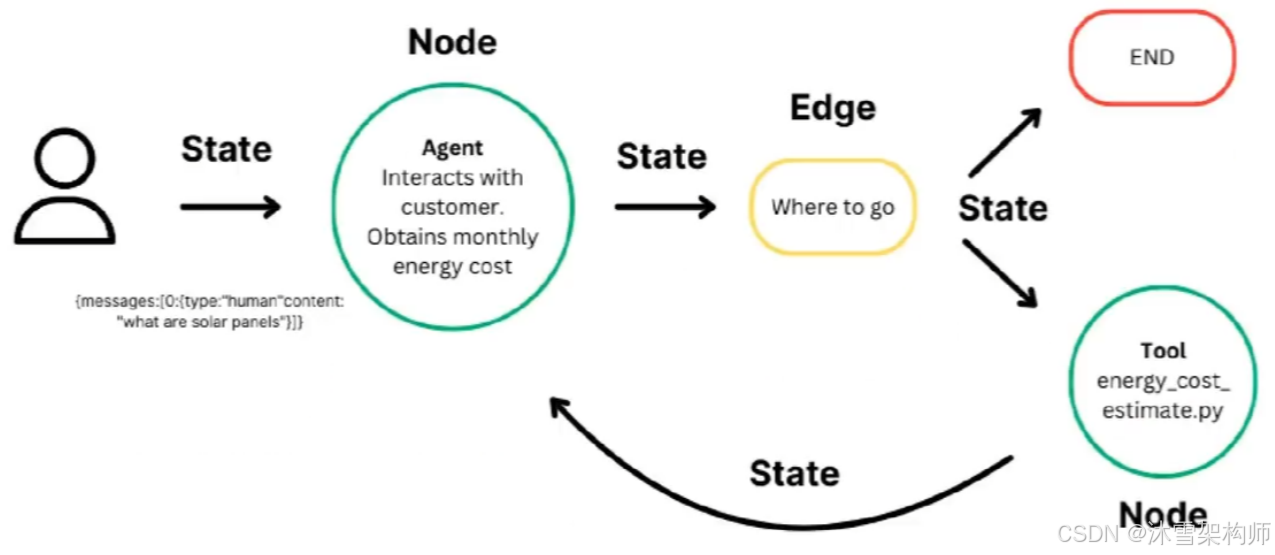
三、Graph图的API概念
LangGraph 的核心是将代理工作流程建模为图表。您可以使用三个关键组件来定义代理的行为:
-
状态:表示应用程序当前快照的共享数据结构。它可以是任何 Python 类型,但通常是
TypedDict或 PydanticBaseModel。 -
节点:用于编码代理逻辑的 Python 函数。它们接收当前值
State作为输入,执行一些计算或副作用,并返回更新后的State。 -
边 :根据当前条件确定下一步执行哪个操作的 Python 函数
State。它们可以是条件分支或固定转换。
通过组合节点(Nodes)和边(Edges),您可以创建复杂的循环工作流,使其State随时间推移而演化。然而,真正的强大之处在于 LangGraph 对 的管理方式State。需要强调的是:Nodes和Edges只不过是 Python 函数而已——它们可以包含 LLM 代码,也可以只是经典的 Python 代码。
简而言之:节点负责工作,边负责告诉下一步做什么。
LangGraph 的底层图算法使用消息传递来定义通用程序。当一个节点完成其操作时,它会沿着一条或多条边向其他节点发送消息。这些接收节点随后执行其函数,将生成的消息传递给下一组节点,并继续执行该过程。受 Google
Pregel系统的启发,该程序以离散的“超级步骤”进行。
超级步骤可以被视为图节点上的单次迭代。并行运行的节点属于同一个超级步骤,而顺序运行的节点则属于不同的超级步骤。
- 图执行开始时,所有节点都处于同一
inactive状态。 - 当节点在其任何传入边(或“通道”)上收到新消息(状态)时,它将变为
active。 - 然后,活动节点运行其函数并进行更新响应。
- 在每个超级步骤结束时,没有传入消息的节点通过将其标记为 inactive 来投票 halt。
- 当所有节点 均为
inactive且没有消息在传输时,图执行终止。
状态图StateGraph
该类StateGraph是要使用的主要图形类。它由用户定义的State对象参数化。
编译你的图表
要构建图,首先要定义状态
,然后添加节点和边,最后进行编译。编译图究竟是什么?为什么需要编译?
编译是一个非常简单的步骤。它会对图的结构进行一些基本检查(例如,没有孤立节点等)。你还可以在其中指定运行时参数,例如检查点和断点。只需调用以下.compile方法即可编译图:
graph = graph_builder.compile(...)您必须先编译您的图表,然后才能使用它。
状态(State)
定义图时,你做的第一件事是定义图的 状态 。 状态 包含图的 模式 以及 归约器函数,它们指定如何将更新应用于状态。 状态 的模式将是图中所有 节点 和 边 的输入模式,可以是 TypedDict 或者
Pydantic 模型。所有 节点 将发出对 状态 的更新,这些更新然后使用指定的 归约器 函数进行应用。
模式(Schema)
指定图模式的主要记录方式是使用TypedDict,也支持使用 Pydantic BaseModel作为图状态,以添加默认值和附加数据验证。
默认情况下,图将具有相同的输入和输出模式。如果您想更改此设置,也可以直接指定显式的输入和输出模式。当您拥有大量键,并且其中一些显式用于输入,另一些用于输出时,这非常有用。
节点(Nodes)
类似于 NetworkX ,您可以使用add_node方法将这些节点添加到图形中。 示例代码如下:
1、创建一个节点
# 从langgraph.graph模块导入START和StateGraph
from langgraph.graph import START, StateGraph
# 定义一个节点函数my_node,接收状态和配置,返回新的状态
def my_node(state, config):
return {"x": state["x"] + 1,"y": state["y"] + 2}
# 创建一个状态图构建器builder,使用字典类型作为状态类型
builder = StateGraph(dict)
# 向构建器中添加节点my_node,节点名称将自动设置为'my_node'
builder.add_node(my_node) # node name will be 'my_node'
# 添加一条边,从START到'my_node'节点
builder.add_edge(START, "my_node")
# 编译状态图,生成可执行的图
graph = builder.compile()
# 调用编译后的图,传入初始状态{"x": 1}
print(graph.invoke({"x": 3,"y":2}))2、创建多节点
#示例:node_case.py
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, START
from langgraph.graph import END
# 初始化 StateGraph,状态类型为字典
graph = StateGraph(dict)
# 定义节点
def my_node(state: dict, config: RunnableConfig):
print("In node: ", config["configurable"]["user_id"])
return {"results": f"Hello, {state['input']}!"}
def my_other_node(state: dict):
return state
# 将节点添加到图中
graph.add_node("my_node", my_node)
graph.add_node("other_node", my_other_node)
# 连接节点以确保它们是可达的
graph.add_edge(START, "my_node")
graph.add_edge("my_node", "other_node")
graph.add_edge("other_node", END)
# 编译图
print(graph.compile())START 节点
from langgraph.graph import START
graph.add_edge(START, "my_node")
graph.add_edge("my_node", "other_node")END 节点
END 节点是一个特殊节点,它代表一个终端节点。当您想要指定哪些边在完成操作后没有动作时,会引用此节点。一个流程通常只有一个开始节点和结束节点。
from langgraph.graph import END
graph.add_edge("other_node", END)边(Edges)
边定义了逻辑如何路由以及图形如何决定停止。这是您的代理如何工作以及不同节点如何相互通信的重要部分。有一些关键类型的边
- 普通边:直接从一个节点到下一个节点。
- 条件边:调用一个函数来确定下一个要转到的节点。
- 入口点:用户输入到达时首先调用的节点。
- 条件入口点:调用一个函数来确定用户输入到达时首先调用的节点。
普通边
如果您总是想从节点 A 到节点 B,您可以直接使用add_edge方法。
graph.add_edge("node_a", "node_b")条件边
如果您想选择性地路由到一个或多个边(或选择性地终止),您可以使用add_conditional_edges方法。此方法接受节点的名称和一个“路由函数”,该函数将在该节点执行后被调用。
graph.add_conditional_edges("node_a", routing_function)类似于节点, routing_function 接受图形的当前 state 并返回一个值。
默认情况下,返回值 routing_function 用作要将状态发送到下一个节点的节点名称(或节点列表)。
所有这些节点将在下一个超级步骤中并行运行。
您可以选择提供一个字典,该字典将 routing_function 的输出映射到下一个节点的名称。
graph.add_conditional_edges("node_a", routing_function, {True: "node_b", False:"node_c"})入口点
from langgraph.graph import START
graph.add_edge(START, "my_node")条件入口点
from langgraph.graph import START
graph.add_conditional_edges(START, routing_function)graph.add_conditional_edges(START, routing_my,{True: "my_node", False: "other_node"})四、多智能体示例代码
LangGraph创建多智能体的示例代码。
1、requirements.txt
aiohappyeyeballs==2.6.1
aiohttp==3.11.18
aiosignal==1.3.2
annotated-types==0.7.0
anyio==4.9.0
attrs==25.3.0
certifi==2025.4.26
charset-normalizer==3.4.2
dataclasses-json==0.6.7
distro==1.9.0
frozenlist==1.6.0
greenlet==3.2.1
h11==0.16.0
httpcore==1.0.9
httpx==0.28.1
httpx-sse==0.4.0
idna==3.10
jiter==0.9.0
jsonpatch==1.33
jsonpointer==3.0.0
langchain==0.3.24
langchain-community==0.3.23
langchain-core==0.3.58
langchain-openai==0.3.16
langchain-text-splitters==0.3.8
langgraph==0.4.1
langgraph-checkpoint==2.0.25
langgraph-prebuilt==0.1.8
langgraph-sdk==0.1.66
langsmith==0.3.41
marshmallow==3.26.1
modelscope==1.25.0
multidict==6.4.3
mypy_extensions==1.1.0
numpy==2.2.5
nvidia-ml-py==12.570.86
nvitop==1.4.2
openai==1.74.0
orjson==3.10.18
ormsgpack==1.9.1
packaging==24.2
pip==25.1
propcache==0.3.1
pydantic==2.11.4
pydantic_core==2.33.2
pydantic-settings==2.9.1
python-dotenv==1.1.0
PyYAML==6.0.2
regex==2024.11.6
requests==2.32.3
requests-toolbelt==1.0.0
setuptools==78.1.1
sniffio==1.3.1
SQLAlchemy==2.0.40
tenacity==9.1.2
tiktoken==0.9.0
tqdm==4.67.1
typing_extensions==4.13.2
typing-inspect==0.9.0
typing-inspection==0.4.0
urllib3==2.4.0
wheel==0.45.1
xxhash==3.5.0
yarl==1.20.0
zstandard==0.23.0
2、核心代码
from typing import Literal, Annotated
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
from langchain_core.pydantic_v1 import BaseModel, Field
import re
import json
# ================== 强化状态类 ==================
class AgentState(BaseModel):
messages: Annotated[list, Field(default_factory=list)]
next_agent: Literal["researcher", "calculator", "writer", "done"] = "researcher"
step_count: int = 0
is_finalized: bool = False
search_data: dict = Field(default_factory=dict) # 新增搜索数据存储
@classmethod
def from_raw(cls, raw):
"""统一状态转换方法"""
if isinstance(raw, cls):
return raw
if isinstance(raw, dict):
return cls(
messages=raw.get('messages', []),
next_agent=raw.get('next_agent', 'researcher'),
step_count=raw.get('step_count', 0),
is_finalized=raw.get('is_finalized', False),
search_data=raw.get('search_data', {})
)
raise ValueError(f"无效状态类型: {type(raw)}")
def to_safe_dict(self):
"""安全转换为字典"""
return {
"messages": [msg.model_dump() for msg in self.messages],
"next_agent": self.next_agent,
"step_count": self.step_count,
"is_finalized": self.is_finalized,
"search_data": self.search_data
}
# ================== 模型配置 ==================
model = ChatOpenAI(
openai_api_base="https://vip.apiyi.com/v1",
model_name="gpt-4o",
openai_api_key="sk-xxxxxxxx",
max_tokens=4096,
temperature=0.2
)
# ================== 核心节点定义 ==================
def create_researcher():
def agent(raw_state):
state = AgentState.from_raw(raw_state)
if state.is_finalized:
return state
try:
# 获取搜索查询
search_query = next(
msg.content for msg in reversed(state.messages)
if isinstance(msg, HumanMessage)
)
messages = convert_messages(state.messages)
response = model.invoke(messages)
print(f"\n[研究员输出] {response.content[:300]}...")
# 解析下一步建议
next_agent = "supervisor"
if match := re.search(r'建议下一步\s*[::]\s*(\w+)', response.content):
suggestion = match.group(1).lower()
if suggestion in {"researcher", "calculator", "writer", "done"}:
next_agent = suggestion
return AgentState(
messages=state.messages + [response],
next_agent=next_agent,
step_count=state.step_count + 1,
is_finalized=False
)
except Exception as e:
print(f"[研究员错误] {str(e)}")
return AgentState(
messages=state.messages,
next_agent="supervisor",
step_count=state.step_count + 1,
is_finalized=True
)
return agent
def create_calculator():
def agent(raw_state):
state = AgentState.from_raw(raw_state)
if state.is_finalized:
return state
try:
messages = convert_messages(state.messages)
messages.append(SystemMessage(
content="请执行GDP增长率计算,需包含完整计算过程和公式,最后用'建议下一步:选项'格式结尾"
))
response = model.invoke(messages)
print(f"\n[计算器输出] {response.content[:200]}...")
return AgentState(
messages=state.messages + [response],
next_agent=re.search(r'建议下一步\s*[::]\s*(\w+)', response.content).group(1).lower(),
step_count=state.step_count + 1,
is_finalized=False
)
except Exception as e:
print(f"[计算器错误] {str(e)}")
return AgentState(
messages=state.messages,
next_agent="supervisor",
step_count=state.step_count + 1,
is_finalized=True
)
return agent
def create_writer():
def agent(raw_state):
state = AgentState.from_raw(raw_state)
if state.is_finalized:
return state
try:
messages = convert_messages(state.messages)
messages.append(SystemMessage(
content="请生成包含[END]标识的最终报告,要求:\n"
"1. 包含数据来源说明\n"
"2. 使用Markdown格式\n"
"3. 最后必须添加[END]标识\n"
"4. 必须引用搜索数据中的具体内容"
))
response = model.invoke(messages)
if "[END]" not in response.content:
response.content += "\n[END]"
return AgentState(
messages=state.messages + [response],
next_agent="done",
step_count=state.step_count + 1,
is_finalized=True
)
except Exception as e:
print(f"[作家错误] {str(e)}")
return AgentState(
messages=state.messages,
next_agent="supervisor",
step_count=state.step_count + 1,
is_finalized=True
)
return agent
# ================== 辅助函数 ==================
def convert_messages(raw_messages):
converted = []
for msg in raw_messages:
if isinstance(msg, dict):
try:
msg_type = {
"user": HumanMessage,
"system": SystemMessage,
"assistant": AIMessage
}[msg["role"]]
converted.append(msg_type(content=msg.get("content", "")))
except KeyError:
converted.append(AIMessage(content=str(msg)))
elif hasattr(msg, 'content'):
converted.append(msg)
else:
converted.append(AIMessage(content=str(msg)))
return converted
# ================== Supervisor节点 ==================
def supervisor(raw_state):
state = AgentState.from_raw(raw_state)
if state.is_finalized:
return state
try:
print(f"\n[Supervisor] 当前步数: {state.step_count}")
# 智能流程控制
if state.step_count >= 8:
print("[强制终止] 达到最大步数限制")
return AgentState(
messages=state.messages,
next_agent="writer",
step_count=state.step_count + 1,
is_finalized=False
)
messages = convert_messages(state.messages)
control_prompt = '''请严格选择下一步:
1. 需要补充数据 → researcher
2. 需要计算 → calculator
3. 生成报告 → writer
4. 完成 → done
注意:必须优先选择需要完成的最关键步骤'''
response = model.invoke(messages + [SystemMessage(content=control_prompt)])
decision = re.search(r'\b(researcher|calculator|writer|done)\b', response.content.lower())
new_agent = decision.group(1).lower() if decision else "done"
# 强制writer前必须存在搜索数据
if new_agent == "writer" and not state.search_data:
new_agent = "researcher"
# 强制done前必须生成报告
if new_agent == "done" and not any("[END]" in msg.content for msg in messages):
new_agent = "writer"
return AgentState(
messages=state.messages,
next_agent=new_agent,
step_count=state.step_count + 1,
is_finalized=False
)
except Exception as e:
print(f"[Supervisor错误] {str(e)}")
return AgentState(
messages=state.messages,
next_agent="writer",
step_count=state.step_count + 1,
is_finalized=False
)
# ================== 工作流配置 ==================
builder = StateGraph(AgentState)
builder.add_node("supervisor", supervisor)
builder.add_node("researcher", create_researcher())
builder.add_node("calculator", create_calculator())
builder.add_node("writer", create_writer())
# 定义条件边
def route_supervisor(state):
return state.next_agent
builder.add_conditional_edges(
"supervisor",
route_supervisor,
{
"researcher": "researcher",
"calculator": "calculator",
"writer": "writer",
"done": END
}
)
# 添加节点到supervisor
for agent in ["researcher", "calculator", "writer"]:
builder.add_edge(agent, "supervisor")
builder.set_entry_point("supervisor")
workflow = builder.compile()
# ================== 执行入口 ==================
if __name__ == "__main__":
try:
initial_state = AgentState(
messages=[HumanMessage(content="成都市2025年GDP增长率分析")]
)
final_report = None
for step in workflow.stream(initial_state):
node_name, raw_state = step.popitem()
current_state = AgentState.from_raw(raw_state)
print(f"\n[系统状态] 当前节点: {node_name}")
print(f"下一步: {current_state.next_agent}")
print(f"步数: {current_state.step_count}")
print(f"完成状态: {current_state.is_finalized}")
# 捕获最终报告
if node_name == "writer":
final_report = next(
(msg.content for msg in reversed(current_state.messages)
if "[END]" in msg.content),
None
)
if current_state.is_finalized or node_name == "__end__":
print("\n====== 流程完成 =====")
if final_report:
print(final_report)
else:
print("警告:未检测到完整报告")
break
except Exception as e:
print(f"\n!!! 流程异常终止: {str(e)}")
if 'current_state' in locals():
print("最后状态:", current_state.to_safe_dict())

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 29
29 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)