
语音处理工具 sox & librosa
参考:https://blog.csdn.net/qq_39516859/article/details/87980189能量增强or衰减sox命令的-v选项可以用来(成倍地)改变音量的大小:sox -v 0.5 foo.wav bar.wav能量增强 or衰减,但不削波sox foo.wav -n stat -v 2> vcsox -v `cat vc` foo.wav foo-maxed
参考:https://blog.csdn.net/qq_39516859/article/details/87980189
载入语音
# 读入的输入是【0,1】之间的float32数据
# 如果sr不声明,默认读取24k,sr=None按照音频实际采样率读取;
# sr=target_sr,采样率不一致的时候会重采样
ldata, sr=librosa.load(wav_path, sr=None)
# 和librosa的结果一模一样,soudfile.read读取的和librosa一样
wave, samp_freq = torchaudio.load(filename, sr=16000)
# scipy读取的是int16的数据
from scipy.io.wavfile import read
sr, data = read(wav_path)
# librosa数据和scipy数据转换,int16的表示范围【-32768,32767】
data = round(ldata*32767)
#soudfile.read读取的和librosa一样
wav, sr = sf.read(wav_path)
sf.write(wav_path, wav, sr)
sox
- 如果没有apt-get,但是有conda,安装方法 conda install -c conda-forge sox
- 能量增强or衰减
sox命令的-v选项可以用来(成倍地)改变音量的大小:
sox -v 0.5 foo.wav bar.wav
- 能量增强 or衰减,但不削波
sox foo.wav -n stat -v 2> vc
sox -v `cat vc` foo.wav foo-maxed.wav
-
查看音频信息
soxi xx.wav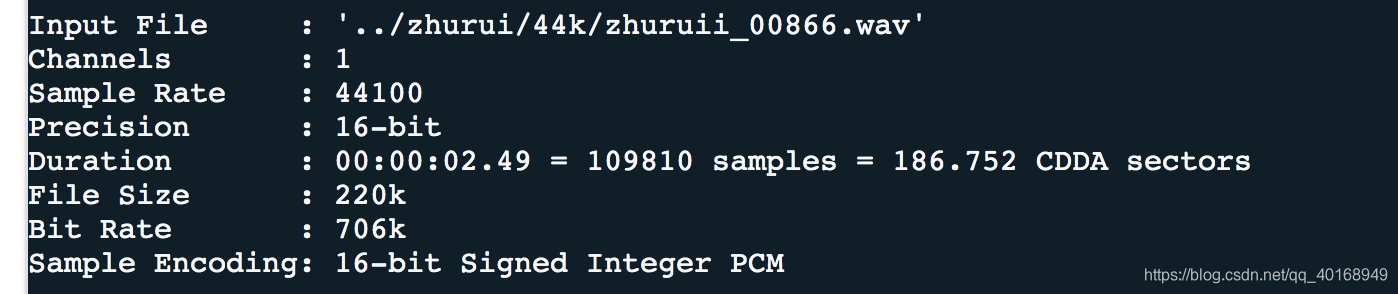
其中bit rate=sample rate*precision*channels=44.1k*16=706k -
修改采样率&通道数
sox src.wav -c 1 -r 16000 tar.wav
- 合成静音片段
sox 命令可以创建静音状态的音频片段,使用 -n 选项表示没有输入,通过 trim 效果指定需要静音的片段。
$ sox -n -r 48000 silence.wav trim 0.0 0.250
在 slience.wav 文件中创建一段长度为 250ms 采样率为 48000Hz 的静音片段。
- 变调–sox变调用的是PSOLA算法
# Transpose input.mp3 1 tone lower and saves it as output.mp3
# pitch 100指的是一个半音(semitone),而不是频率意义的100hz
sox input.mp3 output.mp3 pitch -200
sox input.wav output.wav pitch -200
#Transpose input.mp3 1/2 tone higher and saves it as output.mp3
sox input.mp3 output.mp3 pitch 100
- 变速
tempo只变速不变调
# speed up a song
sox slow.mp3 fast.mp3 tempo 1.6
#speed up a song and prevent clipping by lowering the volume
sox slow.mp3 fast.mp3 vol 0.25 tempo 1.6
// speed会变调
$ sox input.wav output.wav speed 1.3 #速度变为原来的1.3倍
$ sox input.wav output.wav speed 0.8 #速度变为原来的0.8倍
- 拼接多个音频为一个
sox -r 16000 -b 16 -c 1 qa01_*.wav output.wav
- 修改能量到指定范围(+/- 3db)
$SOX -t wav ${wav} -c 1 -e signed-integer -b 16 -t wav -r ${sample_rate} ${target_name} norm -3;
ffmpeg
linux下载安装
安装指定的版本
参考博客:从下载到安装
- 如果有遇到filter不存在的报错,考虑是否是版本太老;新版本安装以后按照教程没有覆盖原来的版本
which ffmpeg #看一下原来的版本在哪里
把新版本的bin文件拷贝到老版本的地址下,再次查看ffmpeg -version即替换成功
- 直接安装
apt-get install ffmpeg
可能会遇到IP not found的问题,apt-get update再次安装就可以了
安装之后,命令栏直接输入ffmpeg,会出现help的使用提示,说明安装成功了
语音变速不变调
ffmpeg -n -i input.wav -filter:a "atempo=0.5" output.wav
atempo是速度比例调整,0.5是慢速一半,1.5是加速一倍
一般加速是丢掉一些信息,听起来还好;慢速0.5,需要滤波器自动补入很多信息,因为看频谱会有类似一条一条的纹路,听起来也有点抖
从视频(flv)格式中抽取音频
参考flv提取音频
ffmpeg -i input.flv -vn -c:a copy output.aac
格式互转
- aac转wav
ffmpeg音频各种格式互转
ffmpeg -i audio.aac audio.wav
- flv转mp4
ffmpeg -i input.flv -vcodec copy -acodec copy output.mp4
- mp4转16k-wav
ffmpeg -i $ID.mp4 -ac 1 -ar 16000 $ID.wav
- m4a转wav
ffmpeg -iinput.m4a -acodec pcm_s16le -ac 2 -ar 44100 output.wav
- 采样率调整
ffmpeg -i in.wav -ar 16000 -ac 1 -f wav out.wav
- pcm转wav
ffmpeg -f s16le -ar 44.1k -ac 2 -i file.pcm file.wav
- 加颤音:vibrato 是一种颤音效果,可以使音符产生轻微的波动,从而使音符更加丰富和生动。
tremolo 是一种颤抖效果,可以使音符的音量产生快速的变化,从而使音符更加有力和感性。
ffmpeg -i 02.wav -af vibrato=f=10:d=0.5 02_v10_05.wav
参考:ffmpeg 音视频转换
soundfile
import soundfile as sf
# 读取
data, sr = sf.read('existing_file.wav') ———读取的也是【0,1】之间的数据
# 写出
sf.write('new_file.ogg', data, sr)
audition
- audition自己录制音频
- 新建音频文件,命名,文件格式;
- 点击下方红色按钮(录制开始),如果没有开始录制,拔下耳机,手动切换一下读入接口

- 开始后可以手动将进度条拨到中间,这样可以重新录制(覆盖原来的内容)
文件编码
-
GL直接恢复的文件是(-1,1)之间的float32数字
-
librosa.load(wav)读取的数据也是float32格式,数值在(-1,1)之间
-
librosa.output.write_wav('01.wav', tar_data.astype(np.float32), sr=16000),librosa写出的数据也必须是在float32格式的,数值可以超出(-1,1)的区间范围,但是听起来会是噪声很大的
保存的wav格式
-
wavfile.write('01.wav', 16000, tar_data.astype(np.int16)) -
ps. 需要现将(-1,1)之间的数值手动转换到 -32,768~32,767 (-215, 215-1)
保存的wav格式
librosa
- 提取基频,librosa给了两种方式,基于yin算法和pyin算法
f0, voiced_flag, voiced_probs = librosa.pyin(y, fmin, fmax, sr=22050, frame_length=2048)
- yin方法,主要存在的问题在于,对于每一帧信号,它只给出一个基音周期的估计值,如果估计时产生了半频错误,那么就很难恢复出正确的值。
- pYin的改进地方在于:对于每一帧,它会挑选出多个峰谷值作为备选点。可以有效避免错误估计的问题。通过HMM对模型来基音轨迹更加平滑。
- 计算时间,同一条语音,yin<<1s, pyin则要3s左右。
- dct filters
librosa.filters.dct在librosa 0.6.0中有效,高级版本中已经换成scipy,比较难单独剥离出filter的参数
dct_filter = librosa.filters.dct(n_filters, input_dim)
dct_filter = librosa.filters.dct(80, 80)
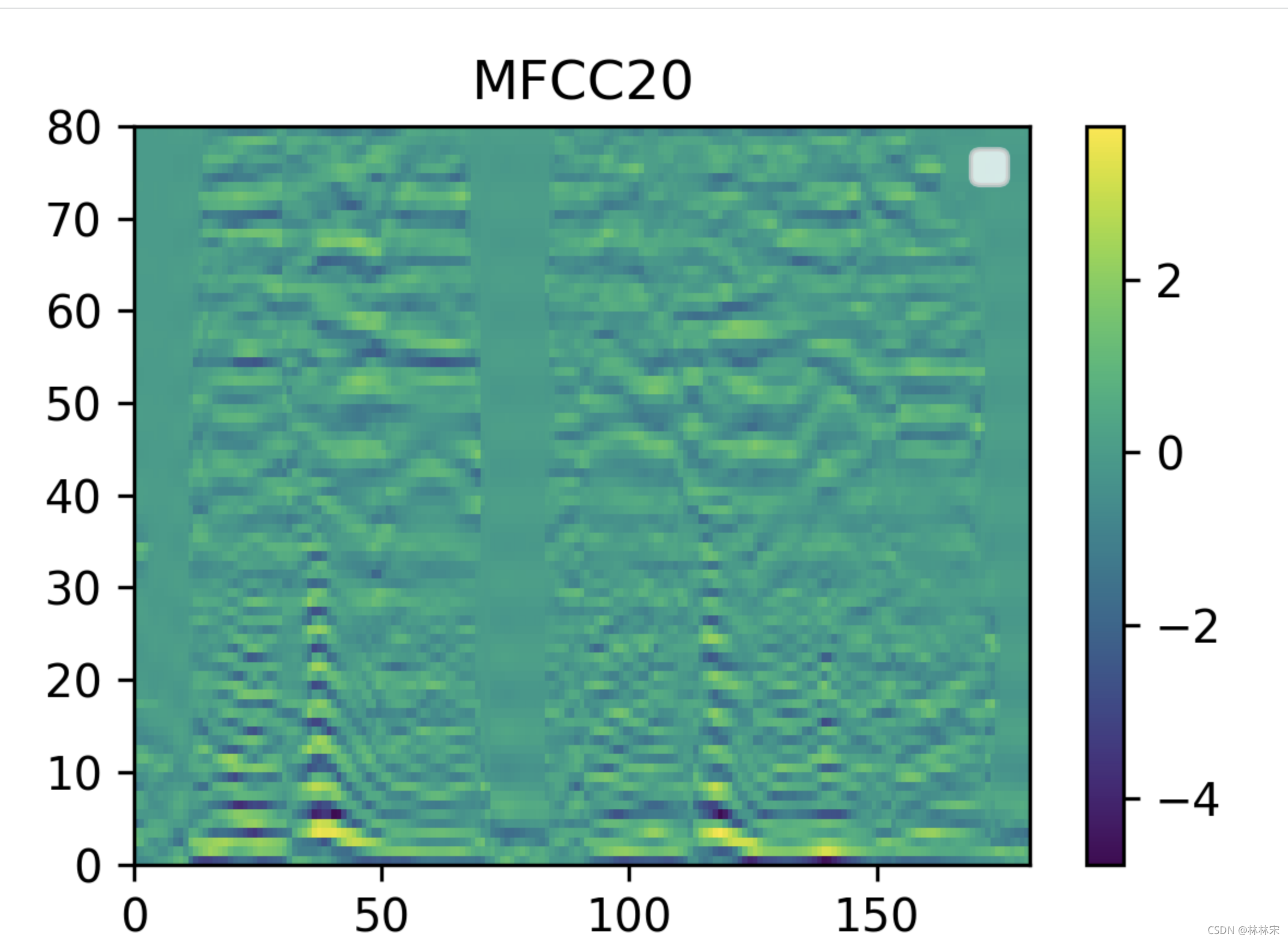
np.dot(mel, dct_filter[:, :20]) ------mfcc20, mel--(t, 80)
- wav2mfcc
y, sr = librosa.load(wav_path, sr=24000)
if sr != 24000:
raise ValueError('%s sr is not 24k'%wav_path)
# librosa 8.0的接口,调用的是scipy.dct
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=80, n_mels=80, n_fft=2048, hop_length=300)
mfcc = np.array(mfcc, np.float32)
mfcc_name = os.path.basename(wav_path).replace('.wav', '.npy')
mfcc_path = os.path.join(save_dir, mfcc_name)
print('mfcc', mfcc.shape())
np.save(mfcc_path, mfcc.T)
- mfcc2wav
- 以下示例为librosa 8.0的接口
mel_data = librosa.feature.inverse.mfcc_to_mel(mfcc) # mfcc: (n_mfcc, T)
wav_data = librosa.feature.inverse.mel_to_audio(mel_data, sr=24000, n_fft=2048)
wav_data = librosa.feature.inverse.mfcc_to_audio(mfcc)
save_path = os.path.join(save_dir, os.path.basename(mfcc_path).replace('.npy', '.wav'))
sf.write(save_path, wav_data, 24000)
- 20维度MFCC恢复为mel80的包络—只有耳语,内容完全保留
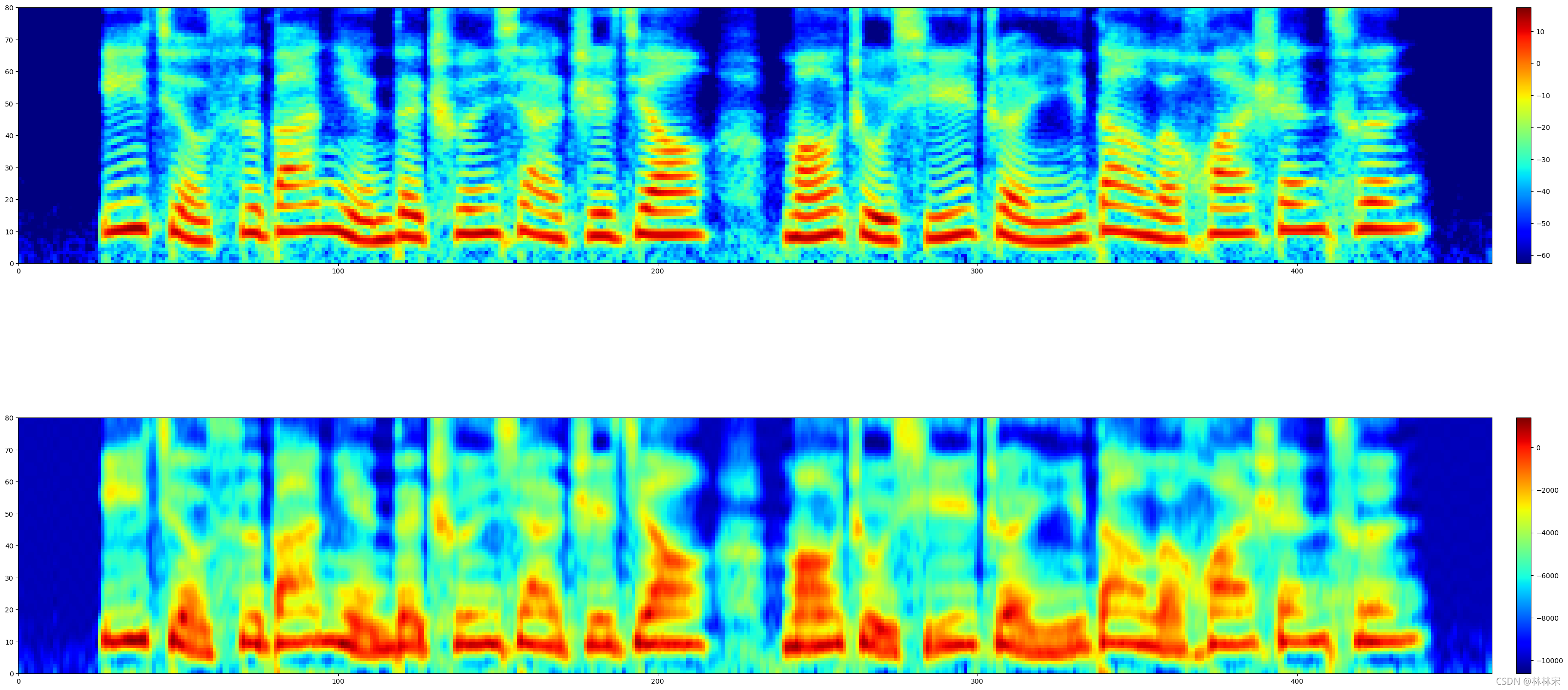
-
高维MFCC恢复为mel:前20维补成0,恢复后有基频线的变化,但是包络明暗信息没有了,内容也无法听懂;
-
-
librosa读文件直接数值是float型;scipy读文件是int型,需要value/32768.0
# 不指定sr,高于22050的被下采样;低于的上采样
wav, sr= librosa.load(wav_path)
# sr=None,读取音频真实的采样率
wav, sr= librosa.load(wav_path, sr=None)
sptk安装
- 安装
1)下载sptk的包
2)安装到/usr/local/bin中
./configure --prefix=/usr/local
3) make && make install
- 检查是否安装成,最下边带有版本号;SPTK: version 3.11
pitch -h
x2x +fa input > output float转可读形式

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)