
离线部署AI大模型—[简单易操作]
1、上传模型gguf文件到 /opt 目录,同时在/opt 下新建ollama、models两个目录,分别用于存放ollama-linux-amd64.tgz安装包、及后面模型运行起来后存放的模型文件。2、根据显卡选择合适的模型,RTX3080显存12G,RTX3090显存24G,下面我列举的Deepseek所需配置,Qwen3跟这差不多。:这里下载后,大家可以通过压缩工具打开,看看里面的内容,里
离线部署AI大模型—[简单易操作]
前置条件
1、部署大模型,需要服务器安装好显卡驱动,可以通过nvidia-smi 命令进行查看。
nvidia-smi
2、根据显卡选择合适的模型,RTX3080显存12G,RTX3090显存24G,下面我列举的Deepseek所需配置,Qwen3跟这差不多。
| 模型版本 | 显存大小 |
|---|---|
| 1.5B | 不需要显卡 |
| 7-8B | 8G |
| 14B | 16G |
| 30B | 24G |
| 70B | 多卡并行80G 以上 |
``
一、准备Ollama和模型文件
1、Ollama下载有三种方式,具体可以参考这个文章https://blog.csdn.net/anningyue/article/details/145484113
2、这里演示离线下载,需TZ访问下面网址下载https://github.com/ollama/ollama/releases
(ps1:这里下载后,大家可以通过压缩工具打开,看看里面的内容,里面会有bin 和lib 两个目录,bin下面有ollama可执行文件)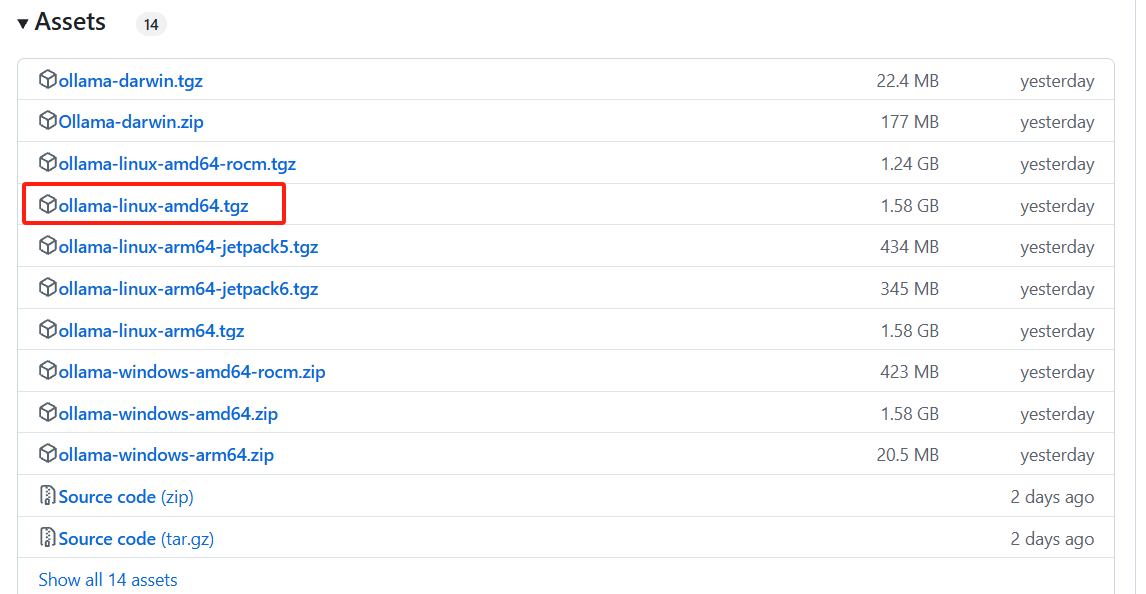
3、下载模型文件
-
访问网址
https://hf-mirror.com/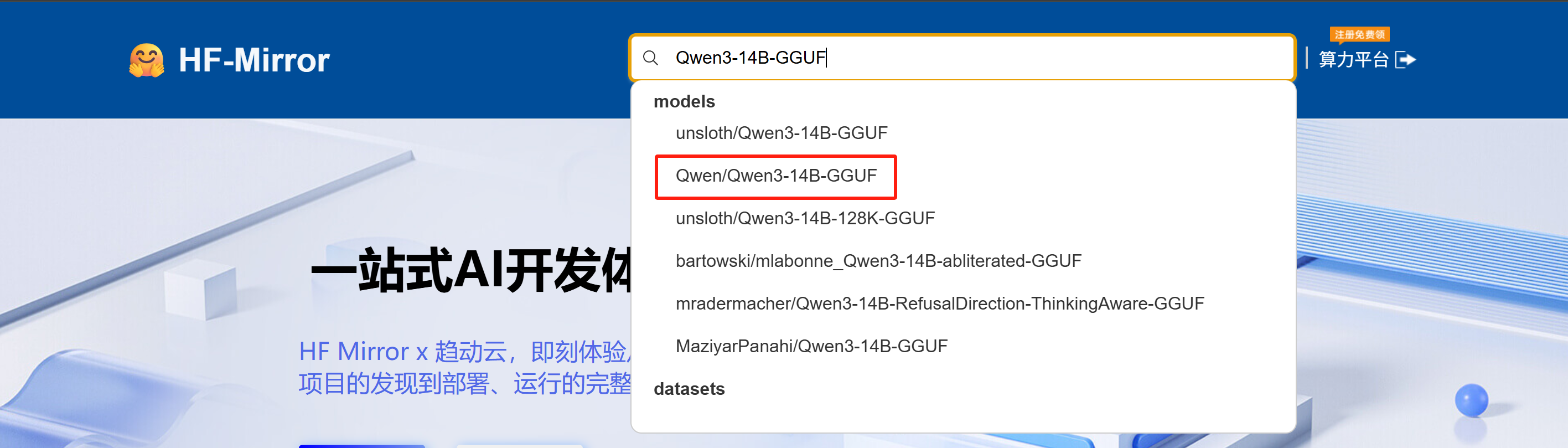
-
下载
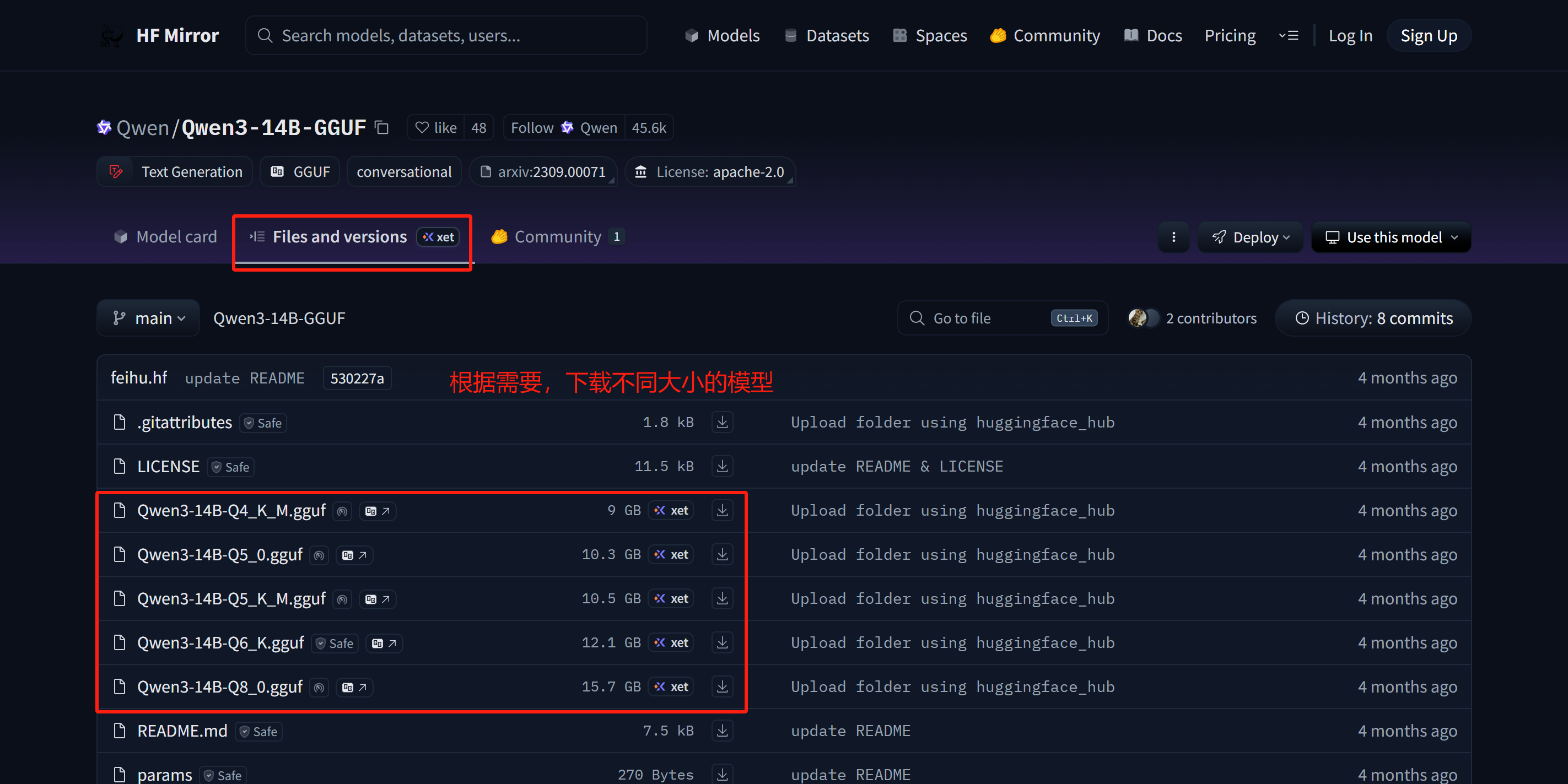
4、这里演示使用Qwen3:14Bhttps://hf-mirror.com/Qwen/Qwen3-14B-GGUF/resolve/main/Qwen3-14B-Q4_K_M.gguf
``
二、部署Ollama
1、上传模型gguf文件到 /opt 目录,同时在/opt 下新建ollama、models两个目录,分别用于存放ollama-linux-amd64.tgz安装包、及后面模型运行起来后存放的模型文件
2、进入到 /opt/ollama 目录, 使用命令进行解压
sudo tar -C /usr -xzf ollama-linux-amd64.tgz
(ps2:这里的解压命令,是将压缩包中可执行文件ollama (详见ps1),放到/usr/bin/ 下面)
3、新增 / 编辑配置文件vim /etc/systemd/system/ollama.service
添加以下内容
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=root ##填运行ollama的用户,可新建专门用户,这里简化直接root
Group=root ##用户的分组,直接root
Restart=always
RestartSec=3
Environment="PATH=$PATH"
Environment="OLLAMA_MODELS=/opt/models" ##路径填写模型运行起来后存放的位置(与步骤1中新建的models目录位置对应上)
Environment="CUDA_VISIBLE_DEVICES=0,1,2"
##CUDA_VISIBLE_DEVICES填写Ollam运行起来后调用的GPU资源,序号从0开始,只有一张卡则只填写0
Environment="OLLAMA_HOST=0.0.0.0:11434" ##配置后局域网内可通过IP调用ollama的API
##GPU负载均衡和模型常驻配置,用于有多张显卡时负载GPU资源
Environment="OLLAMA_SCHED_SPREAD=1"
Environment="OLLAMA_KEEP_ALIVE=-1"
[Install]
WantedBy=default.target
4、重新加载ollama.service配置文件,启动ollama,并查看服务状态
systemctl daemon-reload
systemctl start ollama
systemctl status ollama
服务状态 active (running) 即为正常
``
三、通过Ollama启动模型
1、在 /opt 目录下 (与模型gguf文件同级),创建modelfile文件并编辑
touch modelfile && vi modelfile
添加以下内容
FROM ./Qwen3-14b.gguf ##改成gguf模型文件名称
2、启动模型并查看
ollama create <取名:qwen14b> -f modelfile
通过ollama lis 可以查看启动模型
``
四、测试运行
ollama run <模型名称> “请写一个java脚本”
这里可另开窗口,使用nvidia-smi 命令查看GPU使用情况
⚠️前面ollama.service配置文件中,已经配置了ollama的环境变量,只要在局域网内,大家可以通过可视化工具,直接调用API使用
客户端调用工具推荐chatbox,LMstudio等。如果想用浏览器调用API来使用,可以用open-webui

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)