
百度百科数据爬取及内容分类识别
最近在学习知识图谱相关内容,需要爬取一些结构化的数据。下面介绍如何爬取百度百科的数据并提取出有效数据代码实现。
·
前言
最近在学习知识图谱相关内容,需要爬取一些结构化的数据。下面介绍如何爬取百度百科的数据并提取出有效数据代码实现。
一、分析页面结构
页面可以分为5个区域,如下图标注所示(聚丙烯介绍的页面结构)。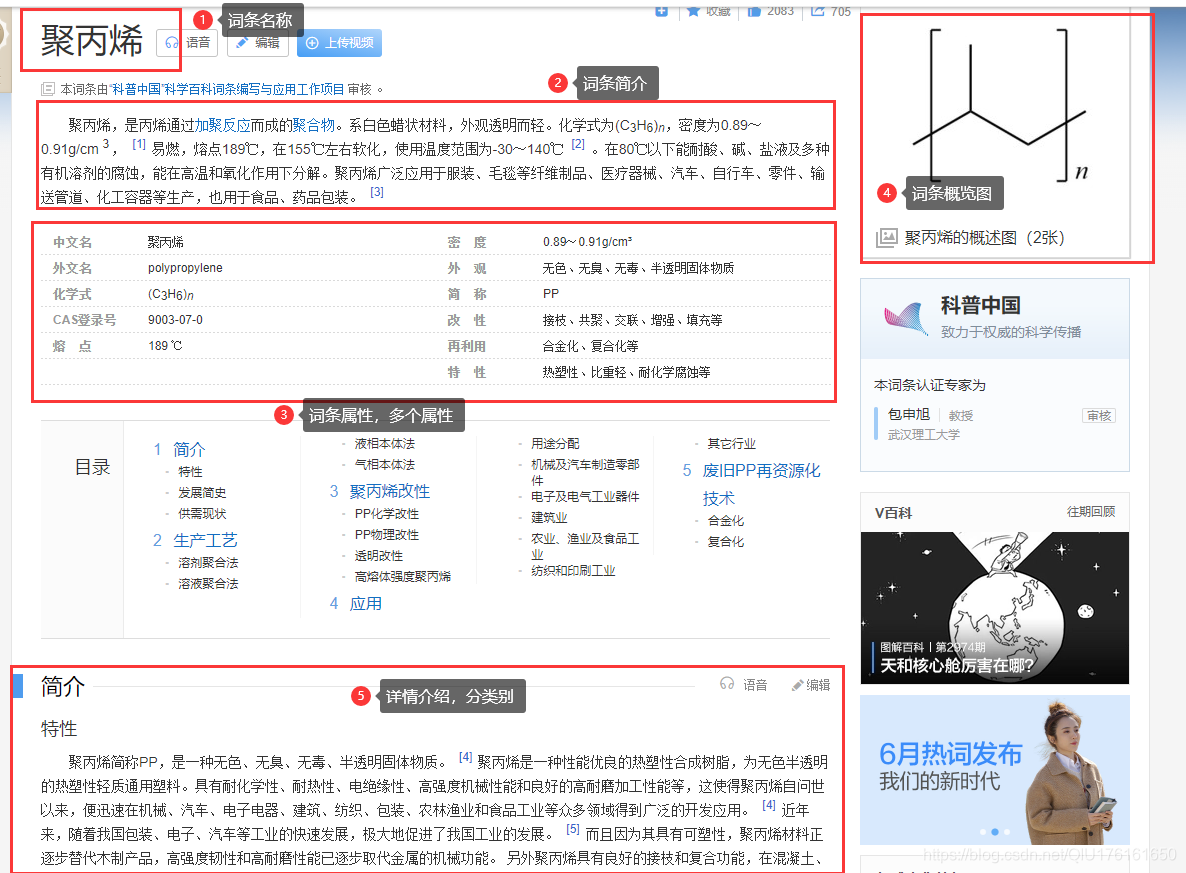
https://baike.baidu.com/wikitag/taglist?tagId=76613
二、使用步骤
1.引入库
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2.读入数据
代码如下(示例):
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())
该处使用的url网络请求的数据。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)