
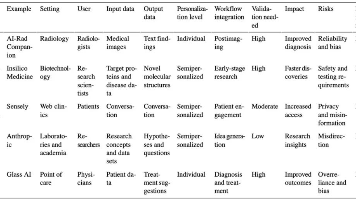
Matlab字符识别实验
字符识别OCR实验
Matlab 字符识别OCR实验
图像来源于屏幕截图,要求黑底白字。数据来源是任意二进制文件,内容以16进制打印输出,'0-9a-f’字符被16个可打印字符替代,这些替代字符经过挑选,使其相对容易被识别。
第一步进行行分割和字符分割。因来源于屏幕截图,所以横平竖直。首先灰度图放大2倍并被二值化,然后在X(W)方向上像素投影求和,这样可以确定行分割精确位置,取多条线(20条)的子图,在Y(H)方向上进行像素投影求和,可大体确定字符间分割位置,在字符切割过程中,针对不同字符在此基础上可做左右精细调整。
第二步逐行逐字符模式匹配识别。对切割出的字符,在16个字符模板中进行匹配,取相似度最高的作为识别结果。匹配可采用二维模板匹配。这里出于效率考虑,用X和Y方向像素投影求和曲线作为字符特征,和切割字符的曲线进行比较,识别率几乎100%。曲线比较逻辑: 首先曲线归一化和对齐,然后用两条曲线的SAD做相似度度量,数值越小相似度越高

细节
SAD做相似度度量,受图像采集等因素影响,鲁棒性不强。通过训练一个浅层神经网络做识别,准确率100%,神奇!应该是特征向量选得好! 随机生成二进制数据
dd if=/dev/random of=data.bin bs=1 count=1M
截取52行输出图片,每行包含200个HEX替换后字符,总计10400个样本库,用patternnet训练分类网络(64个隐含神经元,16个类型),得到网络模型进行识别!
识别效率: 错误来源主要是采集图像质量问题,比如黑白图上有鼠标亮点,丢帧等。实验中最好结果是总数据44万行(每行200个字符), 识别错误的不到300行!(多数错误是因为S和Z混淆,暂时没找到更合适的字符替代其一;R和M偶尔也混淆)

字符模板和XY方向特征曲线示例
16个字符模板
Y(H)方向像素求和特征曲线
X(W)方向像素求和特征曲线


技术共进,成长同行——讯飞AI开发者社区
更多推荐
 7
7 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)