
Python自动化小技巧26——百度云OCR识别文档格式转化(批量将图片自动转为表格)
百度云OCR识别文档格式转化,request请求就行,使用简洁,可以批量将图片自动转为表格
背景
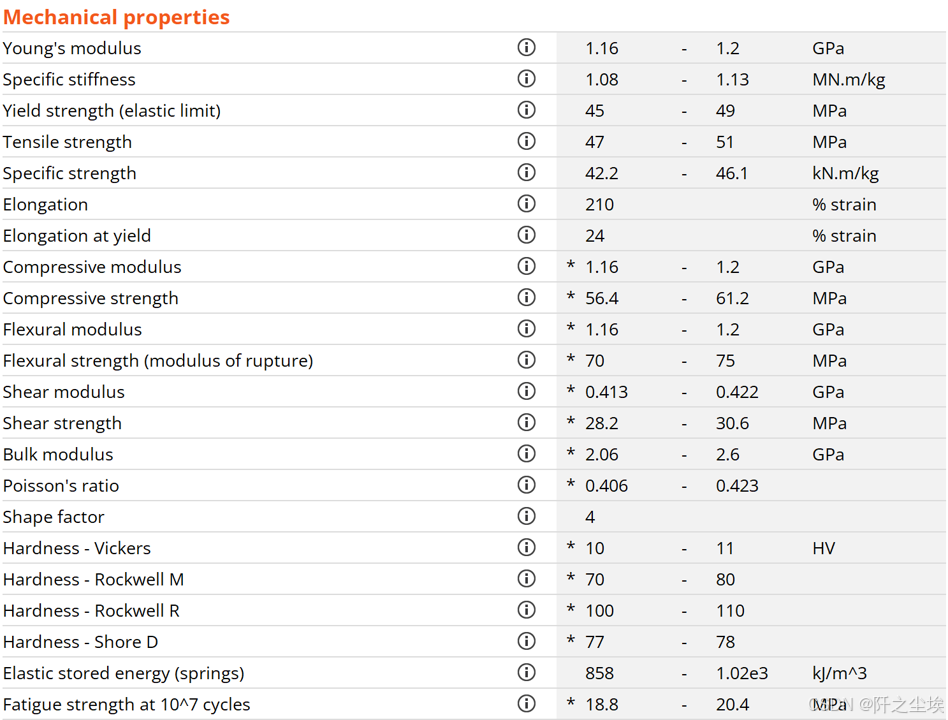
很多时候我们要做OCR的识别,无论是手写或者是一些截图转为文档表格,其实很多内置的python包是没有办法做到很好的效果,但是百度云的OCR服务其实还是效果不错的,并且接口也很简单,不需要下载第三方包request请求就可以了。本次案例教大家怎么把一张类似于下面这样的图片转化为excel表格,这样就实现自动化办公提取表格信息。
百度云准备
虽然百度的AI做的不咋地,但是其这些其他的,例如文字图片语音地图等服务接口还是有的很不错的,付费还是有付费的道理。
这个是他们办公文档识别的地址:办公文档识别-百度智能云,新人应该有一些免费的使用量可以领取。并且他有很多API的教程以及傻瓜式的使用界面可以体验一下。
我们登录到百度云的官网,注册好账号之后,创建一个应用
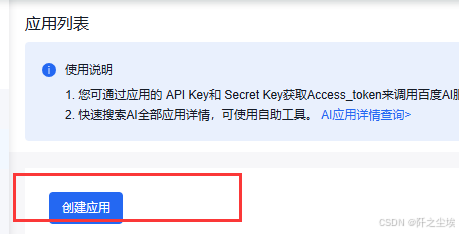
然后里面填一些你这个应用的基础信息,选择你需要的服务就可以了,注意你对应的服务一定要有使用量,这个可以付费,也有一些免费的额度可以领取,可以自己多看看活动。
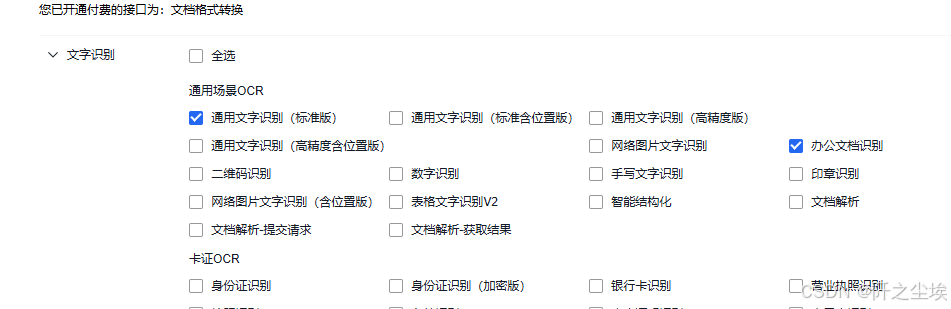
我们本次主要是办公文档的识别,也就是将图片转为表格,所以我们就选这个服务,这个里面它还有很多其他的服务,可以根据自己的场景选择需要的服务以及去购买调用量。
创建好应用之后,我们需要获取这个应用的API key跟secret_key,这两个在代码里面都会传入,很关键,也不要泄露给别人。我下面代码里面会把我自己的这两个key给打进行打码。
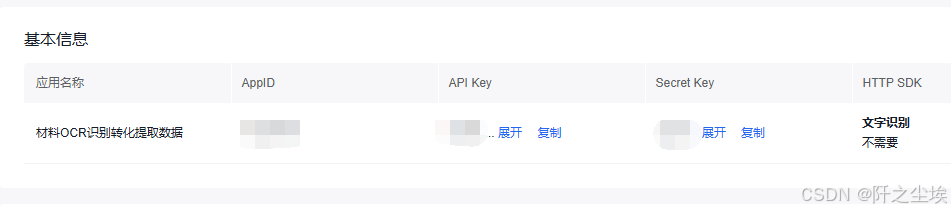
准备好之后,下面就可以开始写代码进行测试了。
代码实现
首先导入包
import requests,json
import base64
import os,time
import pandas as pd将自己的API key和secret key给定义一下。
## API_keys
API_KEY = "H*****************6"
SECRET_KEY = "c**********************v"我这里打码了,大家要用的话填自己的。
然后我们可以根据这两个key获取一个定义接口参数,获取access_token
### 初始化定义接口参数
def get_access_token():
"""
使用 AK,SK 生成鉴权签名(Access Token)
:return: access_token,或是None(如果错误)
"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {"grant_type": "client_credentials", "client_id": API_KEY, "client_secret": SECRET_KEY}
return str(requests.post(url, params=params).json().get("access_token"))
access_token=get_access_token()这都是使用百度的云服务的必要的常备操作。
接下来这个函数就是定义将这个图片进行发送请求,并且返回请求结果的目标的ID。
def submit_request(image_path, access_token):
request_host = "https://aip.baidubce.com/rest/2.0/ocr/v1/doc_convert/request"
with open(image_path, 'rb') as f:
img = base64.b64encode(f.read())
params = {"image": img}
request_url = request_host + "?access_token=" + access_token
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, headers=headers, data=params)
if response:
response_data = response.json()
if response_data.get('success'):
print("提交请求成功:", response_data)
return response_data['result']['task_id']
else:
print("提交请求失败:", response_data)
return None因为百度的这个服务是异步的,你请求之后并不能立刻回到结果,你只能先请求,请求他会给你生成一个任务的ID,然后你再根据这个任务的ID过几秒去从里面捞结果。
所以我们上面这个函数就是在你传入图片文件路径和准入的接口参数access_token后给你返回这个目标的ID。
当然我这里也加了一些容错机制,如果请求提交失败的话就返回None。
接下来是定义了一个下载的函数,这个函数我写的有点复杂,分成了三个小函数,其主要功能就是检查这个请求是否成功,还有因为这个目标会返回excel跟word的两种文件格式,我会先判断,如果返回的文档里面有excel就下载excel,没有excel就下载word,然后最后拿着我们上面生成的任务ID去请求返回结果,对这个结果的获取并且保存下载。
(当然大家想返回的excel跟word都需要的话,可以改一下我这个代码,把这个条件判断给关掉。改为都下载就可以了)
# 下载文件并保存
def download_file(url, file_name): #检查请求是否成功
response = requests.get(url)
if response.status_code == 200:
with open(file_name, 'wb') as f:
f.write(response.content)
print(f"文件已成功下载并保存为: {file_name}")
else:
print(f"文件下载失败,状态码: {response.status_code}")
def download_files(result_data, save_file_path): #判断存储文件类型 ,先excel后word
base_name = os.path.splitext(os.path.basename(save_file_path))[0]
directory = os.path.dirname(save_file_path)
# 检查并下载 Excel 文件
excel_url = result_data.get('excel')
if excel_url:
download_file(excel_url, os.path.join(directory, base_name + '.xlsx'))
else:
# 如果没有 Excel 文件,检查并下载 Word 文件
word_url = result_data.get('word')
if word_url:
download_file(word_url, os.path.join(directory, base_name + '.docx'))
# 获取结果并下载文件
def get_result_and_download(task_id, access_token, save_file_path):
request_host = "https://aip.baidubce.com/rest/2.0/ocr/v1/doc_convert/get_request_result"
params = {"task_id": task_id}
request_url = request_host + "?access_token=" + access_token
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, headers=headers, data=params)
if response:
response_data = response.json()
if response_data.get('success'):
print("获取结果成功:", response_data)
result_data = response_data['result']['result_data']
# 下载文件到与原始文件相同的目录
download_files(result_data, save_file_path)
return result_data
else:
print("获取结果失败:", response_data)
return None下面我们开始调用,我们将刚刚最上面的那个演示的案例放在要处理的图片这个文件夹里面,就是这个图片:
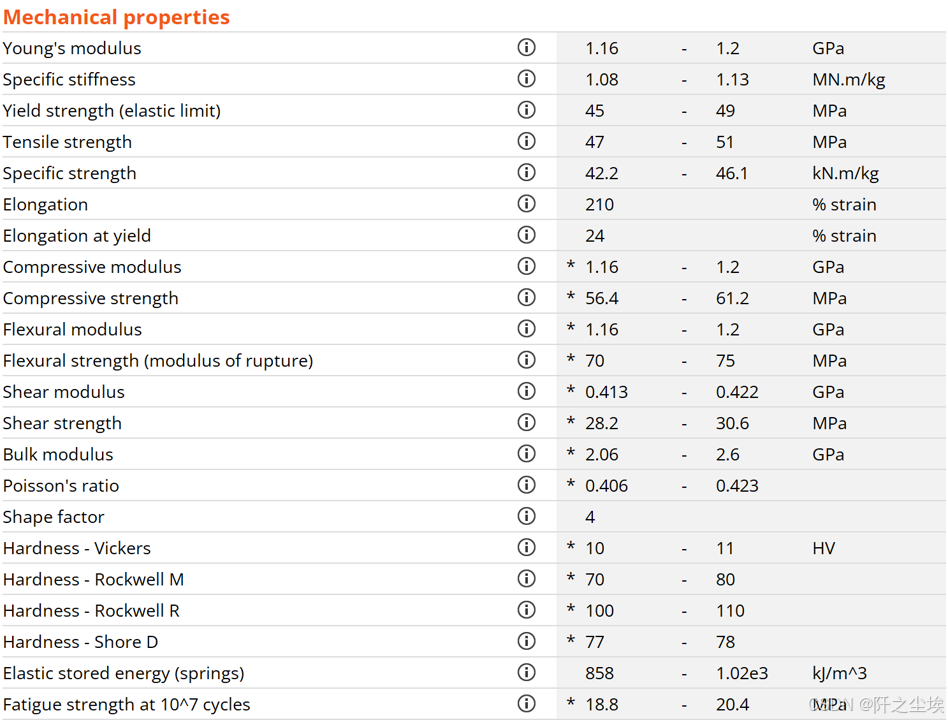
然后我直接这样下面代码运行就可以。会在和图片的同一个文件夹下生成一个对应同名称的excel表,里面就装着这个图片里面所有的数据。
#单个例调用
image_path = './要处理的图片/4.png' # 图片路径
task_id = submit_request(image_path, access_token)
if task_id:
time.sleep(5)
get_result_and_download(task_id, access_token, image_path)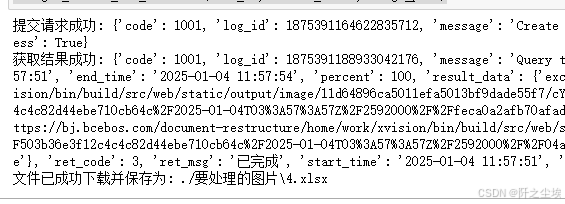
生成的结果是:
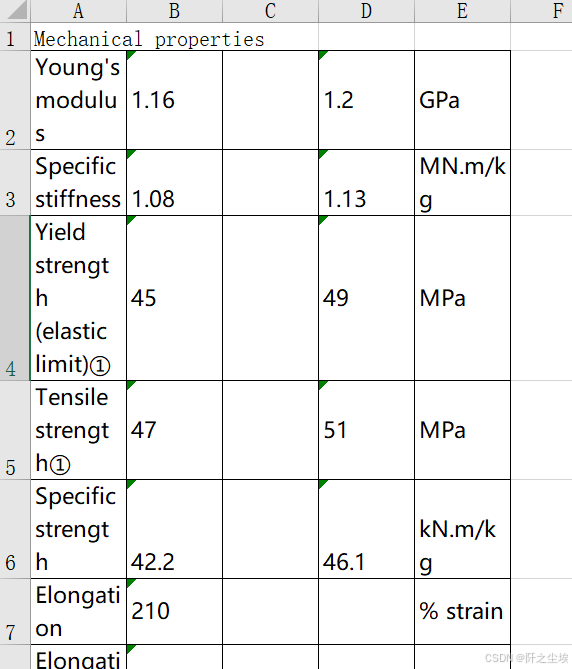
怎么样?我觉得效果非常棒,其表格格式还有字母的识别都是挺正确的。虽然它看起来高,宽长度不均匀,并且框线什么的也不是很标准,但是这些都是可以用python的excel的库进行后期调整的。
这可比那些免费的包效果好多了,那些包完全识别不了这些表格的位置,要么就是识别到一起,要么就是位置错乱。这个百度的云服务能够把所有的表格相对的位置识别正确就很完美了,有一些细小的错误或者格式上的问题,我们后期都可以用代码进行批量化的调整。
批量调用
上面只是演示了一个图片的调用,现实生活中要自动化办公肯定不会处理一个表格,我们要处理一个文件夹里面很多个表格,而有时候这些文件夹里面的表格还是嵌套的,有的文件夹里面会有多个文件夹,每个文件夹下面也有可能有多个文件夹,每个文件夹下面又会有多种图片,这种格式,所以我们要先写一个函数返回该文件夹下面里面所有的图片的路径。
## 文件夹批量调用
def get_all_file_paths(directory):
file_paths = [] # 用于存储所有文件的路径
image_extensions = ['.jpg', '.jpeg', '.png', '.gif', '.bmp', '.tiff'] # 常见图片的后缀名
for dirpath, dirnames, filenames in os.walk(directory):
for filename in filenames:
# 获取文件的扩展名
_, ext = os.path.splitext(filename)
# 判断扩展名是否在常见图片后缀列表中
if ext.lower() in image_extensions:
file_paths.append(os.path.join(dirpath, filename)) # 拼接得到完整的文件路径
return file_paths
# 示例使用
directory_path = '.\\要处理的图片\\'
file_paths = get_all_file_paths(directory_path)
len(file_paths)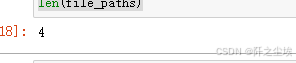
由于是演示,所以说我就没有放那么多的案例,该文件夹里面就放了4个图片。
打印看看
for original_file_path in file_paths:
# 获取文件名(不带扩展名)
base_name11 = os.path.splitext(os.path.basename(original_file_path))[0]
# 获取文件所在的目录路径
directory11 = os.path.dirname(original_file_path)
print(f"File Name: {base_name11}, Directory: {directory11}")
接下来再定义一个主函数,来遍历上面那个函数返回的所有的图片文件路径,然后对他们同目录下去生成和图片同名的,识别之后的表格。
task_id_list=[]
# 主函数来处理文件
def process_files(file_paths, access_token):
records = [] # 用于存储成功处理的文件记录
failed_files = [] # 用于存储处理失败的文件路径
for png in file_paths:
try:
task_id = submit_request(png, access_token)
if task_id:
task_id_list.append(task_id)
time.sleep(5)
# 尝试获取结果并下载
result_data = get_result_and_download(task_id, access_token, png)
print(f"{png}完成{'='*50}")
# 将成功处理的记录添加到列表中
records.append({ 'png': png, 'task_id': task_id, 'result_data': result_data })
except Exception as e:
# 处理异常并记录失败的文件路径
print(f"处理 {png} 时发生错误: {e},跳过该文件。")
failed_files.append(png)
# 创建数据框
df = pd.DataFrame(records)
return df, failed_files # 返回成功的数据框和失败的文件列表然后我们调用就行了
df ,failed_files = process_files(file_paths, access_token)
df.shape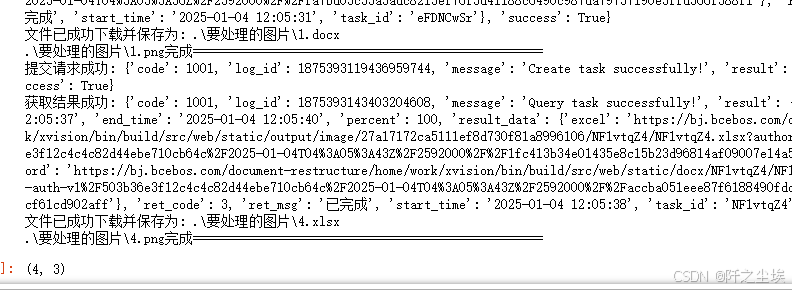
非常方便,有木有,全程我们只需要传入图片的文件夹的路径以及access token就可以了。
然后就会在图片里面的相同目录里面生成对应的这个图片的所有的表格或者是word。
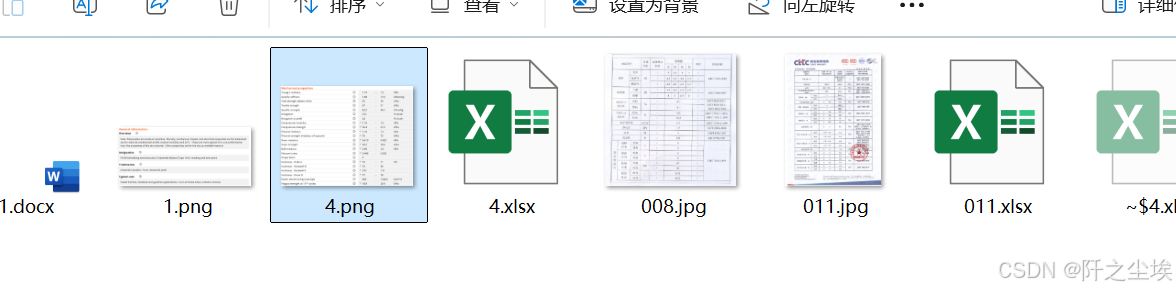
当然最后这个主函数会返回一个df里面就是我们所有的调用记录的缓存日志,我将这个保存下来主要是防止中间程序运行错误或者是其他因素中断之后,可以再次用这个任务的ID去请求结果。不用再去浪费自己的调用量,再去请求一遍。
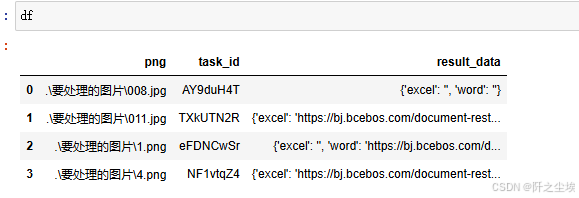
最后这一列result data其实里面就是对应的这个图片的Excel和word的下载地址,可以看到有的图片是没有返回任何的excel或者word的,也就是说这个服务它是没有办法把这个图片转化为表格或者是文档的。有的是返回不了表格但会返回word,有的是都返回。这个根据自己实际情况需要看返回什么,然后再取什么吧。
储存日志:
df.to_excel('调用记录缓存.xlsx',index=False)留下日志就是方便自己以后可以直接从这个结果里面获取下载,不用再去请求浪费调用量了。
图片大小检查
这里附赠一个图片大小检查的函数,因为我们发现OCR服务并不是能够识别所有的图片的,图片尺寸超过一定大小,可能就会没有办法使用这个服务,所以我们可以定义一个检查大小的函数。
# from PIL import Image
# def check_image_size(image_path):
# with Image.open(image_path) as img:
# width, height = img.size
# print(f"Image size: {width}x{height} pixels")
# if 15 <= width <= 4096 and 15 <= height <= 4096:
# print("Image size is within the acceptable range.")
# else:
# print("Image size is out of the acceptable range.")
# # 示例使用
# image_path = './材料1/11.jpg'
# check_image_size(image_path)可以根据这个来判断自己的图片是不是能使用这个服务。
展望
OCR这个文档转化只是一个很小的应用场景,它还有很多图片识别文字识别或者是一些通用的卡证,票据识别

这些都可以用于自己的业务场景进行测试,然后自动配置一个脚本到自己的工作流中,能够极大的提高工作效率。
小型的开发者可以自己用pyinstaller打包脚本成一个exe可执行程序,双击就能够将指定目录里面的所有图片都转为表格,不需要python环境,是非常方便的。
当然要注意使用量,其实这个通用文字识别的还是挺便宜的,但是这个文档还是有点贵,大概是1毛8一条。希望百度以后能出更多的活动,更便宜一些。
我后面也会再测试百度的其他的语音服务能力,比如图片识别,语音识别,地图地址等。有应用场景的话应该能够极大的提高工作效率。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 15
15 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)