
[LLM] 自然语言处理 --- 1.Attention
目录Attention简介Encoder-Decoder框架Attention模型Attention 的优点Attention 不同类型1. 计算区域2. 所用信息3. 结构层次4. 模型方面5. 相似度计算方式Attention详细介绍Soft Attention 模型图解Attention机制第一步:准备隐藏状态第二步:获取每个编...
目录
一 Attention简介
Attention 机制最早是在计算机视觉里应用的,随后在 NLP 领域也开始应用了,真正发扬光大是在 NLP 领域,因为 2018 年 BERT 和 GPT 的效果出奇的好,进而走红。而 Transformer 和 Attention 这些核心开始被大家重点关注。
如果用图来表达 Attention 的位置大致是下面的样子:
注意力模型(Attention Model)是深度学习领域最受瞩目的新星,用来处理与序列相关的数据,特别是2017年Google提出后,模型成效、复杂度又取得了更大的进展。以金融业为例,客户的行为代表一连串的序列,但要从串行化的客户历程数据去萃取信息是非常困难的,如果能够将self-attention的概念应用在客户历程并拆解分析,就能探索客户潜在行为背后无限的商机。
本文解释在机器翻译的领域中,是如何从Seq2seq演进至Attention model 再至self attention
为此,系列文分为两篇,第一篇着重在解释Seq2seq、Attention模型,第二篇重点摆在self attention,希望大家看完后能有所收获。
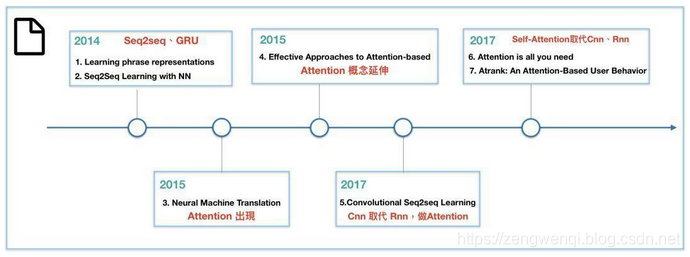
2015年 ICLR 《Neural machine translation by jointly learning to align and translate》首次提出 attention(基本上算是公认的首次提出),文章提出了最经典的 Attention 结构(additive attention 或者 又叫 bahdanau attention)用于机器翻译,并形象直观地展示了 attention 带来源语目标语的对齐效果,解释深度模型到底学到了什么。
2015年 EMNLP 《Effective Approaches to Attention-based Neural Machine Translation》在基础 attention 上开始研究一些变化操作,尝试不同的 score-function,不同的 alignment-function。文章中使用的 Attention(multiplicative attention 或者 又叫 Luong attention)结构也被广泛应用。
2015年 ICML 《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》是 attention(提出hard/soft attention的概念)在 image caption 上的应用,故事圆满,符合直觉。
在上面几篇奠基之作之上,2016和2017年 attention 开枝散叶,无往不利。Hiearchical Attention,Attention over Attention,multi-step Attention……这些或叫得上名的或叫不上名。
2017年-至今是属于 transformer 的时代。基于 transformer 强大的表示学习能力,NLP 领域爆发了新一轮的活力,BERT、GPT 领跑各项 NLP 任务效果。奠基之作无疑是:2017年 NIPS《Attention is all you need》提出 transformer 的结构(涉及 self-attention,multi-head attention)。基于 transformer 的网络可全部替代sequence-aligned 的循环网络,实现 RNN 不能实现的并行化,并且使得长距离的语义依赖与表达更加准确(据说2019年的 transformer-xl《Transformer-XL:Attentive Lanuage Models Beyond a fixed-length context》通过片段级循环机制结合相对位置编码策略可以捕获更长的依赖关系)。
1. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
地址:https://arxiv.org/abs/1502.03044v1
文章提出了两种attention模式,即hard attention 和soft attention
2. Effective Approaches to Attention-based Neural Machine Translation
地址:https://arxiv.org/abs/1508.04025
文章提出了两种attention的改进版本,即global attention和local attention。
二 Encoder-Decoder框架
要了解深度学习中的注意力模型,就不得不先谈Encoder-Decoder框架(Sequence-to-sequence),因为目前大多数注意力模型附着在Encoder-Decoder框架下,最直观的就是机器翻译,一句英文翻译成一句中文。或者应答,问一句答一句。
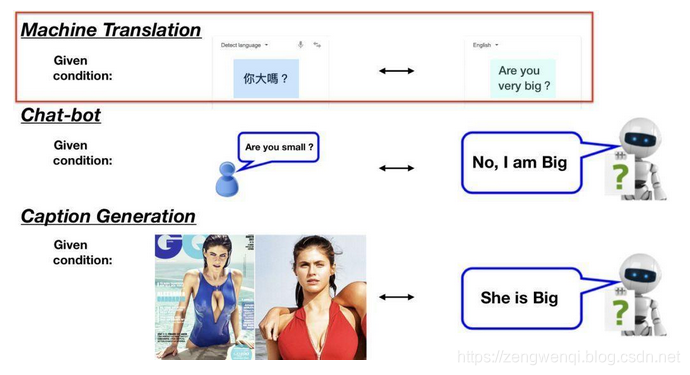
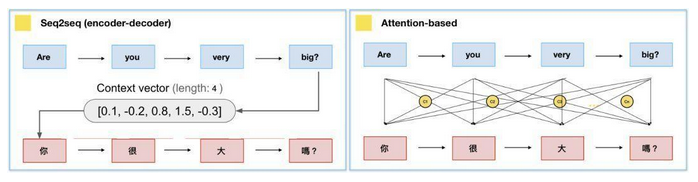
你可能很常听到Seq2seq这词,却不明白是什么意思。Seq2seq全名是Sequence-to-sequence,也就是从序列到序列的过程,是近年当红的模型之一。Seq2seq被广泛应用在机器翻译、聊天机器人甚至是图像生成文字等情境。如下图:
其实注意力模型可以看作一种通用的思想,本身并不依赖于特定框架,这点需要注意。Encoder-Decoder框架可以看作是一种深度学习领域的研究模式,应用场景异常广泛。图2是文本处理领域里常用的Encoder-Decoder框架最抽象的一种表示。
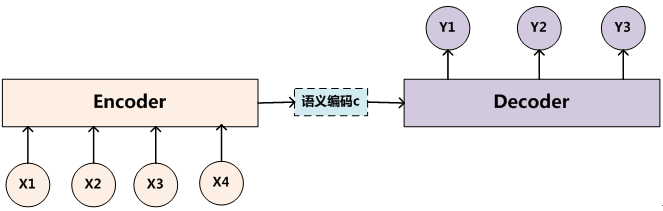
图2 抽象的文本处理领域的Encoder-Decoder框架
文本处理领域的Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对<Source,Target>,我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。Source和Target可以是同一种语言,也可以是两种不同的语言。而Source和Target分别由各自的单词序列构成:
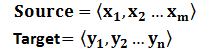
Encoder顾名思义就是对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C:
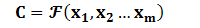
对于解码器Decoder来说,其任务是根据句子Source的中间语义表示C和之前已经生成的历史信息 来生成i时刻要生成的单词
来生成i时刻要生成的单词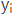 :
:
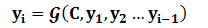
每个yi都依次这么产生,那么看起来就是整个系统根据输入句子Source生成了目标句子Target。
- 如果Source是中文句子,Target是英文句子,那么这就是解决机器翻译问题的Encoder-Decoder框架;
- 如果Source是一篇文章,Target是概括性的几句描述语句,那么这是文本摘要的Encoder-Decoder框架;
- 如果Source是一句问句,Target是一句回答,那么这是问答系统或者对话机器人的Encoder-Decoder框架。
由此可见,在文本处理领域,Encoder-Decoder的应用领域相当广泛。
Encoder-Decoder框架不仅仅在文本领域广泛使用,在语音识别、图像处理等领域也经常使用。比如对于语音识别来说,图2所示的框架完全适用,区别无非是Encoder部分的输入是语音流,输出是对应的文本信息;而对于“图像描述”任务来说,Encoder部分的输入是一副图片,Decoder的输出是能够描述图片语义内容的一句描述语。一般而言,文本处理和语音识别的Encoder部分通常采用RNN模型,图像处理的Encoder一般采用CNN模型。
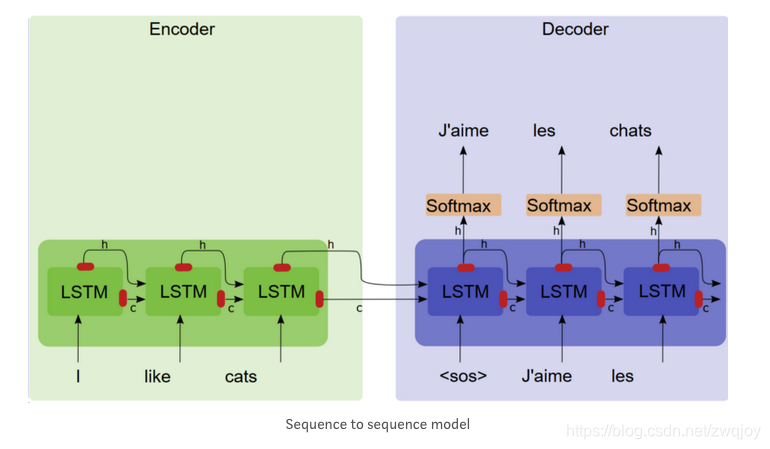
我们可以看到Seq2seq包含两部分:Encoder和Decoder。一旦将句子输入至Encoder,即可从Decoder获得目标句。本篇文章着墨在Decoder生成过程,Encoder就是个单纯的RNN/ LSTM,读者若有兴趣可再自行研究,此外RNN/LSTM可以互相代替,以下仅以LSTM作为解释。
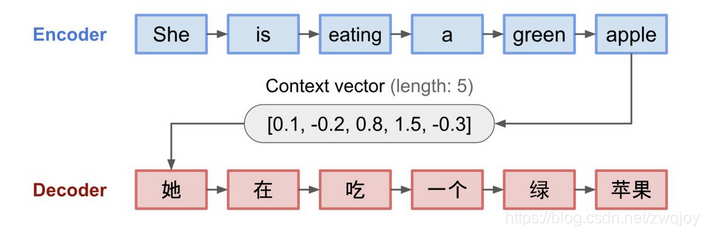
将“she is eating a green apple”翻译成中文,图中是对编码器和解码器随着时间步而展开的可视化效果
这种固定长度的上下文向量设计的一个关键的和明显的缺点在于,它无法记住很长的句子,对很长的时序信息来说,一旦它完成了对整个序列的处理,它通常会忘记最开始的部分,从而丢失很多有用的信息。因此,在2015年Bahdanau等人为了解决长时依赖问题,提出了注意力机制。
三 Attention模型
1. Attention 的优点
之所以要引入 Attention 机制,主要是3个原因:
- 参数少: 模型复杂度跟 CNN、RNN 相比,复杂度更小,参数也更少。所以对算力的要求也就更小。
- 速度快: Attention 解决了 RNN 不能并行计算的问题。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
- 效果好: 在 Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。
Attention 是挑重点,就算文本比较长,也能从中间抓住重点,不丢失重要的信息。下图红色的预期就是被挑出来的重点。

二 Attention 不同类型
Attention 有很多种不同的类型:Soft Attention、Hard Attention、静态Attention、动态Attention、Self Attention 等等
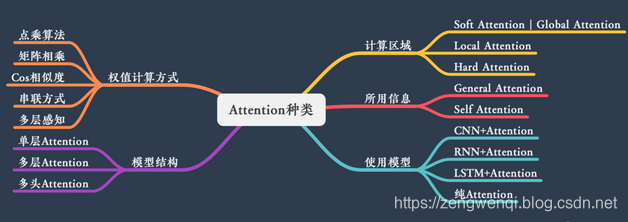
本节从计算区域、所用信息、结构层次和模型等方面对Attention的形式进行归类。
1. 计算区域
根据Attention的计算区域,可以分成以下几种:
1)Soft Attention,这是比较常见的Attention方式,对所有key求权重概率,每个key都有一个对应的权重,是一种全局的计算方式(也可以叫Global Attention)。这种方式比较理性,参考了所有key的内容,再进行加权。但是计算量可能会比较大一些。
2)Hard Attention,这种方式是直接精准定位到某个key,其余key就都不管了,相当于这个key的概率是1,其余key的概率全部是0。因此这种对齐方式要求很高,要求一步到位,如果没有正确对齐,会带来很大的影响。另一方面,因为不可导,一般需要用强化学习的方法进行训练。(或者使用gumbel softmax之类的)
3)Local Attention,这种方式其实是以上两种方式的一个折中,对一个窗口区域进行计算。先用Hard方式定位到某个地方,以这个点为中心可以得到一个窗口区域,在这个小区域内用Soft方式来算Attention。
2. 所用信息
假设我们要对一段原文计算Attention,这里原文指的是我们要做attention的文本,那么所用信息包括内部信息和外部信息,内部信息指的是原文本身的信息,而外部信息指的是除原文以外的额外信息。
1)General Attention,这种方式利用到了外部信息,常用于需要构建两段文本关系的任务,query一般包含了额外信息,根据外部query对原文进行对齐。
比如在阅读理解任务中,需要构建问题和文章的关联,假设现在baseline是,对问题计算出一个问题向量q,把这个q和所有的文章词向量拼接起来,输入到LSTM中进行建模。那么在这个模型中,文章所有词向量共享同一个问题向量,现在我们想让文章每一步的词向量都有一个不同的问题向量,也就是,在每一步使用文章在该步下的词向量对问题来算attention,这里问题属于原文,文章词向量就属于外部信息。
2)Local Attention,这种方式只使用内部信息,key和value以及query只和输入原文有关,在self attention中,key=value=query。既然没有外部信息,那么在原文中的每个词可以跟该句子中的所有词进行Attention计算,相当于寻找原文内部的关系。
还是举阅读理解任务的例子,上面的baseline中提到,对问题计算出一个向量q,那么这里也可以用上attention,只用问题自身的信息去做attention,而不引入文章信息。
3. 结构层次
结构方面根据是否划分层次关系,分为单层attention,多层attention和多头attention:
1)单层Attention,这是比较普遍的做法,用一个query对一段原文进行一次attention。
2)多层Attention,一般用于文本具有层次关系的模型,假设我们把一个document划分成多个句子,在第一层,我们分别对每个句子使用attention计算出一个句向量(也就是单层attention);在第二层,我们对所有句向量再做attention计算出一个文档向量(也是一个单层attention),最后再用这个文档向量去做任务。
3)多头Attention,这是Attention is All You Need中提到的multi-head attention,用到了多个query对一段原文进行了多次attention,每个query都关注到原文的不同部分,相当于重复做多次单层attention:
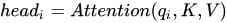
最后再把这些结果拼接起来:
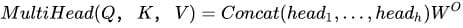
4. 模型方面
从模型上看,Attention一般用在CNN和LSTM上,也可以直接进行纯Attention计算。
1)CNN+Attention
CNN的卷积操作可以提取重要特征,我觉得这也算是Attention的思想,但是CNN的卷积感受视野是局部的,需要通过叠加多层卷积区去扩大视野。另外,Max Pooling直接提取数值最大的特征,也像是hard attention的思想,直接选中某个特征。
CNN上加Attention可以加在这几方面:
a. 在卷积操作前做attention,比如Attention-Based BCNN-1,这个任务是文本蕴含任务需要处理两段文本,同时对两段输入的序列向量进行attention,计算出特征向量,再拼接到原始向量中,作为卷积层的输入。
b. 在卷积操作后做attention,比如Attention-Based BCNN-2,对两段文本的卷积层的输出做attention,作为pooling层的输入。
c. 在pooling层做attention,代替max pooling。比如Attention pooling,首先我们用LSTM学到一个比较好的句向量,作为query,然后用CNN先学习到一个特征矩阵作为key,再用query对key产生权重,进行attention,得到最后的句向量。
2)LSTM+Attention
LSTM内部有Gate机制,其中input gate选择哪些当前信息进行输入,forget gate选择遗忘哪些过去信息,我觉得这算是一定程度的Attention了,而且号称可以解决长期依赖问题,实际上LSTM需要一步一步去捕捉序列信息,在长文本上的表现是会随着step增加而慢慢衰减,难以保留全部的有用信息。
LSTM通常需要得到一个向量,再去做任务,常用方式有:
a. 直接使用最后的hidden state(可能会损失一定的前文信息,难以表达全文)
b. 对所有step下的hidden state进行等权平均(对所有step一视同仁)。
c. Attention机制,对所有step的hidden state进行加权,把注意力集中到整段文本中比较重要的hidden state信息。性能比前面两种要好一点,而方便可视化观察哪些step是重要的,但是要小心过拟合,而且也增加了计算量。
3)纯Attention
Attention is all you need,没有用到CNN/RNN,乍一听也是一股清流了,但是仔细一看,本质上还是一堆向量去计算attention。
5. 相似度计算方式
在做attention的时候,我们需要计算query和某个key的分数(相似度),常用方法有:
1)点乘:最简单的方法, 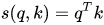
2)矩阵相乘:
3)cos相似度: 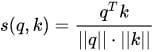
4)串联方式:把q和k拼接起来, 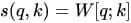
5)用多层感知机也可以: 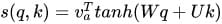
四 Attention详细介绍
为什么要用Attention Model?
The attention model用来帮助解决机器翻译在句子过长时效果不佳的问题。
这种新的构架替输入句的每个文字都创造一个context vector,而非仅仅替输入句创造一个从最终的hidden state得来的context vector
举例来说,如果一个输入句有N个文字,就会产生N个context vector,好处是,每个context vector能够被更有效的译码。

在Attention model中,Encoder和Seq2seq概念一样,一样是从输入句<X1,X2,X3…Xm>产生<h1,h2,h….hm>的hidden state,再计算目标句<y1…yn>。换言之,就是将输入句作为input而目标句作为output,所以差别就在于context vector c_{i}是怎么计算。
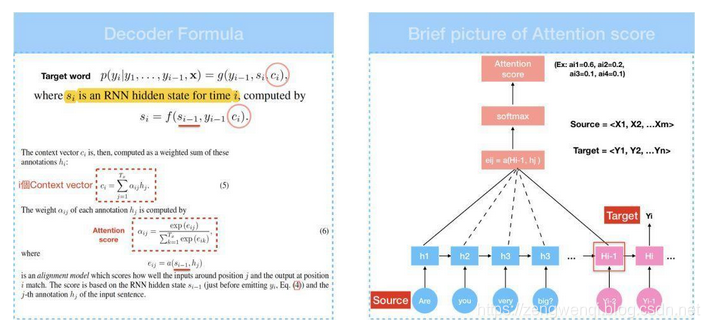
Context vector c_{i}是透过attention score α乘上input的序列加权求和, Attention/Alignment score是attention model中提出一个很重要的概念,可以用来衡量输入句中的每个文字对目标句中的每个文字所带来重要性的程度。由公式可知,attention score由score e_{ij}所计算得到,所以先来看看score e_{ij}是什么。
在计算score中,a代表Alignment model会根据输入字位置j和输出字位置i这两者的关联程度,计算出一个score e_{ij}。换言之,e_{i,j}是衡量RNN decoder中的hidden state s_{i-1}和输入句中的第j个文字hidden state h_{j}的关系所计算出的权重 — 如方程式3,那权重怎么算呢?

Neural Machine Translation发表之后,后续的论文Effective approaches of the NMT、Show,Attend and Tell提出了global/local attention和soft/hard attention的概念,而score e_{ij}的计算方式类似global和soft attention。细节在此不多说,图11可以看到3种计算权重的方式,我们把刚才的公式做些改变,将score e_{ij}改写成score(h_{t},bar {h_{s}}),h_{t}代表s_{i-1}而bar {h_{s}}代表h_{j},为了计算方便,我们采用内积(dot)计算权重。
有了score e_{ij},即可透过softmax算出attention score,context vector也可得到,在attention model中,context vector又称为attention vector。我们可以将attention score列为矩阵,透过此矩阵可看到输入端文字和输出端文字间的对应关系,也就是论文当中提出align的概念。
我们知道如何计算context vector后,回头看encoder。
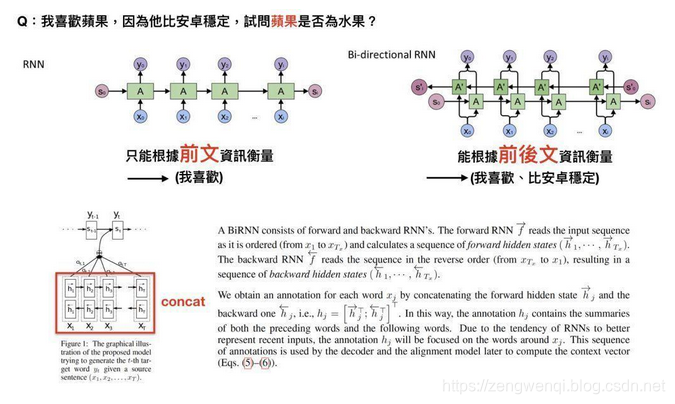
attention model中的encoder用的是改良版RNN:双向RNN(Bi-directional RNN),以往单向RNN的问题在于t时刻时,只能透过之前的信息进行预测,但事实上,模型有时候可能也需要利用未来时刻的信息进行预测,其运作模式为,一个hidden layer用来由左到右,另一个由右到左,透过双向RNN,我们可以对词语进行更好的预测。
举例来说,”我喜欢苹果,因为它很好吃”?和”我喜欢苹果,因为他比安卓稳定”这两个句子当中,如果只看”我喜欢苹果”,你可能不知道苹果指的是水果还是手机,但如果可以根据后面那句得到信息,答案就很显而易见,这就是双向RNN运作的方式。
1. Soft Attention 模型
这是比较常见的Attention方式,对所有key求权重概率,每个key都有一个对应的权重,是一种全局的计算方式(也可以叫Global Attention)。这种方式比较理性,参考了所有key的内容,再进行加权。但是计算量可能会比较大一些。作、
图2中展示的Encoder-Decoder框架是没有体现出“注意力模型”的,所以可以把它看作是注意力不集中的分心模型。为什么说它注意力不集中呢?请观察下目标句子Target中每个单词的生成过程如下:
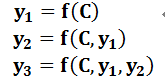
其中f是Decoder的非线性变换函数。从这里可以看出,在生成目标句子的单词时,不论生成哪个单词,它们使用的输入句子Source的语义编码C都是一样的,没有任何区别。
而语义编码C是由句子Source的每个单词经过Encoder 编码产生的,这意味着不论是生成哪个单词,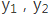 还是
还是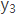 ,其实句子Source中任意单词对生成某个目标单词yi来说影响力都是相同的,这是为何说这个模型没有体现出注意力的缘由。这类似于人类看到眼前的画面,但是眼中却没有注意焦点一样。
,其实句子Source中任意单词对生成某个目标单词yi来说影响力都是相同的,这是为何说这个模型没有体现出注意力的缘由。这类似于人类看到眼前的画面,但是眼中却没有注意焦点一样。
如果拿机器翻译来解释这个分心模型的Encoder-Decoder框架更好理解,比如输入的是英文句子:Tom chase Jerry,Encoder-Decoder框架逐步生成中文单词:“汤姆”,“追逐”,“杰瑞”。
在翻译“杰瑞”这个中文单词的时候,分心模型里面的每个英文单词对于翻译目标单词“杰瑞”贡献是相同的,很明显这里不太合理,显然“Jerry”对于翻译成“杰瑞”更重要,但是分心模型是无法体现这一点的,这就是为何说它没有引入注意力的原因。
没有引入注意力的模型在输入句子比较短的时候问题不大,但是如果输入句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,可想而知会丢失很多细节信息,这也是为何要引入注意力模型的重要原因。
上面的例子中,如果引入Attention模型的话,应该在翻译“杰瑞”的时候,体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:
(Tom,0.3)(Chase,0.2) (Jerry,0.5)
每个英文单词的概率代表了翻译当前单词“杰瑞”时,注意力分配模型分配给不同英文单词的注意力大小。这对于正确翻译目标语单词肯定是有帮助的,因为引入了新的信息。
同理,目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息。这意味着在生成每个单词的时候,原先都是相同的中间语义表示C会被替换成根据当前生成单词而不断变化的 。理解Attention模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的。增加了注意力模型的Encoder-Decoder框架理解起来如图3所示。
。理解Attention模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的。增加了注意力模型的Encoder-Decoder框架理解起来如图3所示。
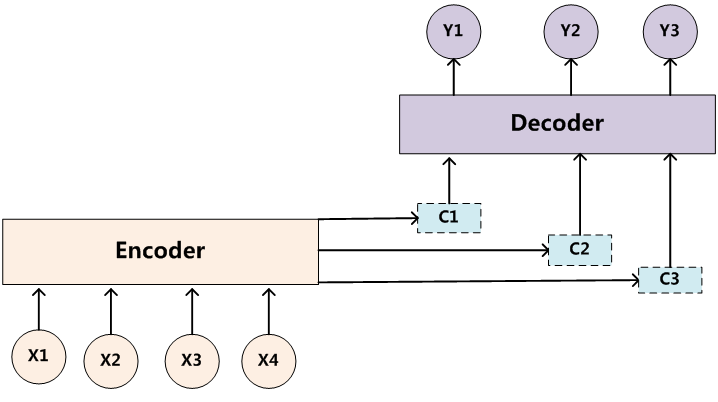
图3 引入注意力模型的Encoder-Decoder框架
即生成目标句子单词的过程成了下面的形式:
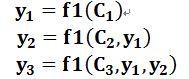
而每个可能对应着不同的源语句子单词的注意力分配概率分布
比如对于上面的英汉翻译来说,其对应的信息可能如下:

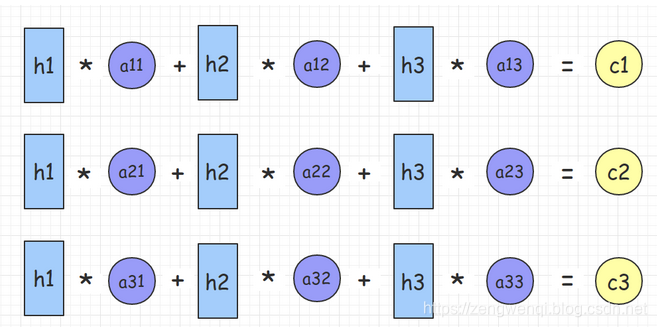
其中,f2函数代表Encoder对输入英文单词的某种变换函数,比如如果Encoder是用的RNN模型的话,这个f2函数的结果往往是某个时刻输入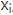 后隐层节点的状态值;g代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数,一般的做法中,g函数就是对构成元素加权求和,即下列公式:
后隐层节点的状态值;g代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数,一般的做法中,g函数就是对构成元素加权求和,即下列公式:
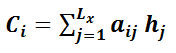
其中, 代表输入句子Source的长度,
代表输入句子Source的长度, 代表在Target输出第i个单词时Source输入句子中第j个单词的注意力分配系数,而
代表在Target输出第i个单词时Source输入句子中第j个单词的注意力分配系数,而 则是Source输入句子中第j个单词的语义编码。假设下标i就是上面例子所说的“ 汤姆” ,那么就是3,h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”)分别是输入句子每个单词的语义编码,对应的注意力模型权值则分别是0.6,0.2,0.2,所以g函数本质上就是个加权求和函数。如果形象表示的话,翻译中文单词“汤姆”的时候,数学公式对应的中间语义表示的形成过程类似图4。
则是Source输入句子中第j个单词的语义编码。假设下标i就是上面例子所说的“ 汤姆” ,那么就是3,h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”)分别是输入句子每个单词的语义编码,对应的注意力模型权值则分别是0.6,0.2,0.2,所以g函数本质上就是个加权求和函数。如果形象表示的话,翻译中文单词“汤姆”的时候,数学公式对应的中间语义表示的形成过程类似图4。
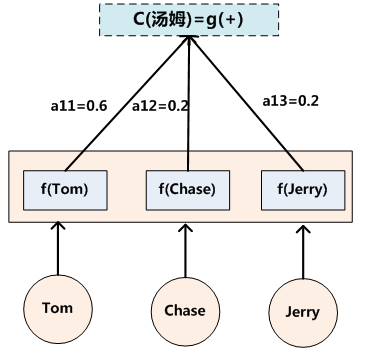
图4 Attention的形成过程
这里还有一个问题:生成目标句子某个单词,比如“汤姆”的时候,如何知道Attention模型所需要的输入句子单词注意力分配概率分布值呢?就是说“汤姆”对应的输入句子Source中各个单词的概率分布:(Tom,0.6)(Chase,0.2) (Jerry,0.2) 是如何得到的呢?
为了便于说明,我们假设对图2的非Attention模型的Encoder-Decoder框架进行细化,Encoder采用RNN模型,Decoder也采用RNN模型,这是比较常见的一种模型配置,则图2的框架转换为图5。
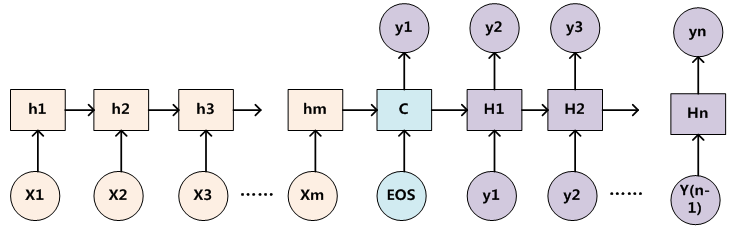
图5 RNN作为具体模型的Encoder-Decoder框架
那么用图6可以较为便捷地说明注意力分配概率分布值的通用计算过程。
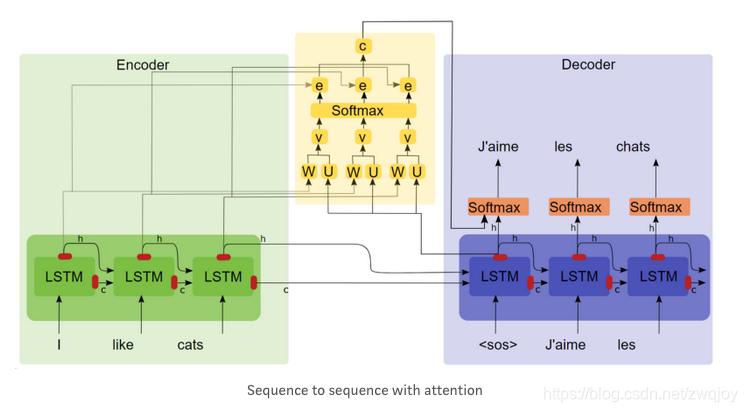
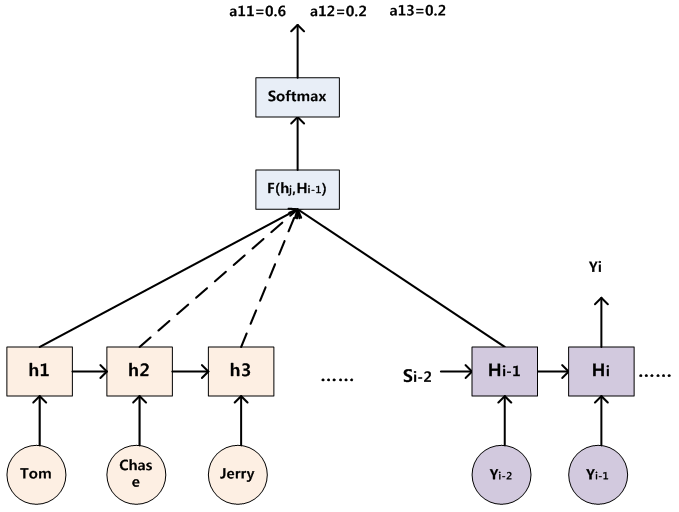
图6 注意力分配概率计算
对于采用RNN的Decoder来说,在时刻i,如果要生成yi单词,我们是可以知道Target在生成之前的时刻i-1时,隐层节点i-1时刻的输出值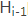 的,而我们的目的是要计算生成时输入句子中的单词“Tom”、“Chase”、“Jerry”对来说的注意力分配概率分布,那么可以用Target输出句子i-1时刻的隐层节点状态去一一和输入句子Source中每个单词对应的RNN隐层节点状态hj进行对比,即通过函数F(,)来获得目标单词和每个输入单词对应的对齐可能性,这个F函数在不同论文里可能会采取不同的方法,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。
的,而我们的目的是要计算生成时输入句子中的单词“Tom”、“Chase”、“Jerry”对来说的注意力分配概率分布,那么可以用Target输出句子i-1时刻的隐层节点状态去一一和输入句子Source中每个单词对应的RNN隐层节点状态hj进行对比,即通过函数F(,)来获得目标单词和每个输入单词对应的对齐可能性,这个F函数在不同论文里可能会采取不同的方法,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。
绝大多数Attention模型都是采取上述的计算框架来计算注意力分配概率分布信息,区别只是在F的定义上可能有所不同。图7可视化地展示了在英语-德语翻译系统中加入Attention机制后,Source和Target两个句子每个单词对应的注意力分配概率分布。
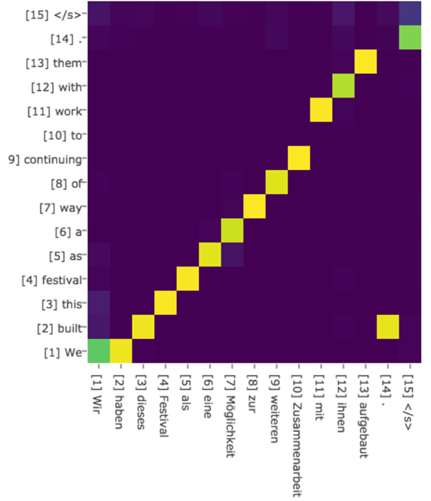
图7 英语-德语翻译的注意力概率分布
上述内容就是经典的Soft Attention模型的基本思想那么怎么理解Attention模型的物理含义呢?一般在自然语言处理应用里会把Attention模型看作是输出Target句子中某个单词和输入Source句子每个单词的对齐模型,这是非常有道理的。
目标句子生成的每个单词对应输入句子单词的概率分布可以理解为输入句子单词和这个目标生成单词的对齐概率,这在机器翻译语境下是非常直观的:传统的统计机器翻译一般在做的过程中会专门有一个短语对齐的步骤,而注意力模型其实起的是相同的作用。
图8 Google 神经网络机器翻译系统结构图
图8所示即为Google于2016年部署到线上的基于神经网络的机器翻译系统,相对传统模型翻译效果有大幅提升,翻译错误率降低了60%,其架构就是上文所述的加上Attention机制的Encoder-Decoder框架,主要区别无非是其Encoder和Decoder使用了8层叠加的LSTM模型。
Seq2seq、Attention model,差别在于计算context vector的方式。
Attention model虽然解决了输入句仅有一个context vector的缺点,但依旧存在不少问题。
1.context vector计算的是输入句、目标句间的关联,却忽略了输入句中文字间的关联,和目标句中文字间的关联性,
2.不管是Seq2seq或是Attention model,其中使用的都是RNN,RNN的缺点就是无法平行化处理,导致模型训练的时间很长,有些论文尝试用CNN去解决这样的问题,像是Facebook提出的Convolutional Seq2seq learning,但CNN实际上是透过大量的layer去解决局部信息的问题,在2017年,Google提出了一种叫做”The transformer”的模型,透过self attention、multi-head的概念去解决上述缺点,完全舍弃了RNN、CNN的构架。
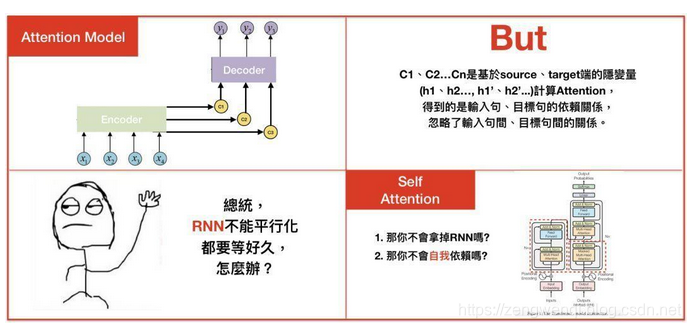
五 图解Attention机制
注意力一共分类两种。一种是全局注意力,使用所有编码器隐藏状态。另一种是局部注意力,使用的是编码器隐藏状态的子集。
在这篇文章中,提到的注意力,都是全局注意力。
使用“seq2seq”方法的话,他会从头开始逐字逐句阅读德语文本,然后逐字逐句将文本翻译成英语。如果句子特别长的话,他在翻译的时候,可能就已经忘了之前文本上的内容了。
如果使用seq2seq+注意力的方法,他在逐字逐句阅读德语文本的时候,会写下关键词。然后,利用这些关键词,将文本翻译成英语。
在模型中,注意力会为每个单词打一个分,将焦点放在不同的单词上。然后,基于softmax得分,使用编码器隐藏状态的加权和,来聚合编码器隐藏状态,以获得语境向量。
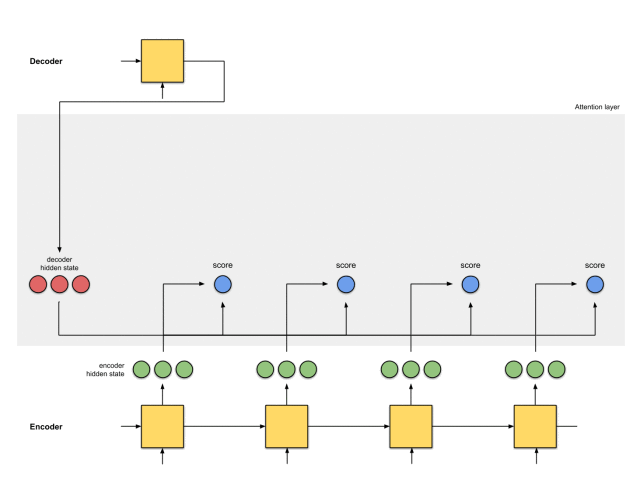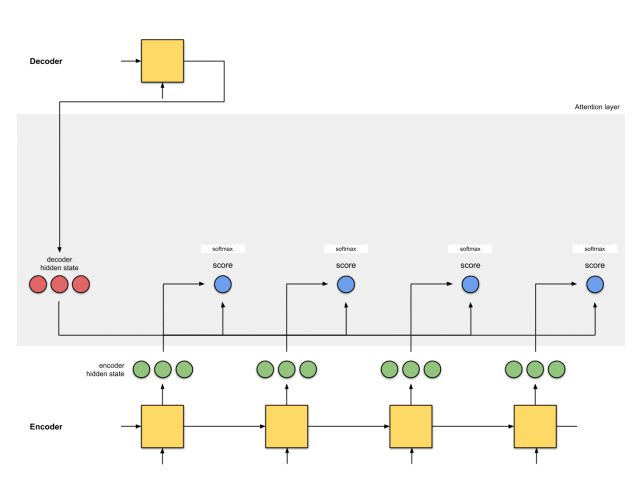
注意力层的实现可以分为6个步骤。
第一步:准备隐藏状态
首先,准备第一个解码器的隐藏状态(红色)和所有可用的编码器的隐藏状态(绿色)。在我们的例子中,有4个编码器的隐藏状态和当前解码器的隐藏状态。

第二步:获取每个编码器隐藏状态的分数
通过评分函数来获取每个编码器隐藏状态的分数(标量)。在这个例子中,评分函数是解码器和编码器隐藏状态之间的点积。
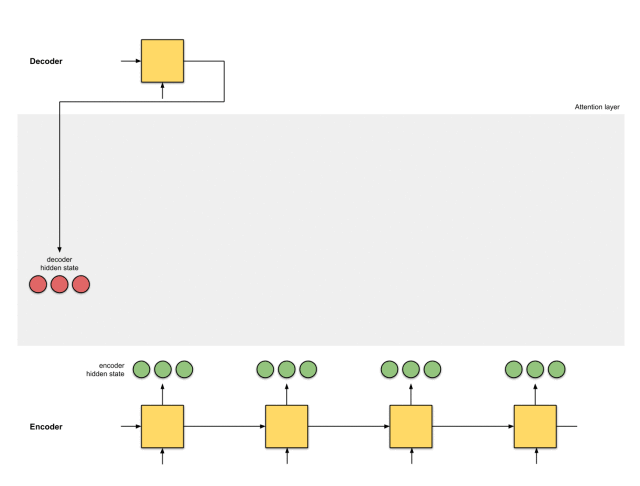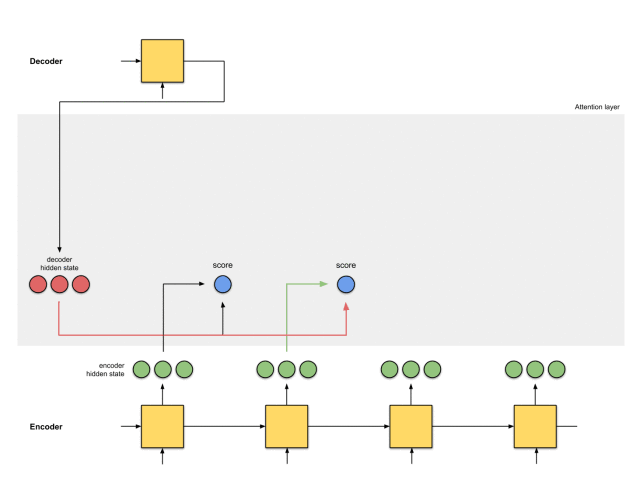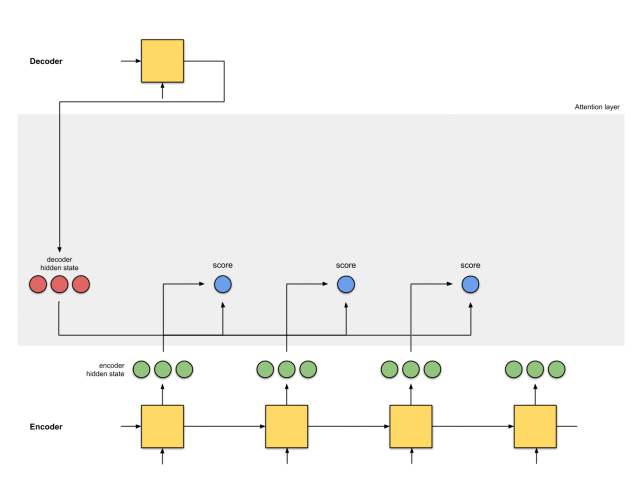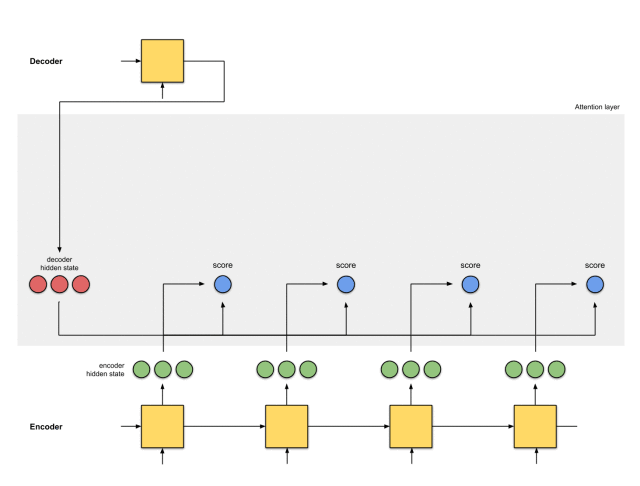
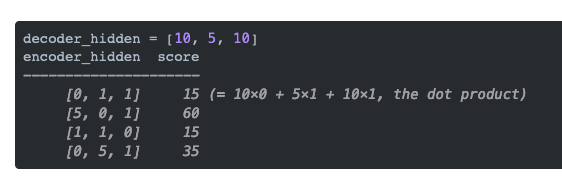
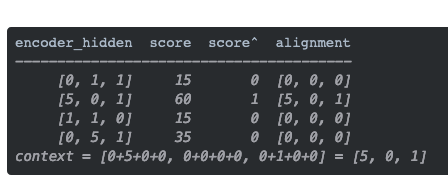
在上面的例子中,编码器隐藏状态[5,0,1]的注意力分数为60,很高。这意味着要翻译的下一个词将受到这个编码器隐藏状态的严重影响。
第三步:通过softmax层运行所有得分
我们将得分放到softmax函数层,使softmax得分(标量)之和为1。这些得分代表注意力的分布。
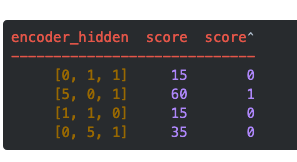
需要注意的是,基于softmaxed得分的score^。注意力仅按预期分布在[5,0,1]上。实际上,这些数字不是二进制数,而是0到1之间的浮点数。
第四步:将每个编码器的隐藏状态乘以其softmax得分
将每个编码器的隐藏状态与其softmaxed得分(标量)相乘,就能获得对齐向量。这就是发生对齐机制的地方。
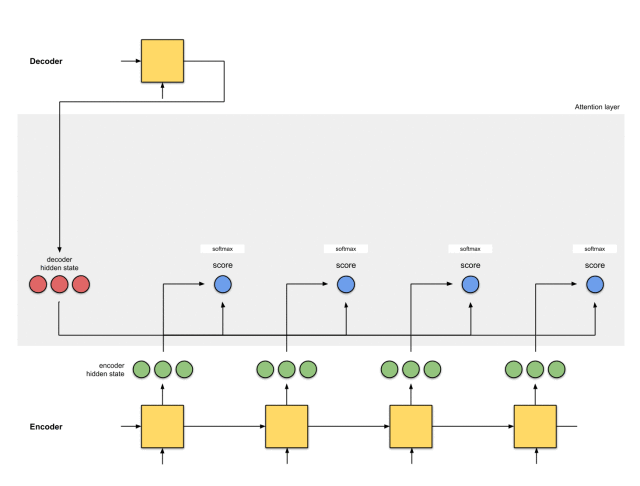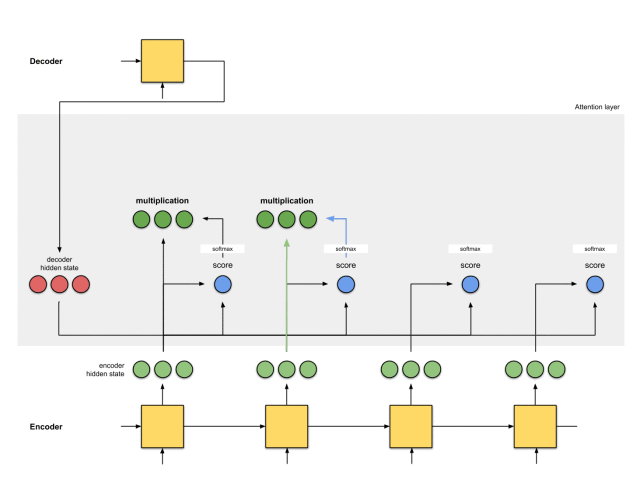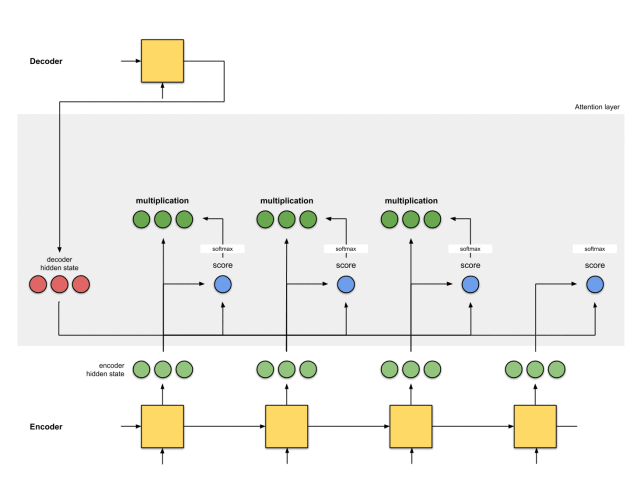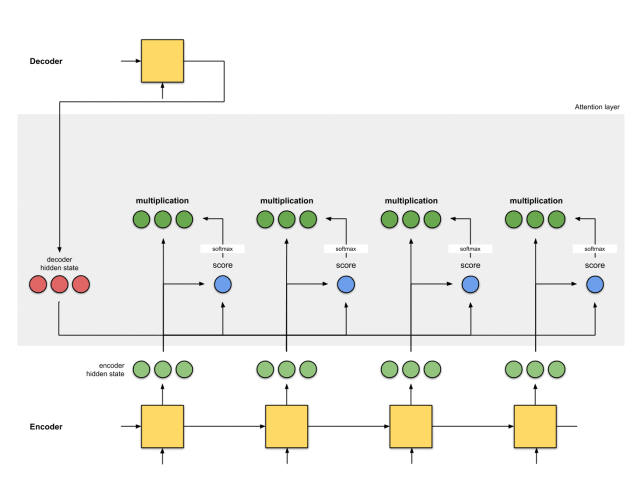
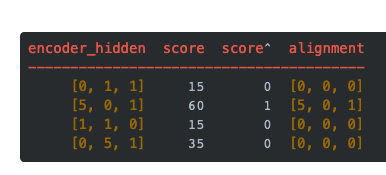
由于注意力分数很低,除了[5,0,1]之外的所有编码器隐藏状态的对齐都减少到了0。这意味着,我们可以预期,第一个被翻译的单词,应该与带有[5,0,1]嵌入的输入单词匹配起来。
第五步:将对齐向量聚合起来
将对齐向量聚合起来,得到语境向量。
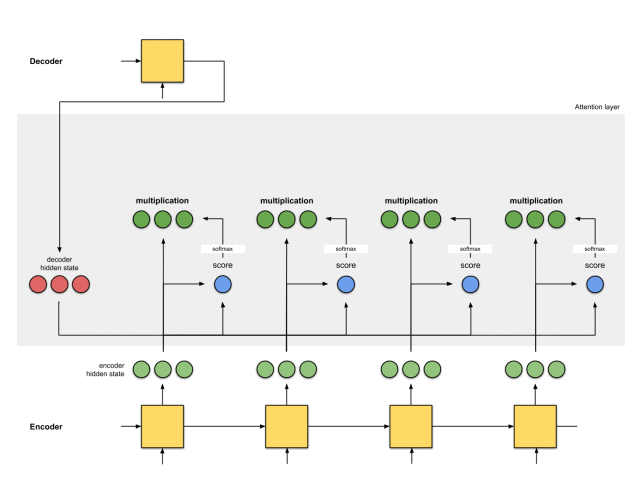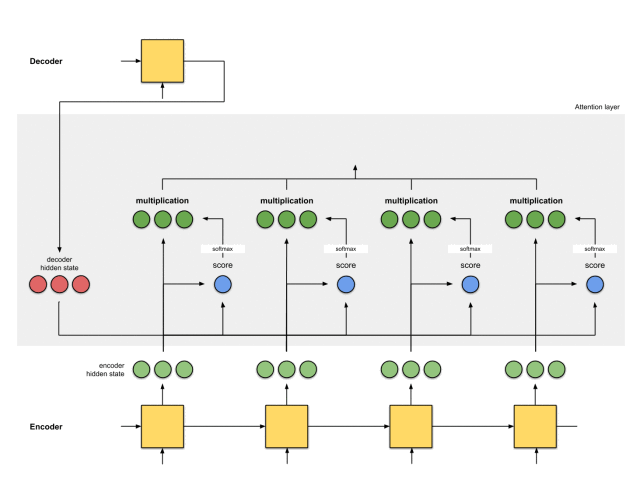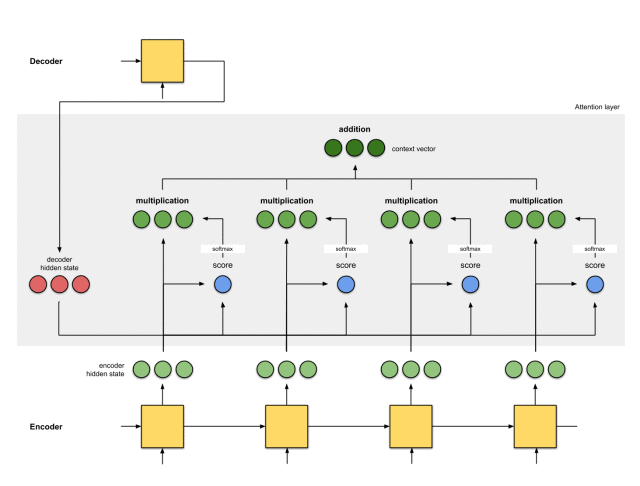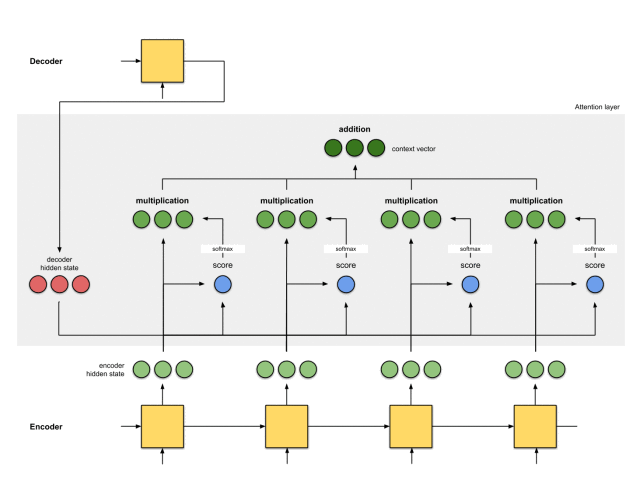
第六步:将语境向量输入到解码器中
这一步怎么做,取决于模型的架构设计。在接下来的示例中,会看到在模型架构中,解码器如何利用语境向量。
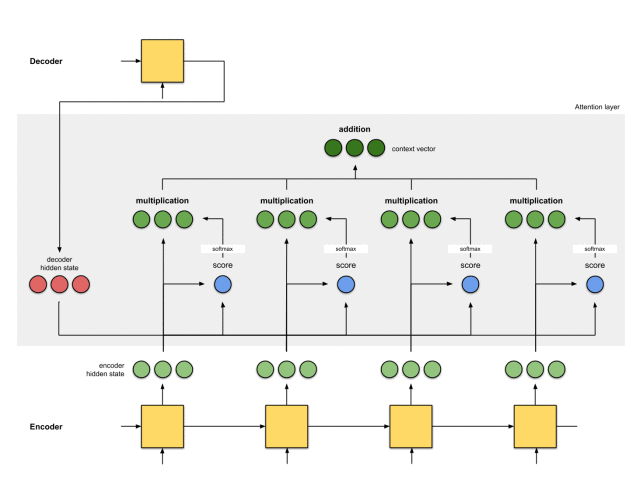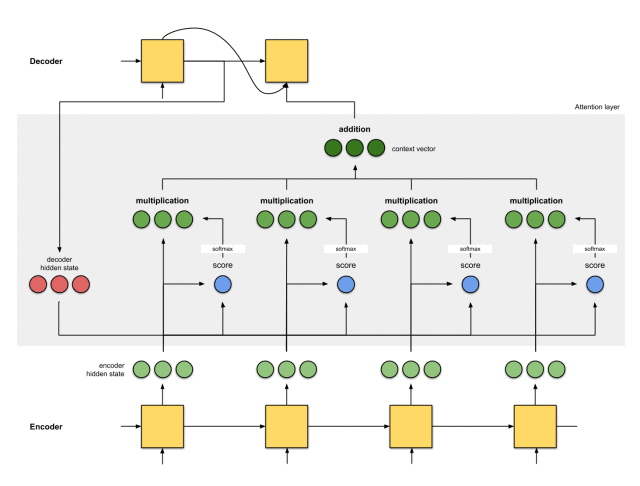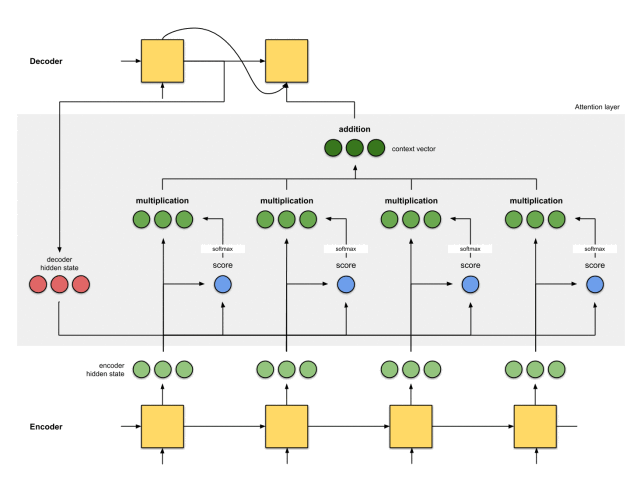
整体的运行机制,如下图所示:

那么,注意力机制是如何发挥作用的呢?
反向传播。反向传播将尽一切努力确保输出接近实际情况。这是通过改变RNN中的权重和评分函数(如果有的话)来完成的。
这些权重将影响编码器的隐藏状态和解码器的隐藏状态,进而影响注意力得分。
想要了解更多技术细节,可以看看下面的文章或者视频:
「文章」深度学习中的注意力机制
「文章」探索 NLP 中的 Attention 注意力机制及 Transformer 详解
链接:
https://juejin.im/post/5dcd2eb951882510ba1cbd91
https://www.jianshu.com/p/4d52edda1d76
https://www.jianshu.com/p/abf0f85467ca

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 4
4 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)