
AI智能体|扣子(Coze)搭建【小红书对标账号爆款采集】工作流
无论做什么,我都希望你从“抄”做起!
无论做什么,我都希望你从“抄”做起!
在自媒体上说好听点叫“对标”,说的不好听点就叫“抄”,我这里说的抄不是让原封不动的 Ctrl+c 然后 Ctrl+v,而是有意识有想法的去抄。
就拿之前 Labubu 火了之后我发了一篇 Labubu 打工的工作流文章来说。
当时我发完之后,很多人就开始抄了。
有的人根据自己的情况去抄,有的人直接全文复制粘贴,然后删删改改的抄,有的人则是自己做不出那种工作流,去复制图片,然后编个原创。

其实刚开始起步的时候抄没什么丢脸的,根据自己的想法去写同样的选题,这样慢慢就能找到自己的风格了,而不是直接复制粘贴,为了流量乱搞。
平台不是傻,用户也不傻,想做这方面的知识付费,啥都不会,就想靠搬运挣钱,不靠实力,这不是把平台和用户当傻子看了吗?
抄是能抄出现象级作品的,只要能在同一个方向/选题上,比原作者更优质,更完美,自然能获得用户的青睐。
如果说在同一个方向/选题上,无法超越对方,此时你做这个抄的行为,很难在用户注意力的竞争上获得胜利。
我看过我后台粉丝的数据,有一百多个同行关注了我,这么看来,至少也有几十个做智能体的同行在把我当成“对标”的对象,
我们做项目,学习,或者创业,我们抄一个大方向就够了,因为很多细节上的东西并不适合自己的情况,有时候变化会导致很多因素不同。
比如前几年做抖音可以,现在做抖音就很卷。
所以我们只需要知道一个大方向(真需求)就够了,再根据自身与周围的情况进行调整,当然我们还需要借鉴被“抄”的这个事情/人的经验来避免自己踩坑。
还需要注意的一点就是不是所有的成功经验都适合自己,多思考,多质疑。
好了,主包吹完牛批了,我们看看今天工作流的效果如何。
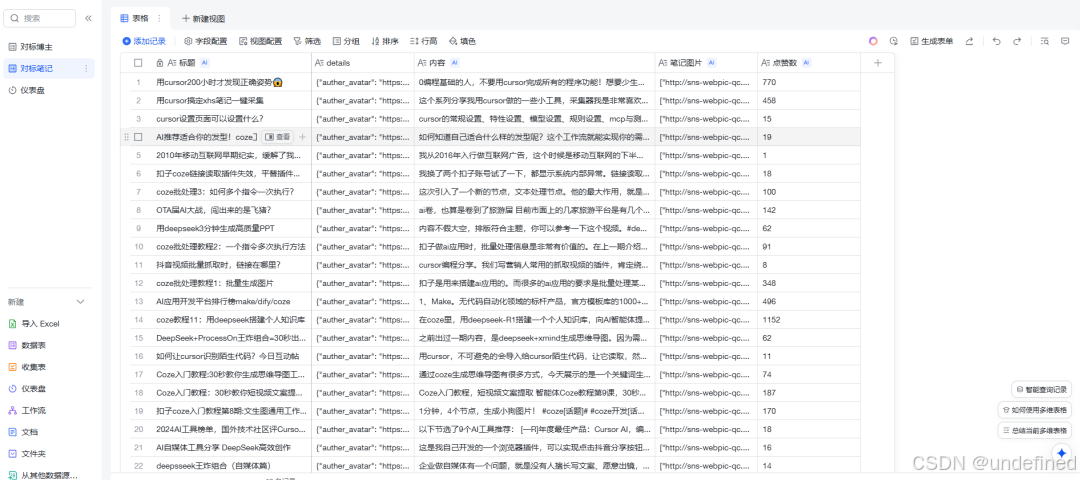
需求分析
做小红书的人都知道,对标很重要,我们要经常观察我们对标的博主,他们发布的内容是什么,数据怎么样,根据数据来为我们接下来的选题做参考。
但大多数的行业对标博主肯定是不止一个的,所以我们对标的时候就会出现太多对标的博主,笔记收集不过来的一个情况。
而且采集对标博主的笔记还是一个体力活,机械性的一个操作。
当然有的人是边采集边思考,但我不建议这么做,一次最好做一件事,这样效率会高一些,先采集,后拆解。
同时对标监测是一个长期性的活,它不是今天做完以后就不会做的事情,而是经常需要更新。
所以这个工作流就能帮助一些做小红书的人采集一些对标博主的内容,减少他们采集与拆解花费的时间,提升他们的工作效率。
工作流流程分析
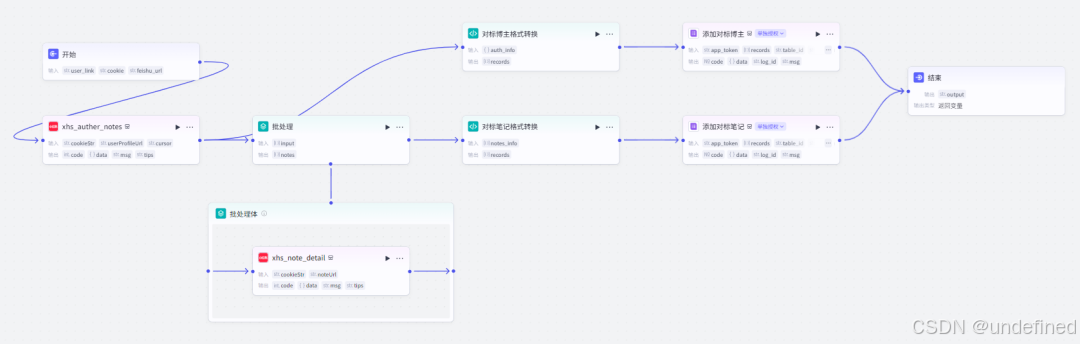
整体事件工作流流程如下。

整体 Coze 工作流流程如下。
保姆级工作流教程
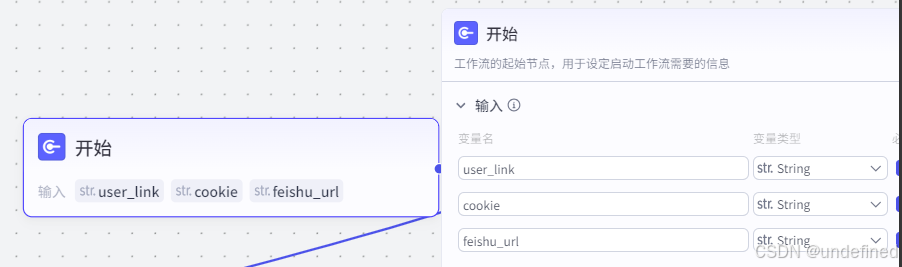
第一步,开始节点
开始节点我们设置三个参数,user_link,cookie,feishu_url,它们分别表示对标博主链接,小红书 cookie,飞书多为表格地址。
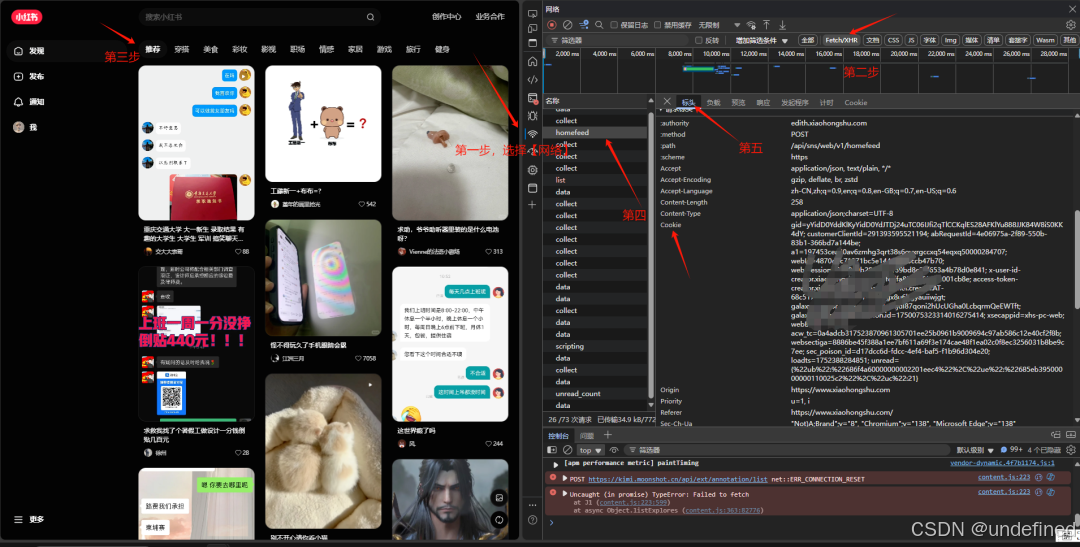
Cookie的获取方式如下图所示。
第二步,博主笔记列表获取(小红书)
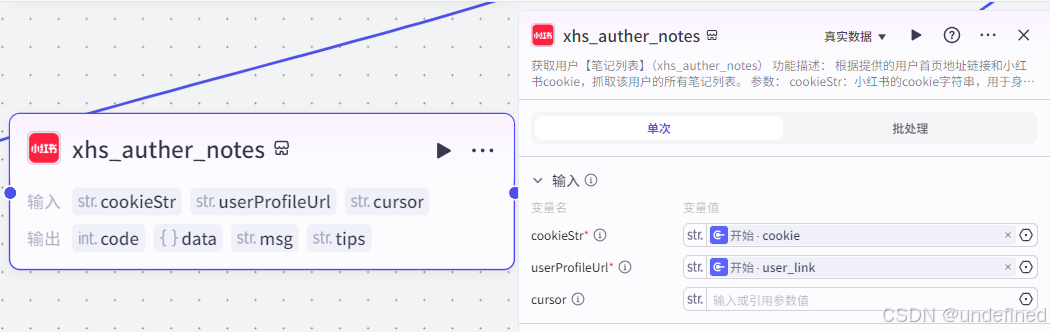
这个节点的作用主要是获取用户所有的笔记列表。
这里有两个参数 cookieStr ,userProfileUrl,它们的数据来源为开始节点的 cookie,user_link。
第三步,批处理
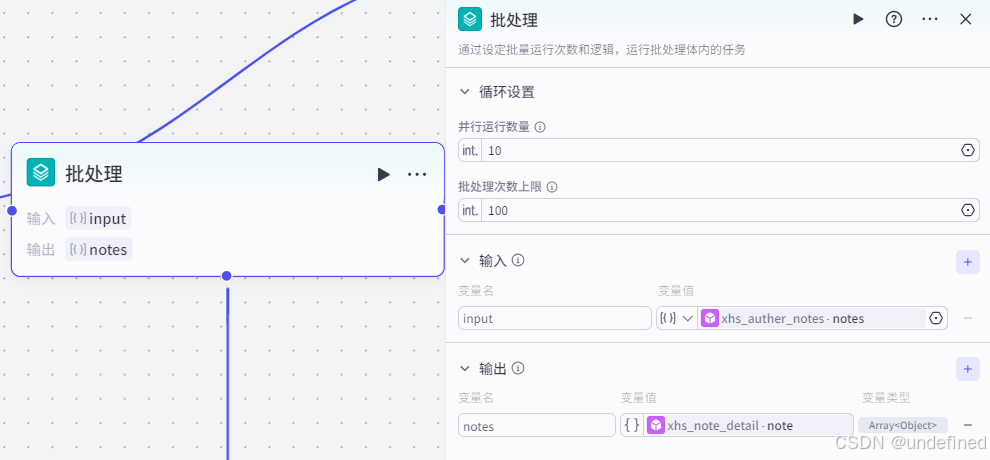
批处理节点的作用主要是对该博主的所有详情笔记进行采集。
这里我们设置并行数量为 10 ,批处理次数上限为 100 ,需要注意的是并行运行数量不能设置太高,否则会出现 bug,次数上限可以根据情况设定。
同时我们还要设置输入参数 input,格式为数组类型,数据来源为小红书笔记获取的 notes ,设置输出参数 notes ,数据来源为小红书笔记获取的 note。
笔记详情获取(批处理体)
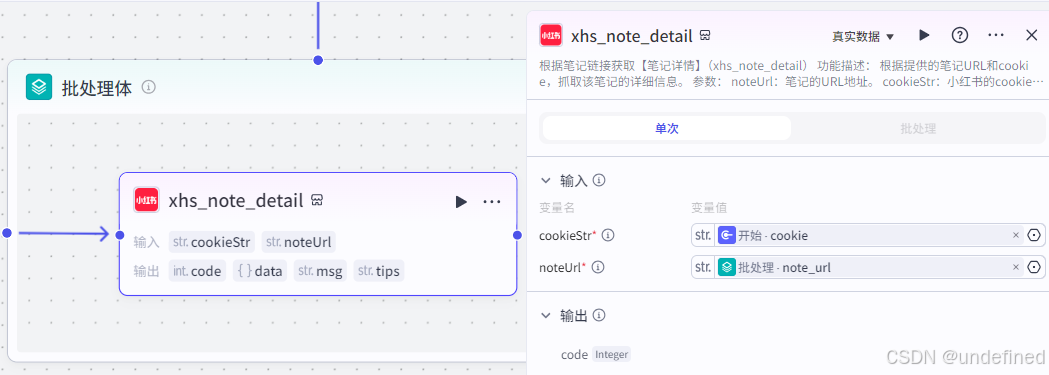
这一节点的作用就是根据笔记链接获取笔记详情了。
这里我们设置参数 cookieStr,数据来源为开始节点的 cookie ,noteUrl 数据来源为批处理节点的 note_url。
第四步,对标博主格式转换
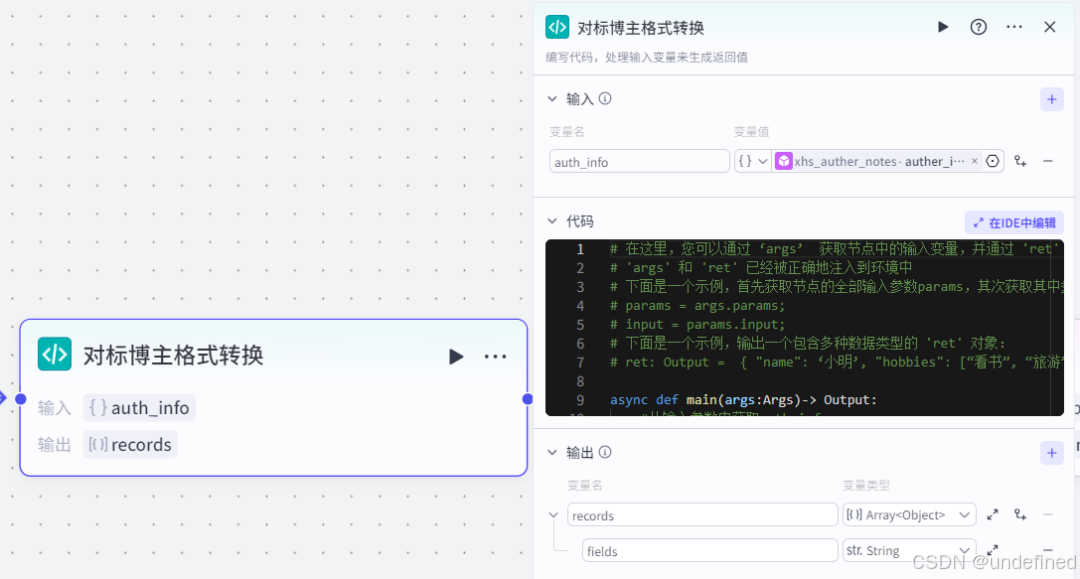
这一步的作用就是把对标博主的数据格式转化成可导入飞书文档节点的数据格式,代码很简单,可以用 AI 写出来,只要把需求和 AI 说清楚即可。
这里我们设置输入参数 auth_info ,数据类型为 object ,来源为博主笔记列表获取的 auther_info,设置输出参数 records 数组类型,包含 fields。
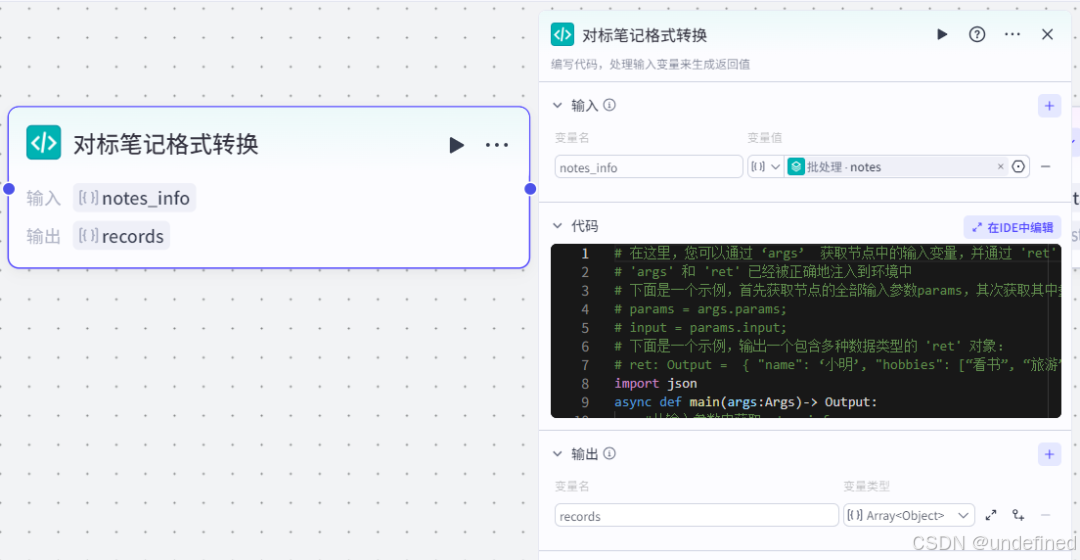
第五步,对标笔记格式转化
这一步的作用就是将对标笔记的数据格式转化成可以导入飞书文档的数据格式。
这里我们设置输入参数 notes_info,数据来源为批处理节点的 notes,设置输出参数 records ,数据类型为数组类型。
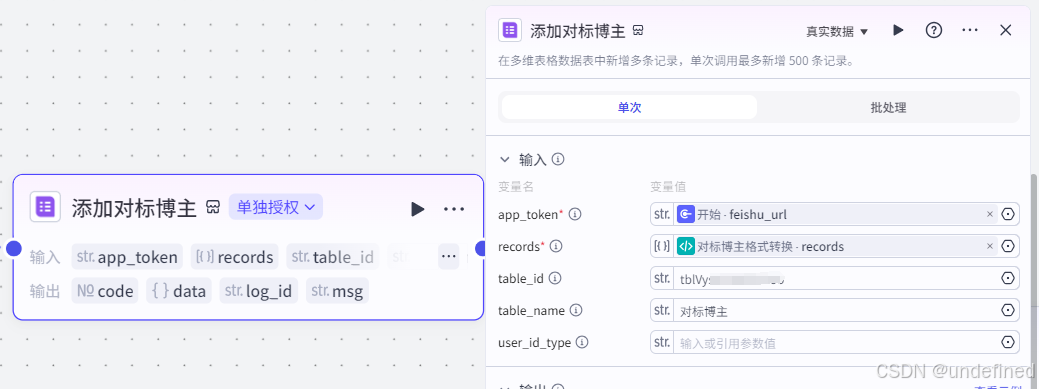
第六步,飞书多维表格
这个节点的作用就是收集一些对标博主了。
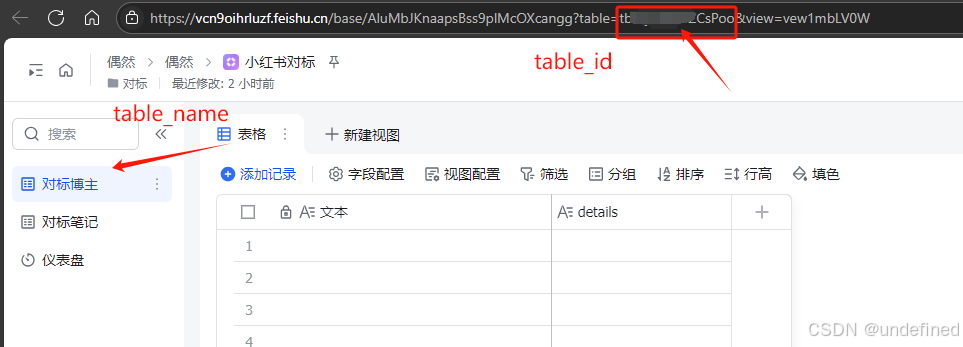
这里我们填写参数 app_token,records,table_id,table_name,数据来源为开始节点的 feishu_url,代码节点的 records,其它参数看截图。
注:这个节点咱们需要授权一下哈。
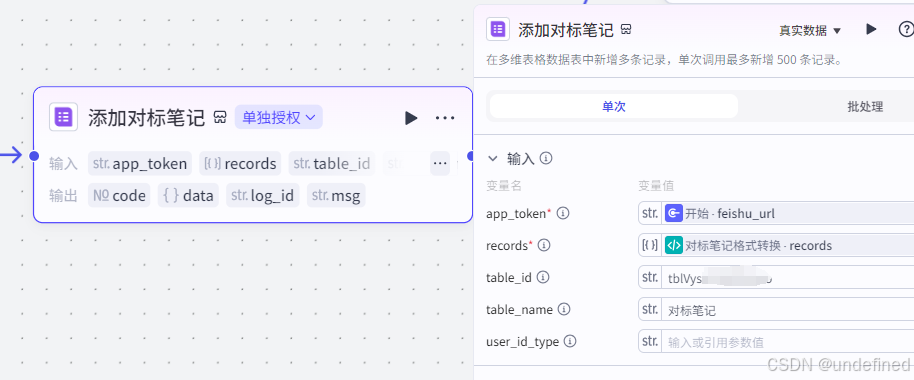
第七步,飞书多维表格
这个节点和上个节点的参数差不多,它的作用就是存储博主的笔记了。
第八步,结束
结束节点不需要返回什么,形成一个闭环就行了,毕竟数据都已经存在飞书多为表格上去了。
数据整理
我们运行该工作流,在开始节点处输入相应的参数。
我们能获得对标博主信息。
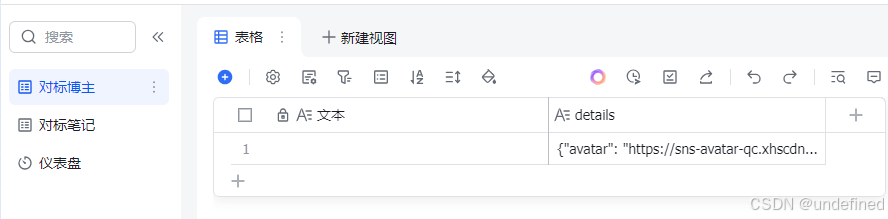
对标博主的笔记信息。
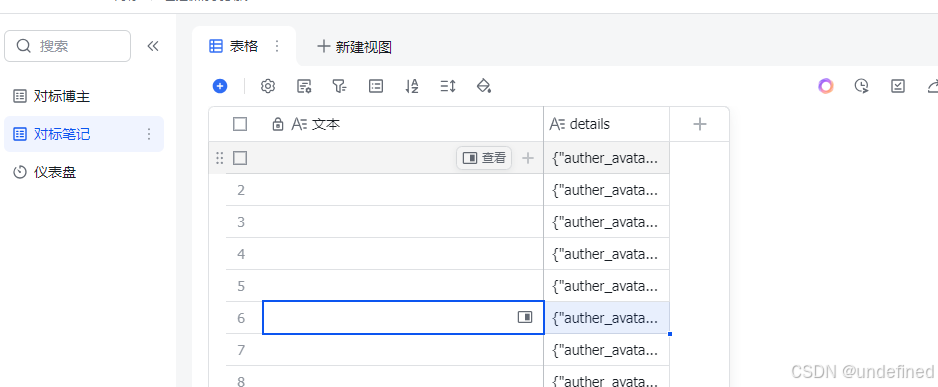
此时我们无法获取比较直观的信息,我们需要使用飞书的功能处理一下数据。
对标博主数据整理
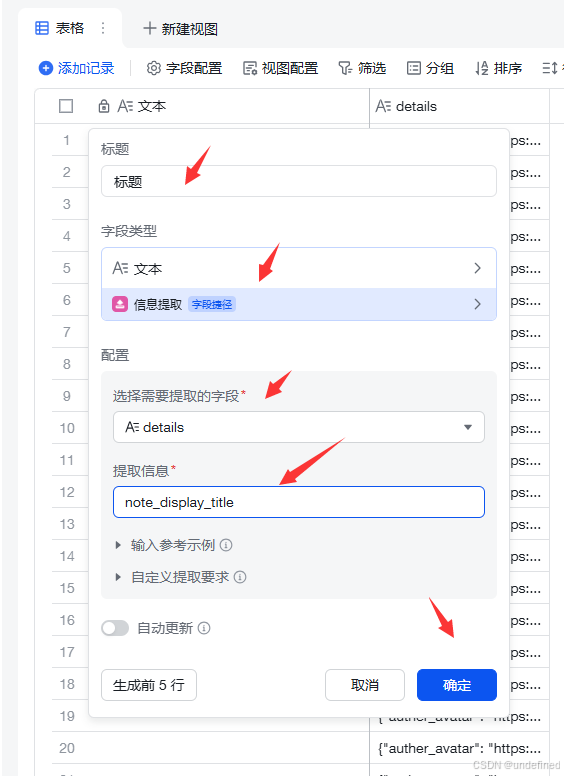
我们先处理对标博主的数据,这里我们选择文本进行博主名称的提取。
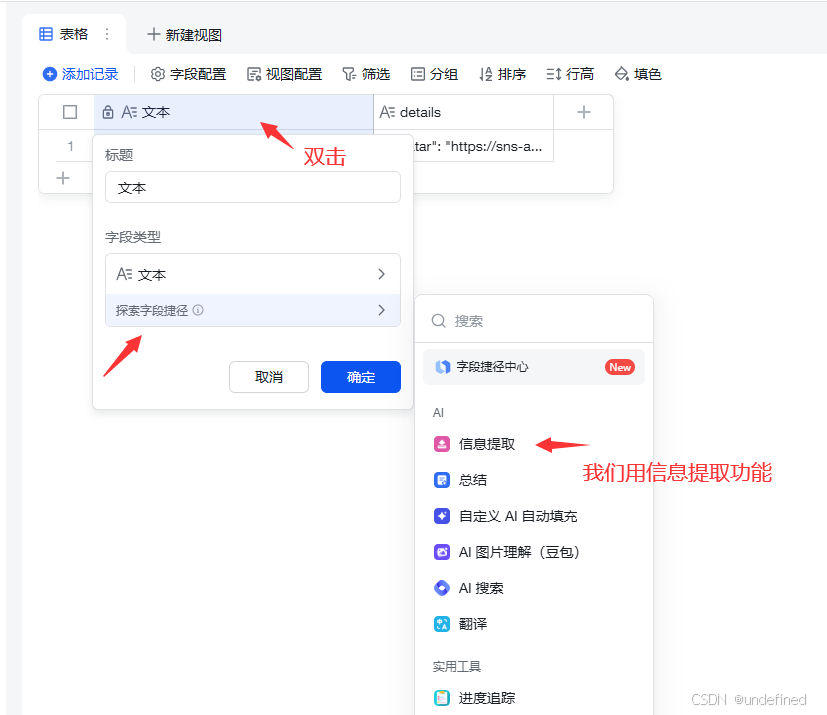
选择数据,再进行处理。
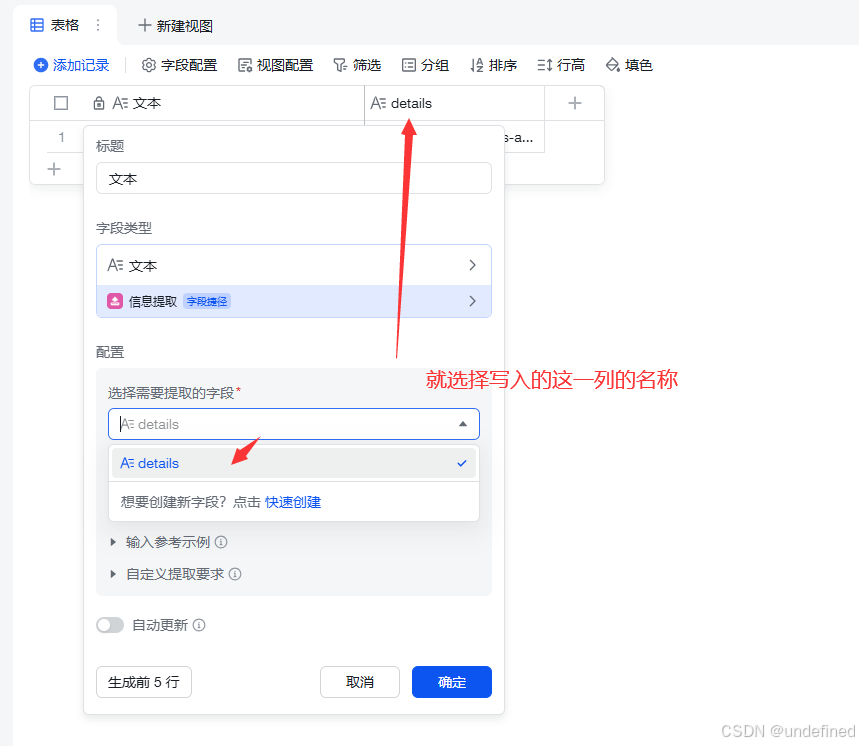
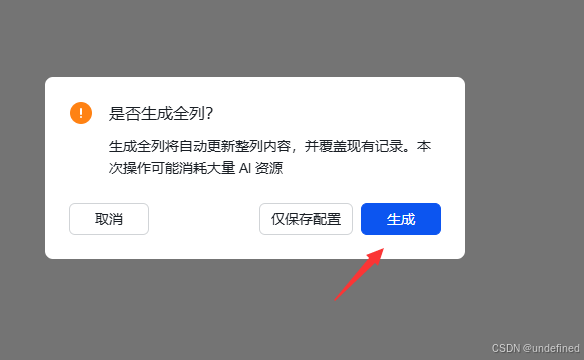
点击生成后,它就会自动生成了。
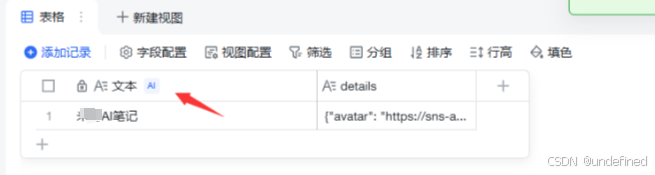
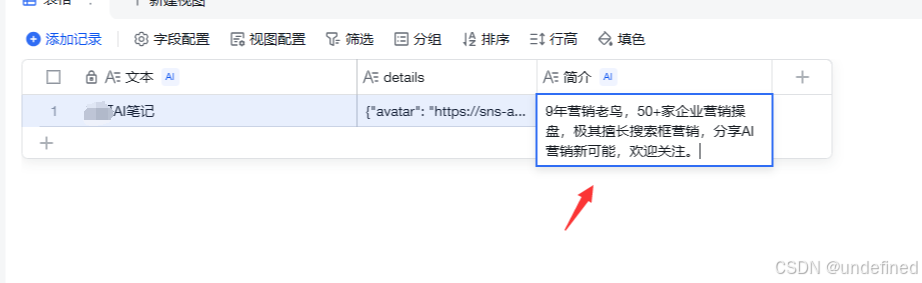
同理,按照上面的方式我们也可以提取其它的信息,比如我这里添加简介。
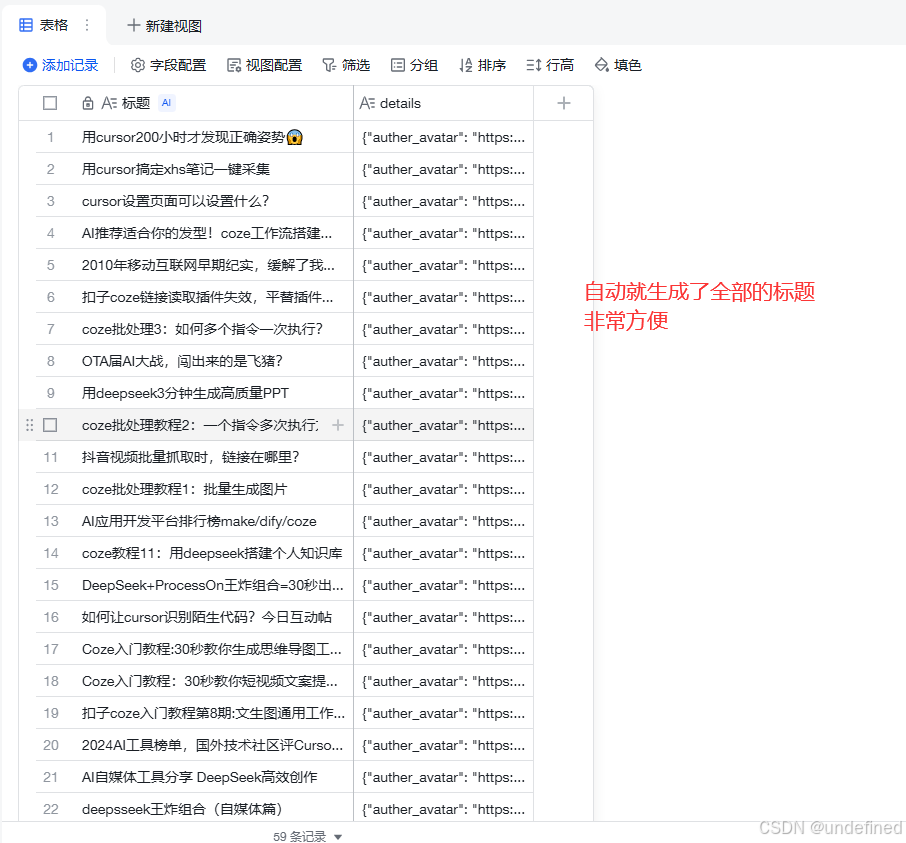
对标笔记数据处理
这题数据处理的方式和上面一样,都是进行信息提取。
比如这里我自动提取全部标题。
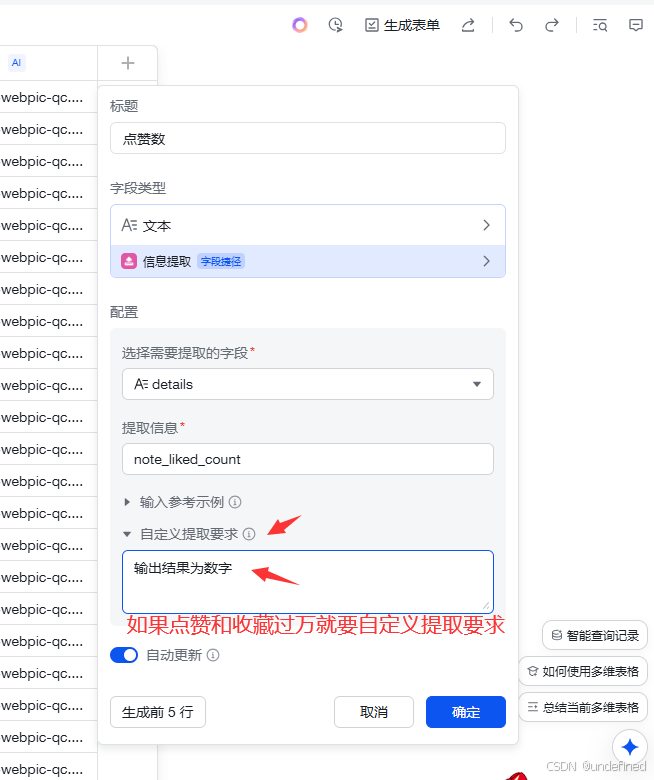
也可以自定义的提取要求。
总结
总体工作流一共 8 步,非常的简单,然后在把收集的数据采用飞书的功能整理一下就行了。
当然,数据整理这个步骤也可以通过代码的方式,直接在飞书中进行体现,这里我就不展示了,如果有兴趣可以自己试试看。
之前讲的那些工作流大多都是视频的,有些工作流对小白来说比较的难。
所以今天挑一个比较简单的,小白也能上手的,同时对一些想做自媒体的兄弟们有帮助的工作流出教程帮兄弟们。
对了,你还想看什么场景下提效的工作流,可以在评论区留言呀。
本期的内容就到这里了,感谢你的耐心。
如果看完喜欢,请帮忙转发分享一下,你的点赞转发,就是我更新下去的动力!

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 16
16 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)