
OCR常用识别算法综述
OCR常用识别算法综述
·
参考:https://aistudio.baidu.com/education/lessonvideo/3279888
语种:常用字符36与常用汉字6623,区别。
标注:文本型位置/单字符位置,后者标注成本大
挑战:场景文字识别:字符大小、颜色、字体、亮度、对比度多样。文字模糊、排列不规则、文字残缺、遮挡
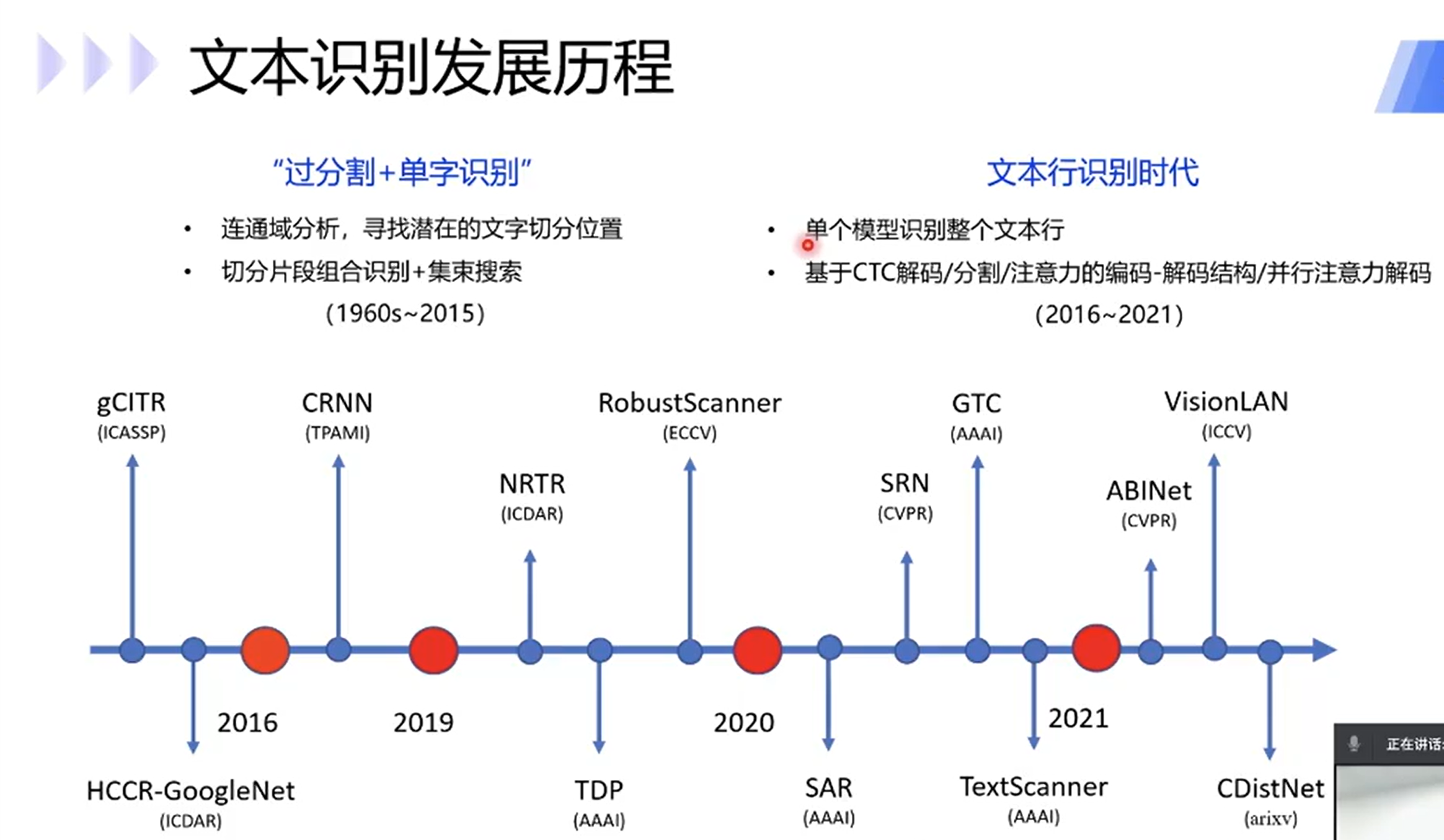
发展历程:两个阶段2015年前,后
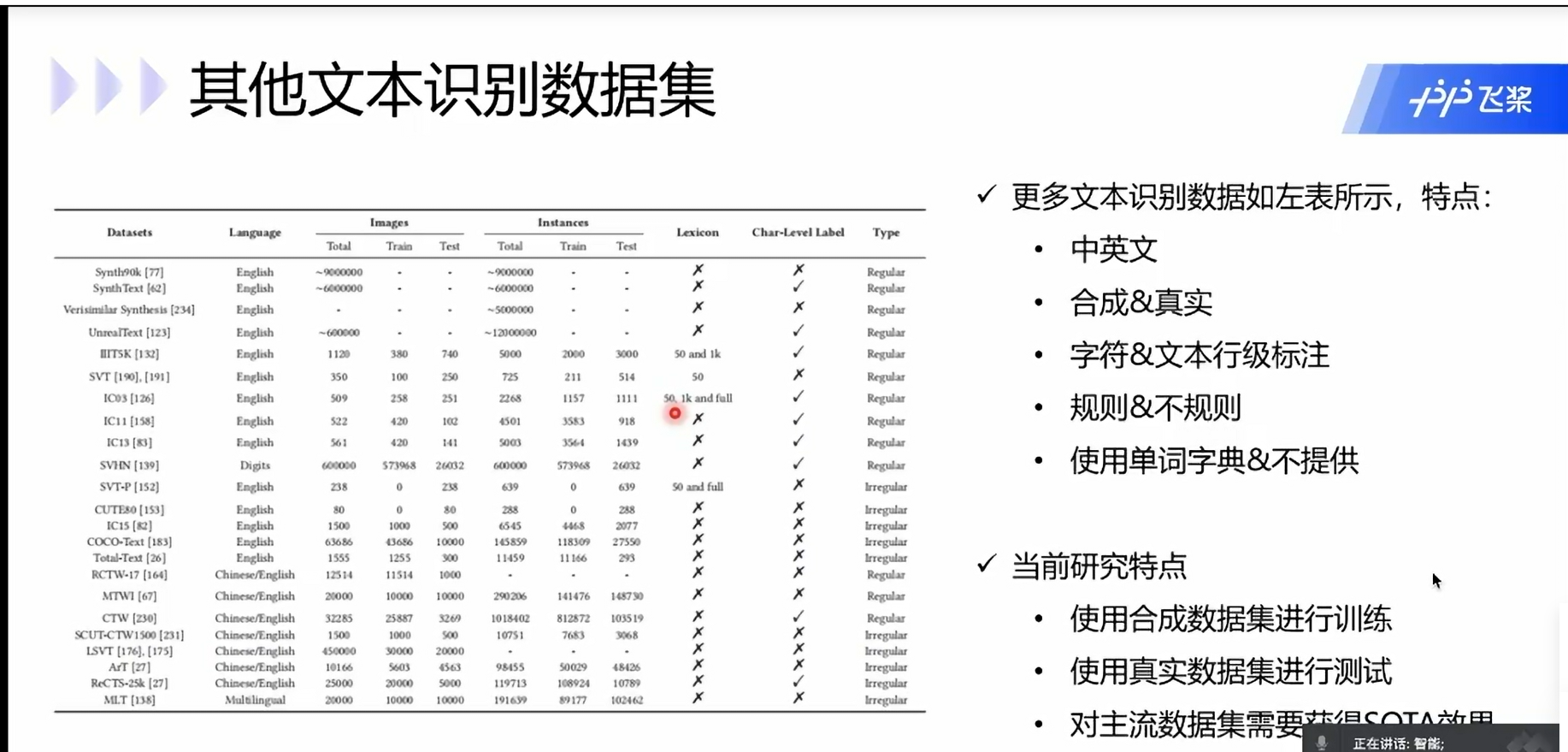
数据集:
Synth90k,Synth Text
水平文本
(最后一个基本不用上)

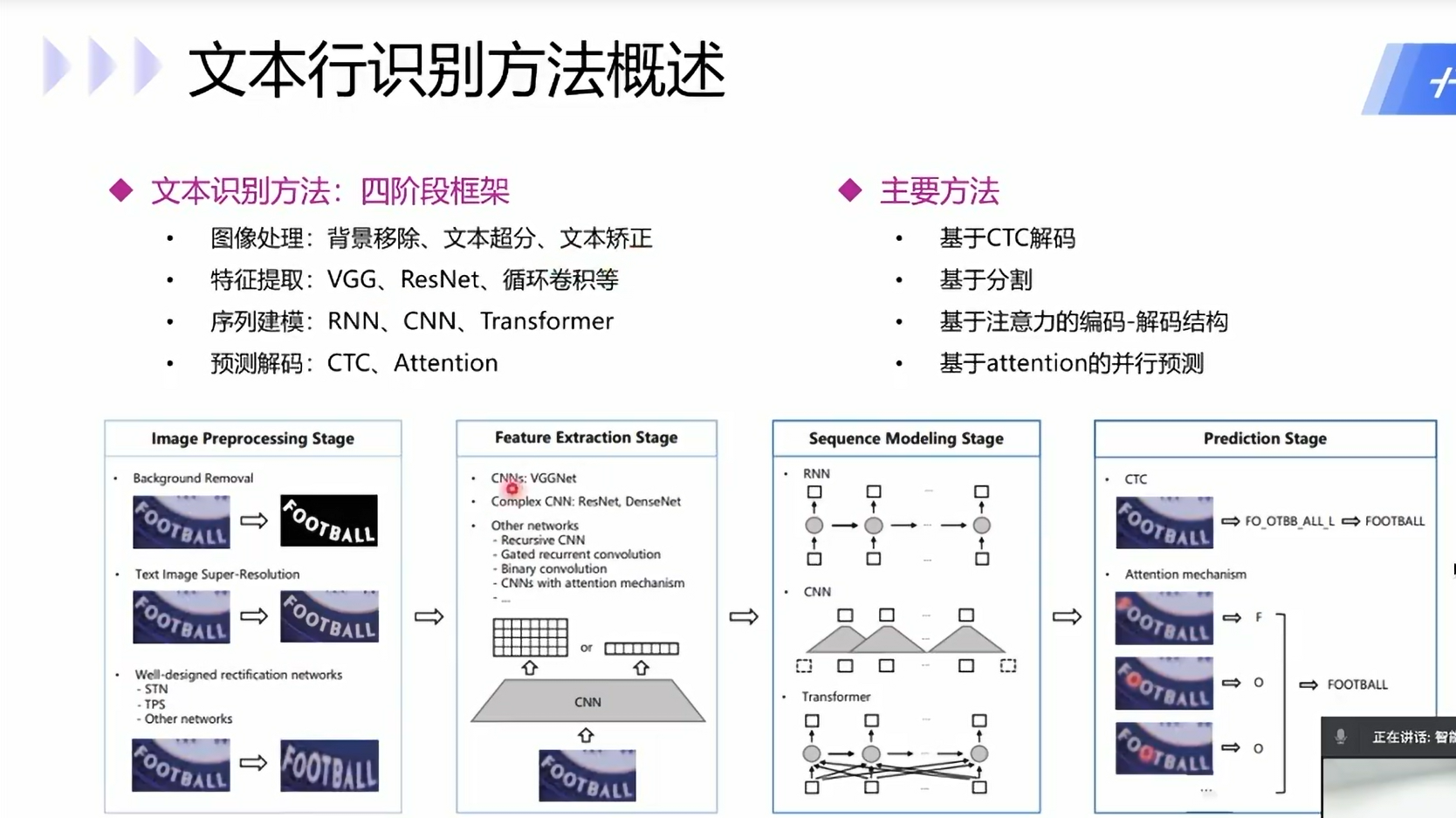
识别方法:
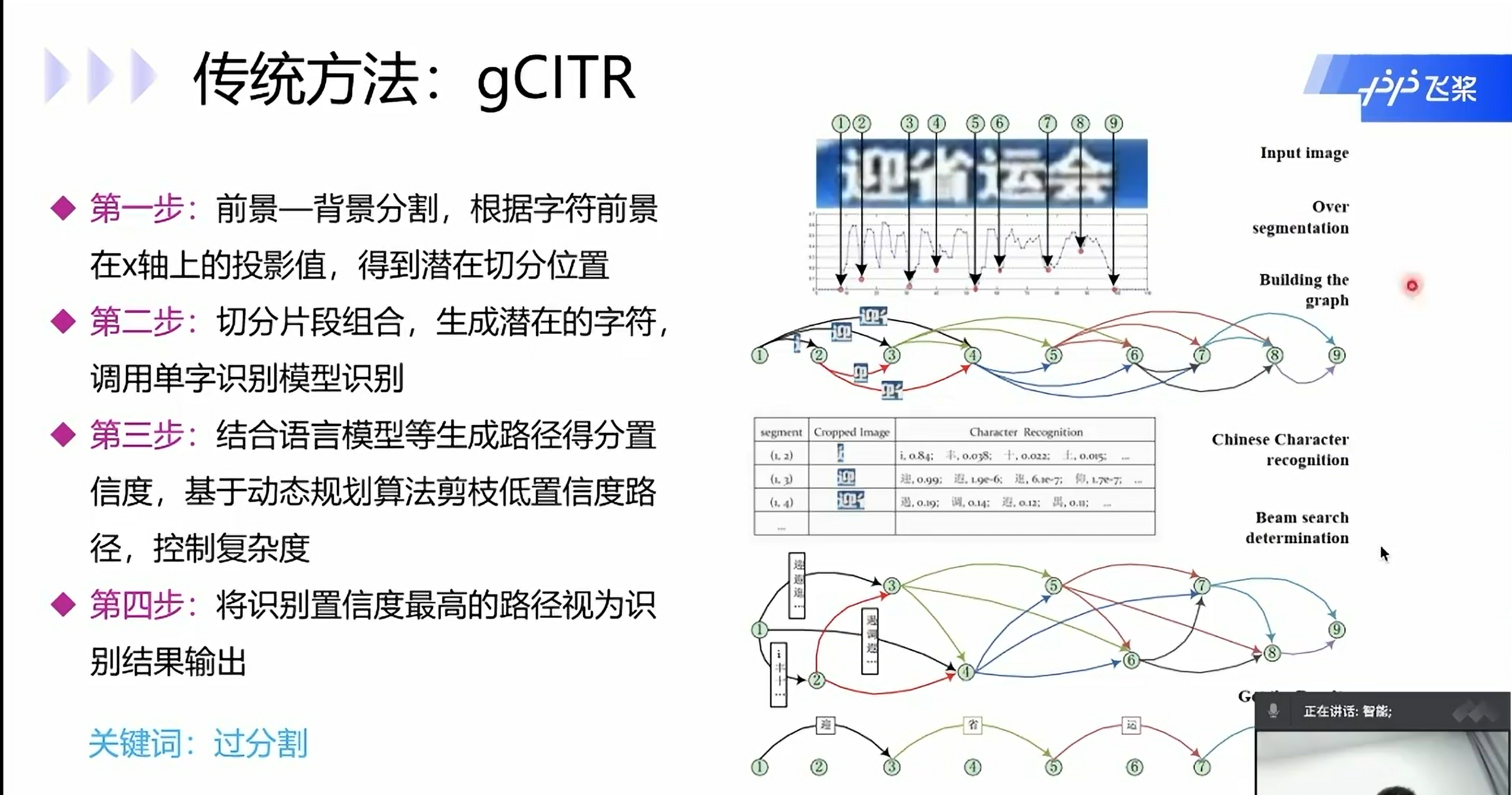
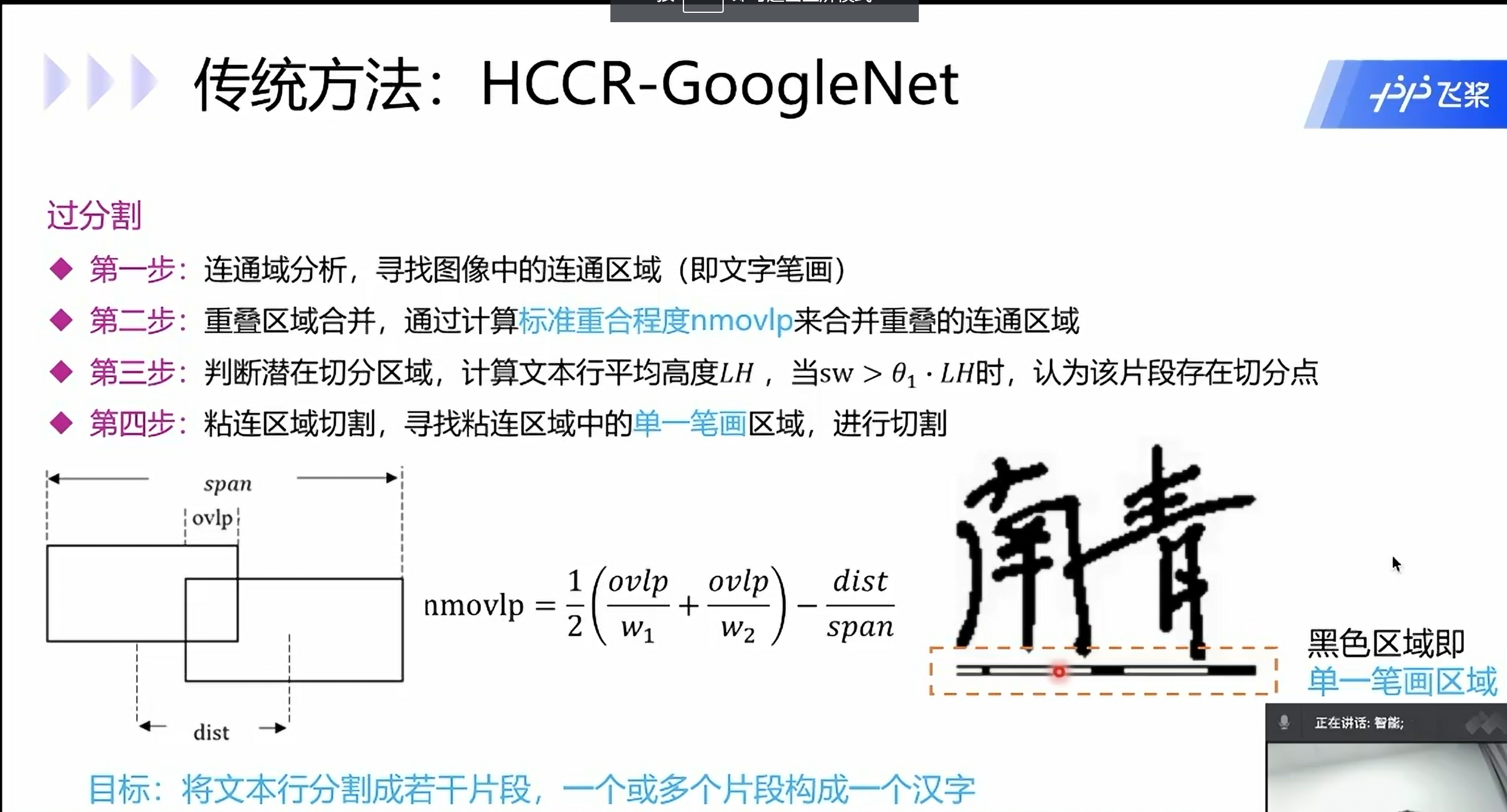
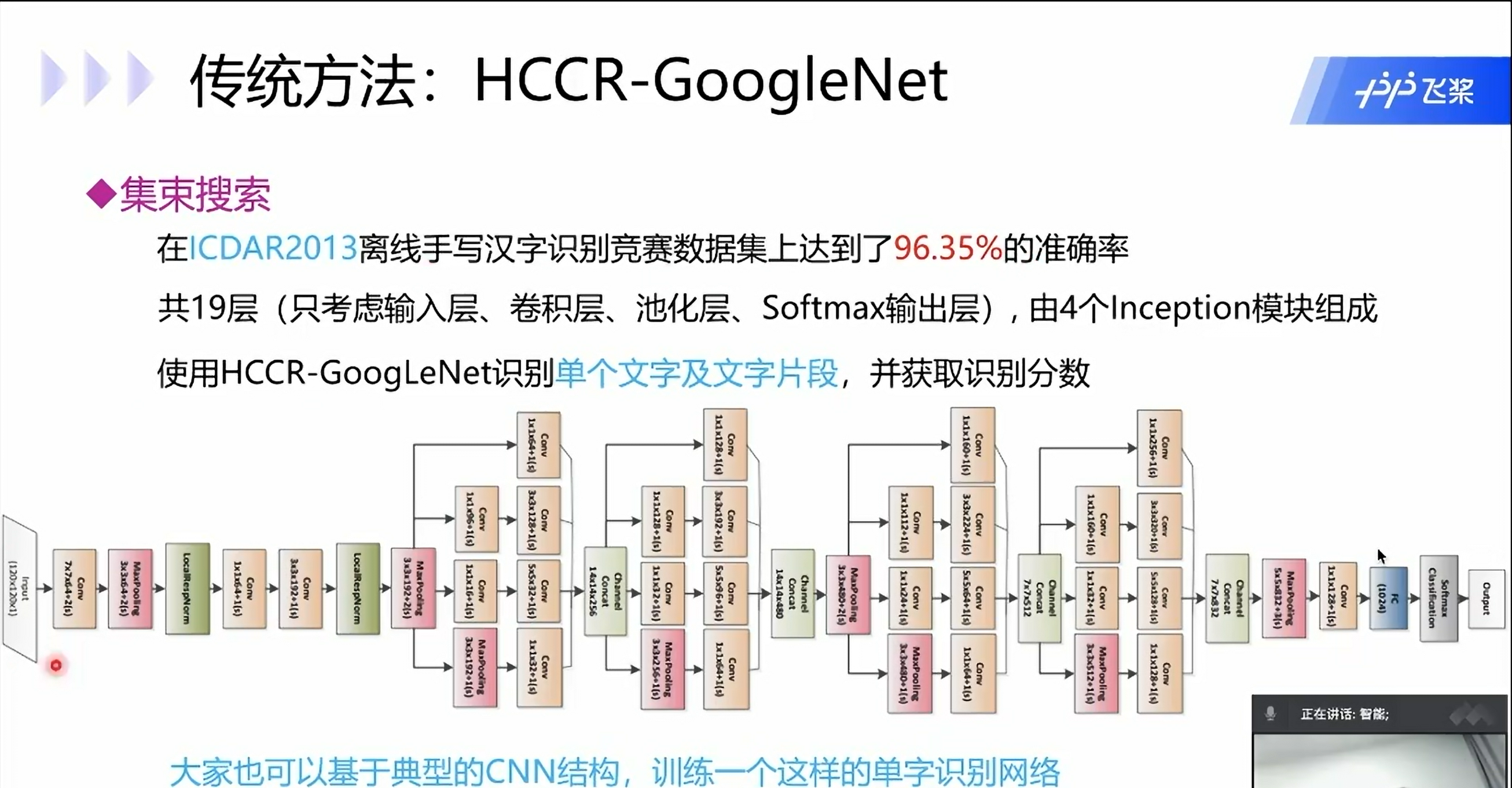
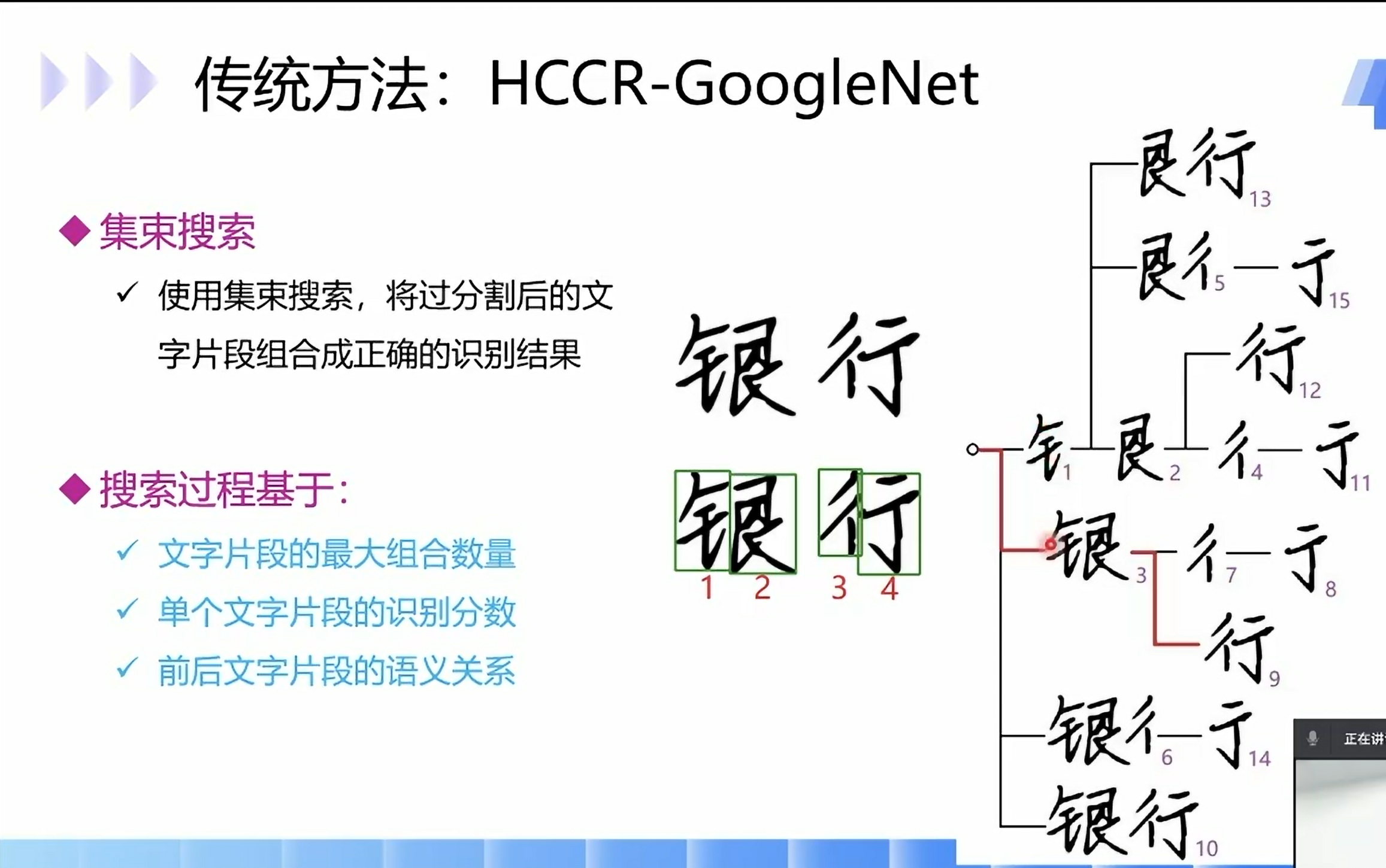
传统方法:
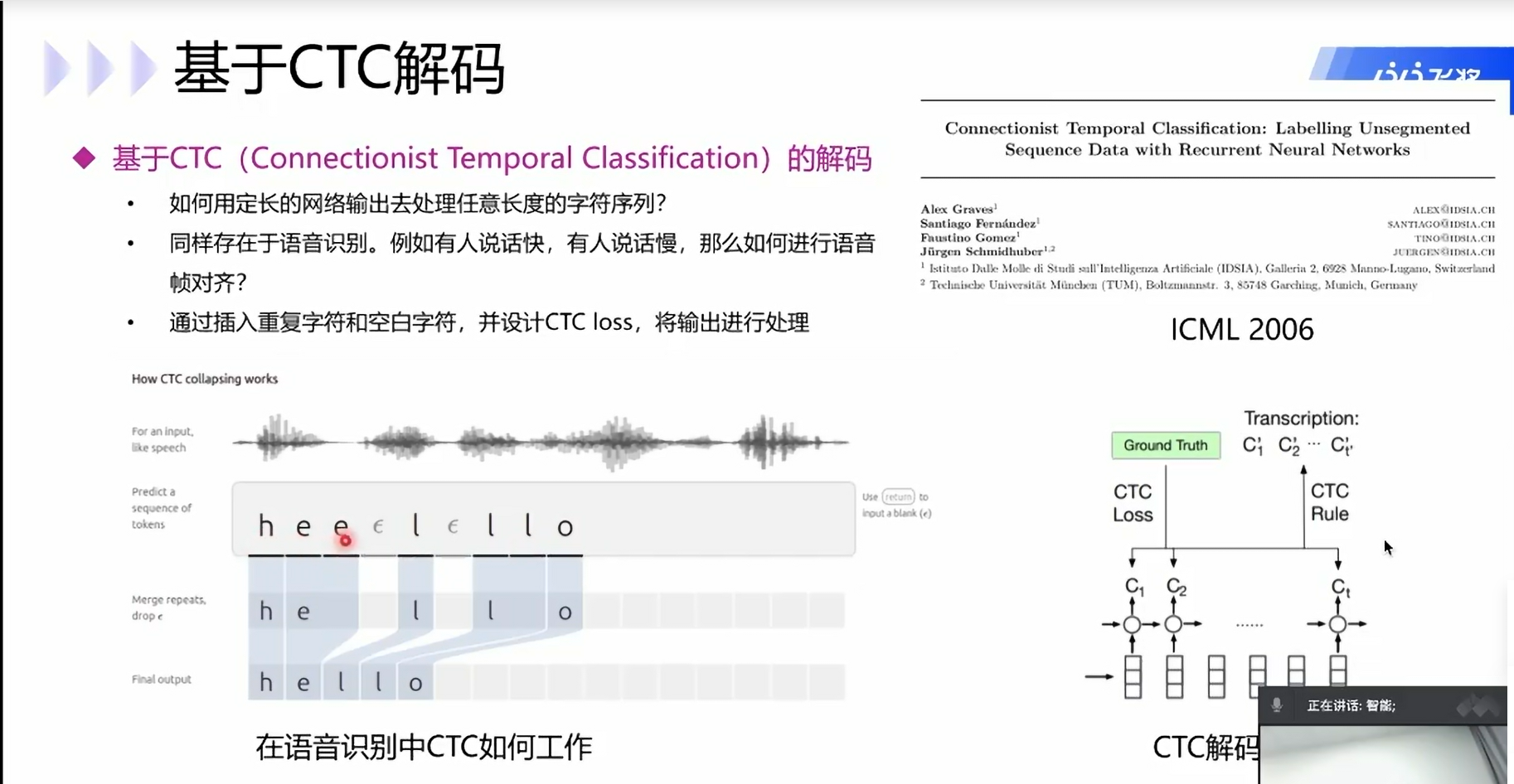
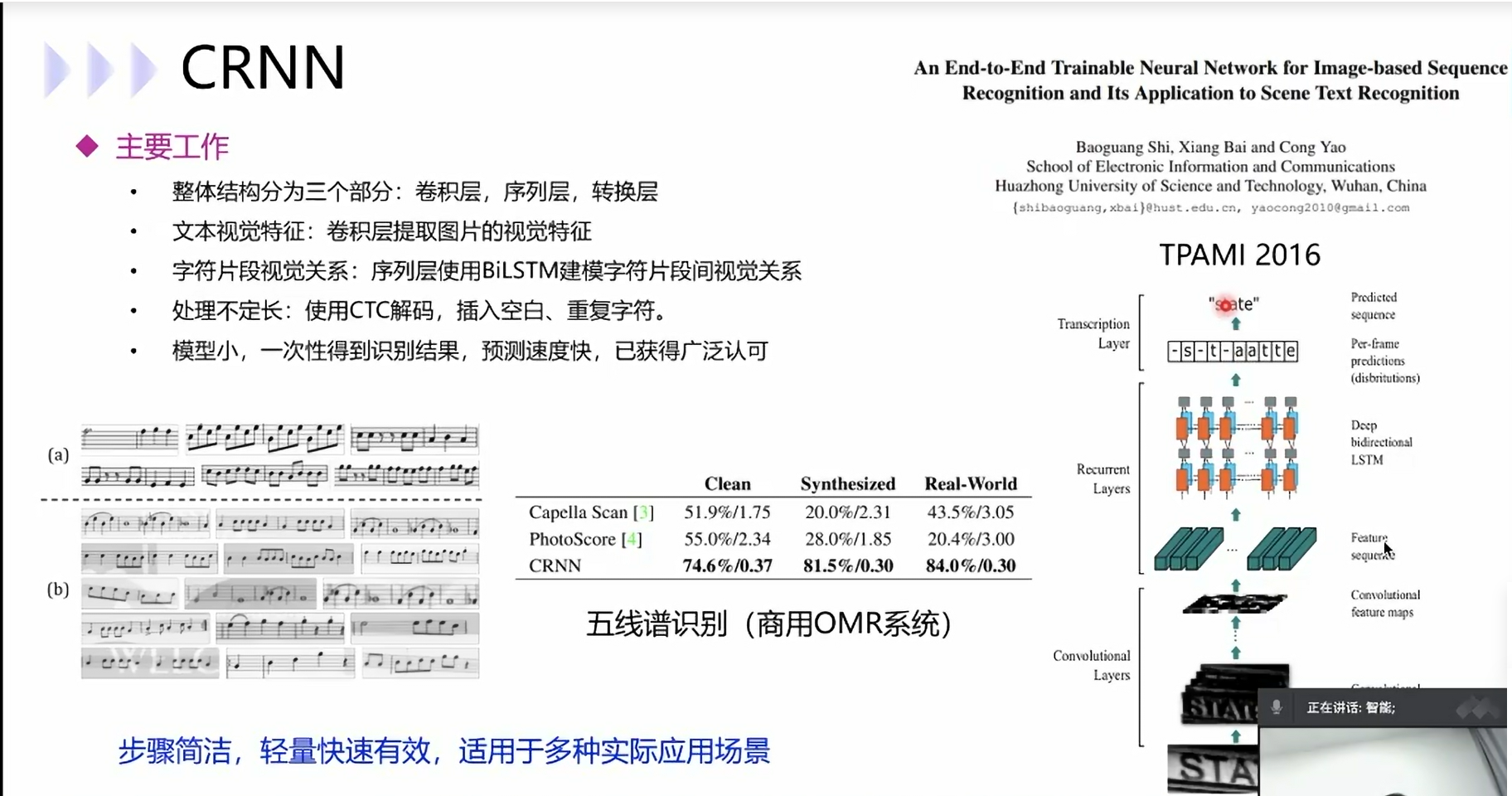
GTC
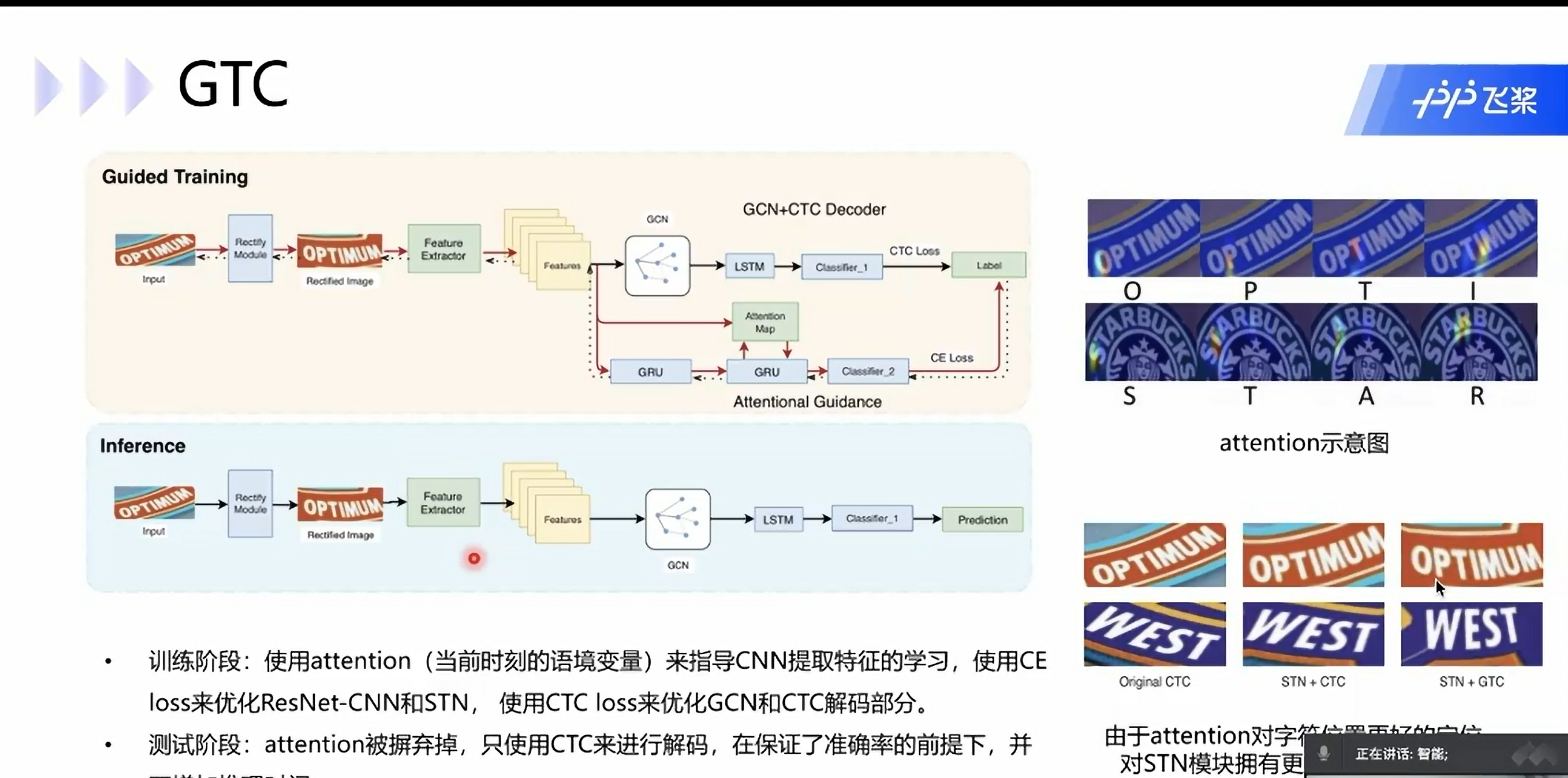
文本不规则解决

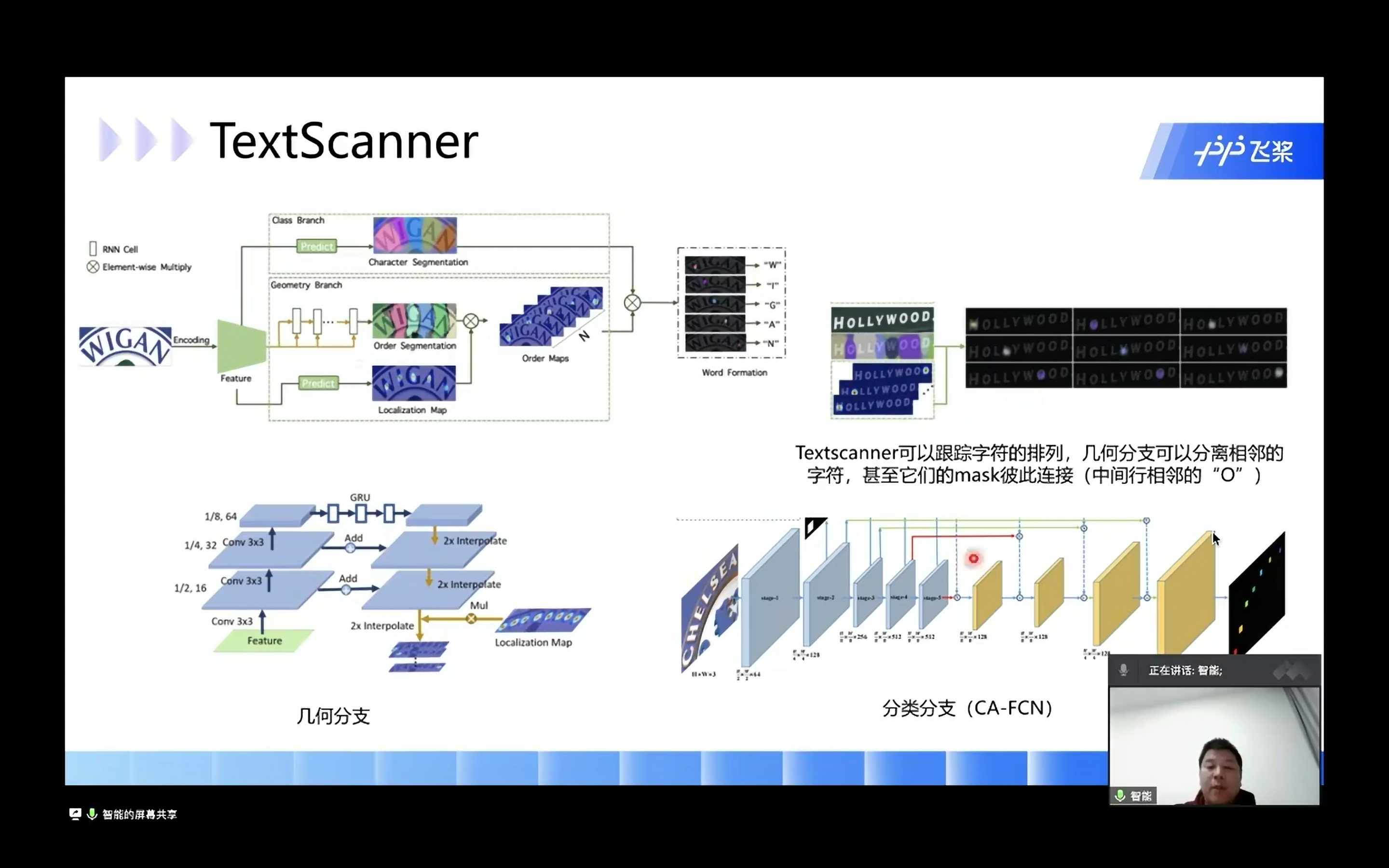
TextScanner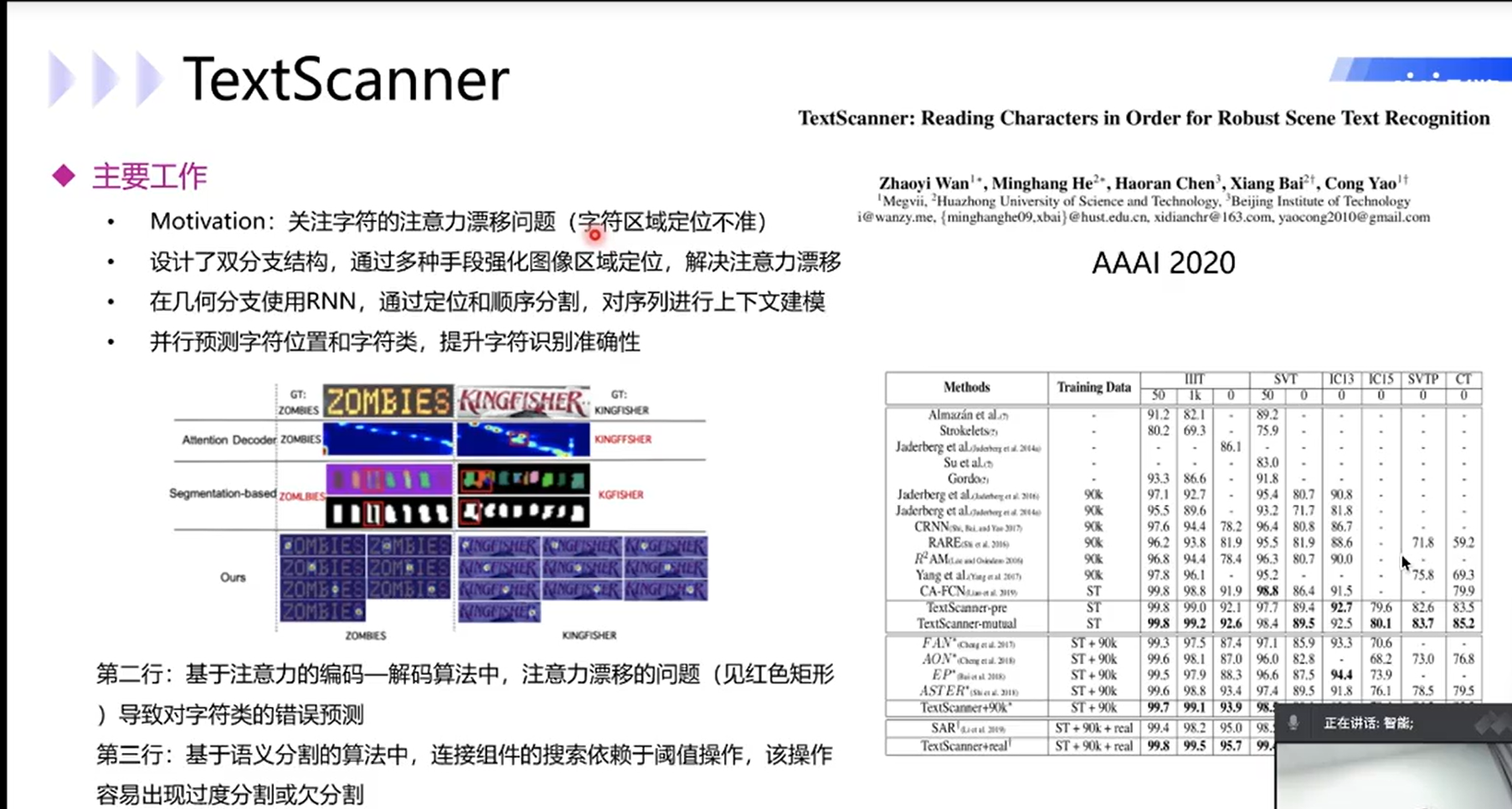

NRTR
自注意力模型:
更适合长文本识别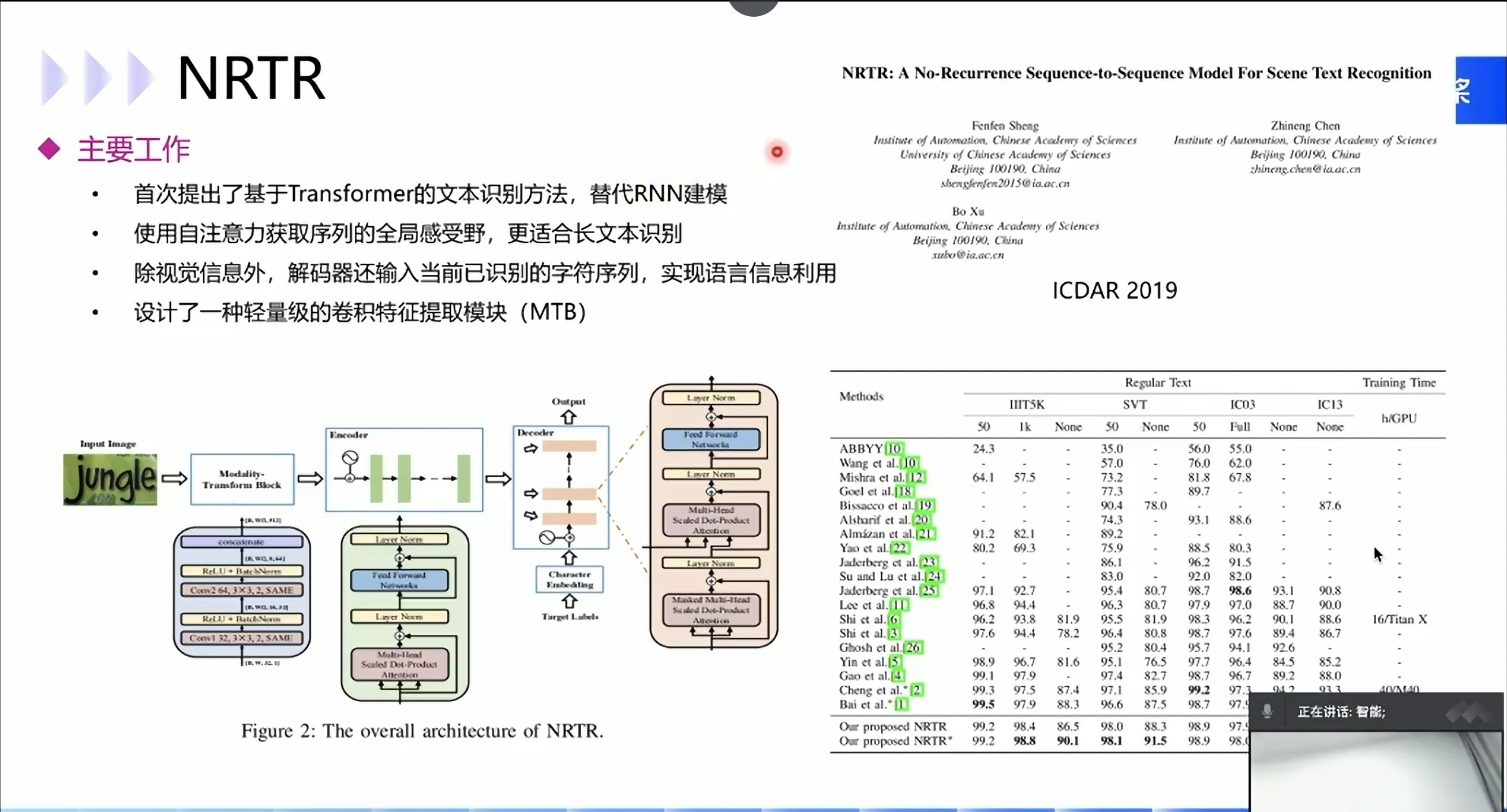
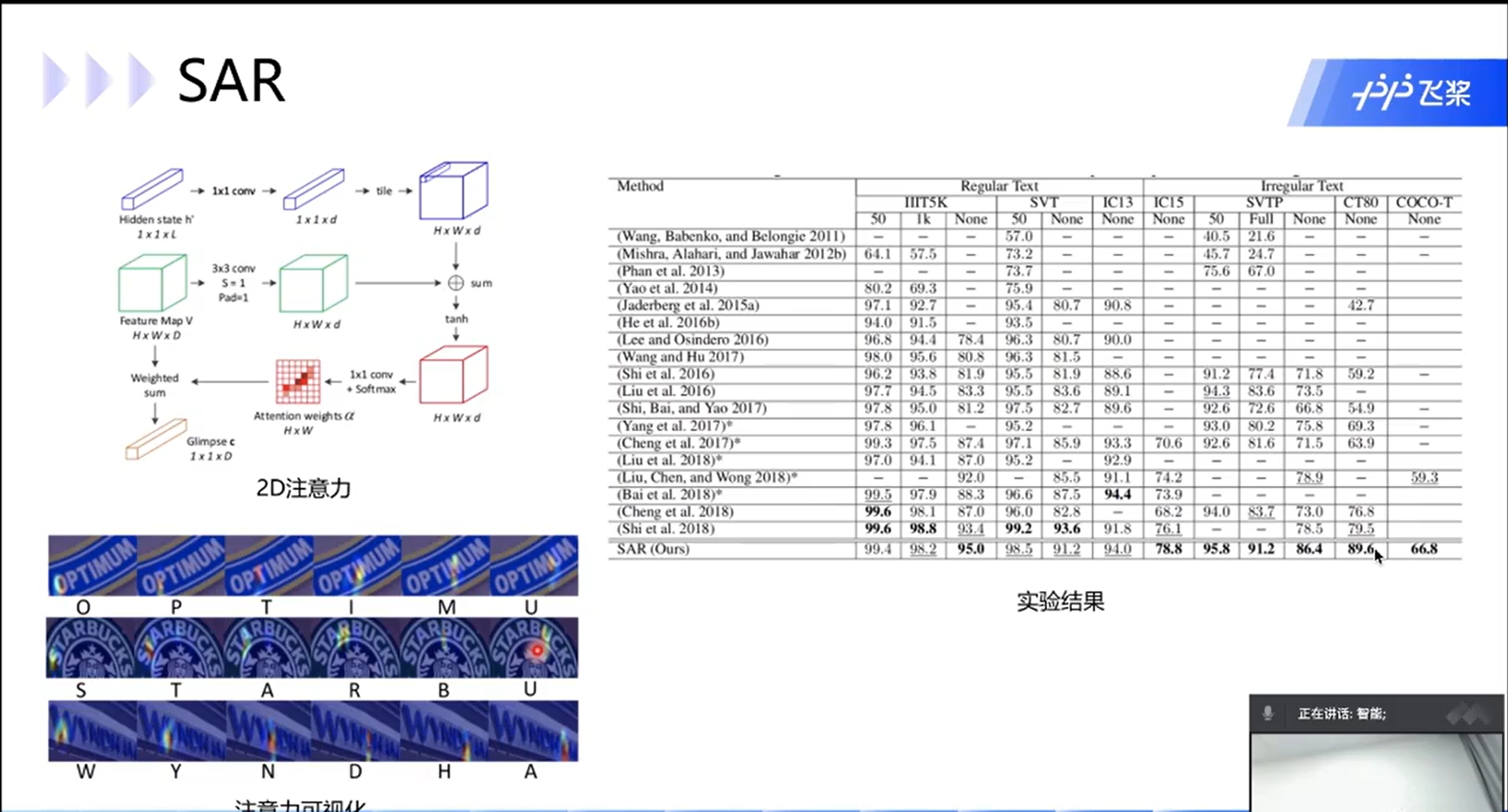
SAR
1D变2D效果更好
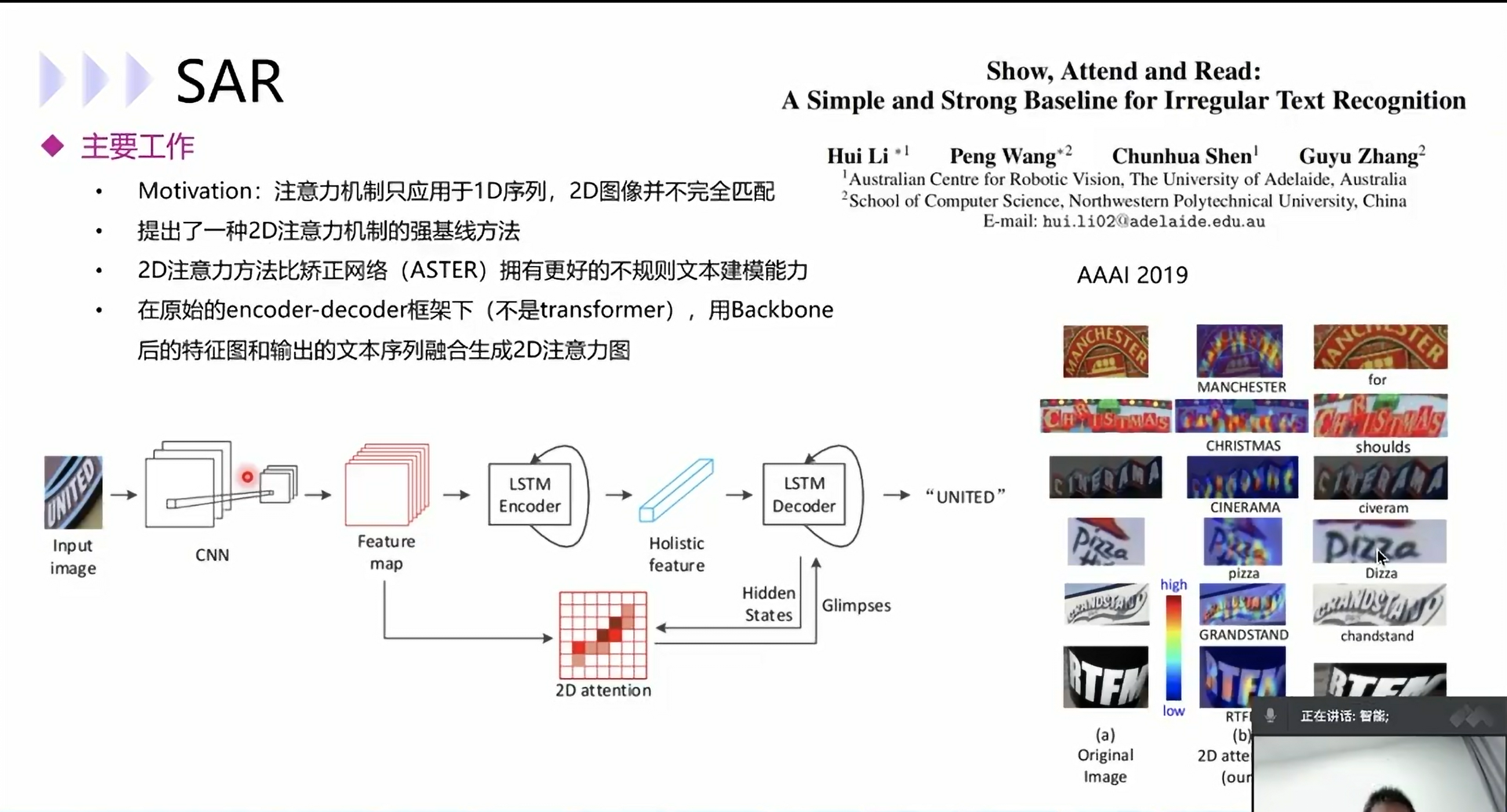
语言信息、对其信息、视觉信息都有用上,就是会更慢一点
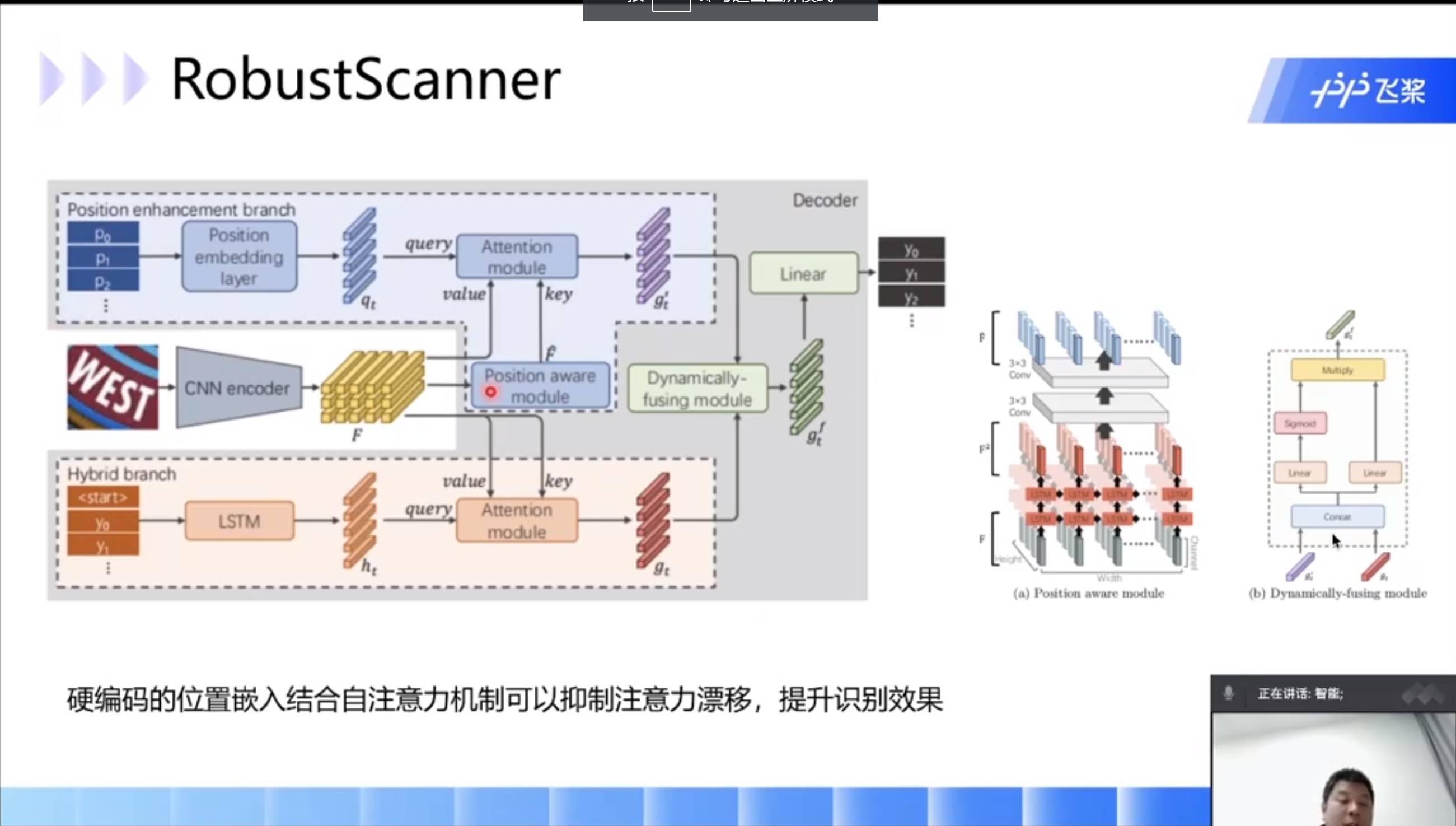
RobustScanner

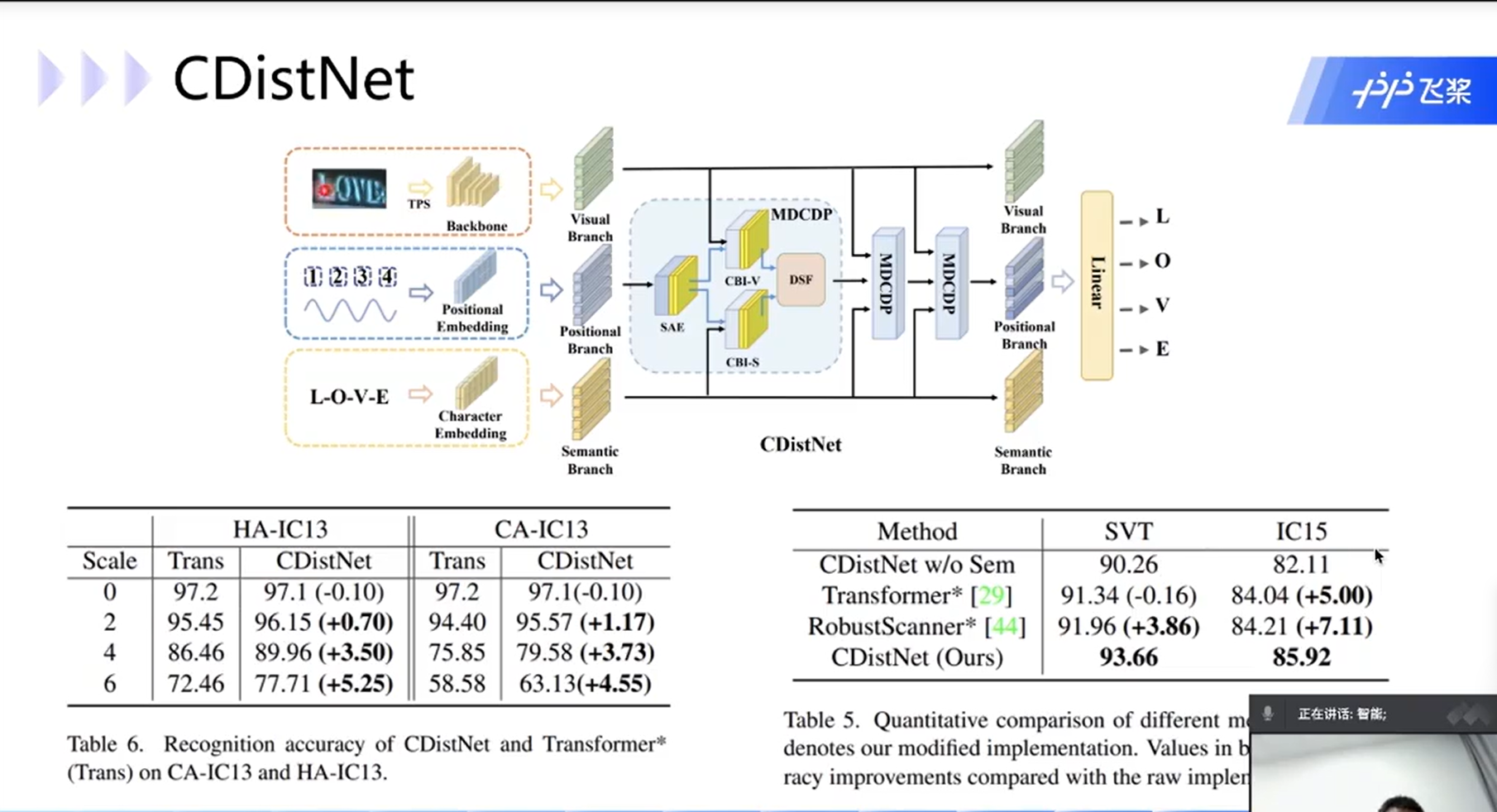
CDistNet

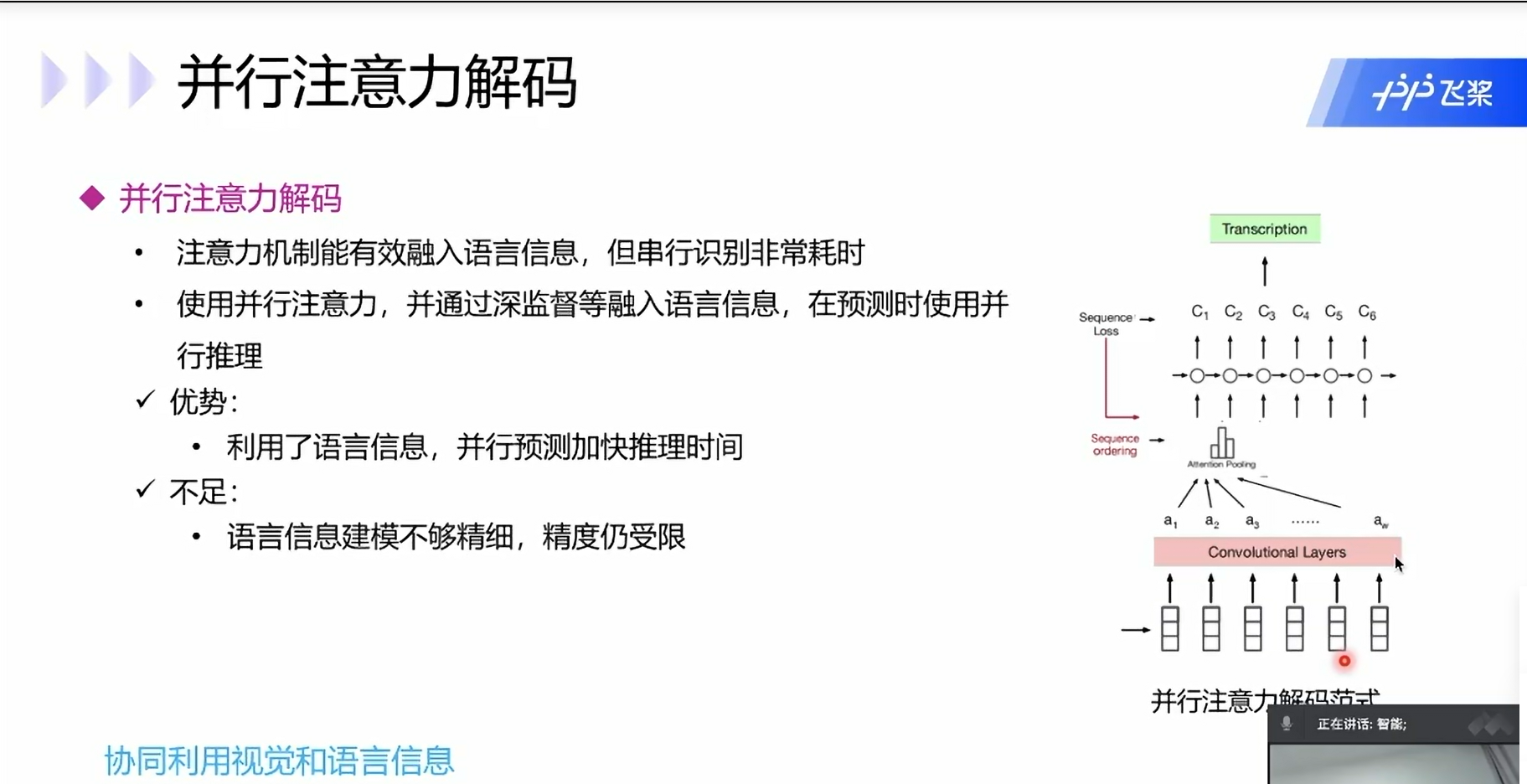
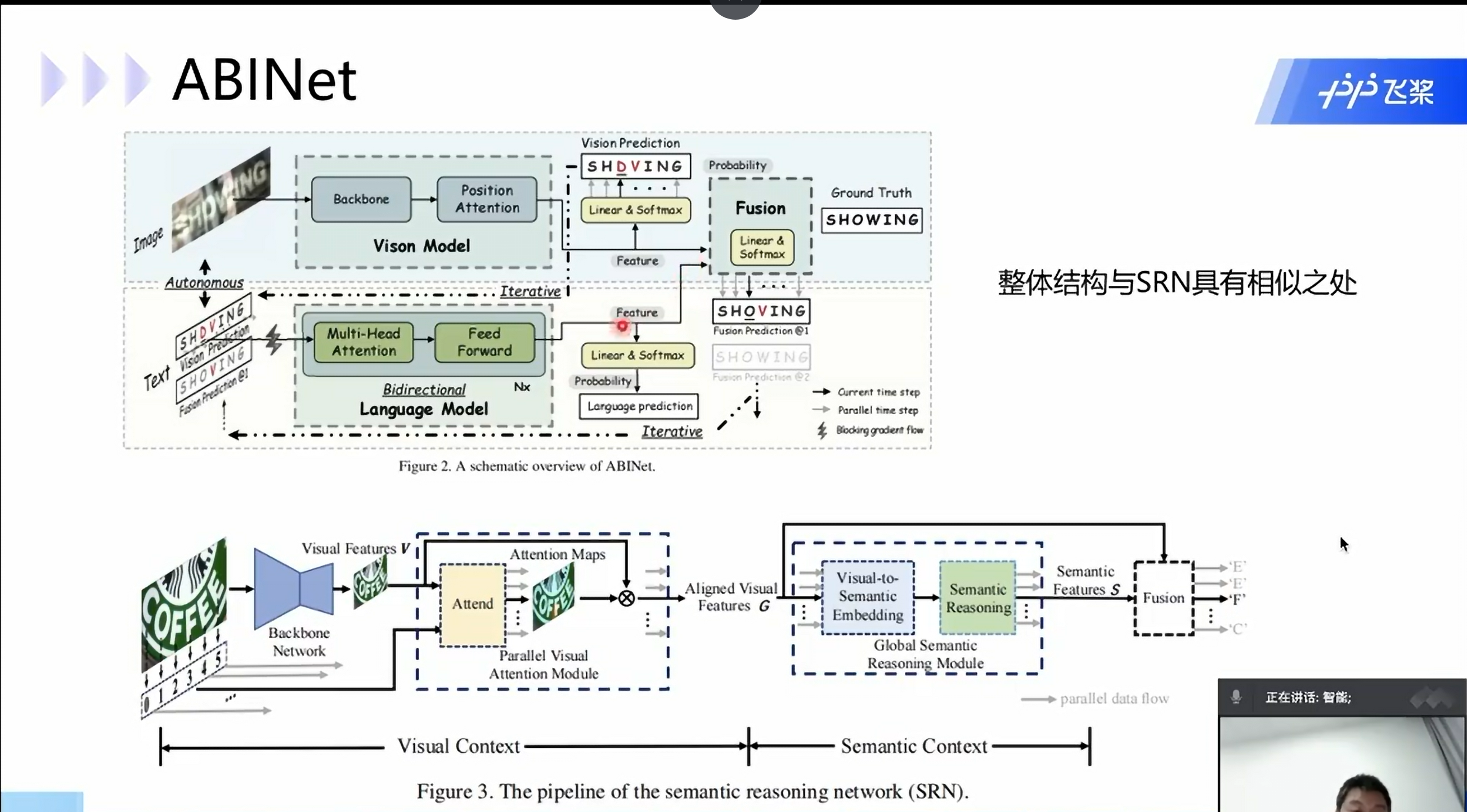
并行注意力解码
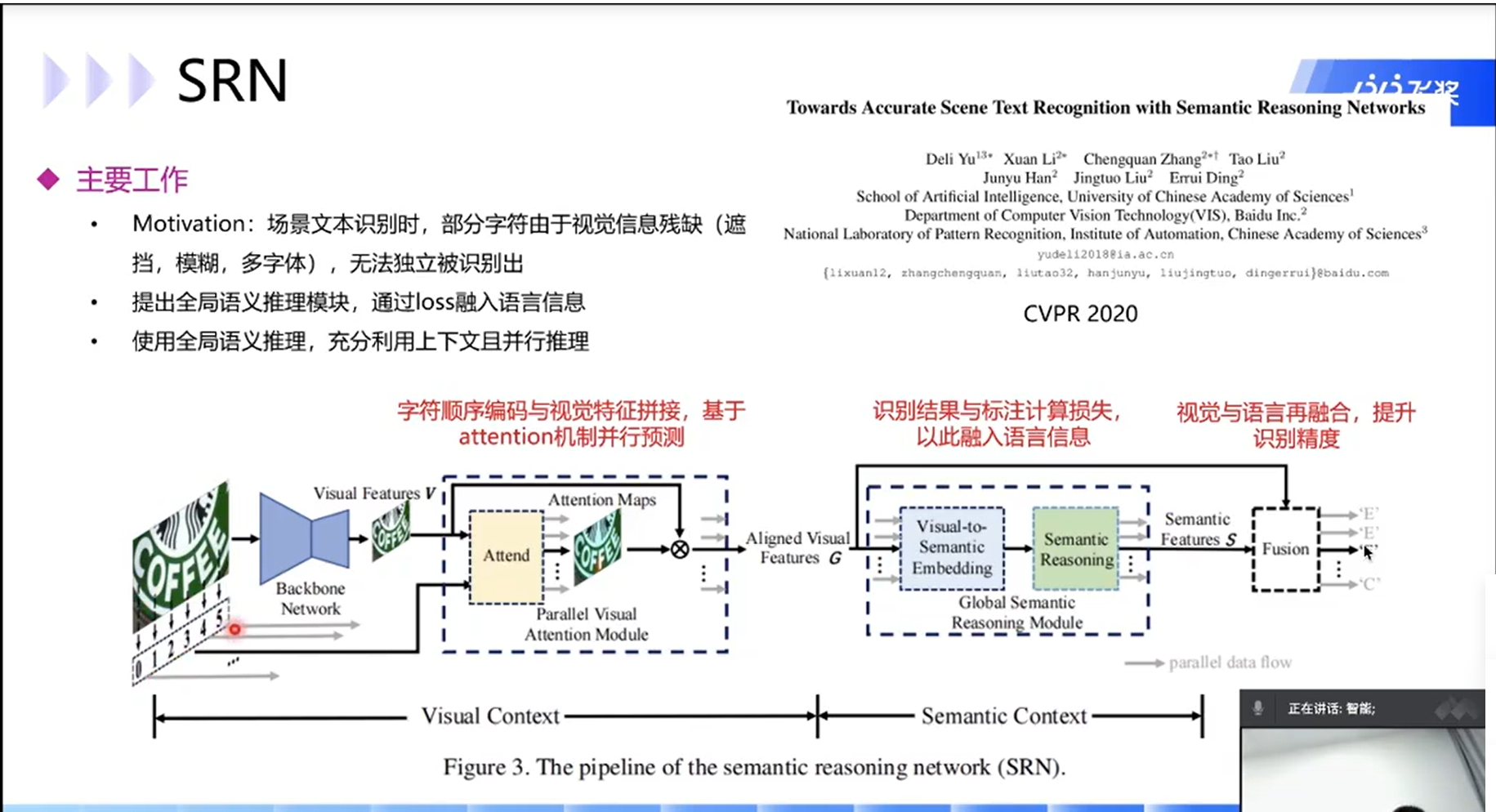
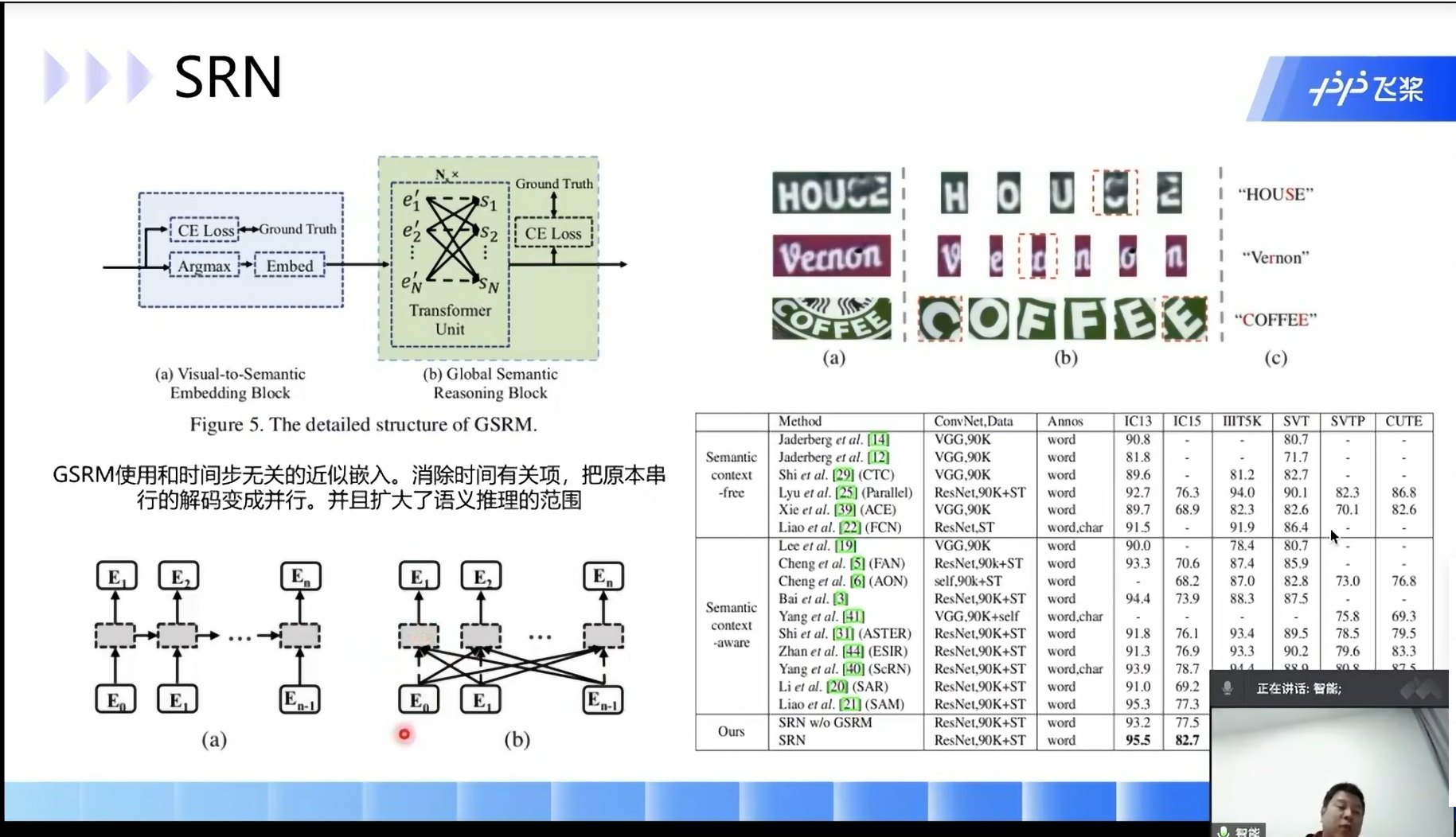
visionLAN

小结: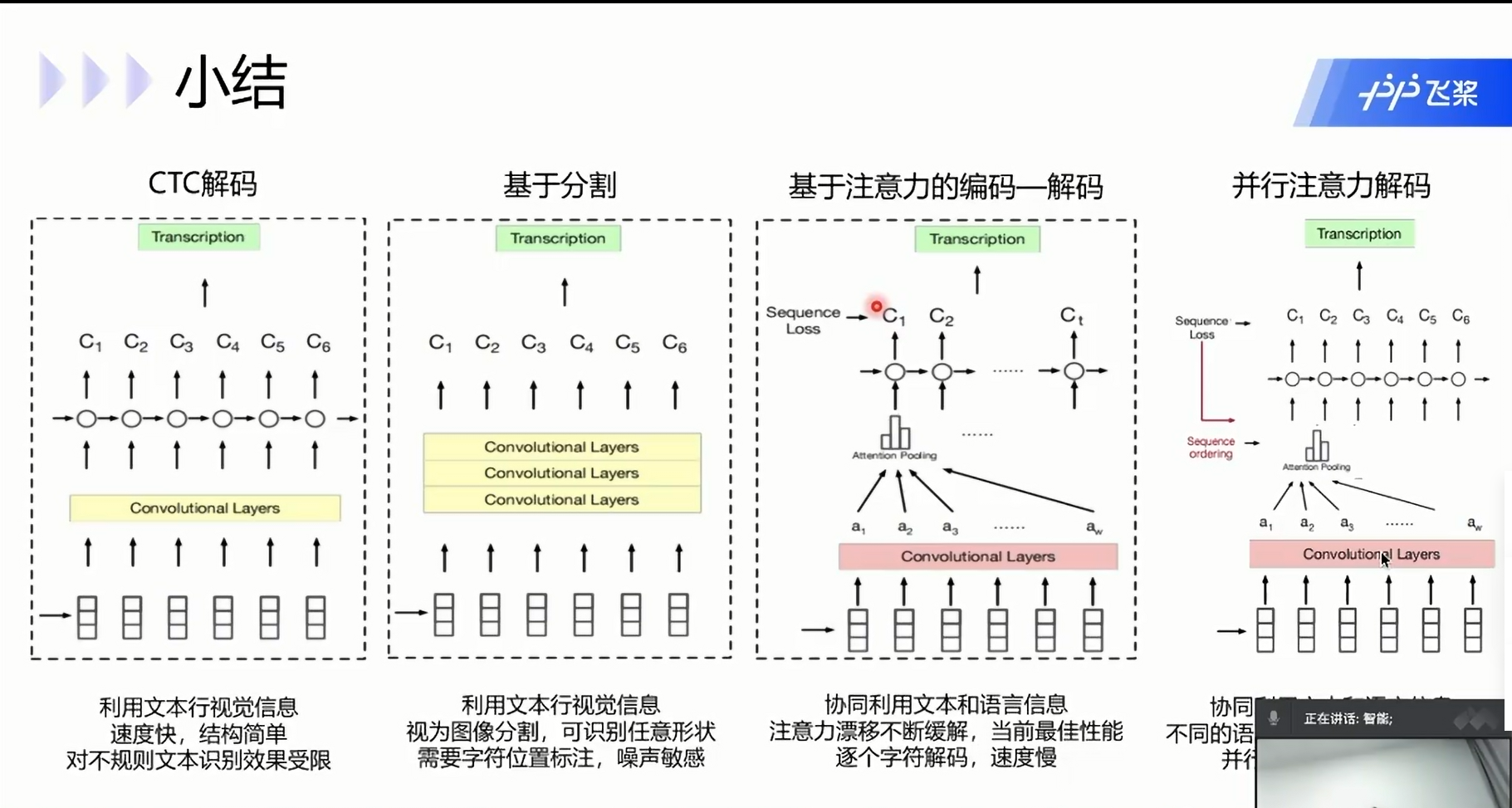

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 2
2 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)