
【大模型RAG】一文搞定大模型知识库RAG:Milvus 2.5 + BM25 + BGE重排 +大模型
本文基于 Milvus 2.5 的混合检索能力,结合 BGE 向量化与 BM25 全文检索,配合 BGE Reranker 重排,最终调用 GPT-4.1-mini 生成高质量回答,搭建了一个端到端的 RAG 问答/推荐 Demo,适用于电商、企业知识库等场景。
背景介绍
在电商场景下,用户常常需要从海量商品描述、用户评价等非结构化文本中快速获取答案或推荐。传统的全文检索(如 BM25)在精确度上有一定局限,而纯向量检索(如基于 BGE 生成的稠密向量)又可能错过关键词匹配的精细信息。为此,Milvus 2.5 提供了混合检索(Hybrid Retrieval)能力,将稠密向量检索和稀疏 BM25 检索相结合,进一步通过 BGE-reranker 对结果重排,最后调用 OpenAI(或本地 ChatGLM3)生成最终答案,形成端到端的 RAG(Retrieval-Augmented Generation)问答系统。本文将基于一份完整的 milvus_rag_hybrid.py 脚本,从环境准备、代码解析到交互示例,带你快速上手电商领域的混合检索与问答方案。
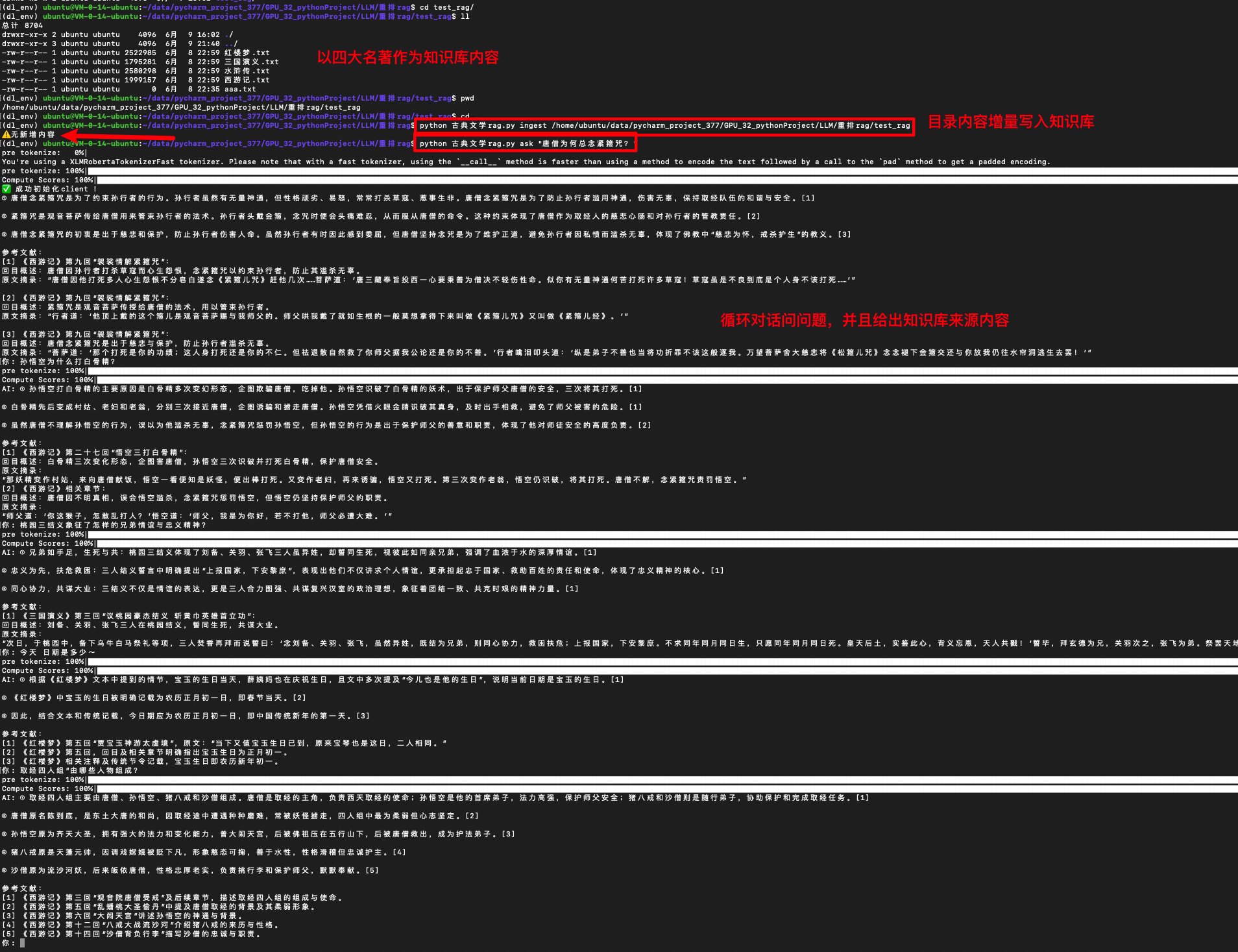
由于电商系统涉及数据比较麻烦,本人以4大名著来演示,详细代码会新出一个文章

关键词
-
Milvus 2.5
-
Hybrid Retrieval
-
BM25 全文检索
-
BGE 向量化
-
BGE Reranker
-
RAG 问答
-
OpenAI 代理
-
ChatGLM3
目录
-
环境准备
-
脚本总体结构
-
关键模块解析
-
3.1 代理与环境变量配置
-
3.2 Milvus 集群连接与 Collection 保证
-
3.3 嵌入函数与重排函数初始化
-
3.4 文本批量导入(ingest)
-
3.5 混合检索与问答生成(ask)
-
-
交互演示
-
总结与后续优化建议
1. 环境准备
-
Milvus 2.5 Stand-alone:通过 Docker 一键部署(暴露 19530 gRPC 和 9091 HTTP/WebUI 端口)。
-
Python 依赖:
pip install -U pymilvus==2.5.* pymilvus-model sentence-transformers openai langchain-
模型权重:BGE-large-zh-v1.5、BGE-reranker-v2-m3 可提前下载并缓存至本地,加速首次调用。
-
网络代理(若在国内访问 OpenAI 或 Hugging Face 出现超时):
os.environ["OPENAI_API_BASE"] = "https://api.openai-proxy.org/v1"
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"2. 脚本总体结构
3. 关键模块解析
3.1 代理与环境变量配置
import os
# OpenAI 代理设置(官方 Key 可省略)
os.environ["OPENAI_API_BASE"] = "https://api.openai-proxy.org/v1"
os.environ["OPENAI_API_KEY"] = "sk-xxx"
# HF 镜像源代理
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
-
目的:解决国内网络对 OpenAI、Hugging Face Hub 的访问超时问题;
-
说明:若使用官方直连,删除或注释掉相关环境变量即可。
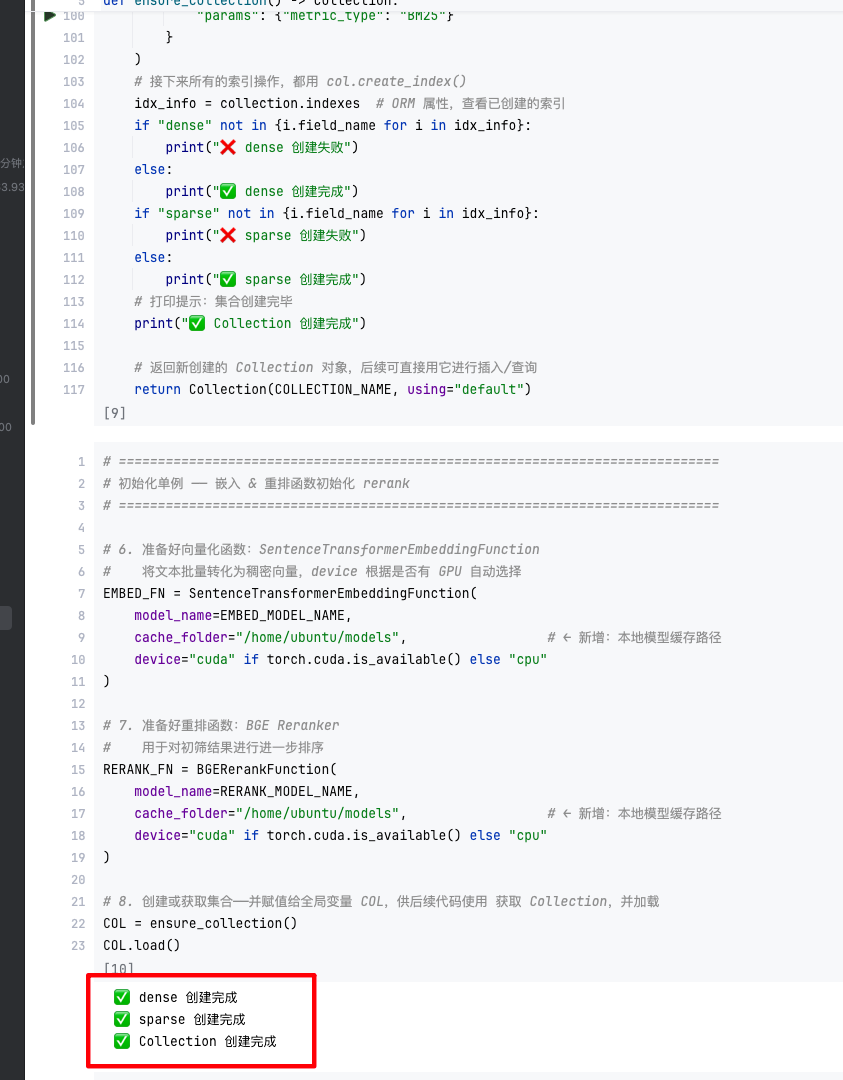
3.2 Milvus 集群连接与 Collection 保证
from pymilvus import connections, utility, Collection, FieldSchema, CollectionSchema, DataType, Function, FunctionType
connections.connect(alias="default", host="127.0.0.1", port="19530")
def ensure_collection() -> Collection:
if COLLECTION_NAME in utility.list_collections(using="default"):
return Collection(COLLECTION_NAME, using="default")
# 定义字段、BM25 函数算子
# 创建 Collection 并建立稠密(HNSW)和稀疏(BM25 倒排)索引
...-
集合结构:
-
doc_id(VARCHAR 主键)
-
text(VARCHAR,支持分词全文检索)
-
dense(FLOAT_VECTOR,1024 维,用于向量检索)
-
sparse(SPARSE_FLOAT_VECTOR,由 BM25 算子自动生成)
-
-
索引:
-
HNSW 索引加速余弦相似度检索
-
稀疏倒排索引支持 BM25 文本检索
-
3.3 嵌入函数与重排函数初始化
from pymilvus.model.dense import SentenceTransformerEmbeddingFunction
from pymilvus.model.reranker import BGERerankFunction
EMBED_FN = SentenceTransformerEmbeddingFunction(
model_name=EMBED_MODEL_NAME, device=“cuda” 或 “cpu”
)
RERANK_FN = BGERerankFunction(
model_name=RERANK_MODEL_NAME, device=“cuda” 或 “cpu”
)-
EMBED_FN:将用户 query 和文档分块文本映射为 1024 维稠密向量;
-
RERANK_FN:对两路召回结果按 query 再次打分,并返回排序后的 top_n 文档。
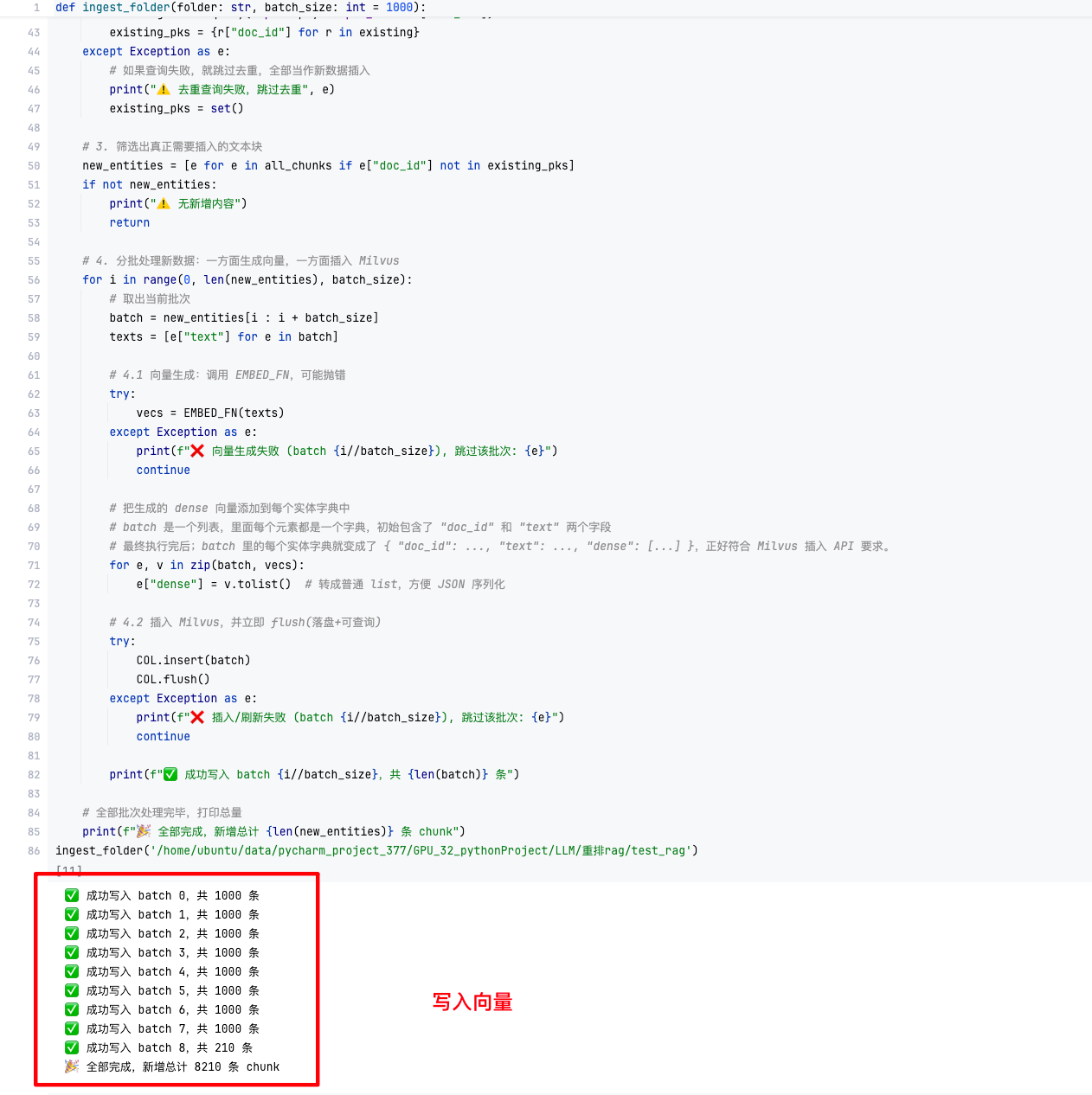
3.4 文本批量导入(ingest)
def ingest_folder(folder: str, batch_size: int=1000):
# 1. 读取所有 .txt 文件并按 512 字符切分,计算 MD5 主键
# 2. 批量去重:通过 expr “doc_id in […]” 查询已存在条目
# 3. 调用 EMBED_FN 批量生成 dense 向量
# 4. 分批插入并 flush-
去重策略:一次性查询所有待入库分块的 MD5,避免多次 round-trip;
-
分批处理:控制单次插入规模,防止内存或网络压力过大;
-
容错设计:对向量生成和插入都做异常捕获,跳过失败批次并继续。
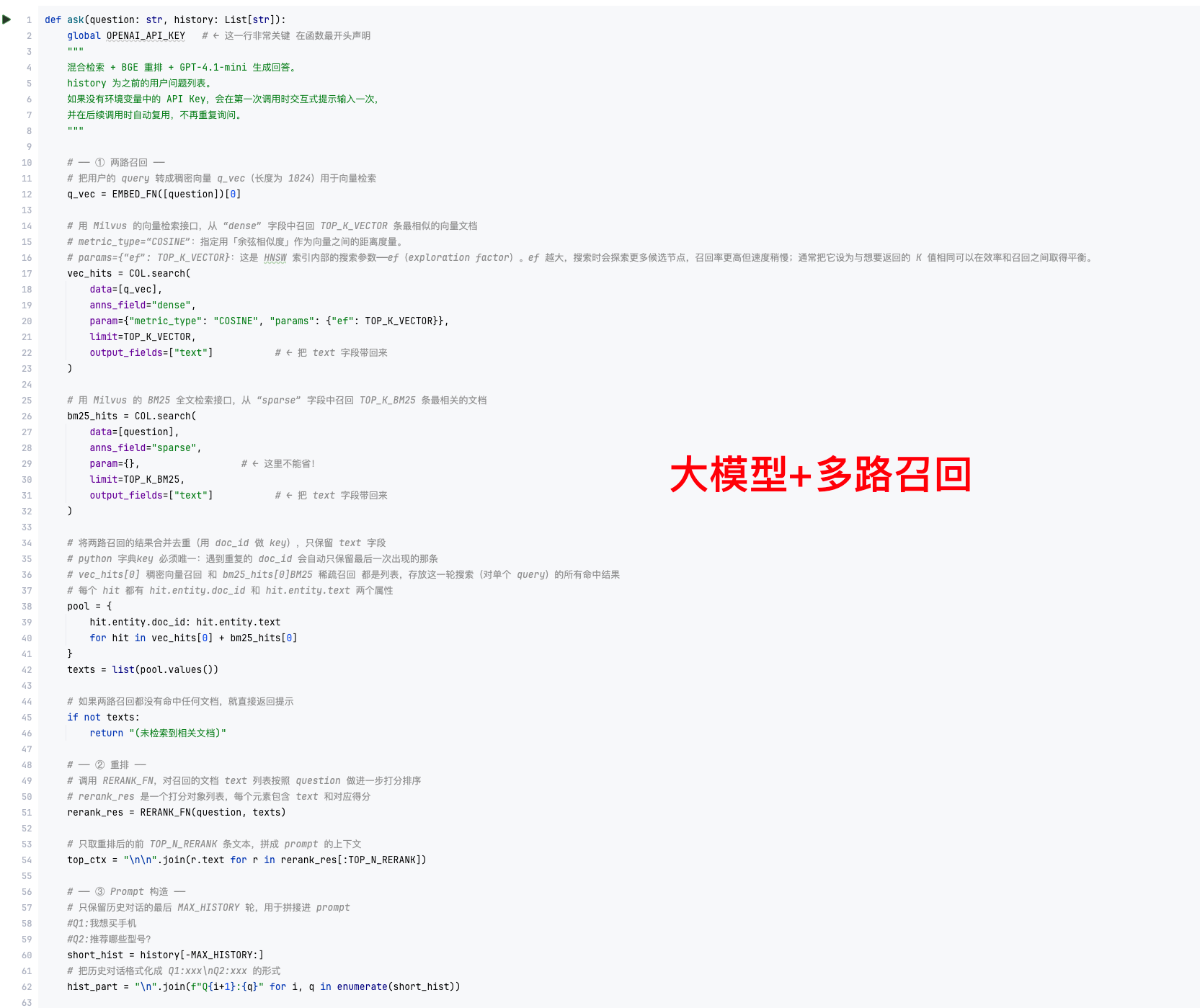
3.5 混合检索与问答生成(ask)
def ask(question: str, history: List[str]):
# 1. 两路召回:向量检索(TOP_K_VECTOR)、BM25 检索(TOP_K_BM25)
# 2. 合并去重候选文档
# 3. RERANK_FN 重排,取前 TOP_N_RERANK 条构建上下文
# 4. 拼接系统、检索上下文、历史对话,调用 OpenAI 生成最终回答-
混合召回优势:BM25 捕获关键词匹配,向量检索捕获语义相似度,两者互补;
-
重排:进一步利用 BGE reranker 提升精排质量,保证 top_n 文档最相关;
-
RAG 生成:将高质量检索结果注入 prompt,通过 GPT-4.1-mini(或 ChatGLM3)产出连贯答案。
4. 交互演示
# 导入本地 docs 目录下所有 txt 文档
python milvus_rag_hybrid.py ingest ./docs
# 提问示例
python milvus_rag_hybrid.py ask "电商推荐系统常见算法有哪些?"
你: 电商推荐系统如何根据用户浏览历史推荐商品?
AI: ① 协同过滤…② 内容召回…③ 混合召回… [引用]-
效果:在几十毫秒到几百毫秒内完成检索与生成,可用于在线问答与推荐;
-
可扩展:支持增量更新,新的文档放入 docs 目录后重复 ingest 即可。
5. 总结与后续优化建议
-
总结:本文基于 Milvus 2.5 的混合检索能力,结合 BGE 向量化与 BM25 全文检索,配合 BGE Reranker 重排,最终调用 GPT-4.1-mini 生成高质量回答,搭建了一个端到端的 RAG 问答/推荐 Demo,适用于电商、知识库等场景。
-
优化方向:
-
检索速度:调优 HNSW 与 BM25 索引参数(如 efConstruction、ef)和 shard 并行。
-
模型轻量化:将 GPT-4-mini 替换为本地 ChatGLM3-6B(量化后)以降低成本。
-
多模态扩展:接入图像检索、商品属性结构化数据,实现跨模态召回。
-
在线服务化:将脚本封装为 FastAPI/Flask 服务,并加上缓存与限流策略。
-
6. 点赞·转发·收藏
如果本文对你有所帮助,欢迎在 CSDN 上 点赞、收藏、转发,一起探讨 Milvus RAG 和大模型在电商场景的更多应用;感兴趣可以在评论区留言交流!
也可关注我,获取更多 AI、向量检索与 RAG 实践干货~

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)