
【多模态目标检测数据集】【LLVIP】LLVIP:一个用于弱光视觉的可见光-红外配对数据集
在弱光条件下,由于有效目标区域的丢失,图像融合、行人检测和图像转换等多种视觉任务面临极大挑战。此时,红外与可见光图像的联合使用可同时提供丰富的细节信息和有效目标区域。本文提出了LLVIP数据集——专为弱光视觉设计的可见光-红外配对数据集。该数据集包含33672张图像(即16836组配对),其中大多数采集于极暗场景,所有图像均经过严格的时空对齐处理,并对行人目标进行了标注。我们通过与其他可见光-红外
LLVIP: A Visible-infrared Paired Dataset for Low-light Vision
LLVIP:一个用于弱光视觉的可见光-红外配对数据集
ICCV 2021

摘要
在弱光条件下,由于有效目标区域的丢失,图像融合、行人检测和图像转换等多种视觉任务面临极大挑战。此时,红外与可见光图像的联合使用可同时提供丰富的细节信息和有效目标区域。本文提出了LLVIP数据集——专为弱光视觉设计的可见光-红外配对数据集。该数据集包含33672张图像(即16836组配对),其中大多数采集于极暗场景,所有图像均经过严格的时空对齐处理,并对行人目标进行了标注。我们通过与其他可见光-红外数据集的对比实验,评估了图像融合、行人检测及图像转换等主流视觉算法在该数据集上的性能。实验结果不仅验证了融合技术对图像信息的互补增强作用,同时揭示了现有三类视觉算法在极端弱光环境下的不足。我们相信LLVIP数据集将通过推动极弱光场景下的图像融合、行人检测和图像转换研究,为计算机视觉领域的发展作出贡献。
1.引言
在质量受限的可见光图像(如低照度条件下因有效目标区域损失)上进行各类视觉任务极具挑战性。不受光照条件限制的红外图像可起到信息补充作用:可见光图像含有丰富纹理与细节信息,但低照度环境下难以辨识物体;红外图像通过物体表面温度场成像,能突出行人等目标,但缺乏纹理信息。可见光与红外图像融合可生成兼具丰富细节信息与有效目标区域的互补图像,进而应用于人类视觉感知、目标检测及视频监控领域。
图像融合的目标是从源图像中提取显著特征,并通过适当的融合方法将其整合到单一图像中。图像融合任务已发展出多种不同方法,其中深度学习算法[12,10,23]在该领域取得了显著成功。数据是构建精确深度学习系统的关键要素,因此需要可见光-红外配对数据集。TNO数据集[21]、KAIST多光谱数据集[7]、OTCBVS OSU彩色-热红外数据库[3]等均为实用数据集,但它们并非同时针对图像融合与低光照行人检测场景设计,即无法同时满足大规模、图像对齐、低光照环境及丰富行人样本等条件。因此,有必要提出一个包含低光照条件下大量行人的可见光-红外配对数据集。
我们构建了LLVIP,一个用于弱光视觉的可见光-红外配对数据集。通过由可见光相机和红外相机组成的双目相机采集图像,该设备能确保图像对在时间与空间上的一致性。每对图像经过配准和裁剪处理,使其具有相同的视场范围与尺寸。数据集中的图像在时空维度严格对齐,这使得该数据集适用于图像融合与图像转换任务。我们在LLVIP数据集上评估了多种融合算法,并进行了主客观分析。从多维度评估结果表明,现有融合方法面临较大挑战:算法难以捕捉弱光可见光图像的细节特征。典型图像转换算法在该数据集上的表现同样不佳。
该数据集包含大量弱光条件下的不同行人,这使得它适用于弱光行人检测。该检测任务的难点之一是图像标注,因为人眼难以辨识行人,更无法精准标注边界框。我们提出一种通过配准红外图像反向映射标注弱光可见光图像的方法,并完成了数据集中全部图像的标注工作。基于本数据集的弱光行人检测实验表明,该任务的性能仍有较大提升空间。
本文的主要贡献如下:1) 我们提出了LLVIP——首个面向多种低光视觉任务的可见光-红外配对数据集;2) 提出通过配准红外图像标注低光可见光图像的方法,并完成LLVIP中行人标注;3) 在LLVIP上评估图像融合、行人检测和图像转换任务的实验结果,发现该数据集对所有任务均构成巨大挑战。
2.相关工作
现有多种视觉任务的可见光与红外配对图像数据集,如TNO图像融合数据集[21]、INO视频分析数据集、OTCBVS OSU彩色-热成像数据库[3]、CVC-14[4]、KAIST多光谱数据集[7]以及FLIR热成像数据集。
由Alexander Toet于2014年发布的TNO图像融合数据集[21]是目前最常用的可见光与红外图像公开数据集。该数据集包含多种军事场景的多光谱图像(增强视觉、近红外及长波红外/热成像),均采用不同多波段摄像系统在夜间拍摄完成。图2(a)(b)展示了TNO数据集中常用的两对图像。
TNO在图像融合研究中发挥着重要作用。然而该数据集不适用于基于深度学习的图像融合算法,原因如下:1) TNO仅包含261组图像,其中含大量连续相似图像序列;2) TNO数据集中行人等目标对象稀少,难以用于融合后的目标检测任务。
INO Videos Analytics Dataset由加拿大国家光学研究所提供,包含多组可见光与红外视频对,呈现了不同天气条件下捕捉的各种场景。多年来,INO在非受控环境中运用多种传感器类型进行视频分析应用方面积累了深厚技术专长。该数据集涵盖极为丰富的场景与环境,但行人及低光照图像数量较少。
由Riad I. Hammoud博士于2004年发起的OTCBVS基准数据集合集[3]包含极其丰富的红外数据集,OSU彩色-热成像数据库[2]则是专为彩色与热成像融合及基于融合的目标检测而设计的可见光-红外配对数据集。该数据集拍摄于俄亥俄州立大学校园内一条繁忙的交叉路口,两组相机以三脚架固定并相互校准,安装位置距地面约三层楼高。图像中包含大量行人目标,但所有采集均发生在白天时段,可见光图像中的行人已极为清晰。在此类场景下,红外图像的优势并不显著。部分图像对如图2©(d)所示。

图2. TNO数据集中的若干图像对(a)(b)及OTCBVS OSU彩色-热成像数据库中的图像对©(d)。每对图像中,左侧为可见光图像,右侧为红外图像。
CVC-14[4]是一个面向自动行人检测任务设计的可见光与红外图像数据集。该数据集包含四个序列:白天/远红外、夜间/远红外、白天/可见光及夜间/可见光。由于专门用于自动驾驶研究,其图像不适用于视频监控场景(如图3所示)。此外,CVC-14的图像亮度不足,人眼仍可轻松识别目标物。需注意该数据集不可用于图像融合任务,因其可见光与红外图像存在时间未严格对齐的问题(见图3(b)黄色框标注部分)。

图3. CVC-14数据集中部分图像对。图像对名称即其在CVC-14数据集中的命名。所有图像均为驾驶视角采集,可见光图像与红外图像在时间上并非严格对应(b)。
KAIST多光谱数据集[7]提供了通过基于分束器的特殊硬件采集、良好对齐的彩色-热成像图像对。借助该硬件,研究团队在不同光照条件下采集了各类常规交通场景的昼夜数据。该数据集同样是一个面向自动驾驶的数据集。
FLIR入门级热成像数据集使开发者能够开始训练卷积神经网络(CNN),助力汽车行业利用FLIR高性价比的热成像摄像头打造更安全、更高效的下一代ADAS与无人驾驶汽车系统。但该数据集中的可见光与红外图像未配准,因此无法用于图像融合。
3.LLVIP数据集
我们提出LLVIP,一个用于低光视觉的可见光-红外配对数据集。本节将介绍数据集的收集、筛选、配准与标注方法,并分析该数据集的优缺点及应用场景。
图像采集
我们所使用的摄像设备是海康威视DS-2TD8166BJZFY-75H2F/V2双目摄像机平台,包含一个可见光摄像头和一个红外摄像头。我们在晚间6点至10点期间从街道不同位置拍摄包含多名行人和骑行者的图像。
经过时间对齐与人工筛选,我们选取了时间同步且包含行人的高质量图像对。截至目前,已从26个不同地点采集到16836对可见光-红外图像,每对图像均包含行人。
配准
尽管可见光图像与红外图像由双目相机拍摄,但由于不同传感器相机的视场范围存在差异,两者并未实现对准。我们对可见光-红外图像对进行了裁剪与配准处理,使其具备完全一致的视野范围和图像尺寸。针对这一多模态图像配准任务,单纯应用自动检测配准方法较为困难,因此我们选择了半人工方式:先手动选取两幅图像中需对齐的若干特征点对,通过计算投影变换对红外图像进行形变处理,最终裁剪得到配准后的图像对。图4(b)©展示了配准前后可见光与红外图像的对比效果。我们同时提供未经配准的图像对以供研究者开展可见光与红外图像配准相关研究。

图4. 图像采集与图像配准。双光谱相机采集不同视场的图像(a)(b),经配准后图像对完成对齐©。
标注
低光环境下行人检测的难点之一在于图像标注,因为人眼几乎无法清晰辨别人体并在图像中准确标出边界框。我们提出一种利用红外图像标注低光可见光图像的方法:首先在行人特征明显的红外图像上进行标注,由于可见光与红外图像已对齐,标注可直接复制到可见光图像上。我们采用此方法完成了数据集中所有图像对的标注工作。
优势
表1展示了LLVIP与第2节提到的现有数据集的对比。我们的LLVIP数据集具有以下优势:
• 可见光-红外图像在时间和空间上同步,因此该图像对可用于图像融合和有监督的图像到图像转换。
• 该数据集处于低光照条件下,红外图像为低光照可见光图像提供了丰富的补充信息,因此该数据集适用于图像融合研究,并可用于低光照行人检测。
• 数据集中包含大量带标注的行人目标,可见光与红外图像融合在行人检测中具有更显著的效果和意义。
• 图像质量极高,原始可见光图像分辨率为1920×1080,红外图像分辨率为1280×720。与其他数据集相比,本数据集是一个高质量的可见光-红外配对数据集。
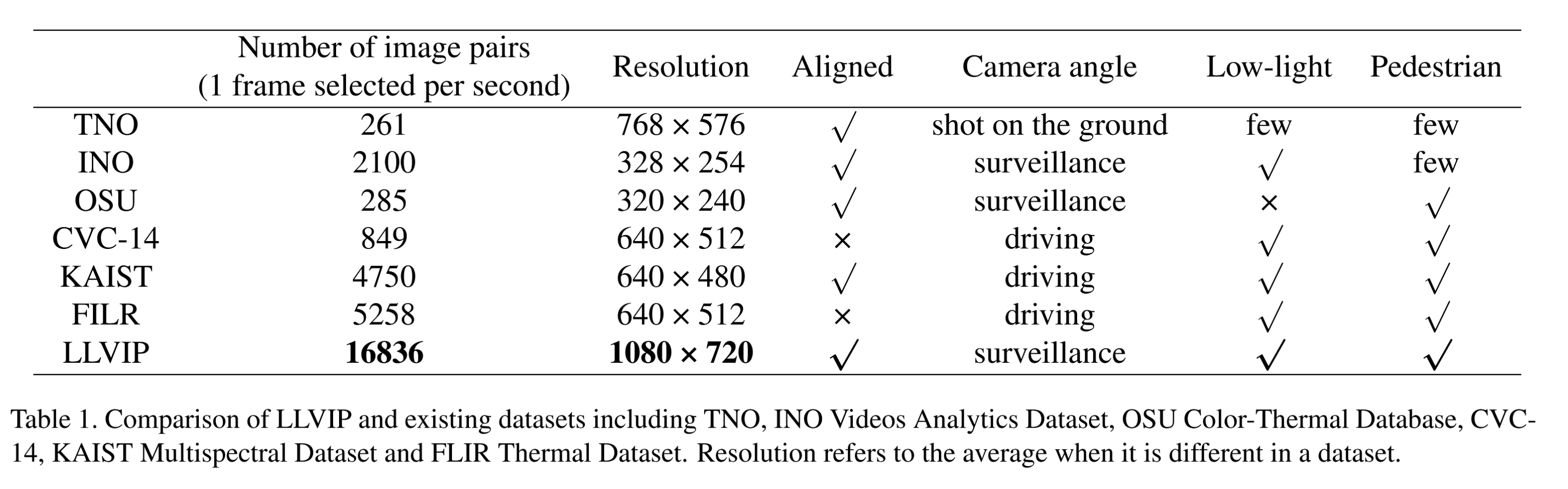
表1. LLVIP与现有数据集对比,包括TNO、INO视频分析数据集、OSU彩色-热成像数据库、CVC14、KAIST多光谱数据集及FLIR热成像数据集。分辨率数据为各数据集不同时的平均值。
不足
数据集中大部分图像是在中等距离下采集的,图像中的行人尺寸也属于中等大小。因此,该数据集不适用于远距离小目标行人检测的研究。
应用
LLVIP数据集可用于研究以下视觉任务:1) 可见光与红外图像融合;2) 弱光行人检测;3) 可见光到红外的图像转换;4) 其他任务,如多模态图像配准。
4.任务
在本节中,我们将详细阐述该数据集可应用的视觉任务,如第3节所述。如图5所示,这些任务包括图像融合、低光行人检测和图像到图像转换。
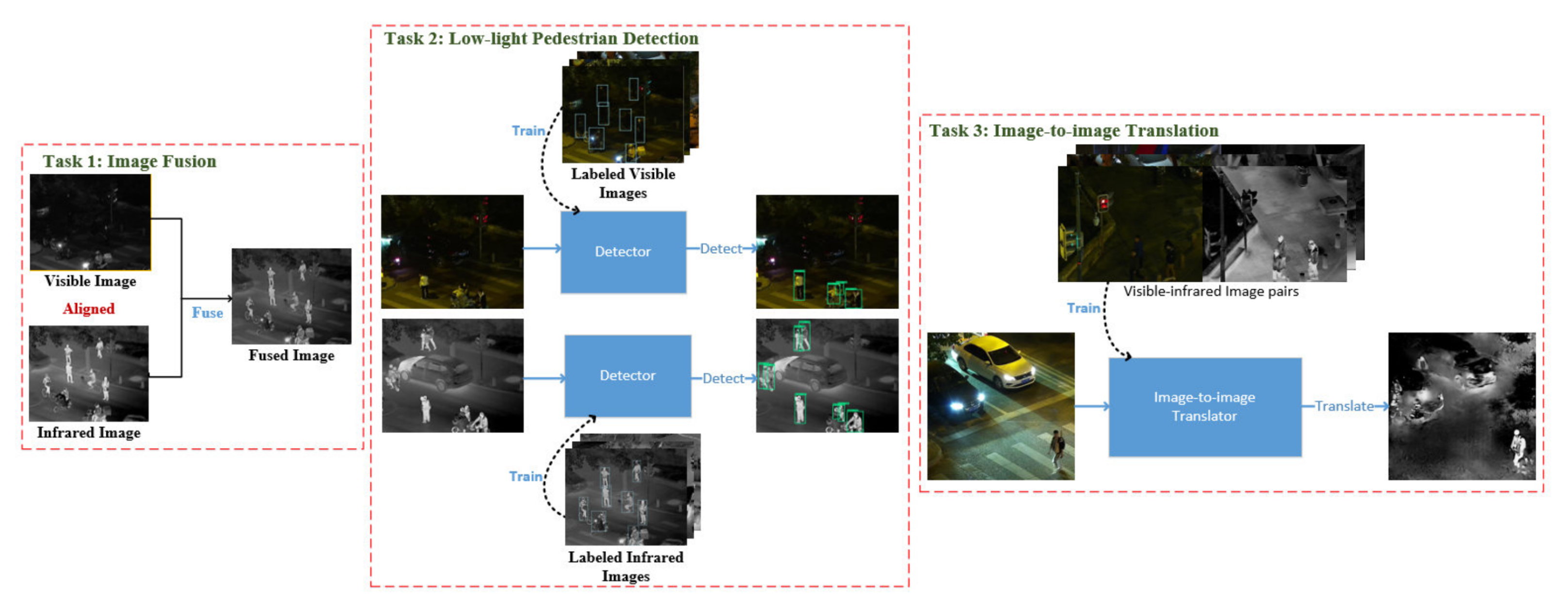
图5. 我们的LLVIP数据集可应用的三种低光视觉任务。任务1:图像融合。任务2:低光行人检测。任务3:图像到图像转换。
4.1 图像融合与度量指标
图像融合旨在从源图像中提取显著特征,并通过适当的融合方法将这些特征整合至单一图像中。可见光与红外图像的融合既能保留可见光图像的丰富细节,又能突出红外图像中热源目标的显著性。
4.1.1 融合方法
近年来,众多融合方法被提出。与传统人工方法相比,我们聚焦于深度学习方法,包括卷积神经网络和生成对抗网络。深度学习方法已在现有方法中取得了最佳性能。
李辉和吴晓军提出了DenseFuse[10],该方法在编码器中引入了密集块结构,即每个卷积层的输出彼此相连。通过这种方式,网络能在编码过程中从源图像获取更多特征。此外,DenseFuse还设计了两种不同的融合策略:加法融合与L1范数融合。
马嘉义等人提出了FusionGAN[12],该方法利用生成对抗网络实现可见光与红外图像的融合。生成器使融合图像兼具红外图像的像素强度和可见光图像的梯度信息。判别器通过特征提取区分融合图像与可见光图像,从而使融合图像能保留更多可见光图像的纹理信息。
4.1.2 融合指标
已有多种融合指标被提出,但难以断言孰优孰劣,因此需选取多项指标评估融合方法。我们采用信息熵(EN)、互信息(MI)[16, 17]系列、结构相似性(SSIM)[22]、Qabf [14]以及融合视觉信息保真度(VIFF)[6]客观评估不同融合方法的性能。具体定义与计算公式详见补充材料。
基于信息论定义的信息熵(EN)用于衡量融合图像所包含的信息量。互信息(MI)[16]是最常用的图像融合客观评价指标。融合因子(FF)[17]是基于互信息衍生的概念。标准化互信息( Q M I Q_{MI} QMI)通过信息熵与互信息进行定义。结构相似性(SSIM)[22]是一种感知指标,用于量化数据压缩或传输损耗导致的图像质量衰减。 Q a b f Q_{abf} Qabf指数[14]通过评估输入图像的显著信息在无失真情况下融入结果图像的程度来反映融合质量。视觉信息保真度(VIFF)[6]借鉴VIF模型从两幅源图像中提取视觉信息。
4.2. 低光照行人检测
过去几年间,行人检测技术在自动驾驶、视频监控和人数统计等领域的广泛应用推动了其显著发展。然而在弱光条件下,现有行人检测方法的性能仍存在局限,且针对弱光环境的算法与数据集较为匮乏。缺乏可见光弱光行人数据集的原因之一在于其标注难度较高。本研究通过标注已配准的红外图像来完成弱光可见光图像的标注工作,从而解决了这一难题。
Yolo系列算法[18, 19, 20, 1, 9]是目标检测领域最常用的单阶段检测模型。随着计算机视觉技术的发展,该系列持续融合新技术并迭代更新。在5.2节中,我们选用Yolov3[20]和Yolov5[9]在LLVIP数据集上进行行人检测实验,结果表明现有行人检测算法在低光照条件下性能欠佳。
图像到图像转换是一种将图像从一个域转换到另一个域的技术。随着条件生成对抗网络(cGANs)[13]的发展,该技术已取得重大进展,并应用于多种场景,如语义标签图与照片的转换[8]、黑白图与彩色图、素描与照片、白天照片与夜间照片等。与可见光图像相比,由于设备昂贵和拍摄条件严苛,红外图像难以获取。为克服这些限制,研究者利用图像到图像转换方法,通过易获取的可见光图像构建红外数据。
现有的可见光到红外线转换方法主要可分为两类:一类是基于物理模型和人工设计图像转换关系的方法,另一类是深度学习方法。由于热成像情况复杂,难以人工归纳光学图像与红外图像间的全部映射关系,因此物理模型方法的结果往往存在精度不足和细节缺失的问题。近年来深度学习研究发展迅速,在图像到图像转换领域主要聚焦于生成对抗网络(GANs)[5]。Pix2pix GAN作为图像转换问题的通用解决方案,使得传统上需要不同损失函数设计的任务能够采用统一的处理方法[8]。
5.实验
在本节中,我们将详细描述在LLVIP数据集上进行的图像融合、行人检测和图像转换实验,并对结果进行评估。实验基于16GB显存的NVIDIA Tesla T4 GPU完成。
5.1. 图像融合
我们所选用的融合算法包括梯度转移融合(GTF)[11]、FusionGAN[12]、Densefuse(加法融合策略与l1融合策略)[10]以及IFCNN[23]。这些算法均采用原始模型及参数配置,随后通过主客观评估对其融合结果进行分析。最终,基于融合实验结果阐明本数据集对图像融合算法研究的价值。所有超参数及实验设置均依照原作者论文设定。GTF实验在英特尔酷睿i7-4720HQ处理器上完成。
主观评价。图6展示了一些融合图像示例。从左侧第一列可以看出,在光照条件较差时,可见光图像几乎无法区分人体与背景。红外图像中虽能清晰分辨人体等目标轮廓,但缺乏内部纹理信息。融合算法不同程度地结合了两类图像的信息,使得人体目标得到凸显的同时保留了部分纹理特征。
图6. LLVIP数据集上多种融合算法的效果示例。从左至右依次为:(a)可见光图像,(b)红外图像,©GTF融合结果,(d)densefuse加法融合结果,(e)densefuse l1范数融合结果,(f)FusionGAN融合结果,(g)IFCNN融合结果。
从人眼主观感知判断,我们认为DenseFuse L1和IFCNN最适合用于夜间图像融合。因为这两种方法获得的融合图像保留了更多可见光与红外图像的信息,即不仅细节更丰富,还能突出人体目标。
为了更清晰地观察融合图像中保留的可见光图像细节,我们对低照度可见光图像进行了增强处理。图7对比了融合图像与增强后可见光图像的细节表现。原始可见光图像中明亮的细节(如车牌号码和交通信号灯)在融合图像中得到了良好保留,但我们也注意到融合图像中存在部分细节缺失。
一方面,原始可见光图像中的暗部细节在融合图像中严重丢失,如图7中"缺失细节"的区域1和区域2所示。增强图像表明这些低光区域包含大量细节,但融合图像未能保留这些信息,树叶和石块的纹理特征均在融合过程中丢失。
另一方面,人物身上的许多细节丢失了,例如图7中“不良细节”的区域3。融合图像中未显示人物衣物的纹理信息,这不仅是因为可见光图像光照条件较差,还因为该区域红外图像像素强度较高,导致其在融合图像中占主导地位。

图7. 增强可见光图像与融合图像的细节对比。原始可见光图像中明亮的细节在融合图像中得到良好保留(我们对车牌号进行了涂抹处理),但许多其他细节已丢失。
一般而言,当源图像中某幅图像的像素强度极低,或某幅图像的像素强度极高时,融合效果会较差。换言之,融合算法平衡两幅源图像的能力不足。这表明现有融合算法仍有较大改进空间。
客观评价。我们在表2中提供了不同融合算法在LLVIP数据集上六项指标的平均值。总体而言,DenseFuse L1和IFCNN在该数据集上表现最佳,但仍存在较大改进空间。
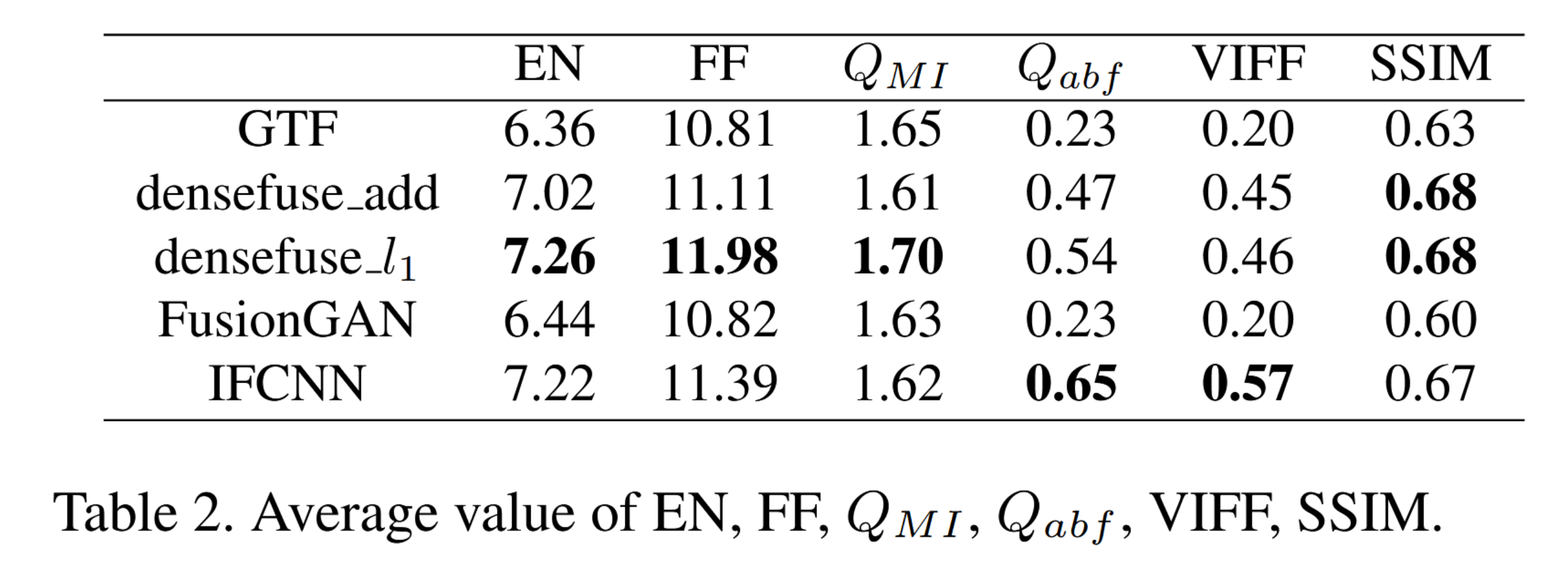
表2. EN、FF、QMI、Qabf、VIFF、SSIM的平均值。
5.2. 行人检测
为进行对比,我们分别使用可见光图像和红外图像进行行人检测实验。
Yolov5 [9]在数据集上进行了测试。该模型首先在COCO数据集上进行预训练,随后在我们的数据集上进行了微调。选用预训练权重yolov5l,数据集的70%用于训练,30%用于测试。模型训练200个epoch,批量大小为8,学习率从0.0032降至0.000384。我们采用带动量0.843、权重衰减0.00036的随机梯度下降法(SGD)。Yolov3 [20]同样在数据集上进行了测试,实验设置与默认配置保持一致。
经过训练和测试,可见光图像与红外图像的实验结果如表3所示。实验结果的示例如图8所示。可见光图像中存在大量漏检现象,而红外图像突出了行人目标,在检测任务中取得了更优的效果,这不仅证明不仅体现了红外图像的必要性,也表明行人检测算法在低光照条件下的性能尚不够理想。可见光与红外图像的检测结果至少存在一定差异。该数据集可用于研究和改进夜间行人检测算法的性能。
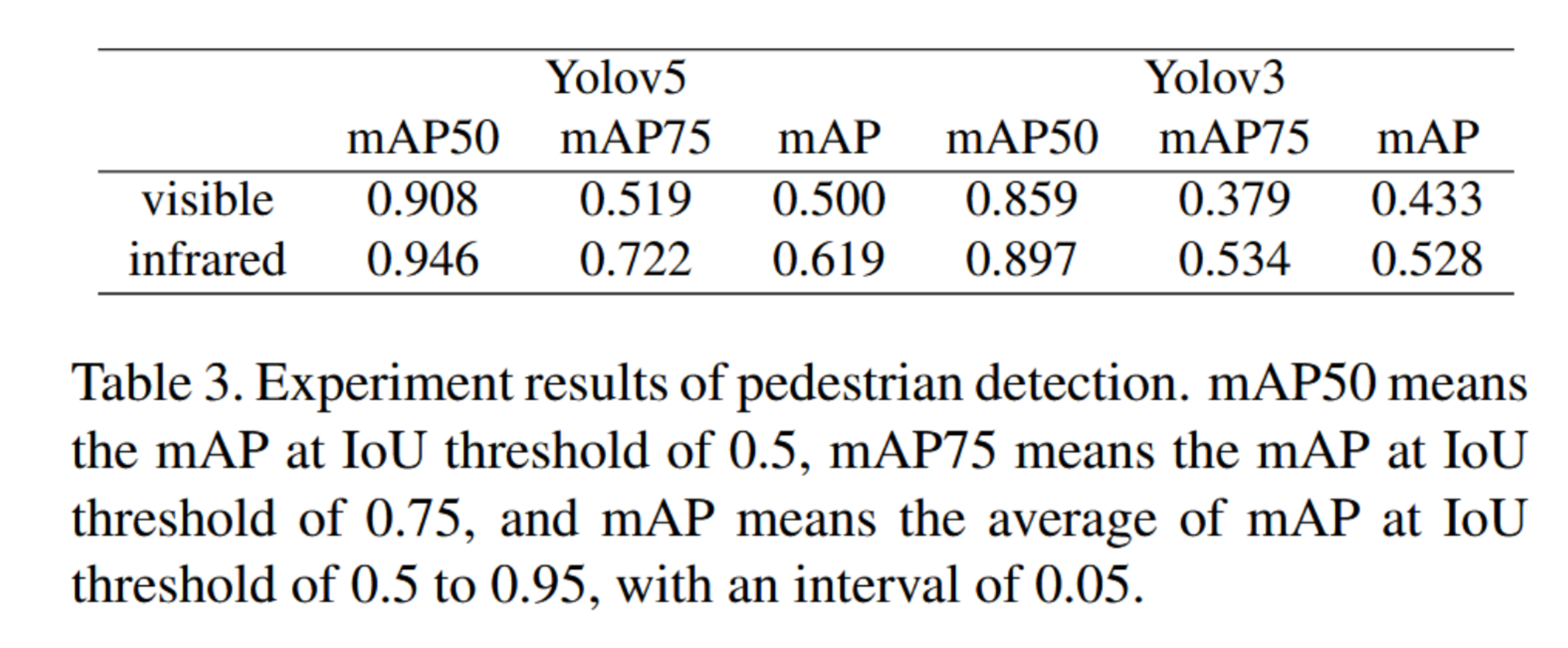
表3. 行人检测实验结果。mAP50表示IoU阈值为0.5时的mAP,mAP75表示IoU阈值为0.75时的mAP,mAP表示IoU阈值从0.5到0.95(间隔0.05)的平均mAP。

图8. 检测实验结果示例。
5.3. 图像到图像转换
在图像到图像的翻译任务中,我们采用pix2pixGAN[8]进行实验。生成器采用unet256结构,判别器默认使用基础PatchGAN架构。数据预处理阶段先将图像缩放至320×256,再裁剪为256×256尺寸。批处理大小设为8,使用前述相同GPU设备。模型训练共进行100轮次,初始学习率为0.0002,后续100轮次将学习率线性衰减至零。
流行的pix2pixGAN在我们的LLVIP数据集上表现极差。图9中我们展示了两个图像转换效果的定性示例,可见生成图像的质量及其与真实图像的相似度均不理想。生成图像中的背景杂乱,行人和车辆的轮廓不清晰且细节错误,图像上还有许多伪影。

图9. pix2pixGAN在LLVIP数据集上的图像到图像转换结果示例。从左至右:(a)原始可见光图像,(b)生成的红外图像,©真实的红外图像。
从量化指标来看,如表4所示,该方法的SSIM和PSNR值极低。我们将钱等人在KAIST多光谱行人数据集上提出的pix2pixGAN实验结果[15]进行对比,明显可见该图像转换算法在LLVIP数据集上的性能远逊于KAIST数据集。造成这种差距的原因可能在于:1) pix2pixGAN的泛化能力较弱。KAIST数据集的场景变化较小,而LLVIP训练集与测试集的场景存在差异;2) pix2pixGAN在低光照条件下性能显著下降。KAIST数据集的暗夜图像光照条件仍较好,与LLVIP数据集图像存在差异。因此,低光照条件下的图像转换算法仍有较大改进空间,亟需构建适用于弱光视觉的可见光-红外配对数据集。
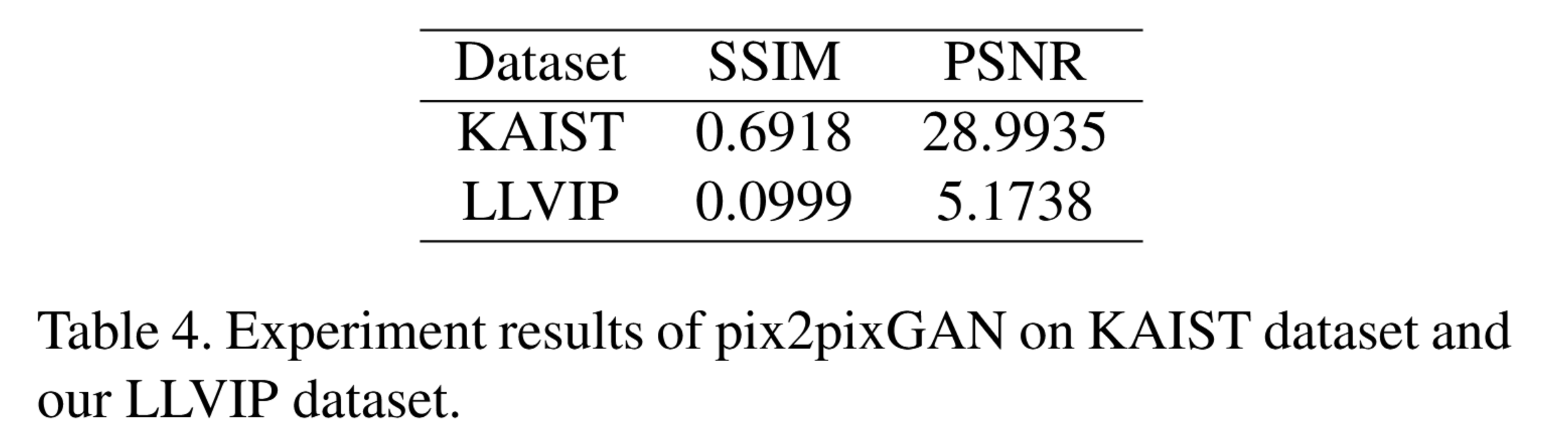
表4. pix2pixGAN在KAIST数据集和我们LLVIP数据集上的实验结果。
6. 结论
本文提出LLVIP低光视觉可见光-红外配对数据集。该数据集严格对齐时空信息,包含大量行人及低光照条件下的图像,并提供行人检测标注。在数据集上的实验表明,可见光与红外图像融合、低光行人检测以及图像间转换等任务的性能均有待提升。
我们提供LLVIP数据集,其用途包括但不限于以下研究:
- 可见光与红外图像融合。数据集中的图像已对齐。
- 低光行人检测。低光可见光图像已精确标注。
- 图像到图像转换。
- 其他领域,如多模态图像配准和域适应。
7.引用文献
- [1] Alexey Bochkovskiy, Chien-Yao Wang, and HongYuan Mark Liao. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934, 2020.
- [2] James W Davis and Vinay Sharma. Background-subtraction using contour-based fusion of thermal and visible imagery. Computer vision and image understanding, 106(2-3):162182, 2007.
- [3] James W Davis and V Sharma. Otcbvs benchmark dataset collection. http://vcipl-okstate.org/ pbvs/bench/, 2007.
- [4] Alejandro Gonza ́lez, Zhijie Fang, Yainuvis Socarras, Joan Serrat, David V ́azquez, Jiaolong Xu, and Antonio M Lo ́pez. Pedestrian detection at day/night time with visible and fir cameras: A comparison. Sensors, 16(6):820, 2016.
- [5] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. Advances in neural information processing systems, 27:2672–2680, 2014.
- [6] Yu Han, Yunze Cai, Yin Cao, and Xiaoming Xu. A new image fusion performance metric based on visual information fidelity. Information fusion, 14(2):127–135, 2013.
- [7] Soonmin Hwang, Jaesik Park, Namil Kim, Yukyung Choi, and In So Kweon. Multispectral pedestrian detection: Benchmark dataset and baselines. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
- [8] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1125–1134, 2017.
- [9] Glenn Jocher, Alex Stoken, Jirka Borovec, NanoCode012, ChristopherSTAN, Liu Changyu, Laughing, Adam Hogan, lorenzomammana, tkianai, yxNONG, AlexWang1900, Laurentiu Diaconu, Marc, wanghaoyang0106, ml5ah, Doug, Hatovix, Jake Poznanski, Lijun Yu, changyu98, Prashant Rai, Russ Ferriday, Trevor Sullivan, Wang Xinyu, YuriRibeiro, Eduard Ren ̃ ́e Claramunt, hopesala, pritul dave, and yzchen. ultralytics/yolov5: v3.0, Aug. 2020.
- [10] Hui Li and Xiao-Jun Wu. Densefuse: A fusion approach to infrared and visible images. IEEE Transactions on Image Processing, 28(5):2614–2623, 2018.
- [11] Jiayi Ma, Chen Chen, Chang Li, and Jun Huang. Infrared and visible image fusion via gradient transfer and total variation minimization. Information Fusion, 31:100–109, 2016.
- [12] Jiayi Ma, Wei Yu, Pengwei Liang, Chang Li, and Junjun Jiang. Fusiongan: A generative adversarial network for infrared and visible image fusion. Information Fusion, 48:1126, 2019.
- [13] Mehdi Mirza and Simon Osindero. Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784, 2014.
- [14] Gemma Piella and Henk Heijmans. A new quality metric for image fusion. In Proceedings 2003 International Conference on Image Processing (Cat. No. 03CH37429), volume 3, pages III–173. IEEE, 2003.
- [15] Xiaoyan Qian, Miao Zhang, and Feng Zhang. Sparse gans for thermal infrared image generation from optical image. IEEE Access, 8:180124–180132, 2020.
- [16] Guihong Qu, Dali Zhang, and Pingfan Yan. Information measure for performance of image fusion. Electronics letters, 38(7):313–315, 2002.
- [17] Chaveli Ramesh and T Ranjith. Fusion performance measures and a lifting wavelet transform based algorithm for image fusion. In Proceedings of the Fifth International Conference on Information Fusion. FUSION 2002.(IEEE Cat. No. 02EX5997), volume 1, pages 317–320. IEEE, 2002.
- [18] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 779–788, 2016.
- [19] Joseph Redmon and Ali Farhadi. Yolo9000: better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7263–7271, 2017.
- [20] Joseph Redmon and Ali Farhadi. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018.
- [21] Alexander Toet et al. Tno image fusion dataset. https:// doi.org/10.6084/m9.figshare.1008029.v1, 2014.
- [22] Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13(4):600–612, 2004.
- [23] Yu Zhang, Yu Liu, Peng Sun, Han Yan, Xiaolin Zhao, and Li Zhang. Ifcnn: A general image fusion framework based on convolutional neural network. Information Fusion, 54:99118, 2020.

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 21
21 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)