
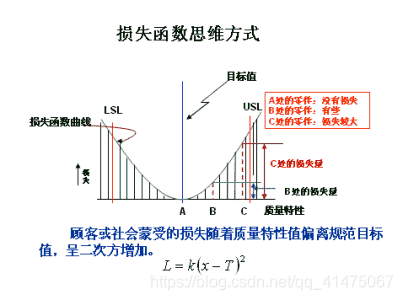
深度学习中常见的损失函数
马上周末了,刚背完损失函数章节课程,抽个时间梳理下深度学习中常见的损失函数和对应的应用场景何为损失函数?我们在聊损失函数之前先谈一下,何为损失函数?在深度学习中, 损失函数是用来衡量模型参数的质量的函数, 衡量的方式是比较网络输出和真实输出的差异应用场景总述?首先明确一点,我们损失函数这个概念会出现在几乎所有机器学习和深度学习的模型中,但是考虑到很多文献资料和各个翻译者的理解不同,大概有如下几种称
马上周末了,刚背完损失函数章节课程,抽个时间梳理下深度学习中常见的损失函数和对应的应用场景
何为损失函数?
我们在聊损失函数之前先谈一下,何为损失函数?在深度学习中, 损失函数是用来衡量模型参数的质量的函数, 衡量的方式是比较网络输出和真实输出的差异
应用场景总述?
首先明确一点,我们损失函数这个概念会出现在几乎所有机器学习和深度学习的模型中,但是考虑到很多文献资料和各个翻译者的理解不同,大概有如下几种称呼:损失函数、代价函数、误差函数等;
通常无论是在分类任务中还是在回归任务中,我们都会选择在对应用于场景中更合适的损失函数。
应用场景详述?
-
分类任务
-
二分类任务
在处理二分类任务时,使用sigmoid激活函数, 损失函数使用二分类的交叉熵损失函数(BinaryCrossentropy) -
多分类任务
而在多分类任务通常使用softmax将logits转换为概率的形式,所以多分类的交叉熵损失也叫做softmax损失,对应损失函数(CategoricalCrossentropy) -
回归任务
回归任务中常用的损失函数有以下几种: -
Mean absolute loss(MAE)也被称为L1 Loss,是以绝对误差作为距离
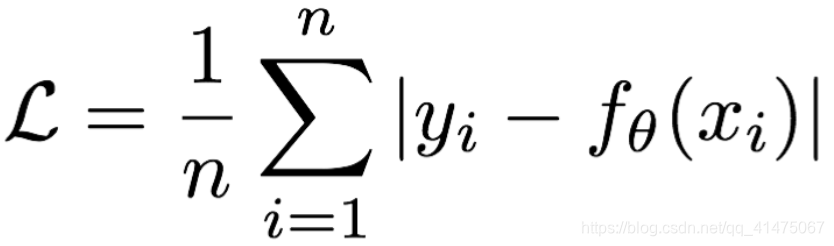
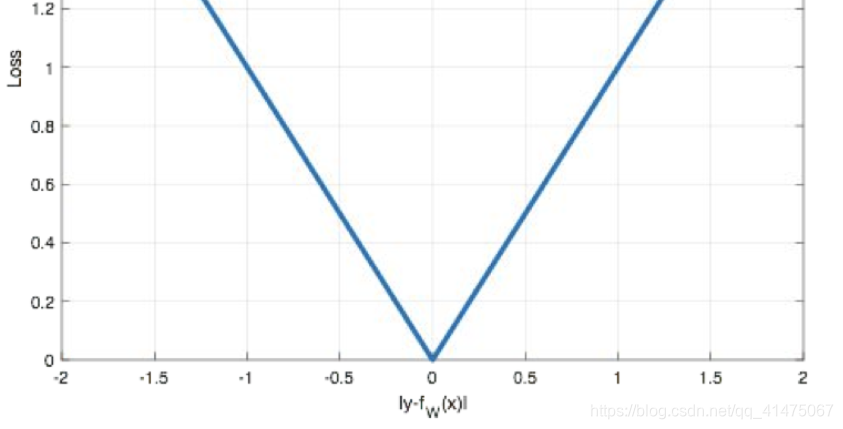
L1损失的特点是:由于L1 loss具有稀疏性,为了惩罚较大的值,因此常常将其作为正则项(正则化惩罚系数)添加到其他loss中作为约束。
L1 loss的最大问题是梯度在零点不平滑,导致会跳过极小值。(个人认为影响不大,只有在理论上才会存在全局最优解)
- Mean Squared Loss/ Quadratic Loss(MSE loss)也被称为L2 loss,或欧氏距离,它以误差的平方和作为距离
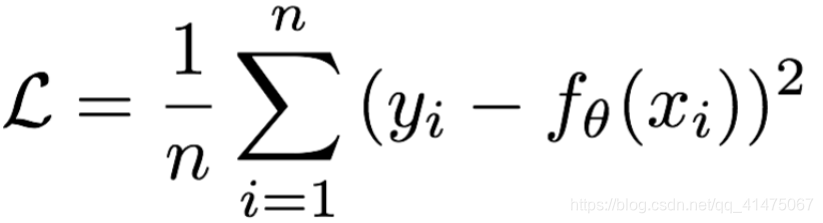
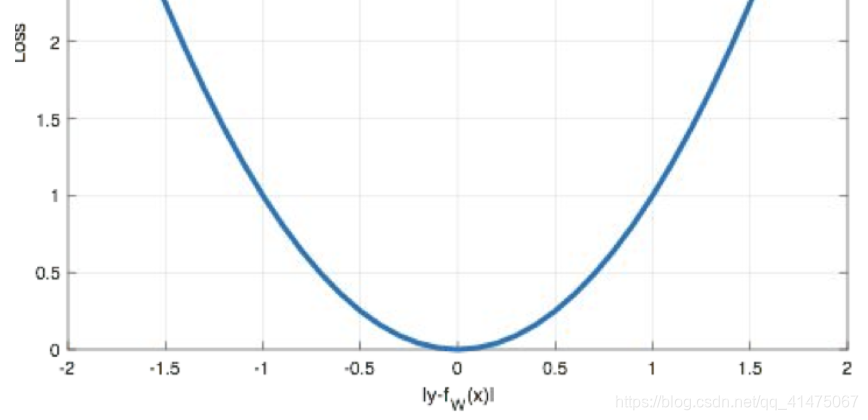
MeanSquaredError特点是:L2 loss也常常作为正则项。当预测值与目标值相差很大时, 梯度容易爆炸。
- smooth L1 损失(Huber,个人观点:解决回归问题在理论层面上的最优损失函数)
公式: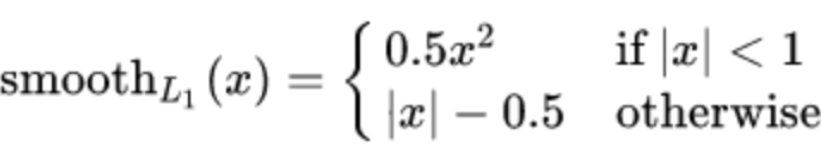
也就是说,smooth L1 损失在L1 loss和L2 loss的基础上融合了双方的优势,有效的规避了各方劣势,正可谓优势互补。
基本原理:
- 在[-1, +1]范围内,smooth L1 损失使用了L2 loss,此处规避了L2损失
当预测值与目标值相差很大时, 容易出现梯度爆炸的问题;(此处也可以理解为离群点现象) - 在[-1, 1]范围之外,smooth L1 损失使用了L1 loss,此处规避了L1 loss 梯度在零点不平滑,导致会跳过极小值的问题。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)