
在虚拟机或Docker中搭建大数据伪分布式集群(四):添加 Spark
在虚拟机或Docker中搭建大数据伪分布式集群(四):添加 Spark系列文章:在虚拟机或Docker中搭建大数据伪分布式集群系列(一):hadoop基础功能——hdfs 与 yarn在虚拟机或Docker中搭建大数据伪分布式集群(二):集群添加zookeeper与HBase在虚拟机或Docker中搭建大数据伪分布式集群(三):添加Hive接下来搭建Spark...
在虚拟机或Docker中搭建大数据伪分布式集群(四):添加 Spark
系列文章:
在虚拟机或Docker中搭建大数据伪分布式集群系列(一):hadoop基础功能——hdfs 与 yarn
在虚拟机或Docker中搭建大数据伪分布式集群(二):集群添加zookeeper与HBase
在虚拟机或Docker中搭建大数据伪分布式集群(三):添加Hive
目录
在虚拟机或Docker中搭建大数据伪分布式集群(四):添加 Spark
接下来搭建Spark
一、Spark安装配置启动
1、安装
下载 spark-3.0.1-bin-hadoop3.2.tgz
我这里直接从本机复制到Docker容器中,使用VM虚拟机的话请使用 rz 上传。
# 格式为:docker cp 本地文件的路径 container_id:<docker容器内的路径>
docker cp /Volumes/Linux/spark-3.0.1-bin-hadoop3.2.tgz hadoop-master:/opt/解压
tar -xzvf spark-3.0.1-bin-hadoop3.2
mv spark-3.0.1-bin-hadoop3.2 spark配置环境变量
vi /etc/profile
# 在文件尾部添加配置
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$PATH:$SPARK_HOME/sbin
#退出保存,再使配置生效
source /etc/profile2、配置
进入安装目录的 conf/ 目录下,拷贝配置样本并进行修改:
cd $SPARK_HOME/confspark-env.sh
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
# 在 spark-env.sh 中添加如下环境变量
export JAVA_HOME=/opt/jdk8
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export YARN_CONF_DIR=/opt/hadoop/etc/hadoop
export SPARK_MASTER_HOST=hadoop-master
# 保存退出slaves
cp slaves.template slaves
vi slaves
# 在 slaves 中指定Worker的所在节点
hadoop-master2
hadoop-slave1
hadoop-slave2
hadoop-slave3
# 保存退出
复制分发
cd /opt/
for i in hadoop-master2 hadoop-slave1 hadoop-slave2 hadoop-slave3; do scp -R spark $i:$PWD ; done或者,写一个复制分发脚本 sync.sh,并将脚本所在路径添加到环境变量里(记得 source 一下,使得配置生效)
#!/bin/bash
host_arr=(hadoop-master hadoop-master2 hadoop-slave1 hadoop-slave2 hadoop-slave3)
for host in ${host_arr[*]}
do
if [ $host != $HOSTNAME ]
then
ssh $host "mkdir -p ${PWD}";
if [ -d $1 ]
then
scp -R $1 $host:$PWD;
else
scp $1 $host:$PWD;
fi
fi
donecd /opt/
sync.sh spark3、启动
在Spark的安装目录执行启动脚本
$SPARK_HOME/sbin/start-all.sh执行 jps 命令查看Java进程,在 hadoop-master 上可用看见Master进程,在其他的节点上可用看见到Worker
访问Master的web管理界面,端口8080
http://hadoop-master:8080
二、spark 布置模式
在初始化SparkConf时,或者提交Spark任务时,都需要设置master参数——Spark的部署方式
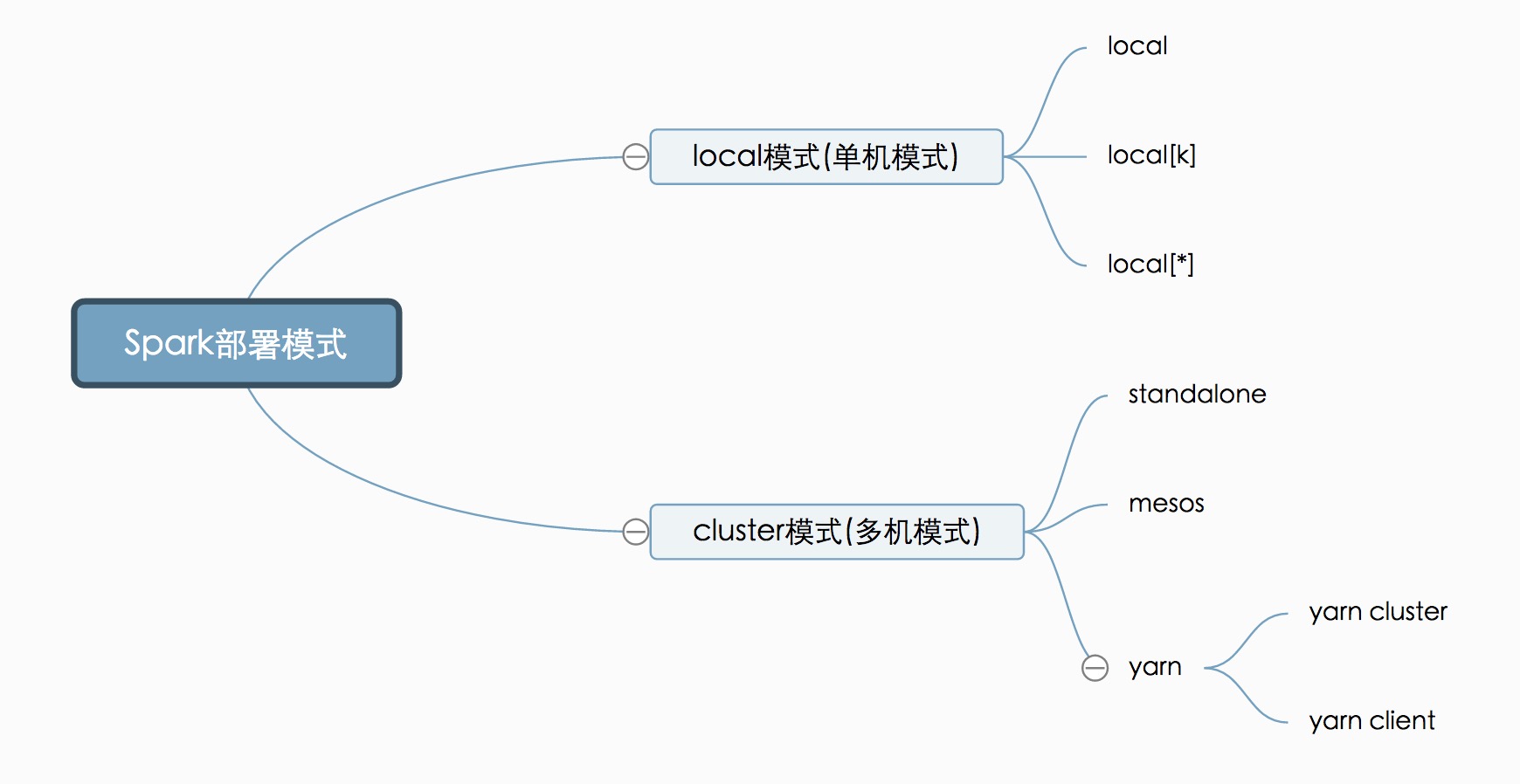
0、Local
本地的单机版模式,用于在本机上练手和测试。
设置如下:
- local: 所有计算都运行在一个线程当中,没有任何并行计算。
- local[K]: 指定使用几个线程来运行计算,比如 local[4] 就是运行4个worker线程。通常计算机cpu有几个core,就指定几个线程,最大化利用cpu的计算能力。
- local[*] : 按照cpu最多cores来设置线程数了。
下面的都是实际应用的集群模式,区别在于谁去管理资源调度:
StandAlone —— Spark自己负责资源的管理调度 --master spark://host:port
mesos —— 使用mesos来管理资源调度 --master mesos://host:port
yarn—— 使用 yarn 来管理资源调度 --master yarn / yarn-cluster / yarn-client
- yarn-cluster: 等同于 –-master yarn —deploy-mode client, 此时不需要指定deploy-mode。生产环境常用的模式,所有的资源调度和计算都在集群环境上运行
- yarn-client: 等同于 –-master yarn —deploy-mode cluster, 此时不需要指定deploy-mode。Spark Driver和ApplicationMaster进程均在本机运行,而计算任务在cluster上
yarn-cluster 和 yarn-client 区别就是 yarn-cluster 的 driver 是在集群节点中随机选取启动,yarn-client 的 driver 是在任务提交的客户端中启动。
注意:提交spark任务一般都使用cluster模式,但是spark-shell、spark-sql必须采用client
1、Spark StandAlone
上面的安装就是 Spark StandAlone的安装配置搭建
client 提交
Spark StandAlone 提交到集群中,默认的模式为 client 模式,默认参数是 --deploy-mode client,特点:Driver 在 SparkSubmit 进程中
例如:
/opt/spark/bin/spark-submit \
--master spark://hadoop-master:7077 \
--deploy-mode client \
--class bigdata.hermesfuxi.spark.day01.WordCount \
/root/spark10-1.0-SNAPSHOT.jar \
hdfs://hadoop-master:9000/input \
hdfs://hadoop-master:9000/outputcluster 提交
参数是 --deploy-mode cluster,特点:Driver运行在集群中,不在SparkSubmit进程中,需要将jar包上传到hdfs中
/opt/spark/bin/spark-submit \
--master spark://hadoop-master:7077 \
--deploy-mode cluster \
--class bigdata.hermesfuxi.spark.day01.WordCount \
hdfs://hadoop-master:9000/jars/spark/submit/spark10-1.0-SNAPSHOT.jar \
hdfs://hadoop-master:9000/input \
hdfs://hadoop-master:9000/output02REST 提交
curl -X POST http://hadoop-master:6066/v1/submissions/create --header "Content-Type:application/json;charset=UTF-8" \
--data '{
"action": "CreateSubmissionRequest",
"clientSparkVersion": "2.3.3",
"appArgs": ["hdfs://hadoop-master:9000/wc", "hdfs://hadoop-master:9000/out003"],
"appResource": "hdfs://hadoop-master:9000/jars/spark/submit/spark10-1.0-SNAPSHOT.jar",
"environmentVariables": {
"SPARK_ENV_LOADED": "1"
},
"mainClass": "bigdata.hermesfuxi.spark.day01.WordCount",
"sparkProperties": {
"spark.jars": "hdfs://hadoop-master:9000/jars/spark/submit/spark10-1.0-SNAPSHOT.jar",
"spark.driver.supervise": "false",
"spark.app.name": "WordCount",
"spark.eventLog.enabled": "false",
"spark.submit.deployMode": "cluster",
"spark.master": "spark://hadoop-master:6066"
}
}'2、Spark On YARN
配置搭建
配置 hadoop
cd $HADOOP_HOME/etc/hadoop修改yarn-site.xml
<!-- 关闭内存资源检测 -->
<!-- 是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
修改 capacity-scheduler.xml
<!-- 资源计算方法:DefaultResourseCalculator 只会计算内存,DominantResourceCalculator则会计算内存和CPU -->
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<!-- <value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value> -->
<value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value>
</property>重新分发到 yarn 中的各个节点
sync.sh yarn-site.xml
sync.sh capacity-scheduler.xml重启 hadoop 即可
client 提交
/opt/spark/bin/spark-submit \
--master yarn \
--deploy-mode client \
--executor-memory 1g \
--executor-cores 2 \
--num-executors 3 \
--class bigdata.hermesfuxi.spark.day01.WordCount \
hdfs://hadoop-master:9000/jars/spark/submit/spark10-1.0-SNAPSHOT.jar \
hdfs://hadoop-master:9000/input \
hdfs://hadoop-master:9000/output04 \cluster 提交
生产环境常用的模式,所有的资源调度和计算都在集群环境上运行
/opt/spark/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--executor-memory 1g \
--executor-cores 2 \
--num-executors 3 \
--class bigdata.hermesfuxi.spark.day01.WordCount \
hdfs://hadoop-master:9000/jars/spark/submit/spark10-1.0-SNAPSHOT.jar \
hdfs://hadoop-master:9000/input \
hdfs://hadoop-master:9000/output04 \资源分配
YARN可以虚拟cpu核数(VCORES),YARN为spark分配任务,spark的cores跟逻辑核数一一对应,建议配置 VCORES = 物理机的逻辑核数
YARN 中的资源分配,针对的是容器, 容器默认最少的资源是1024mb(1G), 容器接受的资源,必须是最小资源的整数倍。
spark中分配的资源由两部分组成,参数 + overhead
例如 --executor-memory 1g,overhead为 max(1024 * 0.1, 384),executor真正占用的资源应该是:1G + 384MB = 1408MB,最终都是分配给容器的是 2G(1408MB 向上取整),
例如:--executor-memory 2g,那么最终的内存为:2048 + Max(2048*0.1, 384) ,向上取整为 3G
3、Spark on Hive
Hive只作为存储角色,Spark负责sql解析优化,执行。
这里可以理解为Spark 通过Spark SQL 使用Hive 语句操作Hive表 ,底层运行的还是 Spark RDD。具体步骤如下:
- 通过SparkSQL,加载Hive的配置文件,获取到Hive的元数据信息;
- 获取到Hive的元数据信息之后可以拿到Hive表的数据;
- 通过SparkSQL来操作Hive表中的数据。
修改添加 spark-env.sh 配置
export JAVA_HOME=/opt/jdk8
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export YARN_CONF_DIR=/opt/hadoop/etc/hadoop
export HIVE_CONF_DIR=/opt/hive/conf
export SPARK_CLASSPATH=$SPARK_CLASSPATH:/opt/hive/lib/mysql-connector-java-8.0.22.jar
export SPARK_MASTER_HOST=hadoop-master
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=2g4、Hive on Spark
Hive既作为存储又负责sql的解析优化,Spark负责执行。
这里Hive的执行引擎变成了Spark,不再是MR,相较于Spark on Hive,这个实现较为麻烦,必须要重新编译spark并导入相关jar包。目前,大部分使用Spark on Hive。
修改 hive-site.xml 中的配置
<!-- Hive计算引擎:mr=>mapreduce(默认);spark=>spark -->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!-- 后面的配置为:Hive on Spark模式,不建议使用 -->
<!-- 动态分配资源 -->
<property>
<name>spark.dynamicAllocation.enabled</name>
<value>true</value>
</property>
<!-- 使用Hive on spark时,若不设置下列该配置会出现内存溢出异常 -->
<property>
<name>spark.driver.extraJavaOptions</name>
<value>-XX:PermSize=128M -XX:MaxPermSize=512M</value>
</property>
<!-- spark地址 -->
<property>
<name>spark.home</name>
<value>/opt/spark</value>
</property>
<!-- Spark运行模式: -->
<!-- 单机local模式:local、local[K]、local[*] -->
<!-- 多机cluster模式:standalone:spark://host:port,mesos:mesos://host:port,yarn模式:yarn-cluster 或 yarn-client -->
<property>
<name>spark.master</name>
<value>yarn-cluster</value>
</property>
<property>
<name>hive.spark.client.channel.log.level</name>
<value>WARN</value>
</property>
<property>
<name>spark.eventLog.enabled</name>
<value>true</value>
</property>
<property>
<name>spark.eventLog.dir</name>
<value>/opt/hive/logs/sparkeventlog</value>
</property>
<property>
<name>spark.executor.memory</name>
<value>1g</value>
</property>
<property>
<name>spark.executor.cores</name>
<value>2</value>
</property>
<property>
<name>spark.executor.instances</name>
<value>6</value>
</property>
<property>
<name>spark.yarn.executor.memoryOverhead</name>
<value>150m</value>
</property>
<property>
<name>spark.driver.memory</name>
<value>4g</value>
</property>
<property>
<name>spark.yarn.driver.memoryOverhead</name>
<value>400m</value>
</property>
<property>
<name>spark.serializer</name>
<value>org.apache.spark.serializer.KryoSerializer</value>
</property>
技术共进,成长同行——讯飞AI开发者社区
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)