
利用 DINOv2 嵌入实现准确的图像分类
在训练期间,教师网络接收图像的大裁剪图像(全局视图),而学生网络则处理同一图像的小裁剪图像(局部视图)和大裁剪图像。锐化是通过在教师网络的 softmax 中使用低温值来实现的,以将教师网络的置信度提升到主导维度,从而更好地指导学生网络。尽管数据集规模较小且具有挑战性,我们仍然通过 kNN 实现了 83.9% 的零样本准确率,并通过训练一个简单的线性头实现了 95.8% 的准确率。这种双重目标方法
介绍
训练高性能图像分类器通常需要大量带标签的数据。但是,如果您能够用最少的数据和轻松的训练获得顶级结果,那会怎样呢?
DINOv2 是一个强大的视觉基础模型,能够生成丰富的图像表征向量(也称为嵌入向量)。与CLIP等专注于语义对齐的基于文本的模型不同,DINOv2 擅长捕捉视觉结构、纹理和空间细节,使其成为医学和生物成像等专业领域中细粒度图像分类任务的理想选择。
在本教程中,我们将探索如何使用 DINOv2 构建基于 k 最近邻 (k-NN) 的零样本分类器,以及如何通过在提取的特征上训练线性层来显著提升性能。得益于 DINOv2 的高质量嵌入,我们仅使用少量带标签的图像即可训练出准确的分类器。
完整代码可在下面嵌入的 Colab 笔记本中找到,供您探索并调整到您自己的数据。
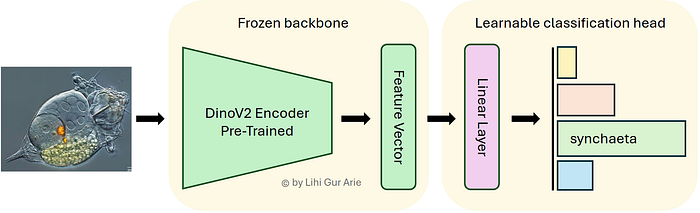
管道:图像由 DINOv2 编码为特征向量,然后用于训练线性分类头 | 图片由作者提供。
背景
DINO (无标签 Distillation 的缩写)由Meta 开发,是一种以自监督方式训练视觉模型的方法,无需标签。生成的 DINO 模型是强大的视觉基础模型,能够从图像中提取丰富的特征。通过在 DINOv2 主干上附加不同的头部,该模型可以适应不同的视觉任务,例如图像分类、分割、深度估计等等。虽然本教程不会训练 DINO 的主干,但了解它最初的训练方式将大有裨益。如果您急于了解代码,可以直接跳到代码实现部分。
𝐃𝐈𝐍𝐎𝐯𝟏
DINO的第一个版本引入了一种自我蒸馏技术,让学生网络学习预测教师网络的输出。教师网络和学生网络共享相同的架构:一个视觉变换器 (Vision Transformer) 主干网络 (ViT) 和一个三层 MLP(多层感知器)头网络。教师网络还引入了居中和锐化功能,以避免崩溃。在训练期间,教师网络接收图像的大裁剪图像(全局视图),而学生网络则处理同一图像的小裁剪图像(局部视图)和大裁剪图像。裁剪图像通过网络进行处理,学生网络尝试预测锐化(低温)教师网络的输出。锐化是通过在教师网络的 softmax 中使用低温值来实现的,以将教师网络的置信度提升到主导维度,从而更好地指导学生网络。
学生的权重用交叉熵成本函数更新,老师的权重更新为学生网络的指数移动平均值。
𝐃𝐈𝐍𝐎𝐯𝟐
DINOv2通过整合多项关键改进,增强了原有框架。DINOv2 的核心在于协同工作的双重目标:
- 图像级目标- 继承自 DINO,此目标鼓励学生网络匹配教师网络的全局图像表征。它基于类别标记进行操作,以捕捉图像的整体视图。
- 块级 目标- 受iBOT启发,此目标涉及遮盖学生输入中的某些块。然后,学生尝试使用周围可见的块作为上下文来预测这些被遮盖的区域。计算学生和教师块特征之间的交叉熵,以促进局部特征理解。
这种双重目标方法既鼓励通过图像级目标对图像进行高层次的理解,又鼓励通过补丁级目标进行详细的局部感知,从而产生更丰富的视觉表现。
最终的训练损失是 DINO 损失和 iBOT 损失的加权和,有效平衡全局和局部学习信号。
此外,DINOv2 还引入了其他多项优化,包括改进的规范化和正则化策略、多分辨率训练方案以及在高质量精选图像数据集上进行训练。您可以点击此处了解更多信息。
代码实现
在探索了 DINO 架构及其主干网络训练过程之后,在本教程中,我们将利用预先训练好的 DINOv2 主干网络来提取图像表征向量。首先,我们将使用 kNN 分类器评估其零样本性能。然后,我们将在其上训练一个线性分类层来提升性能。
环境设置
由于我们使用 Hugging Face 来加载预训练模型,请确保您的 Hugging Face 令牌已在您的 Google Colab 环境中设置。
接下来,安装并导入所需的库。
数据集概述
在本教程中,我们将使用EMDS-6微生物数据集(该数据集最初设计用于图像分割),并对其进行了调整以用于分类。该数据集包含 21 个微生物类别,这些类别具有相似的视觉特征,因此是一项细粒度的分类任务。由于每个类别只有 40 幅图像,而用于训练的图像仅 32 幅,因此在低数据环境下也面临着挑战。
我已将数据预先分成 80% 的训练集和 20% 的验证集。您可以下载准备好的版本,其结构如下:
每个子文件夹以一个类别命名,并包含相应微生物的 PNG 图像。以下是从数据集中随机抽取的样本,共 21 个类别,每个类别包含一张图像:

现在我们已经下载并查看了数据集,我们将设置一个数据管道来加载和预处理图像。
第一部分 - 零样本分类
在第一部分中,我们将使用 kNN 分类器检查 DINOv2 上的零样本性能。
图像数据加载至DINOv2模型
为了准备用于特征提取的数据,我们使用timm的便捷实用程序,根据模型的数据配置定义图像变换。然后,我们使用该类创建训练和验证 PyTorch 数据ImageDataset集,并将变换应用于每个数据集。最后,DataLoader设置 s 以将图像输入 DINOv2 模型,确保一致的预处理以及图像和标签的高效批处理。
def create_data_loaders ( data_dir, batch_size= 32 , model_name= 'vit_small_patch14_dinov2' , seed= 42 ):
"""
使用 timm 的转换和数据集实用程序创建数据加载器。
"""
# 设置带有种子的生成器,以实现可重复的数据加载
g = torch.Generator()
g.manual_seed(seed)
# 创建转换
data_config = timm.data.resolve_model_data_config(model_name)
data_config[ 'input_size' ] = ( 3 , 518 , 518 ) # DINOv2 的本机分辨率
train_transform = timm.data.create_transform(**data_config, is_training= True )
val_transform = timm.data.create_transform(**data_config, is_training= False )
# 使用 timm 的 Dataset 类创建数据集
train_dataset = ImageDataset(root=os.path.join(data_dir, 'train' ), transform=train_transform)
val_dataset = ImageDataset(root=os.path.join(data_dir, 'val' ), transform=val_transform)
# 创建数据加载器
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle= True ,
num_workers= 2 ,
pin_memory= True ,
generator=g
)
val_loader = DataLoader(
val_dataset,
batch_size=batch_size,
shuffle= False ,
num_workers= 2 ,
pin_memory= True ,
generator=g
)
# 获取类映射
class_names = train_dataset.reader.class_to_idx
id2label = {v: k for k, v in class_names.items()}
label2id = class_names
print ( f"Created data加载器:”)
打印(f“训练:{ len(train_dataset)}个样本,{ len(train_loader)}个批次”)
打印(f“验证:{ len(val_dataset)}个样本,{ len(val_loader)}个批次”)
打印(f“类别数量:{len (class_names)} ")
returntrain_loader, val_loader, id2label, label2id
# 创建数据加载器
train_loader, val_loader, id2label, label2id = create_data_loaders(
data_dir='/content/EMDS6_Data',
batch_size=32, seed=0
)提取 DINOv2 特征
数据加载器准备就绪后,下一步是将图像传入预先训练好的 DINOv2 模型,以提取丰富的特征嵌入。通过设置num_classes=0,我们移除分类头并从主干网络获取原始特征向量。
使用 kNN 进行零样本分类
为了评估 DINOv2 嵌入的质量,我们直接在提取的特征上应用了 k 最近邻 (kNN) 分类器。这个简单的方法无需任何训练——它会根据训练集中最接近的嵌入对每张验证图像进行分类。结果:kNN准确率为83.9 %,考虑到区分 21 个细粒度类别的挑战,这已经相当不错了。话虽如此,我们可以通过在此基础上训练一个线性分类器来进一步提升性能。
第二部分 - 训练线性分类器头
虽然 kNN 基于特征之间的距离进行分类,但它不会根据数据集中划分类别的特定决策边界进行调整。通过训练一个以嵌入作为输入的线性分类器,我们可以更好地塑造特征空间以匹配我们的数据集,并更好地进行类别划分。
特征数据加载器设置
为了在训练期间有效地批量加载数据,我们创建了一组新的DataLoaders 来处理之前提取的 DINOv2 嵌入。
定义线性分类头
我们定义了一个简单的 PyTorch 模型,该模型由一个 Dropout 层和一个全连接线性层组成。模型的输入是 DINOv2 特征向量,输出是每个微生物类别的分类得分。这个轻量级的模型头易于训练,足以取得优异的结果。
训练分类主管
在此步骤中,我们定义训练循环参数并训练线性分类头。该循环会根据验证准确率跟踪最佳模型权重。
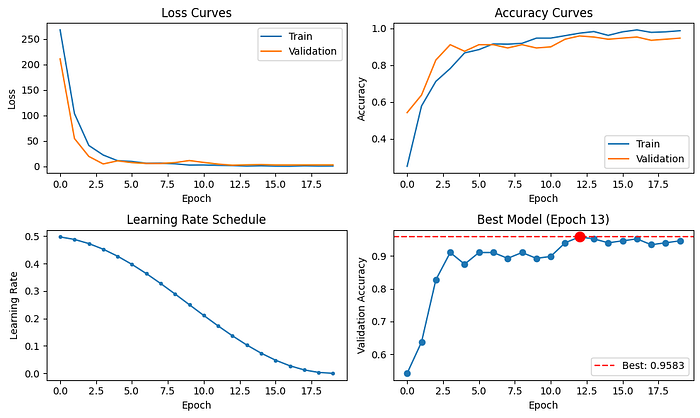
观察下方的训练图,我们观察到在早期阶段,损失明显下降,准确率大幅提升,这表明模型正在有效学习。随着训练的进行和学习率的降低,模型逐渐收敛并稳定下来。性能最佳的模型在第 13 个阶段保存,实现了令人印象深刻的95.8% 的验证准确率 ,相比零样本 kNN 基线有了显著提升!
结束语
在本教程中,我们利用 DINOv2 丰富的嵌入构建了一个精确的微生物分类器。尽管数据集规模较小且具有挑战性,我们仍然通过 kNN 实现了 83.9% 的零样本准确率,并通过训练一个简单的线性头实现了 95.8% 的准确率。DINOv2 非常适合标签有限且视觉细节要求细粒度的场景。然而,其较重的主干使其不太适合实时应用或部署在资源匮乏的边缘设备上。对于需要更深入语义理解的任务,像 CLIP 这样的视觉语言模型可以提供更符合上下文的嵌入。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 25
25 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)