
R语言书籍学习01 《深度学习实践指南——基于R语言》-第五章、第六章 自编码器
目录介绍稀疏自编码器实例:编码器实现输入参数的重构堆叠自编码器实例:堆叠编码器去噪自编码器实例:去噪自编码器介绍自编码器是一种无监督三层特征学习前馈神经网络。输入层的节点数等于输出层的节点数,隐藏层的节点数少于(或多于)输入层节点数。自编码器的目的不是在给定输入x的情况下预测目标值y,而是对输入x进行重构。一个自编码器就是一个尝试对输入数据进行重现的人工神经网络,输出的目的就是输入。自编码器是一个
目录
介绍
自编码器是一种无监督三层特征学习前馈神经网络。输入层的节点数等于输出层的节点数,隐藏层的节点数少于(或多于)输入层节点数。自编码器的目的不是在给定输入x的情况下预测目标值y,而是对输入x进行重构。
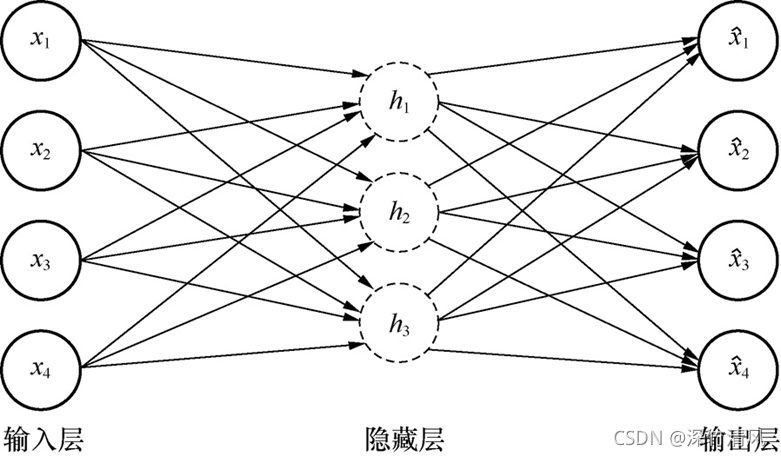
一个自编码器就是一个尝试对输入数据进行重现的人工神经网络,输出的目的就是输入。自编码器是一个前馈神经网络,尝试实现一个恒等函数,训练的时候将输出设置成与输入一致,参数是通过最小化误差函数获得的。
稀疏自编码器
稀疏自编码器使用大量的隐藏层节点,但是只激活其中的一小部分。通过设置隐藏层节点数目远远大于输入层节点数目实现对输入属性向量的非线性映射,然后施加稀疏性约束。最流行的稀疏约束使用Kullback-Leibler(KL)距离。
稀疏自编码器可以产生更多种类的模型,而且允许稀疏表示的特征更有可能含有最初输入数据的可判别特征。
实例:编码器实现输入参数的重构
aburl='http://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.data'
names=c("sex","length","diameter","height","whole.weight","shucked.weight","viscera.weight","shell.weight","rings")
data=read.table(aburl,header=F,sep=",",col.names=names)
summary(data)
data[data$height==0,]
data$height[data$height==0]=NA
data<-na.omit(data)
data$sex<-NULL
summary(data)
datal<-t(data)
datal<-as.matrix(datal)
#编码器
library(autoencoder)
set.seed(2021)
n=nrow(data)
train<-sample(1:n,10,FALSE)
fit<-autoencode(X.train=datal[,train],X.test=NULL,
nl=3,
N.hidden=5,
unit.type="logistic",
lambda=1e-5,
beta=1e-5,
rho=0.07,
epsilon=0.1,
max.iterations=100,
optim.method=c("BFGS"),
rel.tol=0.01,
rescale.flag=TRUE,
rescaling.offset=0.001)
fit$mean.error.training.set
#预测
features<-predict(fit,X.input=datal[,train],hidden.output=TRUE)
features$X.output
pred<-predict(fit,X.input=datal[,train],hidden.output=FALSE)堆叠自编码器
堆叠自编码器是多层神经网络,每一层是一个自编码器,每层的输出连到下一层的输入。中间层的节点数目逐步减少,最终产生数据的“压缩”表示。
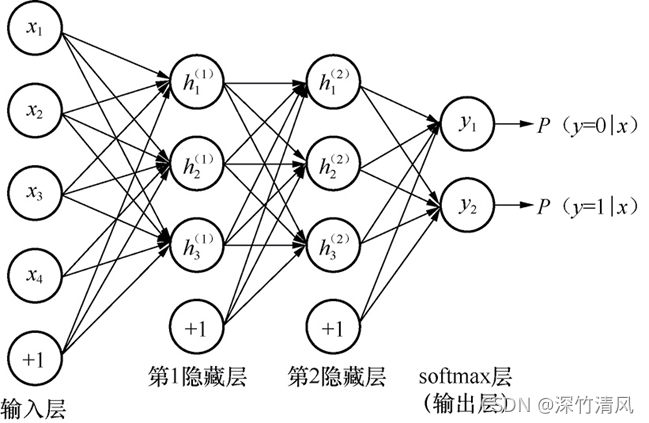
实例:堆叠编码器
注:SAENET包我安装不了……
#堆叠编码器
library(SAENET)
aburl='http://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.data'
names=c("sex","length","diameter","height","whole.weight","shucked.weight","viscera.weight","shell.weight","rings")
data=read.table(aburl,header=F,sep=",",col.names=names)
data$sex<-NULL
data$height[data$height==0]=NA
data<-na.omit(data)
data1<-as.matrix(data)
set.seed(2021)
n=nrow(data)
train<-sample(1:n,10,FALSE)
#训练
fit<-SAENET.train(X.train=data1[train,],
n.nodes=c(5,4,2),
unit.type="logistic",
lambda=1e-5,
beta=1e-5,
rho=0.07,
epsilon=0.1,
max.iterations=100,
optim.method=c("BFGS"),
rel.tol=0.01,
rescale.flag=TRUE,
rescaling.fooset=0.001)
)summary(data)
data[data$height==0,]
data$height[data$height==0]=NA
data<-na.omit(data)
data$sex<-NULL
summary(data)
datal<-t(data)
datal<-as.matrix(datal)
去噪自编码器
去噪自编码器和常规的自编码器一样,也是由输入层、隐藏层和输出层组成,区别在于在训练阶段对输入随机添加了噪声。
对于堆叠去噪自编码器的预训练过程也是每次一层,与堆叠自编码器的方法一样,目标在于最小化重构误差。
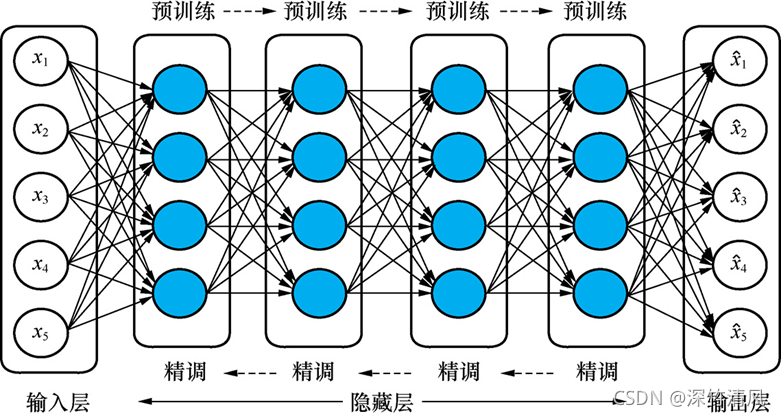
实例:去噪自编码器
#去噪自编码器
library(RcppDL)
library("ltm")
data(Mobility)
data<-Mobility
n=nrow(data)
sample<-sample(1:n,1000,FALSE)
data<-as.matrix(Mobility[sample,])
n=nrow(data)
train<-sample(1:n,800,FALSE)
#创建训练样本和测试样本的属性
x_train<-matrix(as.numeric(unlist(data[train,])),nrow=nrow(data[train,]))
x_test<-matrix(as.numeric(unlist(data[-train,])),nrow=nrow(data[-train,]))
x_train<-x_train[,-3]
x_test<-x_test[,-3]
head(x_test)
y_train<-data[train,3]
temp<-ifelse(y_train==0,1,0)
y_train<-cbind(y_train,temp)
y_test<-data[-train,3]
temp1<-ifelse(y_test==0,1,0)
y_test<cbind(y_test,temp1)
head(y_test)
hidden=c(10,10)
fit<-Rsda(x_train,y_train,hidden)
setCorruptionLevel(fit,x=0.0)
summary(fit)
$PretrainLearningRate
$CorruptionLevel
$PretrainingEpochs
$FinetuneLearningRate
pretrain(fit)
finetune(fit)
predProb<-predict(fit,x_test)
head(predProb,6)
#构建混淆矩阵
pred1<-ifelse(predProb[,1]>=0.5,1,0)
table(pred1,y_test[,1],
dnn=c("Predicted","Observed"))
setCorruptionLevel(fit,x=0.25)
pretrain(fit)
finetune(fit)
predProb<-predicgt(fit,x_test)
pred1<-ifelse(predProb[,1]>=0.5,1,0)
table(pred1,y_test[,1],
dnn=c("Predicted","Observed"))

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)