
《动手学深度学习》---从零开始实现softmax回归
前言内容来自09 Softmax 回归 + 损失函数 + 图片分类数据集【动手学深度学习v2】_哔哩哔哩_bilibili动手学深度学习 v2 - 从零开始介绍深度学习算法和代码实现课程主页:https://courses.d2l.ai/zh-v2/教材:https://zh-v2.d2l.ai/https://www.bilibili.com/video/BV1K64y1Q7wu?p=43.6.
目录
前言
内容来自
09 Softmax 回归 + 损失函数 + 图片分类数据集【动手学深度学习v2】_哔哩哔哩_bilibili动手学深度学习 v2 - 从零开始介绍深度学习算法和代码实现课程主页:https://courses.d2l.ai/zh-v2/教材:https://zh-v2.d2l.ai/ https://www.bilibili.com/video/BV1K64y1Q7wu?p=43.6. softmax回归的从零开始实现 — 动手学深度学习 2.0.0-beta0 documentation
https://www.bilibili.com/video/BV1K64y1Q7wu?p=43.6. softmax回归的从零开始实现 — 动手学深度学习 2.0.0-beta0 documentation https://zh-v2.d2l.ai/chapter_linear-networks/softmax-regression-scratch.html
https://zh-v2.d2l.ai/chapter_linear-networks/softmax-regression-scratch.html
以及 d2l-zh-pytorch书上的内容,在一些地方加入自己的理解与笔记。
什么是softmax回归
回归可以⽤于预测多少的问题。⽐如预测房屋被售出价格,或者棒球队可能获得的胜场数,⼜或者患者住院 的天数。 事实上,我们也对分类问题感兴趣:不是问“多少”,⽽是问“哪⼀个”:
• 某个电⼦邮件是否属于垃圾邮件⽂件夹?
• 某个⽤⼾可能注册或不注册订阅服务?
• 某个图像描绘的是驴、狗、猫、还是鸡?
• 某⼈接下来最有可能看哪部电影?
通常,机器学习实践者⽤分类这个词来描述两个有微妙差别的问题:
1. 我们只对样本的“硬性”类别感兴趣, 即属于哪个类别;
2. 我们希望得到“软性”类别,即得到属于每个类别的概率。这两者的界限往往很模糊。 其中的⼀个原因是:即使我们只关⼼硬类别,我们仍然使⽤软类别的模型。
事实上,softmax就是在做这样一件事,使用训练集训练出一个softmax模型后,再给模型输入一个样本,他可以得到这个样本经过模型得到的预测每个label的概率,我们可以选概率最大或最小或基于某种规则选取我们想要的结果。
举个例子
我们从⼀个图像分类问题开始。假设每次输⼊是⼀个2 × 2的灰度图像。我们可以⽤⼀个标量表⽰每个像素值, 每个图像对应四个特征x1, x2, x3, x4。此外,假设每个图像属于类别“猫”,“鸡”和“狗”中的⼀个。
接下来,我们要选择如何表⽰标签。我们有两个明显的选择:最直接的想法是选择y ∈ {1, 2, 3},其中整数分 别代表{狗, 猫, 鸡}。这是在计算机上存储此类信息的有效⽅法。如果类别间有⼀些⾃然顺序,⽐如说我们试 图预测{婴⼉, ⼉童, ⻘少年, ⻘年⼈, 中年⼈, ⽼年⼈},那么将这个问题转变为回归问题,并且保留这种格式是 有意义的。
但是⼀般的分类问题并不与类别之间的⾃然顺序有关。幸运的是,统计学家很早以前就发明了⼀种表⽰分类 数据的简单⽅法:独热编码(one-hot encoding)。独热编码是⼀个向量,它的分量和类别⼀样多。类别对 应的分量设置为1,其他所有分量设置为0。在我们的例⼦中,标签y将是⼀个三维向量,其中(1, 0, 0)对应于 “猫”、(0, 1, 0)对应于“鸡”、(0, 0, 1)对应于“狗”:
y ∈ {(1, 0, 0),(0, 1, 0),(0, 0, 1)}.
为了估计所有可能类别的条件概率,我们需要⼀个有多个输出的模型,每个类别对应⼀个输出。为了解决线 性模型的分类问题,我们需要和输出⼀样多的仿射函数(affine function)。每个输出对应于它⾃⼰的仿射函 数。在我们的例⼦中,由于我们有4个特征和3个可能的输出类别,我们将需要12个标量来表⽰权重(带下标 的w),3个标量来表⽰偏置(带下标的b)。下⾯我们为每个输⼊计算三个未规范化的预测(logit):o1、o2和o3。
o1 = x1w11 + x2w12 + x3w13 + x4w14 + b1,
o2 = x1w21 + x2w22 + x3w23 + x4w24 + b2,
o3 = x1w31 + x2w32 + x3w33 + x4w34 + b3.
我们可以⽤神经⽹络图来描述这个计算过程。与线性回归⼀样,softmax回归也是⼀个单层神经⽹络。 由于计算每个输出o1、o2和o3取决于所有输⼊x1、x2、x3和x4,所以softmax回归的输出层也是全连接层。
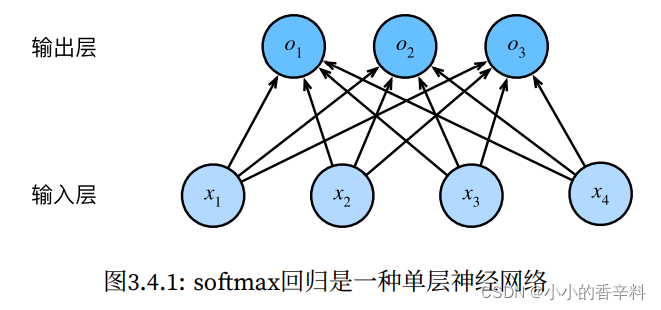
为了更简洁地表达模型,我们仍然使⽤线性代数符号。通过向量形式表达为o = Wx + b,这是⼀种更适合数 学和编写代码的形式。由此,我们已经将所有权重放到⼀个3 × 4矩阵中。对于给定数据样本的特征x,我们的输出是由权重与输⼊特征进⾏矩阵-向量乘法再加上偏置b得到的。
现在我们将优化参数以最⼤化观测数据的概率。为了得到预测结果,我们将设置⼀个阈值,如选择具有最⼤ 概率的标签。
我们希望模型的输出yˆj可以视为属于类j的概率,然后选择具有最⼤输出值的类别argmaxj yj作为我们的预 测。例如,如果yˆ1、yˆ2和yˆ3分别为0.1、0.8和0.1,那么我们预测的类别是2,在我们的例⼦中代表“鸡”。
然⽽我们能否将未规范化的预测o直接视作我们感兴趣的输出呢?答案是否定的。因为将线性层的输出直接 视为概率时存在⼀些问题:⼀⽅⾯,我们没有限制这些输出数字的总和为1。另⼀⽅⾯,根据输⼊的不同,它们可以为负值。这些违反了概率基本公理。
要将输出视为概率,我们必须保证在任何数据上的输出都是⾮负的且总和为1。此外,我们需要⼀个训练⽬ 标,来⿎励模型精准地估计概率。在分类器输出0.5的所有样本中,我们希望这些样本有⼀半实际上属于预测 的类。这个属性叫做校准(calibration)。
社会科学家邓肯·卢斯于1959年在选择模型(choice model)的理论基础上发明的softmax函数正是这样做的: softmax函数将未规范化的预测变换为⾮负并且总和为1,同时要求模型保持可导。我们⾸先对每个未规范化 的预测求幂,这样可以确保输出⾮负。为了确保最终输出的总和为1,我们再对每个求幂后的结果除以它们的 总和。如下式:
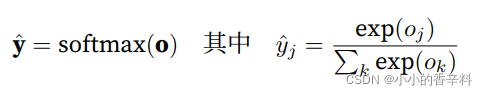
这⾥,对于所有的j总有0 ≤ yˆj ≤ 1。因此,yˆ可以视为⼀个正确的概率分布。softmax运算不会改变未规范化 的预测o之间的顺序,只会确定分配给每个类别的概率。因此,在预测过程中,我们仍然可以⽤下式来选择最 有可能的类别。
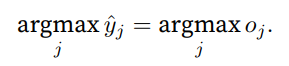
尽管softmax是⼀个⾮线性函数,但softmax回归的输出仍然由输⼊特征的仿射变换决定。因此,softmax回归是⼀个线性模型(linear model)。
所以,到这里,softmax回归做了什么事情就明白了。简单总结就是给定一个样本的各个特征x1、x2、、、xn组成的向量x(或矩阵X),进行o=Wx+b(或WX+b)操作,再将o经过softmax函数映射成每个类别的概率,存储到y=softmax(o)中,输出即为y=[p(预测为类别1),p(预测为类别2),p(预测为类别3)]。
这里我还想提一下输入样本x或X的矢量化,矢量化是为了方便代码实现,计算机都是用数组去存数据的,所以矢量化就是用向量或者矩阵表示我们的大量样本。在我们进行训练的时候,如果只是每次输入一个样本去训练,速度太慢了,往往都是批量传入模型,因此,常常会将输入数据用矩阵X表示。其实一个样本的还好理解,矢量化公式就是
![]()
展开形式就是
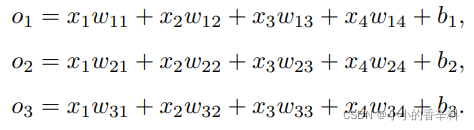
但是批量样本的矢量化我理解的时候还蛮费劲的,矢量化公式为
![]()
展开形式我花时间画了一下,在下图中

最后附上李沐书上的批量样本矢量化原话,自行配合理解~

具体代码实现
1.导包
import torch
from IPython import display
from d2l import torch as d2l
import torchvision
from torch.utils import data
from torchvision import transforms2.批量下载数据集
使用李沐他们写好的d2l包调用相关方法下载fashion_mnist数据集
d2l.use_svg_display#使图像以svg显示,更加清楚
#批量下载读取数据集
batch_size=20
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size)数据集长这样,共有10类标签和对应的图片
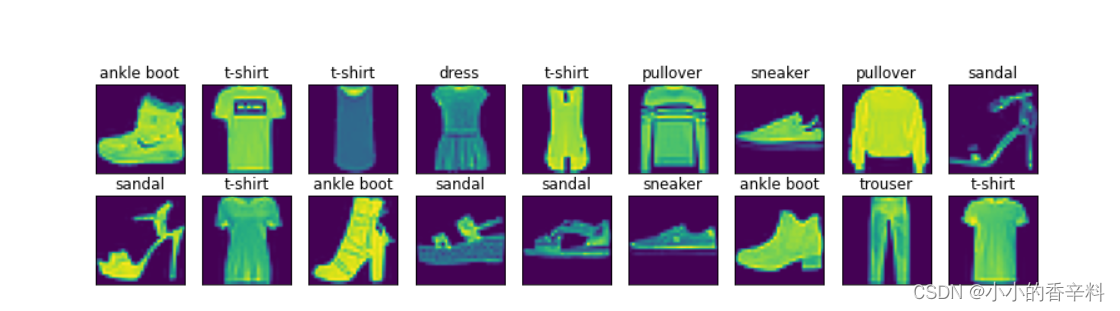
测试一下是否下载并读取成功
#看一下读取数据需要的时间
timer = d2l.Timer()
for X,y in test_iter:
continue
f'{timer.stop():.2f} sec'3.初始化模型参数
输出有10类,输入的图片尺寸为28*28像素,那么输入特征大小就是28*28,也就是输入样本的矩阵X形状为 (样本数行,特征数列即28*28列)。系数矩阵W形状为(特征数行,输出节点数)。偏置向量b为行向量,形状为(1,输出节点数)。
#输出节点个数即为特征数
num_inputs = 784
#输出节点个数即为类别数
out_inputs = 10
W = torch.normal(0,0.01,size=(num_inputs,out_inputs),requires_grad=True)#需要计算梯度来更新参数
b = torch.zeros(size=(1,out_inputs),requires_grad=True)#需要计算梯度来更新参数4.定义softmax函数
softmax公式如下:

对于维度为n*d的X,其每一行代表一个样本,每一列代表一个特征,比如X_1_2就代表第一个样本的第二个特征。 将这样的X传入softmax后,得到的矩阵X_prob的每一行代表将一个样本传入softmax得到的各个类别概率,因此,每行的元素相加为1.
def softmax(X):
X_exp = torch.exp(X)#对矩阵中的每个元素取e指数
fenmu = X_exp.sum(1,keepdim=True)#保留行,保留维度
return X_exp/fenmu测试softmax函数
注意,虽然这在数学上看起来是正确的,但我们在代码实现中有点草率。矩阵中的⾮常⼤或⾮常⼩的元素可能造成数值上溢或下溢,但我们没有采取措施来防⽌这点。
X = torch.normal(0,1,(2,5))
X_prob = softmax(X)
X_prob,X_prob.sum(1)
很好,softmax函数貌似没有问题。
5.定义模型
传入的X是图片的原始形状,需要reshape成X (样本数行,特征数列)
def net(X):
return softmax(torch.matmul(X.reshape(-1,W.shape[0]),W)+b)6.定义损失函数
def cross_entropy(y_hat,y):
return -torch.log(y_hat[range(len(y_hat)),y])7.定义评估函数
定义accuracy函数,返回模型预测正确的样本数量
def accuracy(y_hat,y):
#计算预测正确的数量
if len(y_hat.shape)>1 and y_hat.shape[1]>1: #预测矩阵是二维,且列数>1
y_hat = y_hat.argmax(axis=1)#得到一维的结果,每个值代表每个样本的预测类别
cmp = y_hat.type(y.type()) == y
return float(cmp.type(y.type()).sum())定义了一个累加器,这个累加器初始化为长度为n的列表。调用add(args)函数可以不断地往这个列表里面加args元素。
class Accumulator:
def __init__(self,n):
self.data = [0.0]*n
def add(self,*args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self,idx):
return self.data[idx]定义评估函数,可以计算在指定数据集上模型的精度。
def evaluate_accuracy(net, data_iter): #@save
"""计算在指定数据集上模型的精度"""
if isinstance(net, torch.nn.Module):
net.eval() # 将模型设置为评估模式
metric = Accumulator(2) # 正确预测数、预测总数
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]定义画图类,方便loss的动态展示,我个人感觉不会的可以不用了解,这也只是当成一个工具使用,什么时候需要,copy一份拿来改改就行。
class Animator: #@save
"""在动画中绘制数据"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
# 增量地绘制多条线
if legend is None:
legend = []
d2l.use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# 使用lambda函数捕获参数
self.config_axes = lambda: d2l.set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# 向图表中添加多个数据点
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)8.定义训练函数
该函数用于一个epoch的训练,其整体过程和从零实现线性回归很相似。《动手学深度学习》---线性回归的从零开始实现的一些理解_小小的香辛料的博客-CSDN博客李沐《动手学深度学习》---线性回归的从零开始实现的理解和笔记 https://blog.csdn.net/doubleguy/article/details/124152396?spm=1001.2014.3001.5501
https://blog.csdn.net/doubleguy/article/details/124152396?spm=1001.2014.3001.5501
def train_epoch_ch3(net, train_iter, loss, updater):
#训练一个epoch的模型
#将模式设置为训练模式
if isinstance(net,torch.nn.Module):
net.train() #训练模式和评估模式在一般的神经网络中是一样的,只有当模型中存在dropout和batchnorm的时候才有区别
#定义一个累加器存储训练loss总和、训练准确度总和、样本数
metric = Accumulator(3)
for X,y in train_iter:
#计算梯度并更新参数
y_hat = net(X)#正向传播
l = loss(y_hat,y)#正向传播,得到一维向量,由每个样本经过 H(P,Q)=-sum(P * logQ) 算得,其中P为真实值概率,Q为预测值概率
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad()#参考线性回归,它也是在sgd优化函数中进行的梯度清0
l.mean().backward()#注意这里是取得平均loss
updater.step()#更新参数
else:
#使用自定义优化器和损失函数
l.sum().backward()
updater(X.shape[0])#传入batch_size
metric.add(float(l.sum()),accuracy(y_hat, y), y.numel())
#返回训练损失和训练精度
return metric[0]/metric[2],metric[1]/metric[2]使用上面的一个epoch的函数来定义完整的训练函数
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save
"""训练模型(定义见第3章)"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc9.开始训练
初始化学习率和epoch轮数,定义了优化器为小批量随机梯度下降。
开始训练!
lr = 0.1
def updater(batch_size):
return d2l.sgd([W, b], lr, batch_size)
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)结果如下,其实这个图示动态的,每训练一轮他就会动态更新loss图,但是我感觉直接画最后完整的loss也可以啦,所以那个Animation类个人感觉可有可无。想装杯的就给我冲~
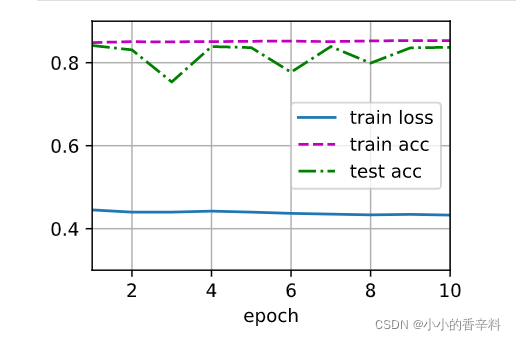
10.进行预测
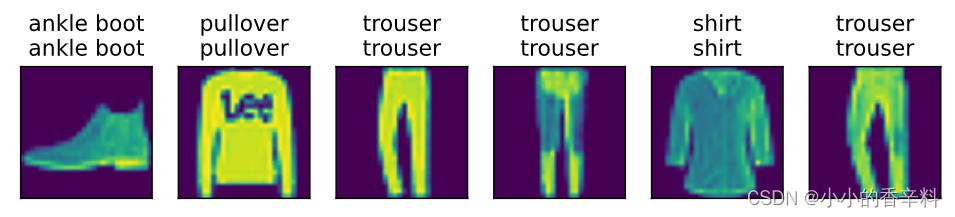
def predict_ch3(net, test_iter, n=6): #@save
"""预测标签(定义见第3章)"""
for X, y in test_iter:
break
trues = d2l.get_fashion_mnist_labels(y)
preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))
titles = [true +'\n' + pred for true, pred in zip(trues, preds)]
d2l.show_images(
X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])
predict_ch3(net, test_iter)结果如下,引用李沐的话说是“运气真好~”

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)