
神经网络基础-CNN网络
神经网络基础——CNN神经网络1、CNN概述1.1导论CNN神经网络,即卷积神经网络,其广泛应用于图像处理问题上和其他的一些问题上。我们下面从一张图像开始,对于一张图像而言,其是由多个像素所组成的,即图像可以看做是由像素点矩阵所构成的。我们将每一个像素看做是图像的一个特征,那么整个图像就是由这些特征矩阵所构成的。如果我们能够设计出一种神经网络,这种网络能够学习到图像的特征,那么我们就可...
神经网络基础——CNN神经网络
1、CNN概述
1.1 导论
CNN神经网络,即卷积神经网络, 其广泛应用于图像处理问题上和其他的一些问题上。我们下面从一张图像开始,对于一张图像而言,其是由多个像素所组成的,即图像可以看做是由像素点矩阵所构成的。我们将每一个像素看做是图像的一个特征,那么整个图像就是由这些特征矩阵所构成的。如果我们能够设计出一种神经网络,这种网络能够学习到图像的特征,那么我们就可以利用这些学习到的网络参数来进行下一步的分类、识别等任务。而我们下面提出的CNN网络就是对这种特征进行学习。
1.2 图像的通道问题
对于一张图片而言,其中用不同的色彩进行,我们将每一种色彩看做是一个通道。例如,对于一个RGB图片而言,其是由红,绿,蓝三种基本颜色所描述的,所以对于一张RGB图片而言,其是由三个通道组成的,每一个通道上具有相同数量的像素点。
1.3 CNN的基本结构
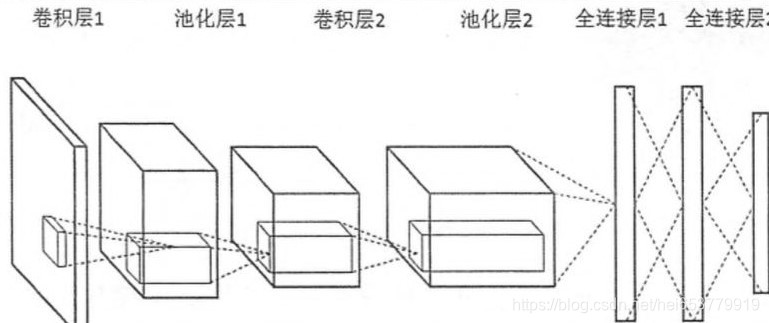
图片来源:https://www.cnblogs.com/Terrypython/p/10496078.html
根据上面的结构图,我们可以有一个直观的了解,对于一个卷积网络而言,其基本的结构包括卷积层,池化层和全连接层。下面我们逐个对这三个基本结构进行介绍。
2、CNN结构详解
2.1 卷积层
2.1.1 特征的局部性
假设我们有下面的一张图片:
(图片来源:https://image.baidu.com/search/detailct=503316480&z=0&ipn=d&word=%E7%AF%AE%E7%90%83)
上面的图片是一个篮球和一个足球,对于上面的图片,一部分是用来展示篮球的,另外一部分是用来展示足球的。这就是特征的局部性。也就是说,对于一张图片而言。不同的区域刻画的可能是不同物体的特征。所以我们也就没有必要将整张图片全部的特征同时都输入到一个神经元中进行学习。可以按照区域,逐步的将每个区域的特征输入到神经元中。这样做的另外一个好处是可以降低参数。比如,如这个图片中包含256个像素点,如果同时输入到一个神经元中,则需要的是256个参数。假设篮球部分和足球部分分别有128个像素,那么按照区域,每次输入的是128个像素,那么也就只需要128个参数。
2.1.2 参数共享
下面我们讨论下一个问题,对于上面的图片,篮球在足球的左侧,现在如果将两个球的位置调换,那么整张图片表示的还是一个篮球和一个足球,而我们学习到的特征应该还是应该表示篮球和足球的特征。也就是说物体在图像的特征应该和物体在图像中的位置无关。为了实现这种机制,我们采用对于图像的每一片区域,同个相同的一些神经单元进行学习的机制来避免这种位置的影响。这种机制就是参数共享。
2.1.3 卷积操作
上面介绍了局部连接和参数共享机制,下面我们开始正式介绍卷积操作:
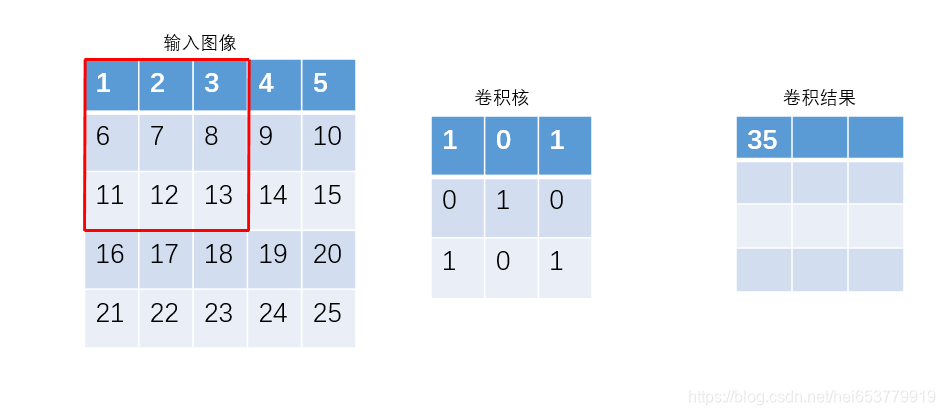
首先,我们假设左侧为我们所输入的图片的某一个通道的特征矩阵,中间表示的是我们要进行特征抽取的神经单元,将其称作为卷积核,右侧为特征抽取之后的结果。其基本的计算过程如下,用卷积核在输入图像不同区域上进行滑动,同时对特征进行抽取。可以看到,卷积核首先在图像的左上部区域进行卷积,其计算过程为:1 * 1+0 * 2+3 * 1+6 * 0+7 * 1+8 * 0+11 * 1+12 * 0+13 * 0=35,通过卷积核在图像上的不断滑动,最终生成右侧的卷积结果矩阵。
2.1.4 步长和Padding
步长:值得就是卷积核在输入图像上滑动时,每次滑动的距离,在上面的计算中,卷积核每次滑动的步长
是1,所以生成3 * 3结果矩阵。卷积核的步长,可以根据实际情况进行设定。
Padding:对于上面的输入图像,当卷积核的步长为3时,也就是卷积核每次滑动的距离为3,那么卷积核只能提取到左上角的特征,是不能向右和向下滑动的。这样就会导致下面和右面分别有两行和两列没有被卷积核进行特征提取。此时可以选择对图像的四周进行填充,使得整张图像的所有区域可以被卷积核扫描到,这种填充的方式被称为padding,padding的数量可以根据实际情况来制定。选择进行padding的另外一个原因是因为,当有多个卷积层的时候,图像不同的被各个卷积层的卷积核进行扫描,得到的结果也会越来越小,到最后,结果可能仅剩下了一个。当然,当卷积层的数量比较少的时候,也可以选择对于剩余的特征进行舍弃。
2.1.5 多通道的卷积计算
上面我们提到过通道的概念,对于一张RGB的图片而言,其是由红绿蓝三个通道所构成的,每一个通道上对应着一个图片的像素矩阵,为了提取各个通道的上的特征,我们采用多个卷积核的方式分别对各个通道上的特征进行提取,其中各个通道上卷积核的参数是不共享的。如下图所示:
图片来源:https://image.baidu.com/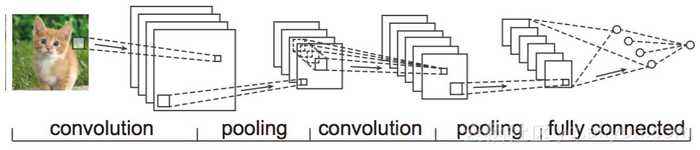
对于上面的图片,采用的就是使用多个卷积核分别对图像的各个特征进行卷积操作。同时,我们还可以定义多个输出的通道,也就是说可以采用更多的卷积核对输入图像进行扫描。
2.2 池化层(pooling)
通过上面的图不难发现,通过pooling以后,卷积操作所获得的卷积结果又进一步的缩小了,这个过程实际上就是获取粗粒度信息的过程,这个过程模拟的是人类通常采用宏观的角度模糊地去观察事物。这种模糊化的操作就体现为将输入特征图的多个特征像素点池化后压缩成一个像素点。
2.2.1 最大池化(max-pooling)
如下图所示: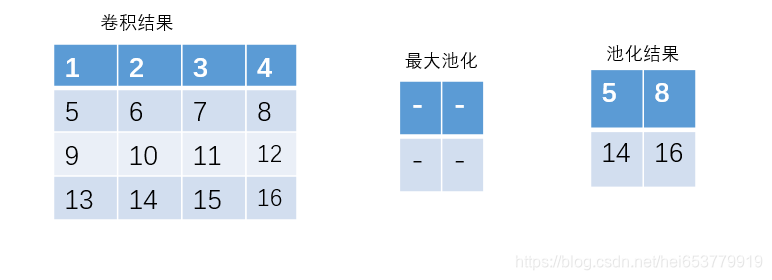
通过上面的图,我们可以总结池化层的几个特点。
- 池化层的计算过程类似于卷积过程,是在输入图像上进行滑动。
- 与卷积操作不同的是,池化层的滑动是不能有重叠的,也就是说池化滑动的最小步长为池化层的维度。
- 池化层是不需要参数,在上图的计算中,直接取池化区域内的最大值即可。
- 池化层一般是不需要padding操作的。
2.2.2 均值池化(mean-pooling)
均值池化的过程与最大池化的唯一区别在于,池化过程中不是取池化区域的最大值,而是取池化区域的平均值。在此不做赘述。
2.3 全连接层
通过池化层或者卷积层的操作之后,我们获得的是关于一张图像的多个特征矩阵,对于卷积神经网络的全连接层而言,我们只需要将这些特征矩阵进行展开,将二维的矩阵转换成一维的向量输入到全连接层即可。一般情况下,该层是整个卷积神经网络中,参数最多的层。
3、CNN的参数计算
首先,我们假设输入的图片的(通道数,长,宽)为(n,k,k),卷积核的尺寸为(s,s),而且我们要输出的通道数为m,则首先我们通过多个卷积核提取输入图片的所有通道的所有特征,则对应的参数数量为 n * s * s,然后将提取的特征在对应到m输出通道中,每一个输入通道的参数来源都是从图片中提取到特征的参数n * s * s,则一共的参数为 s * s * n * m
4、CNN实践-手写数字识别
pre_process_data.py
#encoding=utf-8
import torch
import torchvision.datasets as dets
import torchvision.transforms as transforms
class loadData:
def __init__(self,batch_size):
self.traindata = None
self.testdata = None
self.batch_size = batch_size
def get_data(self):
self.traindata = dets.MNIST('./data', train=True,transform=transforms.ToTensor(),download=True)
self.testdata = dets.MNIST('./data',train=False,transform=transforms.ToTensor())
def dataLoader(self):
#定义数据加载器
train_loader = torch.utils.data.DataLoader(dataset=self.traindata,batch_size=self.batch_size,shuffle=True)
#下面将测试集分为校验集和测试集
index = range(len(self.testdata))
index_val = index[:5000]
index_test = index[5000:]
#定义校验集和测试集的数据采样器
sampler_val = torch.utils.data.sampler.SubsetRandomSampler(index_val)
sampler_test = torch.utils.data.sampler.SubsetRandomSampler(index_test)
#定义校验数据和测试数据的数据加载器
val_loader = torch.utils.data.DataLoader(dataset=self.testdata,batch_size=self.batch_size,
shuffle=False,sampler=sampler_val)
test_loader = torch.utils.data.DataLoader(dataset=self.testdata,batch_size=self.batch_size,
shuffle=False,sampler=sampler_test)
return train_loader,val_loader,test_loader
model.py
encoding=utf-8
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
import torch.optim as optim
#定义一些超参数
image_size = 28
num_class = 10
class cnnModel(nn.Module):
def __init__(self):
super(cnnModel,self).__init__()
#定义第一层卷积
self.conv1 = nn.Conv2d(1, 4, 5,padding=2)
#定义池化
self.pooling1 = nn.MaxPool2d(2,2)
#第二层卷积,输入通道数4,输出通道数8
self.conv2 = nn.Conv2d(4,8,5,padding=2)
#定义全连接层,两层池化,将原来的图像维度缩减为原来的1/4
self.fc1 = nn.Linear(image_size//4 * image_size//4 * 8, 512)
self.fc2 = nn.Linear(512,num_class)
def forward(self,inputs):
#inputs的size (batch_size,input_channels,width,heighth)
outputs = self.conv1(inputs)
#outputs的size(batch_size,4,image_width,image_height_width)
outputs = self.pooling1(outputs)
#outputs的size(batch_size,4,image_width//2,image_height_width//2)
outputs = F.relu(outputs)
#outputs的size(batch_size,4,image_width//2,image_height_width//2)
outputs = self.conv2(outputs)
#outputs的size(batch-size,8,image_width//2,image_height_width//2)
outputs = self.pooling1(outputs)
#outputs的size(batch_size,8,image_width//4,image_height_width//4)
outputs = F.relu(outputs)
#将图片进行压缩,输入到fc中
outputs =outputs.view(-1,image_size//4 * image_size//4 * 8)
#output的size (batch_size,image_size//4 * image_size//4 * 8)
outputs = self.fc1(outputs)
outputs = F.relu(outputs)
outputs = F.dropout(outputs)
#output的size(batch_size,512)
outputs = self.fc2(outputs)
#outputs的size(batch_size,10)
outputs = F.log_softmax(outputs,dim=1)
#output的size(batch_size,10)
return outputs
def review_features(self,inputs):
'''
用于获取卷积神经网络的卷积结果
'''
feature_map1 = F.relu(self.conv1(inputs))
outputs = self.pooling1(feature_map1)
feature_map2 = F.relu(self.conv2(outputs))
return feature_map1,feature_map2
train_and_test.py
#encoding=utf-8
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
import pre_processdata
import model
import matplotlib.pyplot as plt
#定义两个超参数,训练轮数和学习率
num_epoch = 20
learning_rate = 0.001
def rightness(output,target):
pre = torch.max(output.data,1)[1]
rights = pre.eq(target.data.view_as(pre)).sum()
return rights,len(target)
def train_and_test():
#获取数据
predata = pre_processdata.loadData(64)
predata.get_data()
train_loader,val_loader,test_loader = predata.dataLoader()
net = model.cnnModel()
loss = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(),lr=learning_rate,momentum=0.9)
record = []
weights = []
for epoch in range(num_epoch):
train_rights = []
for batch_idx,(train_data,target) in enumerate(train_loader):
train_data,target = Variable(train_data),Variable(target)
net.train()
outputs = net(train_data)
loss_value = loss(outputs,target)
optimizer.zero_grad()
loss_value.backward()
optimizer.step()
accuracy = rightness(outputs,target)
train_rights.append(accuracy)
if batch_idx % 100 == 0 and batch_idx != 0:
net.eval()
val_rights = []
for _,(val_data,val_target) in enumerate(val_loader):
val_data,val_target = Variable(val_data),Variable(val_target)
val_output = net(val_data)
val_right = rightness(val_output,val_target)
val_rights.append(val_right)
train_r = (sum([tup[0] for tup in train_rights ]),sum([tup[1] for tup in train_rights]))
val_r = (sum([tup[0] for tup in val_rights]),sum([tup[1] for tup in val_rights]))
print('epoch:{} [{}/{} ({:.0f}%)]\t,Loss: {:.6f}\t,train_rights: {:.2f}%\t,val_rights:{:.2f}%'
.format(epoch,batch_idx*len(train_data),len(train_loader.dataset),100.*batch_idx/len(train_loader),
loss_value.data,100.*train_r[0]/train_r[1],100.*val_r[0]/val_r[1]))
record.append((100 - 100.*train_r[0] / train_r[1],100-100.*val_r[0]/val_r[1]))
weights.append([net.conv1.weight.data.clone(),net.conv1.bias.data.clone(),
net.conv2.weight.data.clone(),net.conv2.bias.data.clone()])
net.eval()
test_rights = []
for(test_data,test_target) in test_loader:
test_data,test_target = Variable(test_data),Variable(test_target)
test_output = net(test_data)
test_right = rightness(test_output,test_target)
test_rights.append(test_right)
rights = (sum([tup[0] for tup in test_rights]),sum([tup[1] for tup in test_rights]))
right_rate = 1.0 * rights[0] / rights[1]
plt.figure(figsize=(10,7))
plt.plot(record)
plt.xlabel('Steps')
plt.ylabel('Error rate')
if __name__ == '__main__':
train_and_test()

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 1
1 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)