
MedMamba 解释:第一个用于广义医学图像分类的 Vision Mamba 终于来了!!
恭喜您通过了对 MedMamba 的全面深入研究!如果您还在这里并且在我们的数学冒险中没有打瞌睡,那么您值得虚拟竖起大拇指!虽然我努力以易于理解的方式揭开 MedMamba 的核心概念和复杂工作原理的神秘面纱,但这种探索只是触及了这个迷人架构的表面。在原始的 MedMamba 和 Mamba 研究论文中,有一个引人注目的细节、细致入微的组件和技术见解的宝库等待发现。该博客可作为您的智力跳板——为您
自深度学习出现以来,卷积神经网络 (CNN) 和视觉转换器已成为医学图像分类任务的事实上的架构。然而,这些方法在优点的同时也有明显的局限性。CNN 在对远程依赖关系进行建模方面遇到了困难,导致分类性能不佳。Transformer 填补了 CNN 的漏洞,但它们以自注意力的二次复杂性的形式存在自己的一系列计算挑战,这导致计算时间和功耗要求增加。为了解决这些限制,Yue 等人提出了 MedMamba,它利用状态空间模型 (SSM),特别是 Mamba 架构作为其核心。
将显示缩放图像

图 1(来源:MedMamba GitHub 存储库)
这给我们带来了一个问题:是什么让 MedMamba 对医学图像分类任务特别有效?我们将尝试在这篇博文中找到这些问题的答案。通过对数学基础和架构组件的详细探索,我们的目标是提供对模型功能的清晰见解。所以喝杯咖啡,是时候投入其中了!!
赋予动机
如前所述,CNN 和 Vision Transformer (ViT) 及其变体在各自的领域表现出卓越的性能,但也有其自身的一系列局限性。CNN 擅长通过卷积运算捕获局部空间特征,但由于其固有的感受野有限,在对远程依赖关系进行建模方面面临挑战。相反,ViT 利用自注意力机制有效地捕获全局上下文信息;然而,它们在输入序列长度方面存在二次计算复杂性,这使得它们在计算上无法完成在资源限制下运行的实际医学分类任务。
研究表明,将图像的局部特征及其相应的远距离依赖性相结合是准确分类医疗任务的关键。因此,研究人员开发了像 CNN-ViT 这样的混合结构来解决这些问题。虽然提高了精度,但二次计算的问题仍然没有得到解决。因此,在视觉表示学习能力和计算资源消耗之间建立最优权衡对于开发智能临床诊断系统至关重要。
近年来,结构化状态空间模型(SSM)因其计算效率和在远程依赖关系建模方面的出色性能而受到广泛关注。这些模型是循环神经网络 (RNN) 和 CNN 的最佳组合。利用两全其美的优势,这些解决了我们在上述行中讨论的局限性。值得注意的是,由 Albert Gu 和 Tri Dao 开发的 Mamba 是一种最先进的选择性结构化状态空间模型,解决了以前 SSM 的基本局限性,成功地确立了其在远程序列建模任务中的地位,从而成为当今 Transformer World 在自然语言处理 (NLP) 及其他领域的有力竞争对手。
状态空间模型 (SSM) 和 Mamba
要了解 MedMamba,我们需要对 SSM 和 Mamba 架构有一些基本的了解。因此,我们将介绍一些关于 SSM 和 Mamba 架构的要点,在继续之前我们应该了解这些要点。
从状态空间开始,它是一种通过定义系统的可能状态来以数学方式表示问题的方法。想象一下,我们正在迷宫中导航,状态空间是所有可能位置的地图(状态、当前状态、潜在的下一个状态、你为进入下一个状态所做的更改、退出距离)。描述状态和状态空间的变量称为状态向量。
状态空间模型部署在这些状态空间上,用于描述状态表示并预测下一个状态可能是什么。
将显示缩放图像

图2(来源:Maarten Grootendorst的插图)
如图2所示,SSM映射输入序列x(t)并推导预测输出序列y(t)。SSM 从根本上是为连续时间系统设计的,但在深度学习应用中,我们使用通过离散化技术处理的离散序列,以利用连续时间公式。因此,我们必须在输入 SSM 之前将离散序列转换为连续序列,反之亦然。我们该怎么做?
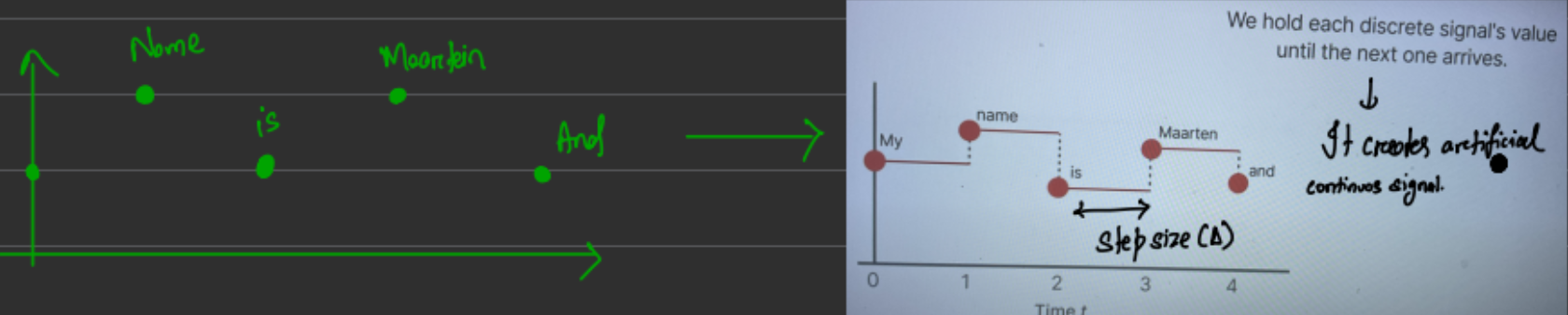
图3(来源:作者图片)
为此,我们使用变量名称“步长 (Δ)”。在这个给定的图 3 示例中,有 5 个点代表“我的名字是火星人和”。步长 (Δ) 表示决定离散系统分辨率的离散化参数。零阶保持 (ZOH) 用于将离散信号转换为分段常数连续信号,以便由连续 SSM 进行处理。
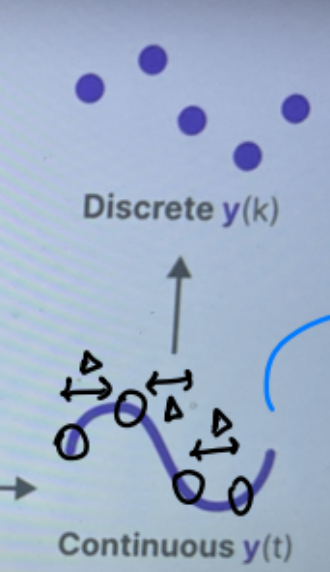
图 4(来源:Maarten Grootendorst 的插图)
您可以反转相同的方法,将连续序列分解回离散序列以显示输出。在上面的图 4 中,您可以看到从 0 开始,将 Δ 添加到您选择的每个点,得到下一个点。这是将离散序列更改为连续并在推理后恢复离散序列的方法。
现在我们知道什么是 SSM,让我们了解控制它的代数。它表示为线性常微分方程 (ODE)。
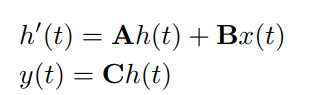
公式 1(来源:MedMamba 官方论文)
其中,A ∈ R^(N×N) 表示状态转换矩阵,B ∈ R^(N×1) 是将输入投影到状态空间的输入矩阵,C ∈ R^(1×N) 是将状态投影到输出空间的输出矩阵。 给定下面的图 5 和 6 有上述方程的图表表示 ~
将显示缩放图像
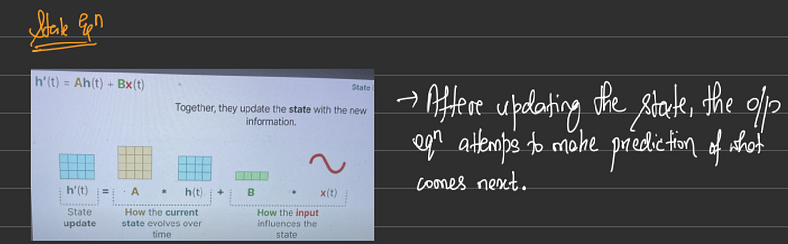
图5(来源:作者图片)
将显示缩放图像
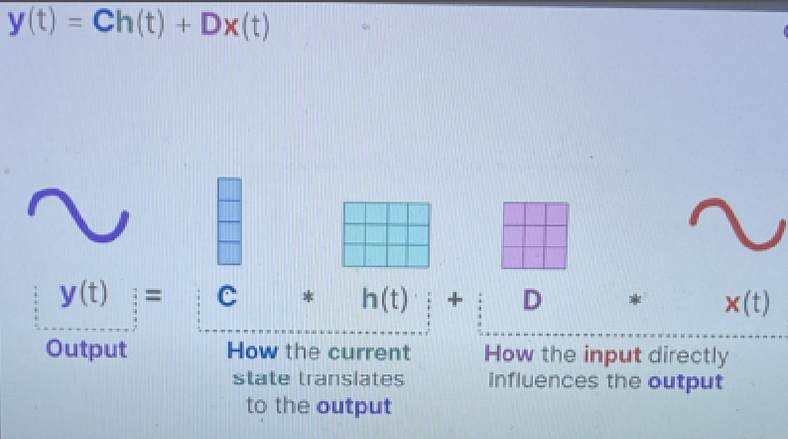
图6(来源:Maarten Grootendorst的插图)
将这两个方程组合在一起后,我们将得到 SSM 架构。如下图7所示。
将显示缩放图像
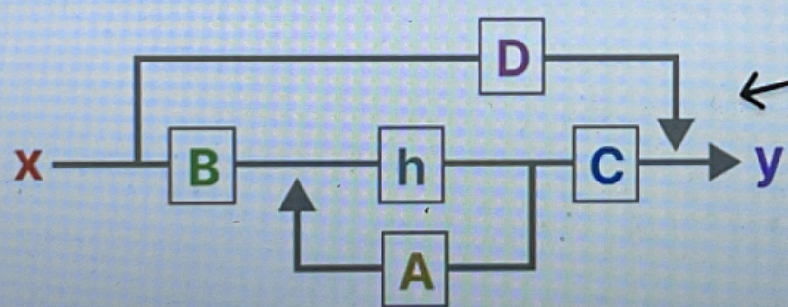
图7(来源:Maarten Grootendorst的插图)
矩阵 D 表示从输入到输出的直接馈通项。虽然它是经典 SSM 公式的一部分,但在深度学习实现中,它经常被省略或被视为简单的跳过连接以简化架构。因此,从技术上讲,矩阵 A、B、C 和 h 是 SSM 块的一部分。
将显示缩放图像
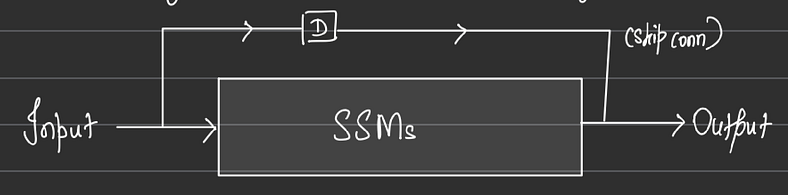
图8(来源:作者图片)
我们之前看到,我们需要将连续系统离散化,使其更适合深度学习。为此,我们使用步长 (Δ) 将 A 和 B 转换为离散参数 A̅ 和 B̅。按照推导,我们得到了这个方程~
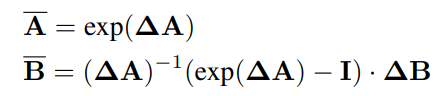
(来源:MedMamba 官方文件)
离散化后,使用步长∆的方程“可以重新定义为 ~
将显示缩放图像
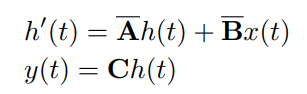
(来源:MedMamba 官方文件)
使用这个方程,我们在 SSM 中进行推理。下面的图 9 显示了序列的开始 ~
将显示缩放图像

图9(来源:作者图片)
这可以用另一种方式来表示~
将显示缩放图像
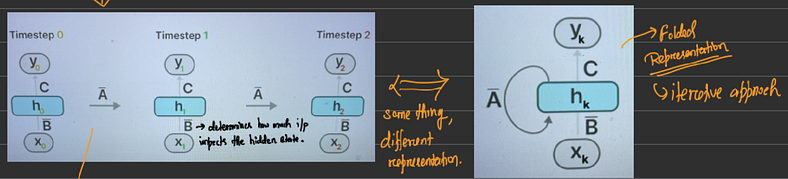
图10(来源:作者图片)
记住一些事情吗!!
是的,你是对的。它的循环神经网络。图 10 显示您可以用 RNN 表示 SSM。如您所知,RNN 在推理中速度很快,因为它们与序列长度线性扩展。但与此同时,我们也遇到了一个问题。也就是说,RNN 不可并行化,因此它们会在训练中消耗大量时间。毕竟,这是 Transformer 在发布后取代 RNN 和 LST 的部分原因。由于 Transformer 是可并行化的,因此可以在 GPU 中进行训练,从而显着减少训练时间。
为了解决这个问题,卷积神经网络 (CNN) 应运而生。使用 CNN,我们可以实现并行化。但怎么???
在下面的图 11 中,如果您展开方程并写入它,您将看到 y(t) 以 A̅、B̅、C、Xt 的形式表示。在方程中,A̅、B̅ 和 C 之间发生了一堆矩阵乘法。通过使用数学,我们可以分离包含矩阵 A̅、B̅ 和 C 的方程和输入矩阵 X。 我们将包含 A̅、B̅ 和 C 的部分命名为矩阵 K。然后我们可以将矩阵 K 与 X 卷积以得到矩阵 Y。
将显示缩放图像

图 11(来源:AI Coffee Break with Letitia 的视频)
通过这样做,我们一次并行获得了 Y 的所有输出。
现在你知道了,聪明的研究人员是如何利用两全其美(RNN 和 CNN)来制作一个计算高效的系统。它使用 RNN 进行推理,使用 CNN 进行训练。该模型称为线性状态空间层 (LSSL)。
但还是有一点小问题!
理想情况下,矩阵 A 是 SSM 中非常强大的部分,因为它包含有关先前状态和隐藏状态的信息。但它只捕获了以前的状态。因此,为了捕获远程依赖关系,SSM 使用 HiPPO(高阶多项式投影仪运算符)。见图12~
将显示缩放图像
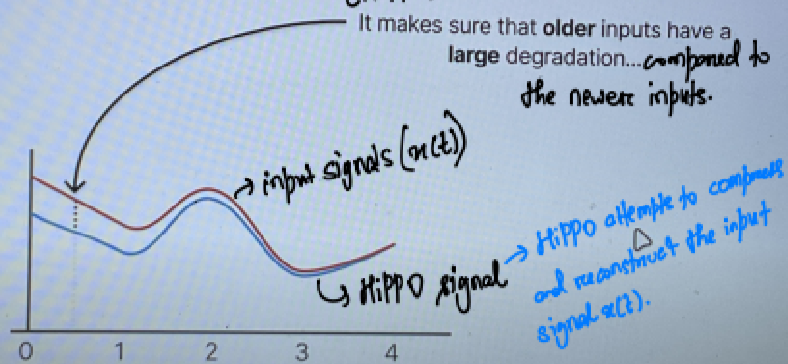
图12(来源:Maarten Grootendorst的插图)
HiPPO 确保 Model 不会从一开始就忘记一切。
总结我们迄今为止所学到的知识,我们了解了 SSM、它们的推理和训练模式表示(RNN、CNN)和 HiPPO。这些组件组合形成结构化状态空间序列模型 (S4),其中“结构化”是指实现高效计算的特定参数化。S4 被认为是处理长序列的最佳模型之一。
这个 S4 与硬件感知算法(HAA 超出了本博客的范围。有关详细信息,您可以参考 Mamba 论文)称为 S6。
S6 是曼巴街区的基础区块。
顾名思义,这个曼巴块就是 MedMamba 的核心!!
二维选择性扫描 (SS2D)
该方法在 Vision Mamba (VMamba) 论文中提出。我们之前看到,Mamba 使用 S6 模型进行自然语言处理 (NLP) 任务。SS2D继承了这种选择性扫描空间状态序列模型(S6),并解决了S6中的“方向敏感”问题。现在这个“方向敏感”问题是什么?
在计算机视觉中,我们处理 2D 或 3D 图像/矢量。我们需要执行 2D 平面遍历来提取上下文信息。但我们使用 Mamba (S6) 在 NLP 中执行一维阵列扫描。所以为了缩小“一维阵列扫描”和“二维平面遍历”之间的差距,那就是解决这个“方向敏感”问题,我们使用了SS2D。
2D选择性扫描(SS2D)引入了交叉扫描模块(CSM)。CSM 有助于将 S6 扩展到视觉数据,而不会影响全局感受野。事实上,它通过确保每个像素可以整合来自所有其他位置的信息来增强感受野。但如何呢?
CSM 采用 4 向扫描策略,即从一个角落扫描到另一个角落四次。将所有特征图扫描到相反的位置会导致图像特征图的空间域遍历,从而确保特征图中的每个像素在不同方向上整合来自所有其他位置的信息。这创建了一个全局感受野,这对于计算机视觉任务至关重要,同时保持线性计算复杂性(而不是注意力机制的二次复杂度)。
这个跨扫描模块过程包括 3 个步骤 ~
- 扫描扩展作
- S6 块
- 扫描合并作
将显示缩放图像
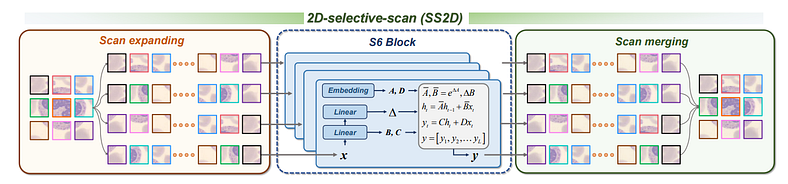
图13(来源:MedMamba官方论文)
扫描扩展作→此作将“2D 特征图/图像”转换为四个“1D 序列”,每个序列代表不同的扫描方向。四个扫描方向是~
- 从左上到右下
- 右下角到左上角
- 从右上到左下
- 左下到右上
让我们用一个虚拟示例来理解上面的作~
[1 2 3]
[4 5 6] ⟹ 一个二维矩阵
[7 8 9]
- [3 6 9 2 5 8 1 4 7] → 右上到左下
- [7 4 1 8 5 2 9 6 3] →左下到右上
- [1 2 3 4 5 6 7 8 9] → 左上到右下
- [9 8 7 6 5 4 3 2 1] → 右下到左上
为什么这 4 个方向有用?
每个扫描方向捕获不同的空间关系。图像中心的像素将通过不同的方向路径接收来自所有其他部分的信息。四个方向还确保不遗漏任何空间关系。
对于具有多个通道(C > 1)的特征图,扫描扩展作独立应用于每个通道(4 个序列/通道),因此总共 4 个 C 序列。(每个序列的长度为 H x W)
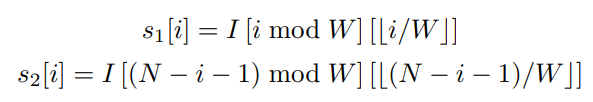
(来源:MedMamba 官方文件)
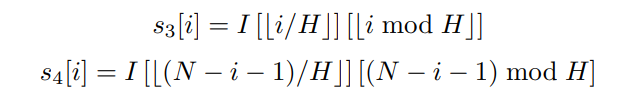
(来源:MedMamba 官方文件)
其中 N = H x W ;i = [0,N-1]
扫描后,4 个序列中的每一个都通过相同的 S6 块架构并行处理,但每个序列都保持自己的处理路径。

图14(来源:)
S6 块 → 此块处理 2D 输入图像的所有扩展的 1D 标记。这是使用 MedMamba 的 Mamba 的部分。处理后,它将反向作应用于上下文标记序列~
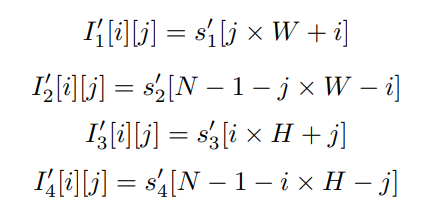
(来源:MedMamba 官方文件)
式中,I1′ 、 I2′ 、 I3' 、 I4' ∈ R^(H×W×C)表示I的展开变换特征图。
扫描合并作 → 顾名思义,此作与扫描扩展作完全相反。它将 S6 块的上下文 1D 令牌输出序列合并回 2D 图像,使其看起来像 2D 输出图像。
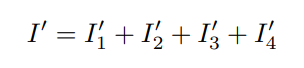
(来源:MedMamba 官方文件)
因此,通过这种方式,扫描合并作将四个处理后的序列组合(而不是简单地添加)回与输入空间维度相同的 2D 特征图,从而保留集成的方向信息。
将显示缩放图像

图15(来源:作者图片)
需要注意的重要一点是,SS2D模块继承了选择性扫描机制的线性复杂度,同时实现了全局感受野,这是相对于具有二次复杂度的注意力机制的关键优势。
SS-Conv-SSM 模块
现在我们知道了什么是 SS2D,我们可以进一步了解模型的层次结构。如图所示的SS-Conv-SSM块有2个分支~
- 卷积分支
- SSM分公司
将显示缩放图像
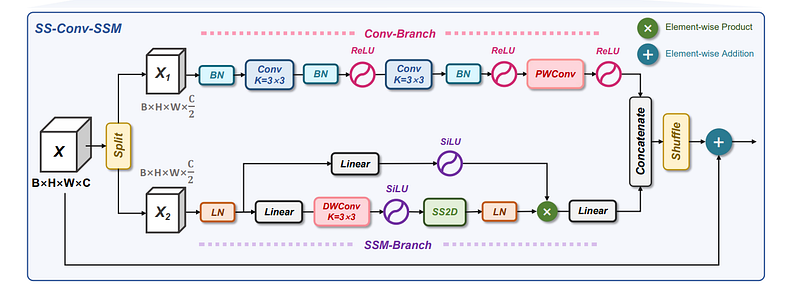
图16(来源:MedMamba官方论文)
图 16 是不言自明的。需要注意的是,我们使用 f(x) 函数来拆分通道,使用 g(x) 函数进行随机播放。相反,由于我们使用 f(x) 进行拆分,因此我们使用 f^-1(x) 进行连接。BN 代表批量归一化,LN 代表层归一化。DWConv 和 PWConv 分别是 DepthWise 和 PointWise 卷积,以提高计算效率。
设 X 为输入变量。在 Split 块之后,X 通过 f(X) 函数分解为 X1 用于 Conv-Branch,X2 用于 SSM-Branch。 此处的 Permute(x1) 将张量维度从 H × W × C/2 重新排列到 C/2 × H × W,以匹配卷积运算的预期输入格式,其中通道在前。
Conv-Branch 的建模过程 ~
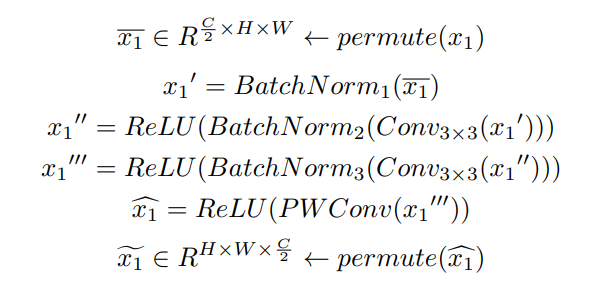
(来源:MedMamba 官方文件)
同时,SSM-Branch 的建模过程 ~

(来源:MedMamba 官方文件)
SS-Conv-SSM 分支的最终输出可以概括为 ~
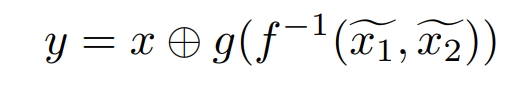
(来源:MedMamba 官方文件)
式中,f^(-1)表示沿信道维度将output-x1和output-x2组合在一起的串联运算,g(x)是促进不同信道组之间信息交换的信道洗牌函数,输入x作为添加到最终输出的残差连接,使y成为一个SS-Conv-SSM块的最终输出。
通道洗牌作 g(x) 对于实现两个分支(Conv 和 SSM)之间的信息交换至关重要,确保在一个分支中学习到的特征可以影响另一个分支,从而提高混合架构的整体表示能力。
在此 SS-Conv-SSM 架构中需要注意的一件事是在 SSM-Branch 中使用层规范化,在 Conv-Branch 中使用批量规范化。为什么?
因为批量归一化更适合 CNN,而层归一化更适合 RNN、LST 等。CNN 旨在检测特征,而不管其空间位置如何。批量归一化完全符合这一原则,因为它在保留空间关系的同时跨批次维度进行归一化。而 RNN、LSTM 和 SSM 一次处理一个元素的序列,这使得批量统计的意义降低。序列中的每个时间步长都有不同的语义内容,因此跨不同序列中的不同位置进行规范化不会保留顺序结构。批量归一化会不恰当地混合不同序列位置和样品之间的统计数据。所以我们改用层归一化。
至此,我们完成了 MedMamba 架构的先决条件。
梅德曼巴
是的!等待终于结束了!!现在我们终于可以深入了解 MedMamba 架构了。见图17。MedMamba 追随 ViT 的脚步,具有相同的输入处理。因此,本文用于训练模型的默认输入维度为 224 x 224 x 3。
将显示缩放图像
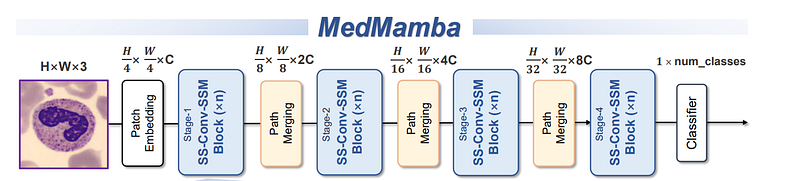
图17(来源:MedMamba官方论文)
从架构上我们可以看到 4 个重要的块~
- 补丁嵌入 (Patch-E)
- SS-Conv-SSM 模块
- 路径合并 (Patch-M)
- 分类
MedMamba 的制造商训练了该模型的 3 种变体:MedMamba-Tiny、MedMamba-Small、MedMamba-Base,为用户提供灵活性。
将显示缩放图像
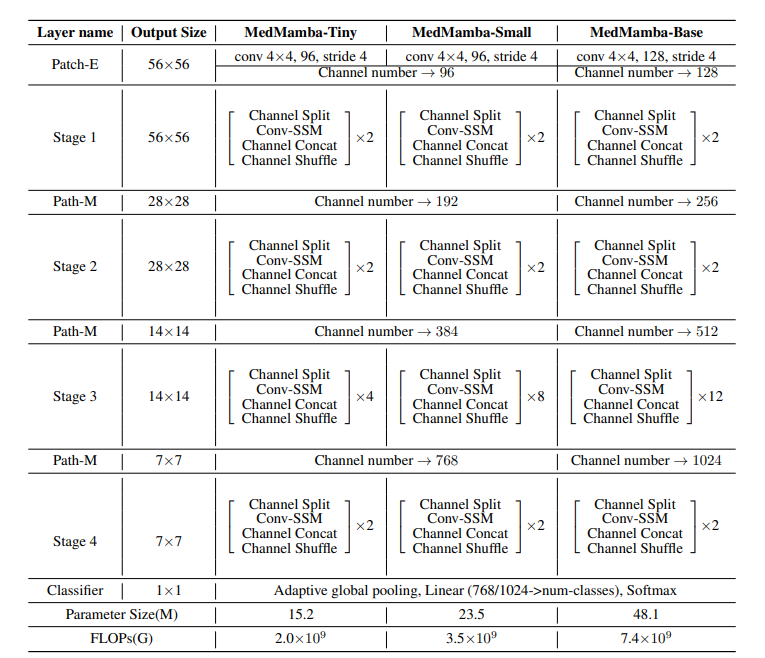
表1(来源:MedMamba官方论文)
1. 补丁嵌入(Patch-E)~
从图 17 中可以看出,Patch Embedding Block 将 H x W x 3 图像作为输入,并输出 H/4 x W/4 x C。为什么 MedMamba 使用它?
因为 MedMamba 深受 Vision Transformer (ViT) 架构的启发。ViT 在处理图像之前将图像分解成补丁,因此 MedMamba 也使用相同的方法。这是有道理的,因为两者都依赖于其 NLP 设计的核心部分来执行计算机视觉任务。
这样,MedMamba 将图像划分为大小为 4 x 4 的不重叠补丁。因此,尺寸为 H x W x 3 的输入图像的大小变为 H/4 x W/4 x C。图像的通道尺寸为“C”。Patch-E 借助 Stride 4 和 Zero Padding 进行 4 x 4 卷积来完成此过程。 MedMamba Tiny and Small 的 C 值为 96,而 Base 的 C 值为 128。MedMamba 的默认输入尺寸设置为 224 × 224 × 3,遵循大多数视觉模型中使用的标准输入尺寸。所以按照卷积的公式~
将显示缩放图像
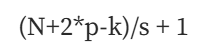
(图源:图片由作者提供)
其中,p = 填充,s = 步幅,n = 图像的暗淡,k = 滤波器的暗淡
对于我们的例子,我们得到 (224 + 2*0–4)/4 + 1= 55 + 1 = 56
因此,我们得到的输出为 56 * 56 * C(其中 C = 96 表示 Tiny、Small,C = 128 表示 Base),如表 1 所述。
2. SS-Conv-SSM 块 ~
我们在上一节中详细研究了这一点。要记住的重要一点是输出与输入大小相同。SS-Conv-SSM 块 (*n) 是指堆叠的“n”个块,用于处理特征而不改变其尺寸。不同阶段的SS-Conv-SSM块数(n)为:MedMamba-Tiny:(2,2,4,2)、MedMamba-Small:(2,2,8,2)和MedMamba-Base:(2,2,12,2)。请注意,第 3 阶段有更多的块,可以以较低的分辨率捕获更复杂的特征。用户可以根据任务的复杂性选择模型的复杂性。
3. 补丁合并 (Patch-M) ~
这是 MedMamba 用来对之前 SS-Conv-SSM 块的输出进行下采样的块。
将显示缩放图像

图18(来源:作者图片)
它减小了补丁的尺寸,增加了通道。Patch-M 在空间维度上组合了相邻的 2 x 2 Patch,同时将通道尺寸加倍。由于它将所有相邻的 2 x 2 通道组合为 1 x 1,因此在技术上将尺寸减小了一半。H x W 变为 H/2 x W/2。因此,为了保留信息内容,通道 (C) 加倍。怎么做?
当您将 2 x 2 色片转换为 1 x 1 色片时,您将连接所有像素形成 4*C 通道。这个 4*C 通道计算起来太多了,所以为了在保留信息内容的同时减少指数级的通道增长,我们需要将 4*C 通道减少到 2*C 通道。我们通过线性投影矩阵来做到这一点。
让我们借助一个例子来理解一下~
有一个 2 x 2 x 1 矩阵 ~

(图源:图片由作者提供)
通道串联后,得到一个维度为 1 x 1 x 4 ~

(图源:图片由作者提供)
现在,要将此 4*C 通道减少到 2*C 通道,请执行线性投影矩阵。在这个例子中 ~
将显示缩放图像
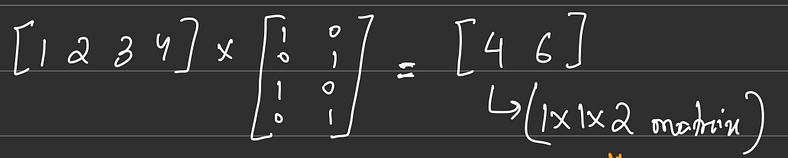
(图源:图片由作者提供)
如您所见,我们最终从 1 x 1 x 2 矩阵中得到了 1 x 1 x 4 矩阵。此示例解释了 Patch Merger 的工作,即将尺寸为 2 x 2 x 1 的 Patch 转换为尺寸为 1 x 1 x 2。
4.分类器~
Classifier 块包含“自适应池化层”和“线性层”。特别是自适应全球平均池化。
从表1中可以看出,第4阶段后的输出为7 x 7 x C(其中,Tiny、Small和Base分别为C = 768,768,1024)。
将显示缩放图像

(图源:图片由作者提供)
然后将这个1 x 1 x C矩阵压平,穿过线性致密层~
将显示缩放图像

(图源:图片由作者提供)
x = 类数
最后,我们应用 Softmax 来预测类/输出~

(图源:图片由作者提供)
所以,这就是 MedMamba 架构的性能。太迷人了,不是吗?
回顾~
瞧!终于达到模型的输出感觉真好,但同时也可能有点不知所措。回顾一下我们所做的工作,我们将回顾我们的进展。
我们刚刚了解了 MedMamba 架构。它由 4 个主要组件组成:补丁嵌入 (Patch-E)、跨四个阶段的分层堆叠 SS-Conv-SSM 块、用于向下采样的补丁合并 (Patch-M) 层,以及具有自适应全局池化的最终分类器。给出 224 x 224 x 3(默认情况下)图像作为输入,我们得到预测的类作为输出。在这个 MedMamba 架构中,我们以 SS-Conv-SSM 块作为主块。SS-Conv-SSM 块采用双分支架构,其中 Conv-Branch 使用卷积运算提取局部空间特征,而 SSM-Branch 通过选择性状态空间建模捕获全局上下文和远程依赖关系。在SS-Conv-SSM块的SSM分支中,有一个名为SS2D的块,它通过处理来自四个方向扫描模式的特征的交叉扫描模块(CSM)将曼巴的选择性状态空间模型实现为二维视觉数据。
MedMamba 的核心创新在于其混合架构,将 CNN 的局部特征提取能力与 SSM 的全局上下文建模和线性计算复杂性协同结合。利用 RNN 的快速推理 (SSM) 和 CNN 的训练并行性,Mamba 系列架构在 NLP 和计算机视觉领域的性能和效率方面不断发展。
最后的话~
恭喜您通过了对 MedMamba 的全面深入研究!如果您还在这里并且在我们的数学冒险中没有打瞌睡,那么您值得虚拟竖起大拇指!虽然我努力以易于理解的方式揭开 MedMamba 的核心概念和复杂工作原理的神秘面纱,但这种探索只是触及了这个迷人架构的表面。
在原始的 MedMamba 和 Mamba 研究论文中,有一个引人注目的细节、细致入微的组件和技术见解的宝库等待发现。该博客可作为您的智力跳板——为您提供必要的基础知识和数学框架,以便自信地浏览完整论文并向充满活力的研究社区贡献您自己的见解。
这本综合指南从几个特殊来源汲取灵感和知识:
- Albert Gu 和 Tri Dao 的开创性曼巴论文。
- Yubiao Yue 和 Zhenzhang Li 的创新 MedMamba 论文。
- Maarten Grootendorst 和 AI Coffee Break with Letitia 的启发性视频内容。
- 我的个人学习笔记是在我自己的学习过程中用这个非凡的模型编写的。
特别表彰我尊敬的导师 Rajesh Kumar Tripathy 博士(BITS Pilani 海得拉巴校区副教授),他向我介绍了 MedMamba 论文,作为他前沿研究工作的一部分。他的指导在这次探索中非常宝贵。
我以真正的热情和我目前的理解来制作这个博客。如果您发现任何概念错误或误解,我热忱欢迎建设性的反馈和更正——毕竟,学习是一个协作之旅!请原谅我在整篇文章中偶尔使用“我们”和“我们”;我采用了教学视角,尽管完全归功于开创这些创新的杰出研究人员。
感谢您加入我的首届博客冒险——您的读者群对我来说确实意味着整个世界!
再见,下一场见!

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 0
0 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)