
自然语言处理(一):自然语言处理与文本分类简介
自然语言处理发展历程从规则驱动到数据驱动的一个过程1990年以前,基于规则的方法基于规则的方法1990-2019,基于统计学的方法离散表示线性模型2012——,基于深度学习的方法神经网络分布式表示非线性模型自然语言处理的主要研究方向文本分类概述在NLP(自然语言处理)的很多子任务中,有绝大部分场景可以归结为文本分类,比如:情感分析领域识别意图识别文本分类的定义在给定的分类体系中,将文本分到指定的某
·
自然语言处理发展历程
从规则驱动到数据驱动的一个过程
- 1990年以前,基于规则的方法
- 基于规则的方法
- 1990-2019,基于统计学的方法
- 离散表示
- 线性模型
- 2012——,基于深度学习的方法
- 神经网络
- 分布式表示
- 非线性模型
自然语言处理的主要研究方向
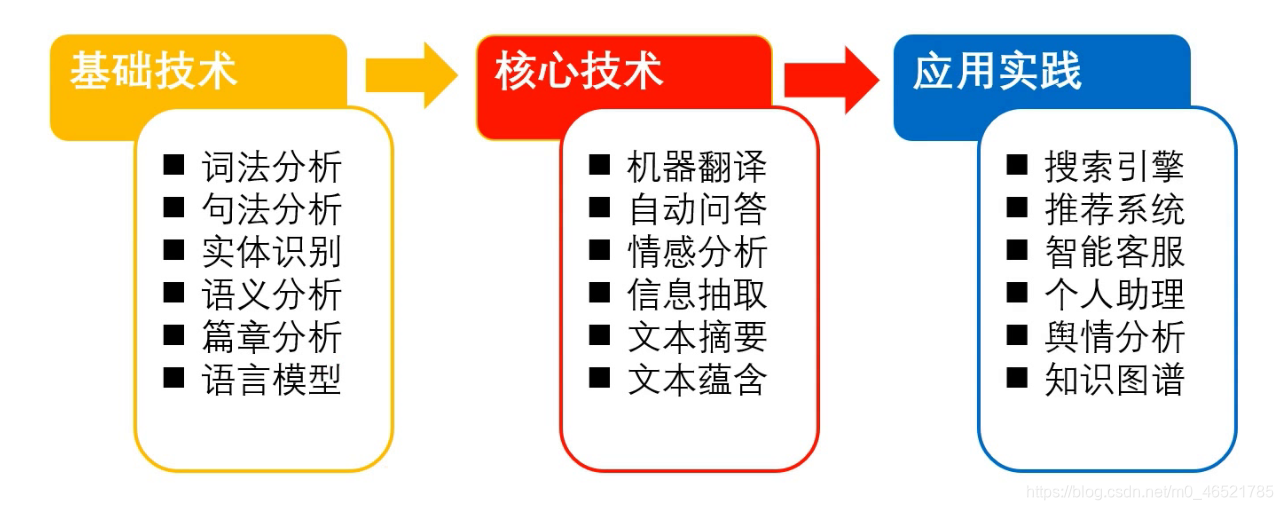
文本分类概述
在NLP(自然语言处理)的很多子任务中,有绝大部分场景可以归结为文本分类,比如:
- 情感分析
- 领域识别
- 意图识别
文本分类的定义
在给定的分类体系中,将文本分到指定的某个或某几个类别中,分类对象分为短文本(句子/标题/商品评论)、长文本(文章)
分类体系一般由人工构造
- 新闻分类:政治、体育、军事、社会
- 情感分类:正能量、负能量
- 微博评论分类:好评、中评、差评
分类模式:
- binary:二分类问题,属于或不属于,positive or negative
- multi-class:多类问题
- multi-label:
多标签问题,一个文本可以属于多类。多标签问题是文本分类的一大难点。
文本分类的方法
人工方法:
- 基于规则的特征匹配,容易理解(足球、联赛->体育)
- 依赖专家系统,不同任务需要构建不同规则,费时费力
- 准确率不高
机器学习方法:
- 特征工程+算法(Naive Bayes / SVM / LR/KNN)
深度学习方法:
- 词向量+模
- FastText
- TextCNN
- TextRNN
- TextRCNN
- DPCNN
- BERT
文本分类的流程
文本预处理:
- 文本去噪
- 文本分词(有必要需要去训练分词器)
- 去停用词
- 文本还原(同义词合并啊,do did dose合一啊)
- 文本消歧
- 文本替换
特征提取:
- 词频特征
- 次性特征
- 语法特征
- 主题特征
- N-Gram
- TFIDF特征
文本表示:
- 词袋模型
- One-Hot
- word2vec
- Glove
- EMLO
- Bert
分类模型:
- 机器学习
- 深度学习
- CNN
- RNN
- Attention
- GNN

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 2
2 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)