
Python大数据之PySpark(三)使用Python语言开发Spark程序代码_windows spark python(3)
函数式编程既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新需要这份系统化资料的朋友,可以戳这里获取片转存中…(img-dRUO9g9X-1715332964327)][外链图片转存中…(img-

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
需求:[(‘Spark’, 2), (‘Flink’, 1), (‘hello’, 3), (‘you’, 1), (‘me’, 1), (‘she’, 1)]
排序:[ (‘hello’, 3),(‘Spark’, 2),]
共识:Spark核心或灵魂是rdd,spark的所有操作都是基于rdd的操作
代码:
# -\*- coding: utf-8 -\*- # Program function: 针对于value单词统计计数的排序 # 1-思考:sparkconf和sparkcontext从哪里导保 # 2-如何理解算子?Spark中算子有2种, # 一种称之为Transformation算子(flatMapRDD-mapRDD-reduceBykeyRDD), # 一种称之为Action算子(输出到控制台,或文件系统或hdfs),比如collect或saveAsTextFile都是Action算子 from pyspark import SparkConf, SparkContext if __name__ == '\_\_main\_\_': # 1 - 首先创建SparkContext上下文环境 conf = SparkConf().setAppName("FirstSpark").setMaster("local[\*]") sc = SparkContext(conf=conf) sc.setLogLevel("WARN") # 日志输出级别 # 2 - 从外部文件数据源读取数据 fileRDD = sc.textFile("D:\BigData\PyWorkspace\Bigdata25-pyspark\_3.1.2\PySpark-SparkBase\_3.1.2\data\words.txt") # print(type(fileRDD))#<class 'pyspark.rdd.RDD'> # all the data is loaded into the driver's memory. # print(fileRDD.collect()) # ['hello you Spark Flink', 'hello me hello she Spark'] # 3 - 执行flatmap执行扁平化操作 flat_mapRDD = fileRDD.flatMap(lambda words: words.split(" ")) # print(type(flat\_mapRDD)) # print(flat\_mapRDD.collect()) # ['hello', 'you', 'Spark', 'Flink', 'hello', 'me', 'hello', 'she', 'Spark'] # # 4 - 执行map转化操作,得到(word, 1) rdd_mapRDD = flat_mapRDD.map(lambda word: (word, 1)) # print(type(rdd\_mapRDD))#<class 'pyspark.rdd.PipelinedRDD'> # print(rdd\_mapRDD.collect()) # [('hello', 1), ('you', 1), ('Spark', 1), ('Flink', 1), ('hello', 1), ('me', 1), ('hello', 1), ('she', 1), ('Spark', 1)] # 5 - reduceByKey将相同Key的Value数据累加操作 resultRDD = rdd_mapRDD.reduceByKey(lambda x, y: x + y) # print(type(resultRDD)) print(resultRDD.collect()) # [('Spark', 2), ('Flink', 1), ('hello', 3), ('you', 1), ('me', 1), ('she', 1)] # 6 针对于value单词统计计数的排序 print("==============================sortBY=============================") print(resultRDD.sortBy(lambda x: x[1], ascending=False).take(3)) # [('hello', 3), ('Spark', 2), ('Flink', 1)] print(resultRDD.sortBy(lambda x: x[1], ascending=False).top(3, lambda x: x[1])) print("==============================sortBykey=============================") print(resultRDD.map(lambda x: (x[1], x[0])).collect()) # [(2, 'Spark'), (1, 'Flink'), (3, 'hello'), (1, 'you'), (1, 'me'), (1, 'she')] print(resultRDD.map(lambda x: (x[1], x[0])).sortByKey(False).take(3)) #[(3, 'hello'), (2, 'Spark'), (1, 'Flink')] # 7-停止SparkContext sc.stop() # Shut down the SparkContext.
- sortBy
- sortByKey操作
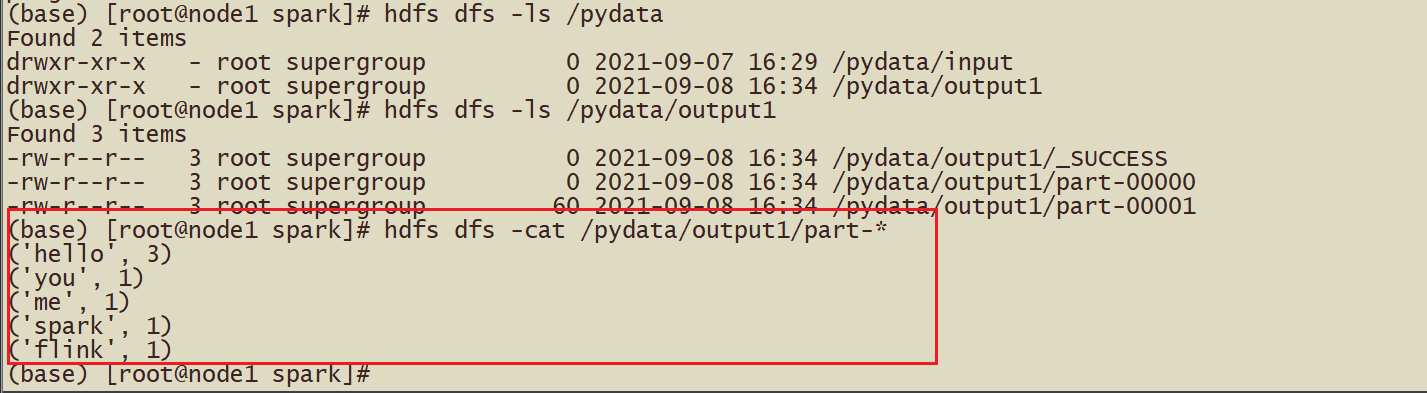
从HDFS读取数据
# -\*- coding: utf-8 -\*- # Program function: 从HDFS读取文件 from pyspark import SparkConf, SparkContext import time if __name__ == '\_\_main\_\_': # 1 - 首先创建SparkContext上下文环境 conf = SparkConf().setAppName("FromHDFS").setMaster("local[\*]") sc = SparkContext(conf=conf) sc.setLogLevel("WARN") # 日志输出级别 # 2 - 从外部文件数据源读取数据 fileRDD = sc.textFile("hdfs://node1:9820/pydata/input/hello.txt") # ['hello you Spark Flink', 'hello me hello she Spark'] # 3 - 执行flatmap执行扁平化操作 flat_mapRDD = fileRDD.flatMap(lambda words: words.split(" ")) # ['hello', 'you', 'Spark', 'Flink', 'hello', 'me', 'hello', 'she', 'Spark'] # # 4 - 执行map转化操作,得到(word, 1) rdd_mapRDD = flat_mapRDD.map(lambda word: (word, 1)) # [('hello', 1), ('you', 1), ('Spark', 1), ('Flink', 1), ('hello', 1), ('me', 1), ('hello', 1), ('she', 1), ('Spark', 1)] # 5 - reduceByKey将相同Key的Value数据累加操作 resultRDD = rdd_mapRDD.reduceByKey(lambda x, y: x + y) # print(type(resultRDD)) print(resultRDD.collect()) # 休息几分钟 time.sleep(600) # 7-停止SparkContext sc.stop() # Shut down the SparkContext.
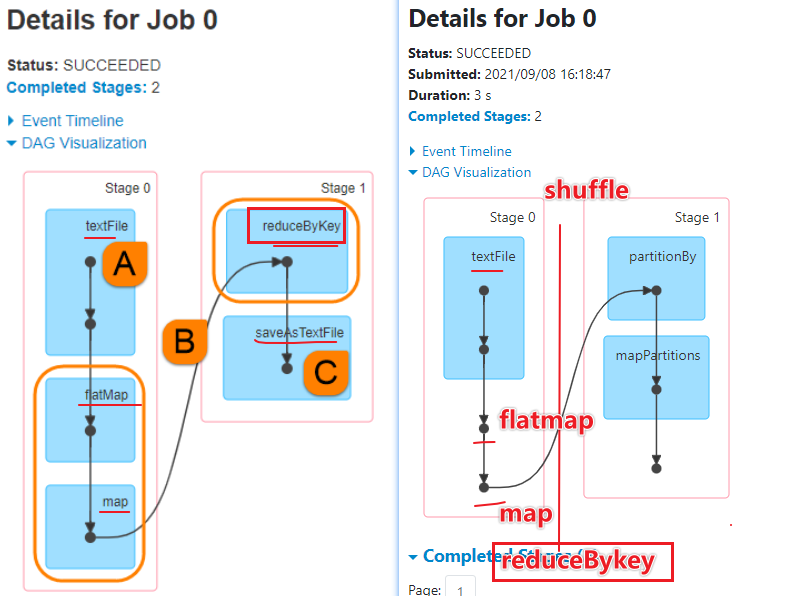
提交代码到集群执行
- 关键:sys.argv[1],
- 代码:
# -*- coding: utf-8 -*- # Program function: 提交任务执行 import sys from pyspark import SparkConf, SparkContext if __name__ == '__main__': # 1 - 首先创建SparkContext上下文环境 conf = SparkConf().setAppName("FromHDFS").setMaster("local[*]") sc = SparkContext(conf=conf) sc.setLogLevel("WARN") # 日志输出级别 # 2 - 从外部文件数据源读取数据 # hdfs://node1:9820/pydata/input/hello.txt fileRDD = sc.textFile(sys.argv[1]) # ['hello you Spark Flink', 'hello me hello she Spark'] # 3 - 执行flatmap执行扁平化操作 flat_mapRDD = fileRDD.flatMap(lambda words: words.split(" ")) # ['hello', 'you', 'Spark', 'Flink', 'hello', 'me', 'hello', 'she', 'Spark'] # # 4 - 执行map转化操作,得到(word, 1) rdd_mapRDD = flat_mapRDD.map(lambda word: (word, 1)) # [('hello', 1), ('you', 1), ('Spark', 1), ('Flink', 1), ('hello', 1), ('me', 1), ('hello', 1), ('she', 1), ('Spark', 1)] # 5 - reduceByKey将相同Key的Value数据累加操作 resultRDD = rdd_mapRDD.reduceByKey(lambda x, y: x + y) # print(type(resultRDD)) resultRDD.saveAsTextFile(sys.argv[2]) # 7-停止SparkContext sc.stop() # Shut down the SparkContext.
- 结果:
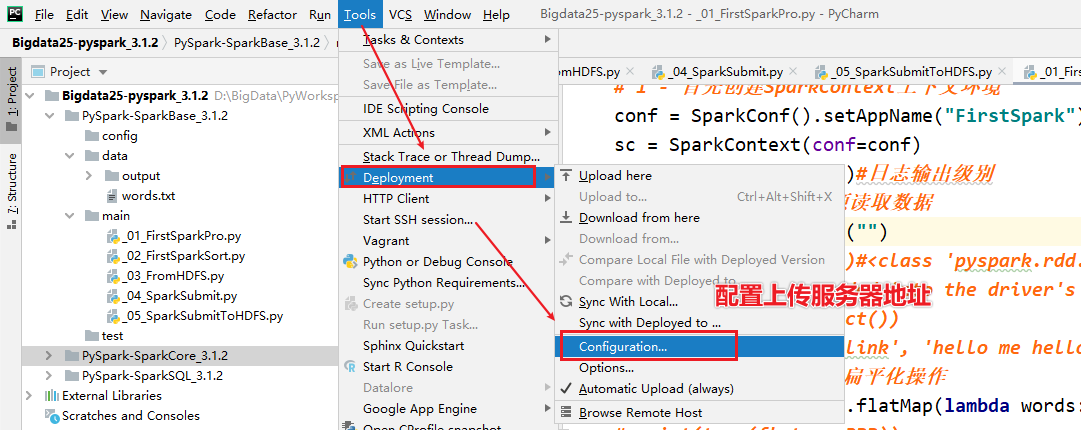
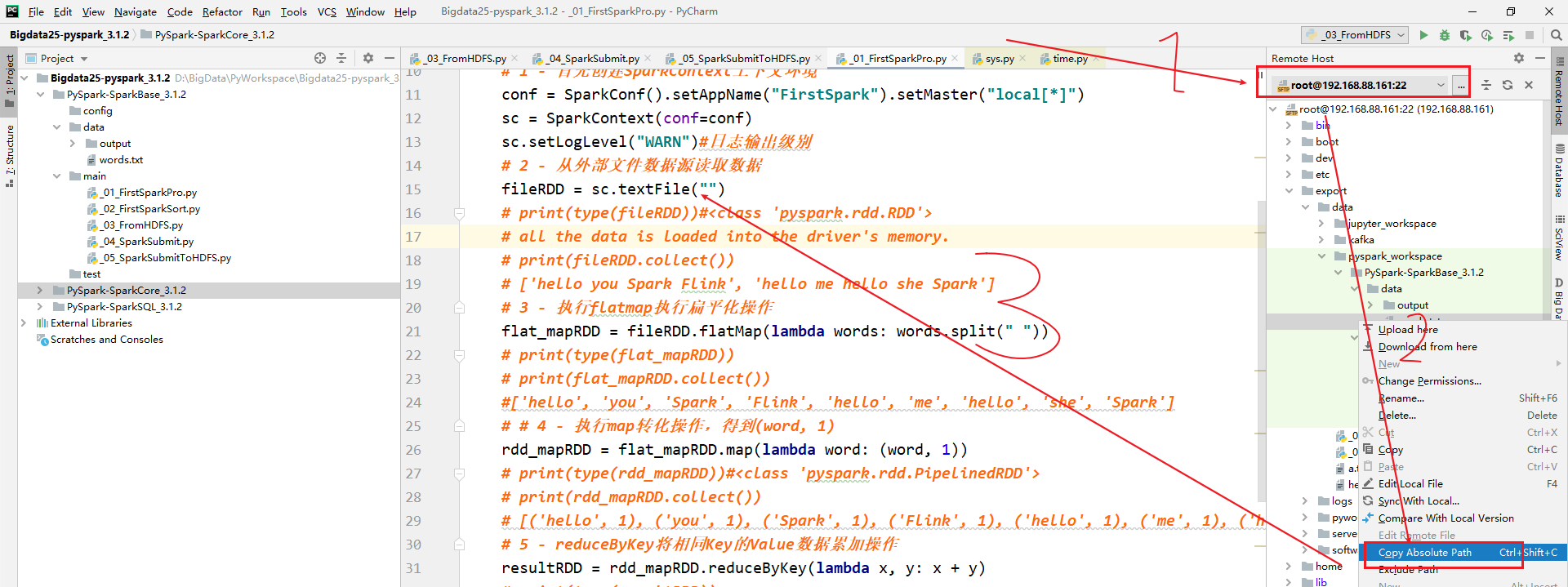
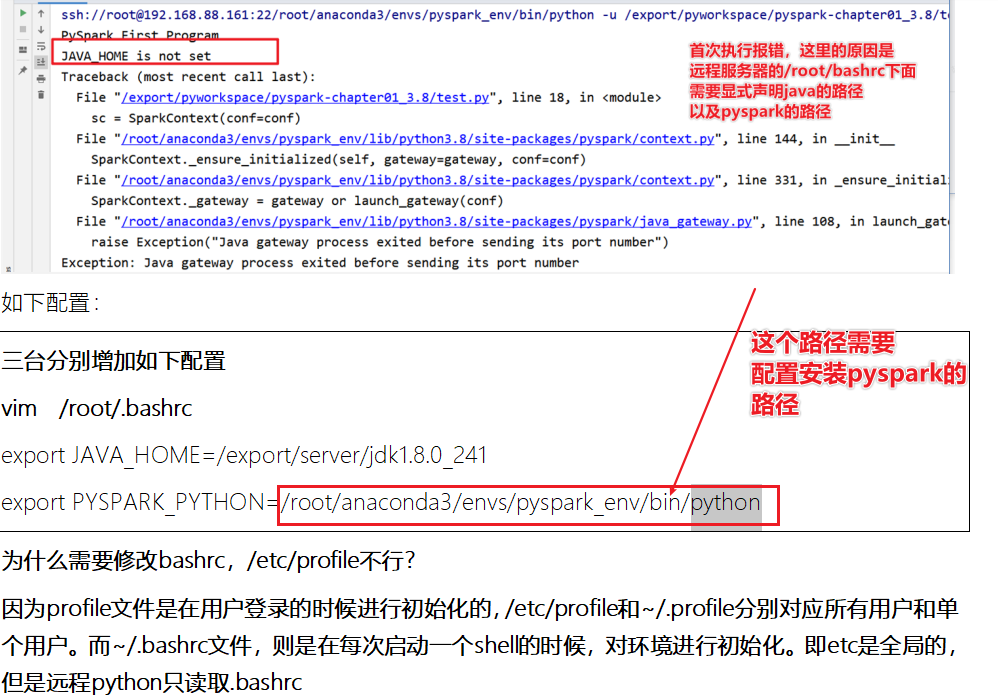
[掌握-扩展阅读]远程PySpark环境配置
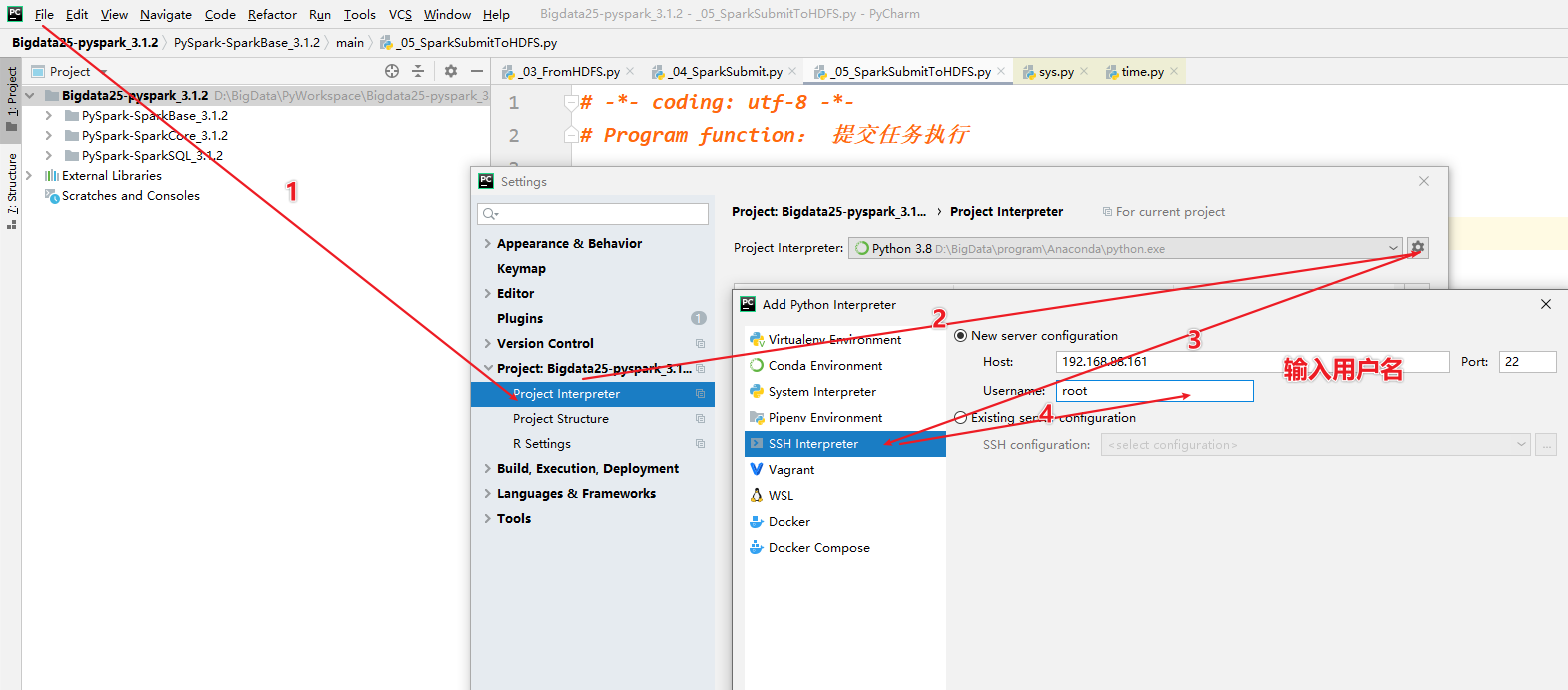
- 需求:需要将PyCharm连接服务器,同步本地写的代码到服务器上,使用服务器上的Python解析器执行
- 步骤:
- 1-准备PyCharm的连接
- 2-需要了解服务器的地址,端口号,用户名,密码
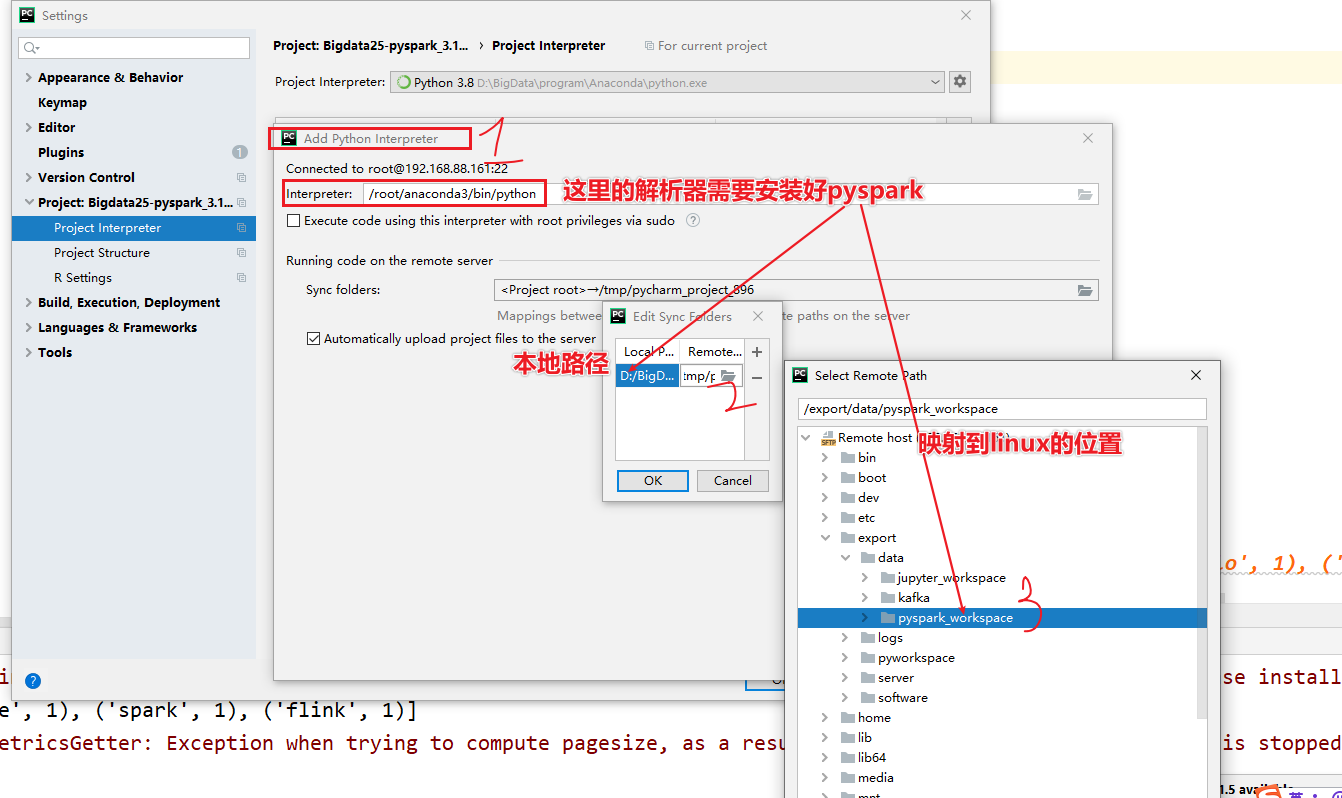
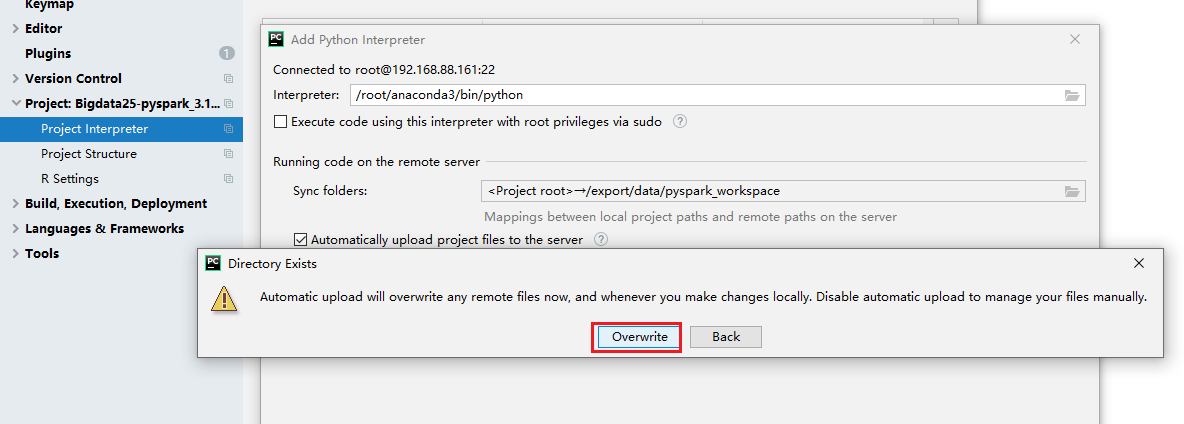
- 设置自动的上传,如果不太好使,重启pycharm
- 3-pycharm读取的文件都需要上传到linux中,复制相对路径
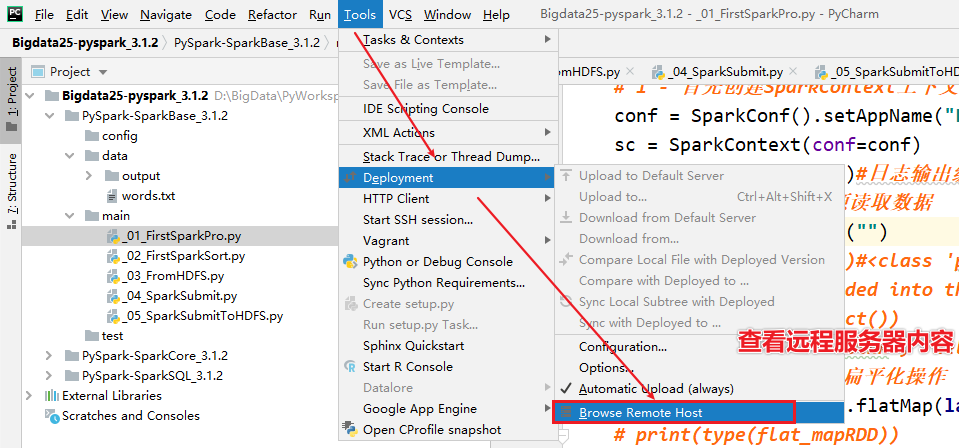
- 4-执行代码在远程服务器上
- 5-执行代码
# -*- coding: utf-8 -*- # Program function: Spark的第一个程序 # 1-思考:sparkconf和sparkcontext从哪里导保 # 2-如何理解算子?Spark中算子有2种, # 一种称之为Transformation算子(flatMapRDD-mapRDD-reduceBykeyRDD), # 一种称之为Action算子(输出到控制台,或文件系统或hdfs),比如collect或saveAsTextFile都是Action算子 from pyspark import SparkConf, SparkContext if __name__ == '__main__': # 1 - 首先创建SparkContext上下文环境 conf = SparkConf().setAppName("FirstSpark").setMaster("local[*]") sc = SparkContext(conf=conf) sc.setLogLevel("WARN") # 日志输出级别 # 2 - 从外部文件数据源读取数据 fileRDD = sc.textFile("/export/data/pyspark_workspace/PySpark-SparkBase_3.1.2/data/words.txt") # fileRDD = sc.parallelize(["hello you", "hello me", "hello spark"]) # 3 - 执行flatmap执行扁平化操作 flat_mapRDD = fileRDD.flatMap(lambda words: words.split(" ")) # print(type(flat_mapRDD)) # print(flat_mapRDD.collect()) # ['hello', 'you', 'Spark', 'Flink', 'hello', 'me', 'hello', 'she', 'Spark'] # # 4 - 执行map转化操作,得到(word, 1) rdd_mapRDD = flat_mapRDD.map(lambda word: (word, 1)) # print(type(rdd_mapRDD))#<class 'pyspark.rdd.PipelinedRDD'> # print(rdd_mapRDD.collect()) # [('hello', 1), ('you', 1), ('Spark', 1), ('Flink', 1), ('hello', 1), ('me', 1), ('hello', 1), ('she', 1), ('Spark', 1)] # 5 - reduceByKey将相同Key的Value数据累加操作 resultRDD = rdd_mapRDD.reduceByKey(lambda x, y: x + y) # print(type(resultRDD)) print(resultRDD.collect()) # [('Spark', 2), ('Flink', 1), ('hello', 3), ('you', 1), ('me', 1), ('she', 1)] # 6 - 将结果输出到文件系统或打印 # resultRDD.saveAsTextFile("D:\BigData\PyWorkspace\Bigdata25-pyspark_3.1.2\PySpark-SparkBase_3.1.2\data\output\wordsAdd") # 7-停止SparkContext sc.stop() # Shut down the SparkContext.
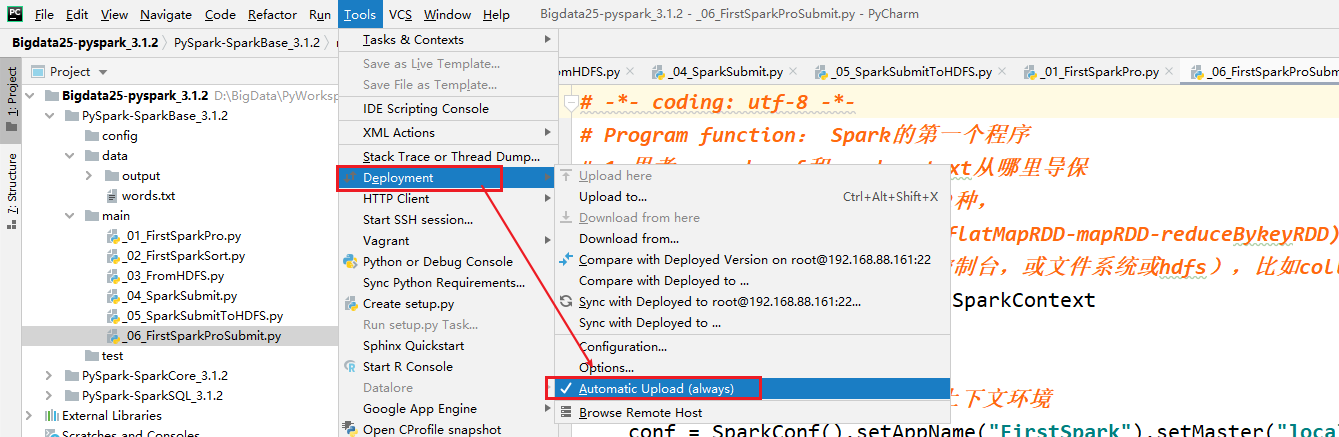
- 切记忘记上传python的文件,直接执行
- 注意1:自动上传设置
- 注意2:增加如何使用standalone和HA的方式提交代码执行
- 但是需要注意,尽可能使用hdfs的文件,不要使用单机版本的文件,因为standalone是集群模式
# -*- coding: utf-8 -*- # Program function: Spark的第一个程序 # 1-思考:sparkconf和sparkcontext从哪里导保 # 2-如何理解算子?Spark中算子有2种, # 一种称之为Transformation算子(flatMapRDD-mapRDD-reduceBykeyRDD), # 一种称之为Action算子(输出到控制台,或文件系统或hdfs),比如collect或saveAsTextFile都是Action算子 >from pyspark import SparkConf, SparkContext > >if __name__ == '__main__': > ># 1 - 首先创建SparkContext上下文环境 > >conf = SparkConf().setAppName("FirstSpark").setMaster("spark://node1:7077,node2:7077") >sc = SparkContext(conf=conf) >sc.setLogLevel("WARN") # 日志输出级别 > ># 2 - 从外部文件数据源读取数据 > >fileRDD = sc.textFile("hdfs://node1:9820/pydata/input/hello.txt") > ># fileRDD = sc.parallelize(["hello you", "hello me", "hello spark"]) > ># 3 - 执行flatmap执行扁平化操作 > >flat_mapRDD = fileRDD.flatMap(lambda words: words.split(" ")) > ># print(type(flat_mapRDD)) > ># print(flat_mapRDD.collect()) > ># ['hello', 'you', 'Spark', 'Flink', 'hello', 'me', 'hello', 'she', 'Spark'] > ># # 4 - 执行map转化操作,得到(word, 1) > >rdd_mapRDD = flat_mapRDD.map(lambda word: (word, 1)) > ># print(type(rdd_mapRDD))#<class 'pyspark.rdd.PipelinedRDD'> > ># print(rdd_mapRDD.collect()) > ># [('hello', 1), ('you', 1), ('Spark', 1), ('Flink', 1), ('hello', 1), ('me', 1), ('hello', 1), ('she', 1), ('Spark', 1)] > ># 5 - reduceByKey将相同Key的Value数据累加操作 > >resultRDD = rdd_mapRDD.reduceByKey(lambda x, y: x + y) > ># print(type(resultRDD)) > >print(resultRDD.collect()) > ># [('Spark', 2), ('Flink', 1), ('hello', 3), ('you', 1), ('me', 1), ('she', 1)] > ># 6 - 将结果输出到文件系统或打印 > ># resultRDD.saveAsTextFile("D:\BigData\PyWorkspace\Bigdata25-pyspark_3.1.2\PySpark-SparkBase_3.1.2\data\output\wordsAdd") > ># 7-停止SparkContext > >sc.stop() # Shut down the SparkContext.
总结
- 函数式编程
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
片转存中…(img-dRUO9g9X-1715332964327)]
[外链图片转存中…(img-jLQmYxnC-1715332964328)]
[外链图片转存中…(img-xE7N3sBV-1715332964328)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)