
自然语言处理nlp--9.情感分析(一般框架、公开数据集,含LSTM/SnowNLP代码示例)
情感分析是通过计算技术对带有情感色彩的主观性文本进行分析和推理的过程,旨在识别用户的态度和观点。其核心任务包括情感信息抽取和情感分类。该领域发展得益于公开评测如TREC、NTCIR和丰富的数据如Cornell、MPQA和情感词典如GI、HowNet。技术上,情感分析方法从早期的基于规则和词典的方法发展到如今的机器学习如LSTM、SVM、预训练语言模型,其中SnowNLP等库提供了开箱即用的解决方案
写在前面
互联网(如博客和论坛)上产生了大量的用户参与的、对于诸如人物、事件、产品等有价值的评论信息。这些评论信息表达了人们的各种情感色彩和情感倾向性,如喜、怒、哀、乐和批评、赞扬等。
潜在的用户可以通过浏览这些主观色彩的评论来了解大众舆论对于某一事件或产品的看法。
本系列文章是我的学习笔记,涵盖了入门的基础知识与模型以及对应的上机实验,截图截取自老师的课程ppt。
- 概论
- 词汇分析
- 句法分析
- 语篇分析
- 语义分析
- 语义计算
- 语言模型
- 文本摘要
- 情感分析
- 部分对应上机实验
目录
定义
情感分析(Sentiment analysis),又称倾向性分析,意见抽取(Opinion extraction),意见挖掘(Opinion mining),情感挖掘(Sentiment mining),主观分析(Subjectivity analysis),它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。
如从评论文本中分析用户对“数码相机”的“变焦、价格、大小、重量、闪光、易用性”等属性的情感倾向。
情感分析主要目的是识别用户对事物或人的看法、态度。参与主体主要包括:
- Holder (source) of attitude:观点持有者
- Target (aspect) of attitude:评价对象
- Type of attitude:评价观点
- set of types:Like, love, hate, value, desire, etc.
- simple weighted polarity: positive, negative, neutral
Text containing the attitude:评价文本,一般是句子或整篇文档。
- 从挖掘的对象(数据)来讲,又可以分为文档级别,句子级别和短语(词)级别三大类。
- 按照处理文本的类别不同,分为基于新闻评论的情感分析和基于产品评论的情感分析俩类。前者处理的文本主要是新闻评论,如情感句“他坚定地认为台湾是中国不可分割的一部分”,表明了观点持有者“他”对于事件“台湾归属问题”的立场;后者处理的主要是网络在线的产品评论文本,如“Iphone6s的外观很时尚”,表明了对评价对象“Iphone6s的外观”的评价“时尚”是褒义的。
情感分析的一般框架
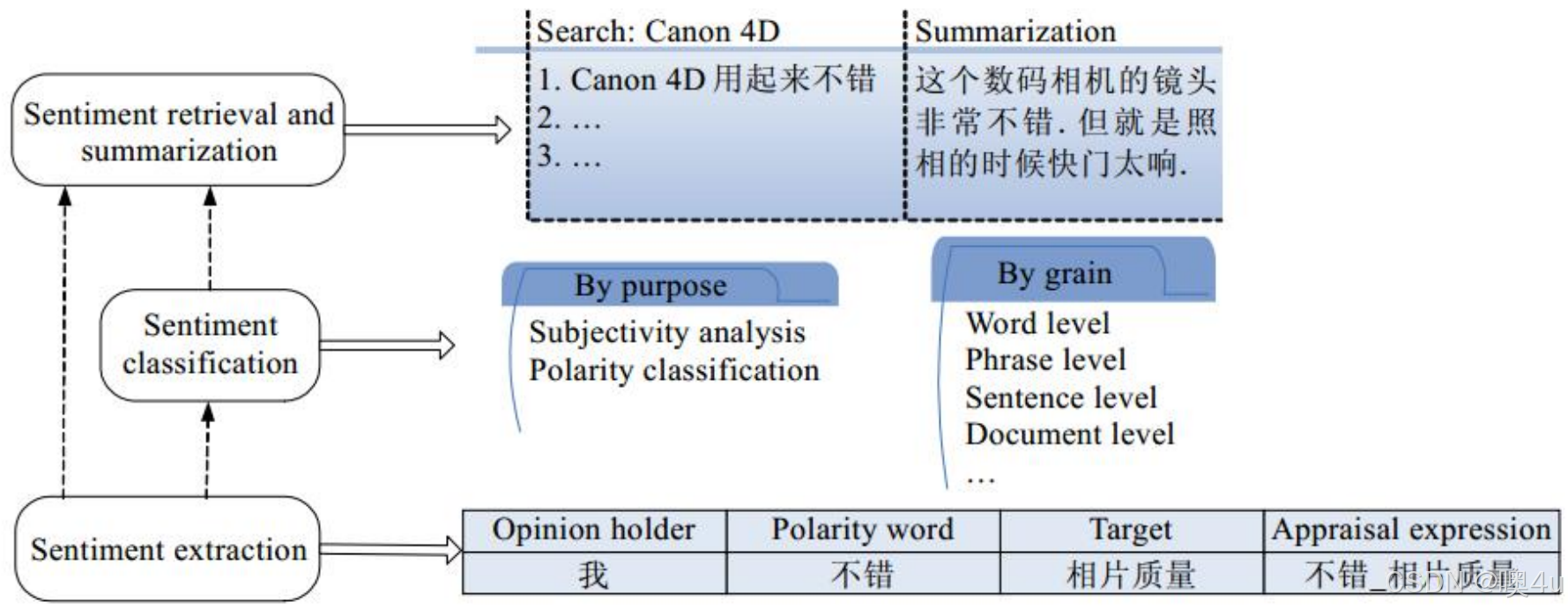
情感信息抽取是情感分析的最底层的任务,它旨在抽取情感评论文本中有意义的信息单元。其目的在于将无结构化的情感文本转化为计算机容易识别和处理的结构化文本,继而供情感分析上层的研究和应用服务。
情感信息分类则利用底层情感信息抽取的结果将情感文本单元分为若干类别,供用户查看,如分为褒、贬两类或者其他更细致的情感类别(如喜、怒、哀、乐等)。 按照不同的分类目的,可分为主客观分析和褒贬分析;按照不同的分类粒度,可分为词语级、短语级、篇章级等多种情感分类任务。
评价词语的抽取和判别
评价词语又称极性词、情感词,特指带有情感倾向性的词语。评价词语在情感文本中处于举足轻重的地位。
主要有基于语料库的方法和基于词典的方法。
- 基于语料库的方法:评价词语抽取和判别主要是利用大语料库的统计特性,观察一些现象来挖掘语料库中的评价词语并判断极性;
- 基于词典的方法:评价词语抽取及判别方法主要是使用词典中的词语之间的词义联系来挖掘评价词语。
评价对象的抽取
评价对象是指某段评论中所讨论的主题,具体表现为评论文本中评价词语所修饰的对象,如新闻评论中的某个事件/话题或者产品评论中某种产品的属性(如“屏幕”)等。
通常采用基于规则/模板的方法:规则的制定通常要基于一系列的语言分析与预处理过程,如词性标注、命名实体识别、句法分析等(可见本专栏之前的博客);
- 将评价对象看作产品属性的一种表现形式(如对数码相机领域而言,“相机的大小”是数码相机的一个属性,而“相机滑盖”是数码相机的一个组成部分),继而考察候选评价对象与领域指示词(如“整体-部分”关系,指示词“has”)之间的关联度来获取真正的评价对象。
观点持有者抽取
观点持有者的抽取在基于新闻评论的情感分析中显得尤为重要,它是观点/评论的隶属者,如新闻评论句“我国政府坚定不移的认为台湾是中国领土不可分割的一部分”中的“我国政府”。
实现方式主要有:命名实体识别技术、序列标注、知识图谱。
组合评价单元的抽取
单独的评价词语存在一定的歧义性,如评价词语“高”在以下 3 个句子中的使用:
- Sen 1:Mac的价格真高.
- Sen 2:华为手机的性价比相当高.
- Sen 3:姚明有2米多高.
主观表达式的抽取
主观表达式(subjective clues)是指表示情感文本单元主观性的词语或词组。评价词语是主观表达式的一部分。某些词语的组合(如 get out of here)也能很明显地标识文本的主观性。
评价短语的抽取
评价短语表现为一组连续出现的词组,不同于主观表达式,该词组往往是由程度副词和评价词语组合而成,如“very good”等。因此,这种组合评价单元不仅顾及了主观表达式的情感极性,还考察了其修饰成分。这些修饰成分或加强或减弱或置反了主观表达式的情感极性,使得评价短语成为一种情感色彩丰富的组合评价单元。
评价搭配的抽取
评价搭配是指评价词语及其所修饰的评价对象二者的搭配,表现为二元对〈评价对象,评价词语〉 ,如情感句“这件衣服价格很高”中的“价格-很高”。
“主观表达式”和“评价短语”主要是考察含有情感极性的一些词和短语,然而其并非真正地表现出情感极性。如情感句 “车跑得好快啊”中的词语“好”并不存在情感极性,需要过滤掉。此外,还有一些“主观表达式”和“评价短语”存在一定的歧义,其极性需要根据上下文而确定。
情感信息的分类
情感信息的分类任务可大致分为两种:一种是主、客观信息的二元分类;另一种是主观信息的情感分类,包括最常见的褒贬二元分类以及更细致的多元分类。
主客观信息分类
情感文本中夹杂着少量客观信息而影响情感分析的质量,需将情感文本中的主观信息和客观信息进行分离。由于情感文本单元表现格式比较自由,区分主、客观文本单元的特征并不明显,在很多情况下,情感文本的主客观识别比主观文本的情感分类更有难度。
情感信息的检索与归纳
情感信息抽取和分类后呈现的结果并不是用户所能直接使用的。情感分析技术与用户的交互主要集中于情感信息检索和情感信息归纳两项任务上。
- 情感信息检索旨在为用户检索出主题相关,且包含情感信息的文档;
- ① 结合传统的信息检索模型进行主题相关的文档检索;
- ② 相关文档的主客观识别。即针对某一主题的所有相关文档,判别它们的主客观性,并获取带有情感的主观性文档。
- ③ 主题相关的情感(主观性)文档排序。此时的排序策略需要同时兼顾文档的情感打分以及相关性打分。
- 情感信息归纳则针对大量主题相关的情感文档,自动分析和归纳整理出情感分析结果提供给用户参考,以节省用户翻阅相关文档的时间。情感文摘的处理对象为某一产品或某一事件的大量用户评论,往往以情感文摘的形式存在。情感文摘共有三种呈现方式:一种是基于产品属性的情感文摘;一种是基于情感标签的情感文摘;一种是基于新闻评论的文摘。
- 产品属性特指在产品评论中的评价对象,如“相机质量”、“焦距”等。

- 一般用若干个词语或短语的标签形式表现。这些标签能够很好地概括评论的主要内容,并以简短精悍的方式吸引了大量的用户群,可以看作是一种新形式的基于情感标签的文摘。但这种方式也存在一些问题:用户写评论时非常随意,很有可能概括不全自己的评论;用户书写的评论用词较为丰富,不方便计算机自动对比两个相似产品。(自动生成标签)。
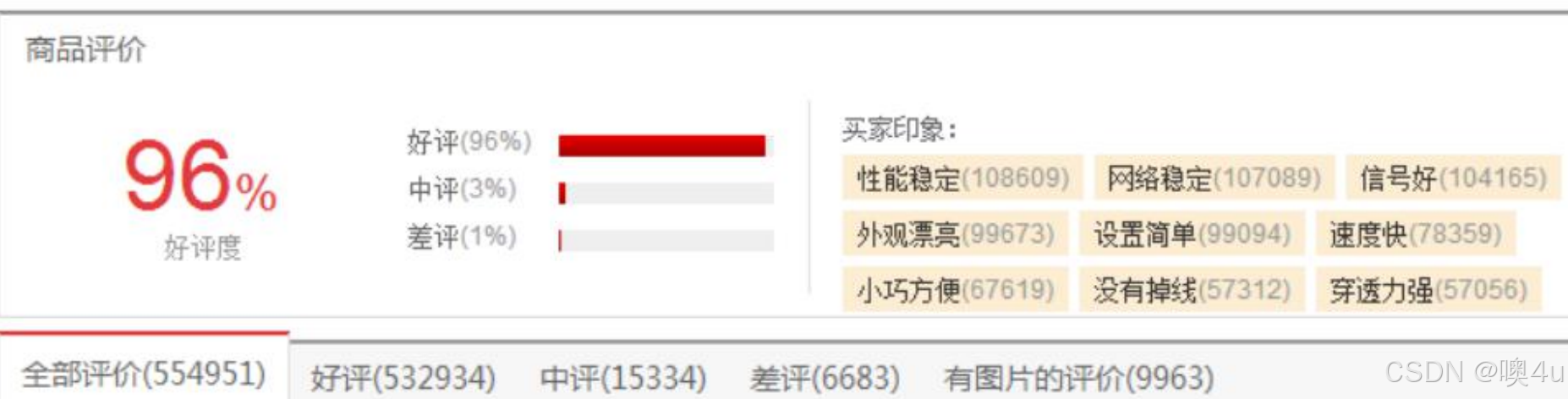
- 基于新闻评论的文摘和普通的新闻文摘比较类似,除了抽取重要的、信息含量大的核心句子之外,还要重视该句子中的情感信息。
- 产品属性特指在产品评论中的评价对象,如“相机质量”、“焦距”等。
公开数据集和资源
TREC(Text REtrieval Conference)由美国国家标准与技术研究院(NIST)主办,2006年设立了博客情感分析任务。已经成为文本检索领域最权威的评测会议之一。官网链接
公开的情感分析数据集:
- Cornell大学影评数据集:包含电影评论,标注了正负情感。其中持肯定和否定态度的各1,000篇;另外还有标注了褒贬极性的句子各5,331句,标注了主客观标签的句子各5,000句。
- MPQA语料库:(multiple-perspective QA) 包含535篇新闻评论,标注了主观性和情感极性。
常用的情感词典:
- General Inquirer (GI)词典:包含英语褒贬义词,带多维度标签。收集了1914个褒义词和2293个贬义词,并为每个词语按照极性、强度、词性等打上不同的标签;(需科学上网)
- OpinionFinder主观词词典:标注了词性和极性的英语主观词。该词典含有8221个主观词,并为每个词语标注了词性、词性还原以及情感极性;
- HowNet评价词典:中英文双语情感词典,该词典包含9193 个中文评价词语/短语,9142个英文评价词语/短语,并被分为褒贬两类。
代码实例
LSTM(三分类)
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import jieba
from collections import Counter
import os
train_data = [
# 强烈好评(2)
("这部电影简直完美,剧情紧凑,情感真挚,演技在线,必须满分推荐!", 2),
("视效炸裂,故事动人,是近年来少有的诚意之作。", 2),
("不管是配乐、摄影还是节奏控制都堪称一流,值得二刷三刷。", 2),
("剧情流畅,情节张力十足,演员表现令人惊艳。", 2),
("一部很有深度的影片,值得静下心来欣赏,回味无穷。", 2),
("感情戏份处理得非常细腻,情绪代入感极强。", 2),
("导演功底扎实,整体完成度极高,令人佩服。", 2),
("观影体验极佳,节奏掌控到位,令人沉浸其中。", 2),
("演员演技精湛,每一个情绪变化都很到位。", 2),
("结尾的反转太惊喜了,编剧真是个天才!", 2),
("从视觉到听觉都是一种享受,电影美学体现得淋漓尽致。", 2),
("角色塑造丰满,每一个人都有血有肉。", 2),
("台词自然流畅,人物对话很真实,有生活感。", 2),
("整部影片让人笑中带泪,是一场心灵的洗礼。", 2),
("这部片子情感细腻,节奏紧凑,非常感人。", 2),
("打斗设计精彩纷呈,动作场面流畅干净。", 2),
("电影节奏掌控得非常好,没有任何拖沓。", 2),
("影片传达的主题深刻,引发了我对人生的思考。", 2),
("配乐非常契合剧情,烘托气氛一级棒。", 2),
("情节设定精彩绝伦,完全沉浸其中无法自拔。", 2),
("一部充满艺术气息的作品,非常有价值。", 2),
("感情细节描绘入微,看得我热泪盈眶。", 2),
("无论是主角还是配角,都演得特别到位。", 2),
("整体节奏紧凑,一气呵成,毫无尿点。", 2),
("剧本扎实,结构合理,逻辑严谨。", 2),
("很多镜头拍得很有美感,审美体验很棒。", 2),
("小成本却拍出了大片的质感,太惊喜了!", 2),
("惊悚与情感交织得恰到好处,非常震撼。", 2),
("演技炸裂,剧情反转精彩,必须推荐!", 2),
("一部让我久久不能平静的好电影,值得收藏。", 2),
("在有限的时间里表达了深刻的主题,佩服。", 2),
("电影非常有力量,情节触动人心。", 2),
("故事设定新颖,完全颠覆了我的预期。", 2),
("完全被剧情吸引,紧张又感人。", 2),
("所有元素都很协调,是部成熟作品。", 2),
("笑点和泪点都处理得恰到好处,非常精彩。", 2),
("这是一部可以引起广泛共鸣的电影。", 2),
("故事真实动人,细节打磨得很好。", 2),
("角色成长线清晰有力,令人动容。", 2),
("整部片流畅自然,没有冗余。", 2),
("这才是真正的好电影,有内容有情感。", 2),
("一部值得全家人一起看的作品。", 2),
("导演讲故事的能力非常出众。", 2),
("全程无尿点,节奏感强。", 2),
("从头爽到尾,燃点十足。", 2),
("很久没有一部电影能让我这么投入了。", 2),
("主角魅力十足,演得特别好。", 2),
("电影节奏快、台词有趣,是完美的商业片。", 2),
("艺术性与娱乐性兼具,佩服创作者。", 2),
("拍得真的好,适合推荐给朋友一起看。", 2),
# 一般评价(1)
("电影一般般,没有太大亮点,也不至于差。", 1),
("节奏有点慢,但也不算难看。", 1),
("故事老套,不过演员演得还行。", 1),
("就是普通水平,适合无聊时看看。", 1),
("整部电影不功不过,没什么记忆点。", 1),
("观影体验中规中矩,没有太多槽点。", 1),
("剧本比较简单,看完也不会太难受。", 1),
("不是很出色但也不难看。", 1),
("台词有些做作,但还能接受。", 1),
("细节不错但剧情缺乏张力。", 1),
("部分演员演技尚可,整体发挥稳定。", 1),
("制作还行,节奏略拖沓。", 1),
("配乐不错,可惜剧情平淡。", 1),
("特效中规中矩,没有惊艳但不差。", 1),
("笑点偶有,整体比较平稳。", 1),
("结局有些仓促,但前半部分还可以。", 1),
("如果没事做可以看看,不看也不会遗憾。", 1),
("不是很推荐,但也没有踩雷。", 1),
("虽然不喜欢,但也能理解别人的喜好。", 1),
("影院体验一般,没什么特别的印象。", 1),
("情节安排合理但缺乏情感爆发。", 1),
("前半段不错,后半段有点拉垮。", 1),
("剪辑节奏尚可,但故事没新意。", 1),
("演员有的出彩,有的拖后腿。", 1),
("没特别不满,也谈不上满意。", 1),
("主题明确但手法平淡。", 1),
("有些地方还蛮有趣的,就是不够打动人。", 1),
("设定比较普通,没有突破。", 1),
("摄影不错,叙事一般。", 1),
("有些桥段还是挺抓人的。", 1),
("适合打发时间但不值得深思。", 1),
("导演还是有点能力的,只是剧本不够好。", 1),
("演技在线但故事太老。", 1),
("整体偏平,没有亮点也没大问题。", 1),
("感觉挺普通的电影,没啥记忆点。", 1),
("片长合适,不累,但也没激情。", 1),
("有想法但表达得不够到位。", 1),
("有些情节挺真实的,有共鸣。", 1),
("角色发展合理但缺乏惊喜。", 1),
("故事结构清晰但太稳妥。", 1),
("整体质量尚可,但缺少灵魂。", 1),
("就那样吧,看了就忘。", 1),
("评分略高于实际感受。", 1),
("最后五分钟有点意思,前面不行。", 1),
("如果免费能看看,花钱不值。", 1),
("部分台词写得还不错。", 1),
("整体气氛比较松散。", 1),
("主角人设略显平庸。", 1),
("拍得不差,但也不特别好。", 1),
# 差评(0)
("剧情无聊,几乎没有任何看点。", 0),
("演技差到令人尴尬,全程出戏。", 0),
("特效简陋,像十年前的电视剧。", 0),
("完全没逻辑,瞎编乱造的故事。", 0),
("浪费我时间,看到一半就想关掉。", 0),
("这部电影真的太糟糕了,毫无亮点。", 0),
("背景音乐吵闹刺耳,非常影响观感。", 0),
("台词生硬,像在背书。", 0),
("完全没有代入感,人物刻板单调。", 0),
("简直是一场灾难,没有任何艺术价值。", 0),
("剧本写得很差,连基本逻辑都没有。", 0),
("剪辑混乱,时间线莫名其妙。", 0),
("演员表现浮夸,令人作呕。", 0),
("这是我今年看过最差的一部电影。", 0),
("本来是冲着导演去的,结果失望透顶。", 0),
("毫无节奏感,看到最后只剩困意。", 0),
("摄影镜头抖得让人头晕。", 0),
("完全感受不到情感投入,全程冷漠。", 0),
("剧情不知所云,胡编乱造。", 0),
("导演一点想法都没有,全靠堆画面。", 0),
("演员演得像机器人,毫无情绪变化。", 0),
("配角比主角还要出戏。", 0),
("台词尴尬,几度让我起鸡皮疙瘩。", 0),
("题材本身不错,可惜被拍烂了。", 0),
("情节推进拖泥带水,一点也不爽快。", 0),
("整个故事一点吸引力都没有。", 0),
("对白浮夸、尴尬、无趣。", 0),
("演出风格极其生硬,看得想笑。", 0),
("导演野心很大,但能力配不上。", 0),
("一星都嫌多,真的劝退。", 0),
("毫无新意,重复老套路。", 0),
("看完想报警,太难受了。", 0),
("整部电影像拼凑出来的垃圾。", 0),
("视觉效果和音效都令人崩溃。", 0),
("完全不知道这片子拍来干什么。", 0),
("主题不清,剧情混乱。", 0),
("毫无逻辑,漏洞百出。", 0),
("整部影片都没说清楚自己要表达什么。", 0),
("观影过程极其痛苦,毫无快感。", 0),
("导演强行煽情,非常做作。", 0),
("让人不断出戏,根本无法入戏。", 0),
("制作水平非常低劣。", 0),
("真的是烂片代表。", 0),
("全程无趣无感。", 0),
("哪怕做背景音都嫌吵。", 0),
("演技和剪辑双重灾难。", 0),
("完全对不起票价。", 0),
("我已经忘了我看过这片。", 0),
("严重低于预期,非常失望。", 0),
]
def tokenize(text):
'''
jieba分词
'''
return list(jieba.cut(text))
# ---------- 构建词表 ----------
all_tokens = [tok for text, _ in train_data for tok in tokenize(text)]
vocab = {"<PAD>": 0, "<UNK>": 1}
# 自动编号,编号从2开始(0 和 1 预留给 <PAD> 和 <UNK>)
vocab.update({tok: i+2 for i, tok in enumerate(Counter(all_tokens))}) # 需要保存或调用 vocab
max_len = 20
embedding_dim = 32
hidden_dim = 64
def encode(text):
tokens = tokenize(text)
ids = [vocab.get(t, 1) for t in tokens][:max_len]
return ids + [0] * (max_len - len(ids))
X = torch.tensor([encode(text) for text, _ in train_data])
y = torch.tensor([label for _, label in train_data])
class MovieDataset(Dataset):
def __init__(self, X, y):
self.X, self.y = X, y
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
train_loader = DataLoader(MovieDataset(X, y), batch_size=2, shuffle=True)
# ---------- 模型定义 ----------
class SentimentModel(nn.Module):
def __init__(self, vocab_size, emb_dim, hidden_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, emb_dim, padding_idx=0) # 对每个词ID,查一个可训练的向量表,把它变成一个稠密向量
self.lstm = nn.LSTM(emb_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, 3)
def forward(self, x):
emb = self.embedding(x) # [batch_size, seq_len] → [batch_size, seq_len, emb_dim]
_, (hn, _) = self.lstm(emb) # hn shape: [1, batch_size, hidden_dim] # hn[-1] 是最后一个时刻的隐藏状态 → [batch_size, hidden_dim]
return self.fc(hn[-1]) # 对应 3 类情感(差评 / 一般 / 强烈好评)
model_path = "sentiment_model.pth"
def load_or_train_model():
model = SentimentModel(len(vocab), embedding_dim, hidden_dim)
if os.path.exists(model_path):
print("加载已保存模型")
model.load_state_dict(torch.load(model_path))
else:
print("未找到模型,开始训练...")
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(10):
for batch_x, batch_y in train_loader:
logits = model(batch_x)
loss = criterion(logits, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}")
torch.save(model.state_dict(), model_path)
print("模型已保存为 sentiment_model.pth")
model.eval()
return model
# ---------- 预测函数 ----------
label_map = {0: "差评", 1: "一般", 2: "强烈好评"}
def predict_sentiment(model, text, vocab, max_len=20):
model.eval()
with torch.no_grad():
tokens = tokenize(text)
ids = [vocab.get(t, 1) for t in tokens][:max_len]
padded = ids + [0] * (max_len - len(ids))
input_tensor = torch.tensor([padded])
logits = model(input_tensor)
pred = torch.argmax(logits, dim=1).item()
return label_map[pred]
if __name__ == "__main__":
model = load_or_train_model()
test_text = "剧情特别好,演员演技也很好。"
print("预测情感:", predict_sentiment(model, test_text, vocab))预测情感:强烈好评SnowNLP库(0-1的评分值)
#使用snownlp进行文本的情感分析,值在[0,1],越高代表这句话的情感评价越积极
from snownlp import SnowNLP
#初始的(训练前)结果不如人意
# print('"这首歌真难听"的情感得分是:',SnowNLP("这首歌真难听").sentiments)
# print('"今天天气真好啊"的情感得分是:',SnowNLP("今天天气真好啊").sentiments)
# 训练(此处注释掉了,当初始结果不满意时可训练)
from snownlp import sentiment
neg="neg.txt"
pos="pos.txt"
# sentiment.train(neg, pos)
# sentiment.save("sentiment.marshal")
#目录下会生成一个sentiment.marshal.3的文件。
#在snownlp的路径(site-package)下:将新得到的sentiment.marshal.3文件替换sentiment.marshal.3即可
#再运行
print('"这首歌真难听"的情感得分是:',SnowNLP("这首歌真难听").sentiments)
print('"今天天气真好啊"的情感得分是:',SnowNLP("今天天气真好啊").sentiments)
#继续不断丰富neg和pos的训练集即可
## 测试模型效果,导入测试数据
import pandas as pd
import numpy as np
test="test.csv"
result="result.xlsx"
data = pd.read_csv(test)
s = []
for c in data['comment']:
score = SnowNLP(c).sentiments
if score>=0.5:
s.append(1)
else:
s.append(0)
# data['sentiment_re'] = s
print(score)
print(s)
count = np.sum((s == data['sentiment'])==1)
print('准确率为:',count/len(data))
# data.to_excel(result,index=False)"这首歌真难听"的情感得分是: 0.14155926445883993
"今天天气真好啊"的情感得分是: 0.6159462002825609可用的测试test.csv
comment,sentiment,sentiment_re
这个项目的进展非常顺利,我们取得了令人振奋的成就。,1,
我的朋友们总是给我带来快乐和支持,让我感到无比幸运。,1,
我最喜欢的音乐家的新专辑充满了创意和活力,让我爱不释手。,1,
这个周末的计划看起来非常有趣,我迫不及待地期待着。,1,
我的家人是我生活中最坚实的后盾,他们的支持让我感到无比温暖和安心。,1,
我在工作中遇到了一些困难和挑战,让我感到有些沮丧和无助。,0,
我的健康状况最近有所下降,这让我感到担忧和不安。,0,
这个城市的交通问题越来越严重,每天都让我感到压力山大。,0,
这个新搬来的邻居很讨厌,总是发出噪音,而且劝说她她的态度也很差,大大降低了我的生活质量。,0,
我最近的假期计划完全泡汤了,让我感到失望和沮丧。,0,
总结
情感分析(Sentiment Analysis)是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程,广泛应用于舆情监控、产品评价等领域。其核心任务包括:
- 信息抽取:识别评价对象、观点持有者、情感词等要素。
- 分类任务:分为主客观分类和情感极性分类(如褒贬、喜怒等)。
- 资源与工具:常用数据集(如Cornell影评、MPQA语料库)、情感词典(如GI、HowNet),以及模型(如LSTM、SnowNLP库)。
- 技术方法:基于规则、词典或机器学习、深度学习、预训练的语言模型。
- 应用场景:从产品属性分析到新闻评论情感归纳。
公开评测(如TREC、NTCIR)推动了技术发展,而代码实例(如三分类LSTM模型)展示了实际应用。情感分析仍需解决歧义性、领域适配等问题。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 62
62 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)