
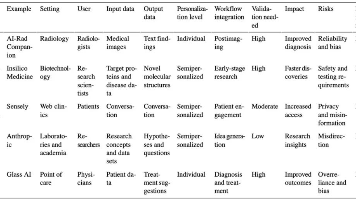
机器学习笔记之正则化(四)贝叶斯概率角度
上一节介绍了从权重衰减的角度描述正则化的本质,本节从贝叶斯概率的角度对正则化进行描述。
机器学习笔记之正则化——贝叶斯概率角度
引言
上一节介绍了从权重衰减的角度描述正则化的本质,本节从贝叶斯概率的角度对正则化进行描述。
本节建议与极大似然估计与最大后验概率估计结合阅读。
回顾:极大似然估计与最大后验概率估计
似然与最大似然估计
关于似然,我们并不陌生。似然就是似然函数( Likelihood Function \text{Likelihood Function} Likelihood Function),这个函数描述的是一个概率分布:
x ∼ P ( X ; θ ) x \sim \mathcal P(\mathcal X;\theta) x∼P(X;θ)
其中 θ \theta θ表示这个似然函数的参数。 X \mathcal X X表示样本集合; x x x表示服从分布 P ( X ; θ ) \mathcal P(\mathcal X;\theta) P(X;θ)中的某个样本。我们通常也会将似然函数描述成对数似然函数 ( Log-Likelihod Function ) (\text{Log-Likelihod Function}) (Log-Likelihod Function):
P ( X ; θ ) ⇒ log P ( X ; θ ) \mathcal P(\mathcal X;\theta) \Rightarrow \log \mathcal P(\mathcal X;\theta) P(X;θ)⇒logP(X;θ)
假设样本集合 X = { ( x ( i ) , y ( i ) ) } i = 1 N \mathcal X = \{(x^{(i)},y^{(i)})\}_{i=1}^N X={(x(i),y(i))}i=1N,并假设各样本之间满足独立同分布( Independent Identically Distribution,IID \text{Independent Identically Distribution,IID} Independent Identically Distribution,IID):
x ( i ) ∼ i.i.d P ( X ; θ ) i = 1 , 2 , ⋯ , N x^{(i)} \overset{\text{i.i.d}}{\sim} \mathcal P(\mathcal X;\theta) \quad i=1,2,\cdots,N x(i)∼i.i.dP(X;θ)i=1,2,⋯,N
那么概率分布 P ( X ; θ ) \mathcal P(\mathcal X;\theta) P(X;θ)可看作是样本集合 X \mathcal X X内 N N N个相互独立样本 x ( i ) ( i = 1 , 2 , ⋯ , N ) x^{(i)}(i=1,2,\cdots,N) x(i)(i=1,2,⋯,N)的联合概率分布:
P ( X ; θ ) = P ( x ( 1 ) , x ( 2 ) , ⋯ , x ( N ) ; θ ) = ∏ i = 1 N P ( x ( i ) ; θ ) \begin{aligned} \mathcal P(\mathcal X;\theta) & = \mathcal P(x^{(1)},x^{(2)},\cdots,x^{(N)};\theta)\\ & = \prod_{i=1}^N \mathcal P(x^{(i)};\theta) \end{aligned} P(X;θ)=P(x(1),x(2),⋯,x(N);θ)=i=1∏NP(x(i);θ)
而对应的对数似然函数表示如下:
- 对数似然函数
相较于似然函数在极大似然估计中有明显的优点。它将连乘操作∏ i = 1 N \prod_{i=1}^N ∏i=1N转化为连加操作∑ i = 1 N \sum_{i=1}^N ∑i=1N,节省了大量的计算资源,并且有利于后续的推导过程。 并且log \log log函数自身是单调递增函数,对极大似然估计结果的单调性无影响。
log P ( X ; θ ) = log ∏ i = 1 N P ( x ( i ) ; θ ) = ∑ i = 1 N log P ( x ( i ) ; θ ) \begin{aligned} \log \mathcal P(\mathcal X;\theta) & = \log \prod_{i=1}^N \mathcal P(x^{(i)};\theta) \\ & = \sum_{i=1}^N \log \mathcal P(x^{(i)};\theta) \end{aligned} logP(X;θ)=logi=1∏NP(x(i);θ)=i=1∑NlogP(x(i);θ)
关于极大似然估计,它是一个算法,它的返回结果是某个参数值,这个参数值满足的条件是:使得似然函数/对数似然函数结果达到最大:这里使用对数似然函数为例。
θ ^ = arg max θ log P ( X ; θ ) \hat \theta = \mathop{\arg\max}\limits_{\theta} \log \mathcal P(\mathcal X;\theta) θ^=θargmaxlogP(X;θ)
假设 θ ^ \hat \theta θ^就是基于样本集合 X \mathcal X X极大似然估计的最优参数结果,那么对应的 P ( X ; θ ^ ) \mathcal P(\mathcal X;\hat \theta) P(X;θ^)也是一个确定的概率分布结果,并且它与真实模型 P d a t a ( X ) \mathcal P_{data}(\mathcal X) Pdata(X)是接近的。
极大似然估计与最大后验概率估计
极大似然估计的问题描述
先说结论:极大似然估计不够准确。
以投掷硬币为例,投掷 10 10 10次硬币,可能会得到如下几种结果:其他结果我们不例举了。
- 硬币是正面 1 1 1次,反面 9 9 9次 ⇒ θ 1 \Rightarrow \theta_1 ⇒θ1;
- 硬币是正面 8 8 8次,反面 2 2 2次 ⇒ θ 2 \Rightarrow \theta_2 ⇒θ2;
- 硬币是正面 7 7 7次,反面 3 3 3次 ⇒ θ 3 \Rightarrow \theta_3 ⇒θ3;
如果以上述不同的 θ \theta θ值来描述投掷 10 10 10次硬币,其中正面 3 3 3次,反面 7 7 7次这个事件的概率时,我们会得到不同的概率结果:需要说明的点,关于似然函数 P ( X ; θ ) \mathcal P(\mathcal X;\theta) P(X;θ)和 P ( X ∣ θ ) \mathcal P(\mathcal X \mid \theta) P(X∣θ)写法都是没有问题的,都有各自的意义。其中 P ( X ; θ ) \mathcal P(\mathcal X;\theta) P(X;θ)可看作参数是 θ \theta θ的概率模型/概率分布; P ( X ∣ θ ) \mathcal P(\mathcal X \mid \theta) P(X∣θ)可看作是给定模型参数 θ \theta θ条件下,生成出样本集合 X \mathcal X X概率。
{ P ( X ∣ θ 1 ) = C 10 3 ⋅ ( 1 1 + 9 ) 7 ⋅ ( 9 1 + 9 ) 3 P ( X ∣ θ 2 ) = C 10 3 ⋅ ( 8 2 + 8 ) 7 ⋅ ( 2 2 + 8 ) 3 P ( X ∣ θ 3 ) = C 10 3 ⋅ ( 7 3 + 7 ) 7 ⋅ ( 3 3 + 7 ) 3 \begin{cases} \mathcal P(\mathcal X \mid \theta_1) = \mathcal C_{10}^3 \cdot (\frac{1}{1 + 9})^7 \cdot (\frac{9}{1+ 9})^3 \\ \mathcal P(\mathcal X \mid \theta_2) = \mathcal C_{10}^3 \cdot (\frac{8}{2 + 8})^7 \cdot (\frac{2}{2 + 8})^3 \\ \mathcal P(\mathcal X \mid \theta_3) = \mathcal C_{10}^3 \cdot (\frac{7}{3 + 7})^7 \cdot (\frac{3}{3 + 7})^3 \\ \end{cases} ⎩
⎨
⎧P(X∣θ1)=C103⋅(1+91)7⋅(1+99)3P(X∣θ2)=C103⋅(2+88)7⋅(2+82)3P(X∣θ3)=C103⋅(3+77)7⋅(3+73)3
虽然我们知道,随着我们投掷硬币的次数越多,上述的概率结果(括号内的部分)会越趋于稳定 ⇒ \Rightarrow ⇒向数值 0.5 0.5 0.5收敛。但这个 0.5 0.5 0.5结果我们可能永远也取不到。从而导致 θ \theta θ值永远无法得到精确解。
但是我们希望能够得到一个精确解来描述模型,因而使用极大似然估计去将这个解 θ \theta θ作为精确解。上述示例中,由于:
P ( X ∣ θ 1 ) < P ( X ∣ θ 2 ) < P ( X ∣ θ 3 ) \mathcal P(\mathcal X \mid \theta_1) < \mathcal P(\mathcal X \mid \theta_2) < \mathcal P(\mathcal X \mid \theta_3) P(X∣θ1)<P(X∣θ2)<P(X∣θ3)
因而上述示例中最优解是 P ( X ∣ θ 3 ) \mathcal P(\mathcal X \mid \theta_3) P(X∣θ3)对应的参数 θ 3 \theta_3 θ3。
那么关于极大似然估计,它有两个不合理的地方:
-
由于没有办法确定 θ \theta θ,我们可能需要通过大量的独立实验来统计 θ \theta θ可能发生的情况,并统计 θ \theta θ对应情况的概率分布 P ( θ ∣ X ) \mathcal P(\theta \mid \mathcal X) P(θ∣X),并从 P ( θ ∣ X ) \mathcal P(\theta\ \mid \mathcal X) P(θ ∣X)中选择出 θ \theta θ的解。
需要注意的是,这个情况不一定是离散的,也可能是连续的。但实际上,我们没有使用 P ( θ ∣ X ) \mathcal P(\theta \mid \mathcal X) P(θ∣X)对 θ \theta θ进行描述,而是使用似然函数 P ( X ∣ θ ) \mathcal P(\mathcal X \mid \theta) P(X∣θ)替代 P ( θ ∣ X ) \mathcal P(\theta \mid \mathcal X) P(θ∣X)进行描述。可是 P ( X ∣ θ ) ≠ P ( θ ∣ X ) \mathcal P(\mathcal X \mid \mathcal \theta) \neq \mathcal P(\theta \mid \mathcal X) P(X∣θ)=P(θ∣X)。
-
θ \theta θ自身没有办法求得精确解,但我们希望使用极大似然估计对应的参数结果作为 P ( X ∣ θ ) \mathcal P(\mathcal X\mid \theta) P(X∣θ)的最优解。
改进:最大后验概率估计
针对上述的第一个不合理的点,虽然 P ( X ∣ θ ) ≠ P ( θ ∣ X ) \mathcal P(\mathcal X \mid \theta) \neq \mathcal P(\theta \mid \mathcal X) P(X∣θ)=P(θ∣X),但是它们之间存在关联关系。使用贝叶斯定理对其进行描述:
P ( θ ∣ X ) = P ( X ∣ θ ) P ( X ) ⋅ P ( θ ) \mathcal P(\theta \mid \mathcal X) = \frac{\mathcal P(\mathcal X \mid \theta)}{\mathcal P(\mathcal X)} \cdot \mathcal P(\theta) P(θ∣X)=P(X)P(X∣θ)⋅P(θ)
由于 X \mathcal X X是样本集合,是已知量,我们可以将上述公式看作关于 θ \theta θ的一个函数 f X ( θ ) f_{\mathcal X}(\theta) fX(θ):其中 P ( X ) = ∫ θ P ( X ∣ θ ) ⋅ P ( θ ) d θ \mathcal P(\mathcal X) = \int_{\theta} \mathcal P(\mathcal X \mid \theta) \cdot \mathcal P(\theta) d\theta P(X)=∫θP(X∣θ)⋅P(θ)dθ,它和 θ \theta θ无关,被视作常数。一个常数对于求解最值没有影响。
f X ( θ ) = P ( θ ∣ X ) = P ( X ∣ θ ) P ( X ) ⋅ P ( θ ) ∝ P ( X ∣ θ ) ⋅ P ( θ ) \begin{aligned} f_{\mathcal X}(\theta) & = \mathcal P(\theta \mid \mathcal X) = \frac{\mathcal P(\mathcal X \mid \theta)}{\mathcal P(\mathcal X)} \cdot \mathcal P(\theta) \\ & \propto \mathcal P(\mathcal X \mid \theta) \cdot \mathcal P(\theta) \end{aligned} fX(θ)=P(θ∣X)=P(X)P(X∣θ)⋅P(θ)∝P(X∣θ)⋅P(θ)
对应的最大后验估计可表示为:
θ ^ = arg max θ f X ( θ ) = arg max θ [ P ( X ∣ θ ) ⋅ P ( θ ) ] \hat \theta = \mathop{\arg\max}\limits_{\theta} f_{\mathcal X}(\theta) = \mathop{\arg\max}\limits_{\theta} \left[\mathcal P(\mathcal X \mid \theta) \cdot \mathcal P(\theta)\right] θ^=θargmaxfX(θ)=θargmax[P(X∣θ)⋅P(θ)]
与对数似然函数一样,我们也可以给上式添加一个 log \log log项:
θ ^ = arg max θ log [ P ( X ∣ θ ) ⋅ P ( θ ) ] = arg max θ [ log P ( X ∣ θ ) + log P ( θ ) ] \begin{aligned} \hat \theta & = \mathop{\arg\max}\limits_{\theta} \log [\mathcal P(\mathcal X \mid \theta) \cdot \mathcal P(\theta)] \\ & = \mathop{\arg\max}\limits_{\theta} \left[\log \mathcal P(\mathcal X \mid \theta) + \log \mathcal P(\theta) \right] \end{aligned} θ^=θargmaxlog[P(X∣θ)⋅P(θ)]=θargmax[logP(X∣θ)+logP(θ)]
正则化项与先验概率
此时可以对比一下极大似然估计与最大后验概率估计的公式结果:
{ MAP : θ ^ = arg max θ [ log P ( X ∣ θ ) + log P ( θ ) ] MLE : θ ^ = arg max θ log P ( X ∣ θ ) \begin{cases} \text{MAP : } \hat \theta = \mathop{\arg\max}\limits_{\theta} \left[\log \mathcal P(\mathcal X \mid \theta) + \log \mathcal P(\theta) \right] \\ \text{MLE : } \hat \theta = \mathop{\arg\max}\limits_{\theta} \log \mathcal P(\mathcal X \mid \theta) \end{cases} ⎩
⎨
⎧MAP : θ^=θargmax[logP(X∣θ)+logP(θ)]MLE : θ^=θargmaxlogP(X∣θ)
其中对数似然函数 log P ( X ∣ θ ) \log \mathcal P(\mathcal X \mid \theta) logP(X∣θ)自身就是一种损失函数,通过最大化 log P ( X ∣ θ ) \log \mathcal P(\mathcal X \mid \theta) logP(X∣θ)来近似求解真实模型中的最优参数 θ ^ \hat \theta θ^。
上述式子仅差一项: log P ( θ ) \log \mathcal P(\theta) logP(θ)。 P ( θ ) \mathcal P(\theta) P(θ)表示参数的先验概率。在贝叶斯主义的思想中,先验概率并不重要,它总是会在大量的实验过程中,逐渐收敛至真实模型对应参数的概率分布。
高斯分布与 L 2 L_2 L2正则化
假设该先验分布中的参数 θ \theta θ服从高斯分布:
这里要定义θ \theta θ是一个K \mathcal K K维向量,这意味着θ \theta θ是K \mathcal K K维权重空间中的一个点:
θ = ( θ 1 , θ 2 , ⋯ , θ K ) T \theta = (\theta_1,\theta_2,\cdots,\theta_{\mathcal K})^T θ=(θ1,θ2,⋯,θK)T我们假设θ \theta θ每个维度的分量θ k ( k = 1 , 2 , ⋯ , K ) \theta_k(k=1,2,\cdots,\mathcal K) θk(k=1,2,⋯,K)均服从均值为0 0 0,方差为σ 2 \sigma^2 σ2的一维高斯分布:
θ k ∼ N ( 0 , σ 2 ) k = 1 , 2 , ⋯ , K \theta_k \sim \mathcal N(0, \sigma^2) \quad k=1,2,\cdots,\mathcal K θk∼N(0,σ2)k=1,2,⋯,K
使用概率密度函数可以将 log P ( θ ) \log \mathcal P(\theta) logP(θ)表示为:
和样本空间X \mathcal X X相同,关于θ \theta θ的权重空间,任意两组基均两两正交。这意味着K \mathcal K K维特征之间相互‘线性无关’。将对应概率密度函数代入。
log P ( θ ) = log P ( θ 1 , θ 2 , ⋯ , θ K ) = log ∏ k = 1 K P ( θ k ) = log ∏ k = 1 K { 1 σ ⋅ 2 π exp [ − ( θ k − 0 ) 2 2 σ 2 ] } \begin{aligned} \log \mathcal P(\theta) & = \log \mathcal P(\theta_1,\theta_2,\cdots,\theta_{\mathcal K}) \\ & = \log \prod_{k=1}^{\mathcal K} \mathcal P(\theta_k) \\ & = \log \prod_{k=1}^{\mathcal K} \left\{\frac{1}{\sigma \cdot \sqrt{2\pi}} \exp \left[-\frac{(\theta_k - 0)^2}{2\sigma^2}\right]\right\} \end{aligned} logP(θ)=logP(θ1,θ2,⋯,θK)=logk=1∏KP(θk)=logk=1∏K{σ⋅2π1exp[−2σ2(θk−0)2]}
将 log \log log代入公式中,最终可化简为如下形式:这里 C \mathcal C C表示常数。
log P ( θ ) = ∑ k = 1 K log { 1 σ ⋅ 2 π exp [ − ( θ k − 0 ) 2 2 σ 2 ] } = ∑ k = 1 K { log [ 1 σ ⋅ 2 π ] + log exp [ − ( θ k − 0 ) 2 2 σ 2 ] } = K ⋅ log [ 1 σ ⋅ 2 π ] ⏟ 常数 − 1 2 σ 2 ∑ k = 1 K θ k 2 = − 1 2 σ 2 θ T θ + C \begin{aligned} \log \mathcal P(\theta) & = \sum_{k=1}^{\mathcal K} \log \left\{\frac{1}{\sigma \cdot \sqrt{2\pi}} \exp \left[-\frac{(\theta_k - 0)^2}{2\sigma^2}\right]\right\} \\ & = \sum_{k=1}^{\mathcal K}\left\{\log \left[\frac{1}{\sigma \cdot \sqrt{2\pi}}\right] + \log \exp \left[-\frac{(\theta_k - 0)^2}{2\sigma^2}\right]\right\} \\ & = \underbrace{\mathcal K \cdot \log \left[\frac{1}{\sigma \cdot \sqrt{2\pi}}\right]}_{常数} - \frac{1}{2\sigma^2} \sum_{k=1}^{\mathcal K} \theta_k^2 \\ & = -\frac{1}{2\sigma^2} \theta^T\theta + \mathcal C \end{aligned} logP(θ)=k=1∑Klog{σ⋅2π1exp[−2σ2(θk−0)2]}=k=1∑K{log[σ⋅2π1]+logexp[−2σ2(θk−0)2]}=常数
K⋅log[σ⋅2π1]−2σ21k=1∑Kθk2=−2σ21θTθ+C
这明显就是一个 L 2 L_2 L2正则化项。其中 λ = − 1 2 σ 2 \begin{aligned}\lambda = -\frac{1}{2\sigma^2}\end{aligned} λ=−2σ21。也就是说:使用最大后验概率求解最优参数的过程中,先验分布 P ( θ ) \mathcal P(\theta) P(θ)如果选择均值为 0 0 0正态分布,相当于在极大似然估计作为损失函数的基础上,增加了 L 2 L_2 L2正则化作为约束。
Laplace \text{Laplace} Laplace分布与 L 1 L_1 L1正则化
同理,如果参数 θ \theta θ各分量均服从一维拉普拉斯分布:
θ k ∼ Laplace ( 0 , b ) \theta_k \sim \text{Laplace}(0,b) θk∼Laplace(0,b)
那么对数条件下的先验概率分布 log P ( θ ) \log \mathcal P(\theta) logP(θ)可表示为:
log P ( θ ) = ∑ k = 1 K log P ( θ k ) = ∑ k = 1 K log { 1 2 b exp [ − ∣ θ k − 0 ∣ b ] ⏟ 1 − Dim Laplace(0,b) PDF } = K ⋅ log 1 2 b ⏟ 常数 − 1 b ∑ k = 1 K ∣ θ k ∣ = − 1 b ∑ k = 1 K ∣ θ k ∣ + C \begin{aligned} \log \mathcal P(\theta) & = \sum_{k=1}^{\mathcal K} \log \mathcal P(\theta_k) \\ & = \sum_{k=1}^{\mathcal K} \log \left\{\underbrace{\frac{1}{2b} \exp \left[-\frac{|\theta_k - 0|}{b}\right]}_{1-\text{Dim Laplace(0,b) PDF}}\right\} \\ & = \underbrace{\mathcal K \cdot \log \frac{1}{2b}}_{常数} -\frac{1}{b} \sum_{k=1}^{\mathcal K} |\theta_k| \\ & = -\frac{1}{b} \sum_{k=1}^{\mathcal K} |\theta_k| + \mathcal C \end{aligned} logP(θ)=k=1∑KlogP(θk)=k=1∑Klog⎩
⎨
⎧1−Dim Laplace(0,b) PDF
2b1exp[−b∣θk−0∣]⎭
⎬
⎫=常数
K⋅log2b1−b1k=1∑K∣θk∣=−b1k=1∑K∣θk∣+C
也可以看出:先验分布选择了均值为 0 0 0拉普拉斯分布,相当于将极大似然估计作为损失函数的基础上,增加了 L 1 L_1 L1正则化作为约束。
同理,我们也可以尝试其他先验分布。如果先验分布是一个常数,此时该分布与参数 θ \theta θ没有关联关系,被忽略。此时最大后验概率被退化成极大似然估计。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)