
机器学习入门6--机器学习数据集相关概念
本系列博客基于温州大学黄海广博士的机器学习课程的笔记,小伙伴们想更详细学习黄博士课程请移步到黄博士的Github、或者机器学习初学者公众号,现在在中国慕课也是可以学习的,内容包括机器学习、深度学习及Python编程,matplotlib、numpy、pandas、sklearn等,资料很详细,要系统学习请移步哦!笔者的博客只是笔记,内容不会十分详细,甚至会有些少错误!1.数据集划分1.1 几个基本
本系列博客基于温州大学黄海广博士的机器学习课程的笔记,小伙伴们想更详细学习黄博士课程请移步到黄博士的Github、或者机器学习初学者公众号,现在在中国慕课也是可以学习的,内容包括机器学习、深度学习及Python编程,matplotlib、numpy、pandas、sklearn等,资料很详细,要系统学习请移步哦!笔者的博客只是笔记,内容不会十分详细,甚至会有些少错误!
1.数据集划分
1.1 几个基本概念
- 训练集(Training Set):训练模型用到的数据,通过训练集的数据确定拟合曲线的参数;
- 验证集(Validation Set):用来做模型选择,做模型的最终优化及确定,用来辅助模型的构建,训练超参数;(可选)
- 测试集(Test Set):测试已经训练好的模型的精确度;
- 一般划分:训练集、验证集、测试集;
- 机器学习一般划分比例:60%、20%、20%;70%、10%、20%;
- 深度学习一般划分比例:98%、1%、1%(百万级数据);
1.2 交叉验证
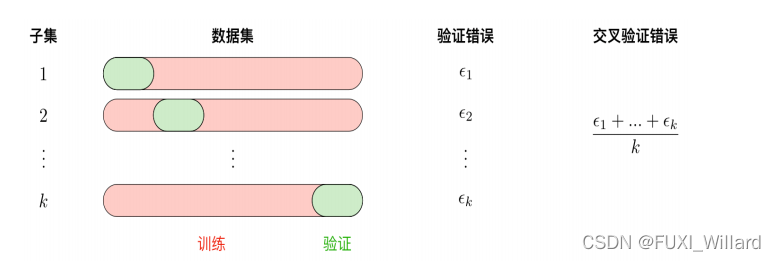
- 使用训练集训练出k个模型;
- 用k个模型分别对交叉验证集计算得出交叉验证误差(代价函数的值);
- 选取代价函数值最小的模型;
- 用上一步骤中选出的模型对测试集计算得出推广误差;
1.3 不平衡数据的处理
- 数据不平衡:数据集中各类样本数量不均衡的情况;
- 常用不平衡处理方法:采样和代价敏感学习;
- 采样欠采样、过采样和综合采样方法如下:
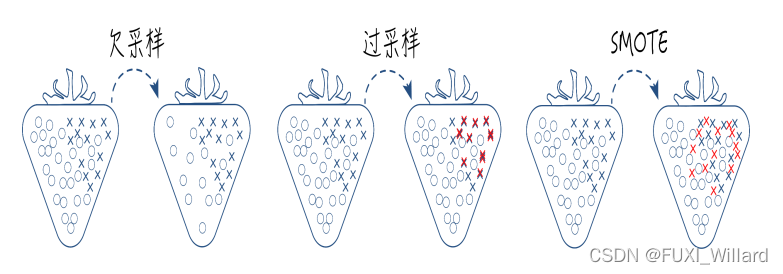
- SMOTE(Synthetic Minority Over-sampling Technique)算法是过采样中常用的一种;算法思想:合成新的少数类样本,但不是简单复制样本;
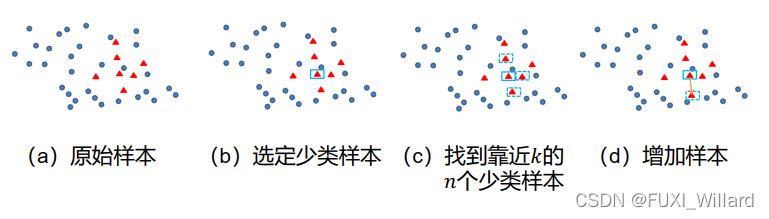
1.4 代价敏感学习
- 代价敏感学习:为不同类别的样本提供不同的权重,让机器学习模型进行学习的一种方法;
- 实例说明:风控或入侵检测;风控和入侵检测有严重的数据不平衡问题,可以在算法学习的时候,为少类样本设置更高的学习权重,让算法更加专注于少类样本的情况,提高对少类样本分类的查全率,但也会降低少类样本分类的查准率;
2.评价指标
2.1 评价指标简述
-
正确肯定(True Positive,TP):预测为真,实际为真;
-
正确否定(True Negative,TN):预测为假,实际为假;
-
错误肯定(False Positive,FP):预测为真,实际为假;
-
错误否定(False Negative,FN):预测为假,实际为真;
-
准确率:
A c c u r a c y = T P + T N T P + T N + F P + F N Accuracy = \frac{TP+TN}{TP+TN+FP+FN} Accuracy=TP+TN+FP+FNTP+TN -
精确率:
P r e c i s i o n = T P T P + F P Precision = \frac{TP}{TP+FP} Precision=TP+FPTP -
召回率:
R e c a l l = T P T P + F N Recall = \frac{TP}{TP+FN} Recall=TP+FNTP -
F1 Score:
F 1 = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n + R e c a l l F1 = \frac{2\times{Precision}\times{Recall}}{Precision+Recall} F1=Precision+Recall2×Precision×Recall -
混淆矩阵:

2.2 评价指标实例说明
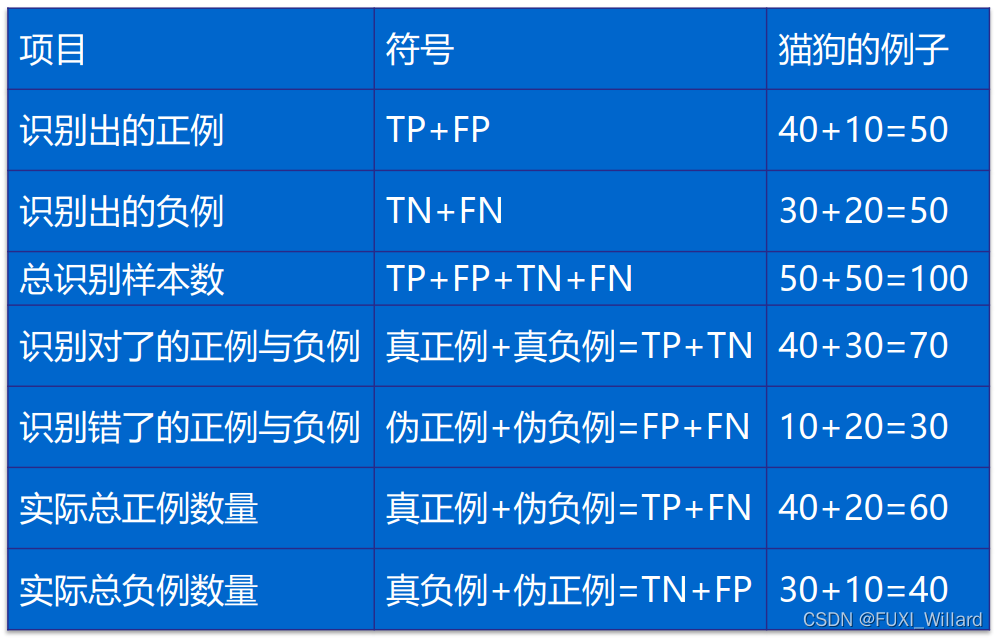
- 有100张照片,猫的照片60张,狗的照片40张;输入这100张照片进行二分类识别,找出这100张照片中所有的猫;
- 正例(Positives):识别对的;负例(Negatives):识别错的;
- 识别结果混淆矩阵:
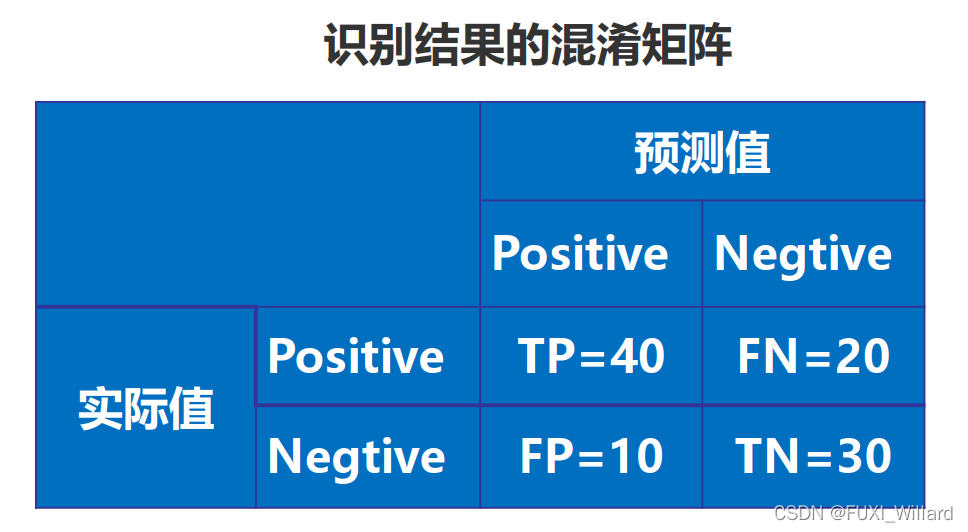
- 正确率(Accuracy):
A c c u r a c y = T P + T N T P + T N + F N + F P = 70 / 100 = 0.7 Accuracy = \frac{TP+TN}{TP+TN+FN+FP}=70/100=0.7 Accuracy=TP+TN+FN+FPTP+TN=70/100=0.7 - 精度(Precision):
P r e c i s i o n = T P T P + F P = 40 / 50 = 0.8 Precision = \frac{TP}{TP+FP}=40/50=0.8 Precision=TP+FPTP=40/50=0.8 - 召回率(Recall):
R e c a l l = T P T P + F N = 40 / 60 = 0.67 Recall = \frac{TP}{TP+FN}=40/60=0.67 Recall=TP+FNTP=40/60=0.67 - 各项如下:
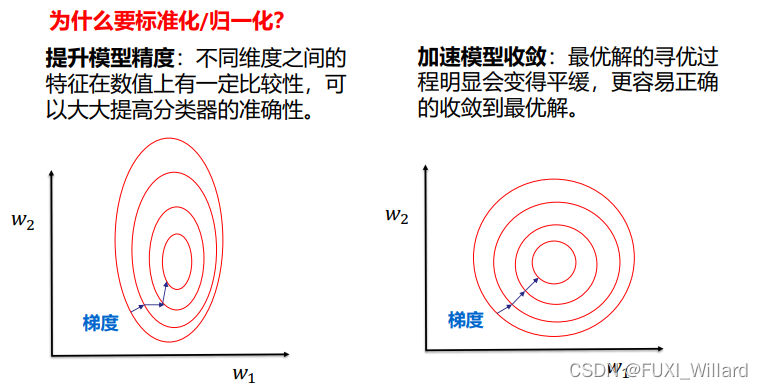
3.正则化
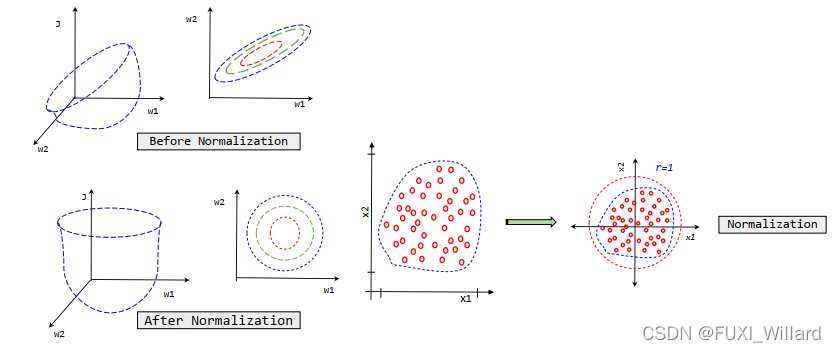
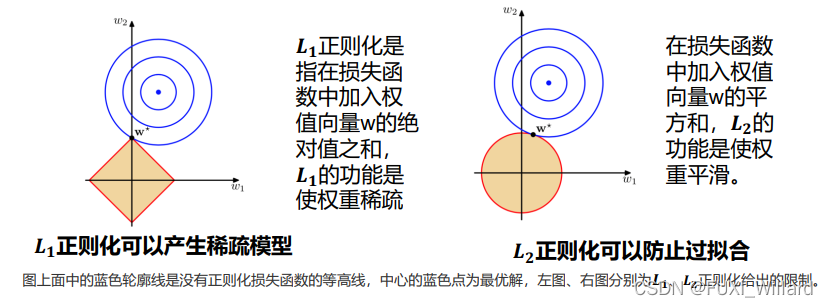
注:详细请移步:回归之正则化及评价指标.
4.误差、偏差
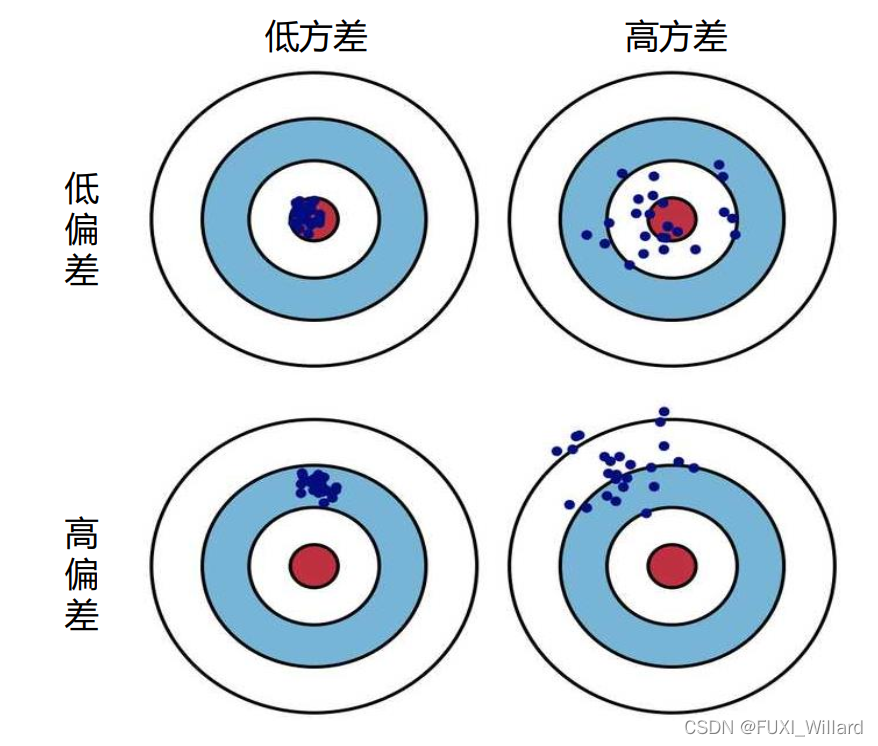
4.1 方差(Variance)
- 描述预测值的变化范围,离散程度,即:离期望值的距离;
- 方差越大,数据分布越分散;
4.2 偏差(Bias)
- 描述预测值的期望与真实值之间的差距;
- 偏差越大,越偏离真实数据;
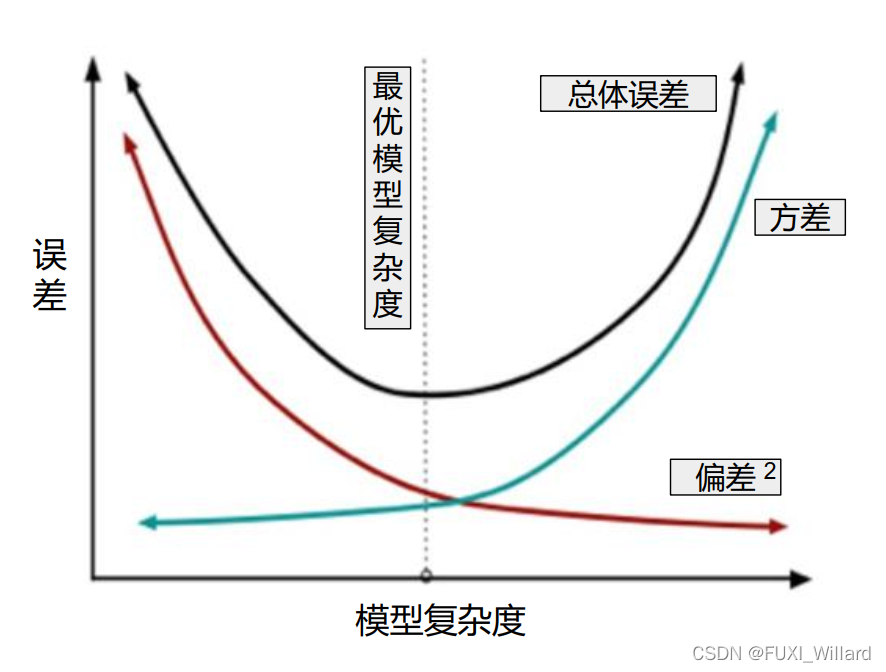
4.3 误差、方差、模型复杂度
- 一般来说,模型复杂度增加,方差逐渐增大,偏差逐渐减小;
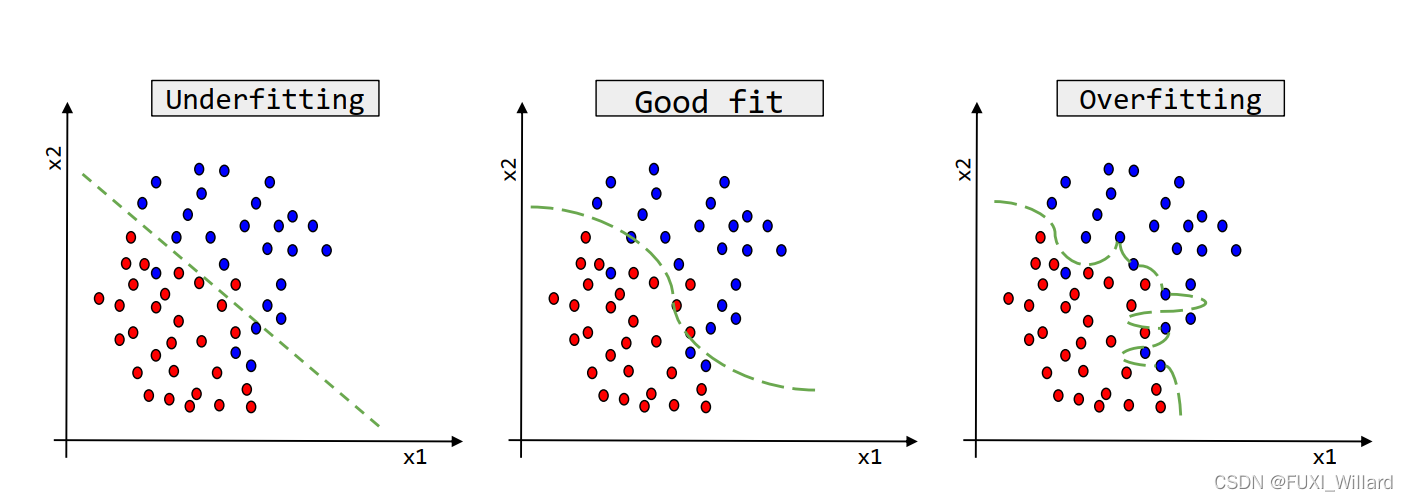
- 训练集误差和交叉验证集误差近似时:偏差/欠拟合;
- 交叉验证集误差远大于训练集误差时:方差/过拟合;
4.4 方差和偏差解决方案
- 获得更多的训练实例–解决高方差;
- 尝试减少特征的数量–解决高方差;
- 尝试获得更多的特征–解决高偏差;
- 尝试增加多项式特征–解决高偏差;
- 尝试减少正则化程度–解决高偏差;
- 尝试增加正则化程度–解决高方差;

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)