
AI智能体|扣子(Coze)搭建【自动采集爆款小红书笔记拆解二创】保姆级工作流教程
开始节点我们设置三个参数,cookie,keywords,feishu,分别代表的是小红书的 cookie,需要搜索内容的关键词,以及飞书多维表格的 token。这里我们设置大模型为 DeepSeek R1,设置输入参数为 title,content,分别代表笔记的标题和笔记的内容,设置输出参数为 output。比如职场有职场的规则,考试有考试的规则,当我们理解职场的规则,我们才能在职场如鱼得水,
大多数做自媒体的人,总想着用坚持去感动算法。
很多人对自媒体有一个误区,就是坚持后就有结果,其实这是不对的想法。
前段时间我朋友和我说:做自媒体有随机性,运气好的一下就火了,就算运气不好,坚持做,也能做起来。
听到他说这个的时候,我就知道他对这东西,几乎不懂,我见过很多人写了几百篇文章都几十阅读的,也见过写几十篇文章就几万阅读的。
很多做自媒体的人他们做不动,其实大概就是因为他们不理解自媒体的正确规则是什么。
这个世界是有规则的,我们只有遵循相应的规则,我们才能获得想要的结果,如果总想着逆天,那大概率是失败的。
比如职场有职场的规则,考试有考试的规则,当我们理解职场的规则,我们才能在职场如鱼得水,当我们理解考试的规则,我们才知道哪些东西不需要去学。
而自媒体也有自媒体的规则,那么自媒体的规则是什么呢?
我认为自媒体的规则只有一个,那就是【利他】,你只有提供对用户有帮助的东西,用户才会留下来。
而不是整天自己想发表什么就发表什么,也不必过多关注什么排版,多少点发布这种次要的因素,要把重点放在客户上。
记住:不建立在正确认知上的坚持,大概率会失败!
我的公众号之前单月涨粉近4900,就是在利他这方面有做一些思考,但做的还不够好,接下来我会不断考虑利他这方面,再进行内容的创作。
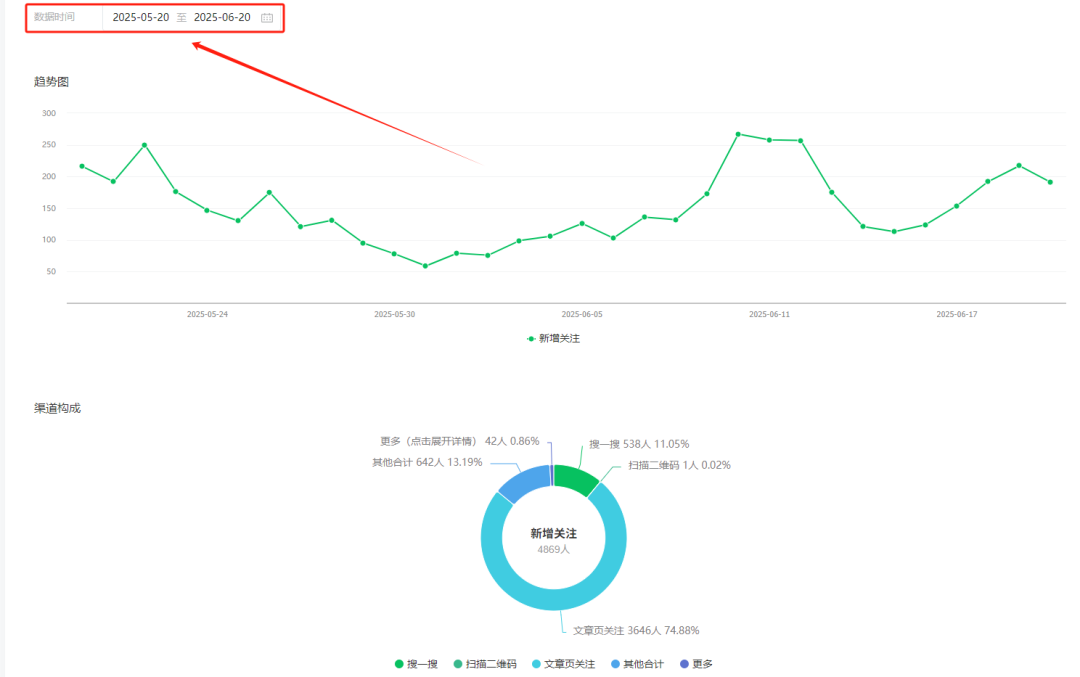
关于单月涨粉近 4900 的公众号,我也写了一篇深度的复盘帖子,如果你感兴趣,可以找我发给你看看。
这里由于文章长度的关系,我就不浪费大家的时间了。
好了,我们开始今天的内容吧,我们先看看工作流的效果如何。
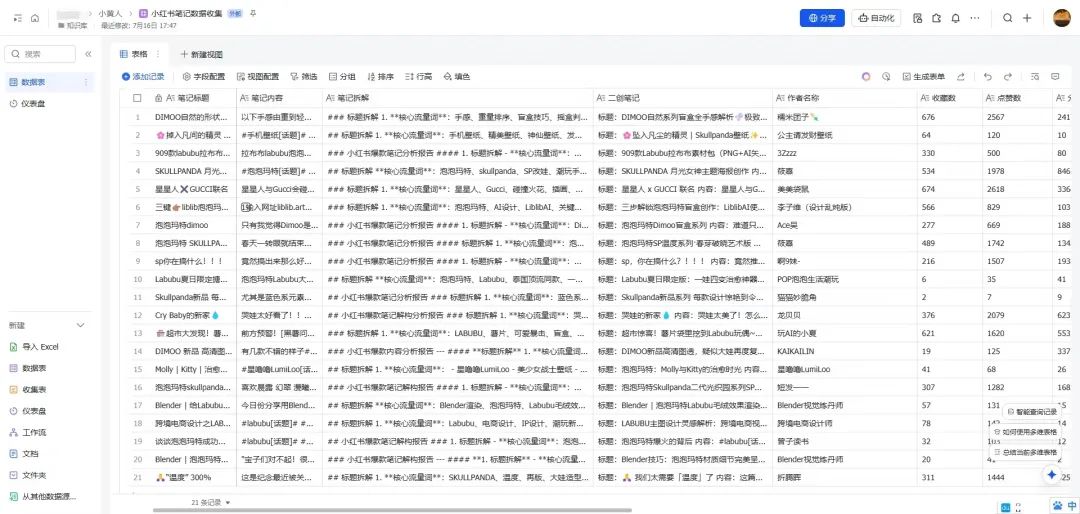
需求分析
很多做自媒体的人需要时刻的去监测平台的热点事件,然后产出相对应的作品。
但一条条的去搜索同一热点相关的笔记,非常费时间,而且这还是一种机械化且每天都需要重复的事情。
每天都会有新的热点,有新的热点,我们就需要去收集一些与这个热点相关的作品,然后产出。
因此这个工作流就能帮助一些做自媒体的人,减少收集热点对标笔记的时间,然后把大部分的时间都用在创作上。
整体流程分析
整体事件流程如下。

整体 Coze 工作流程如下。
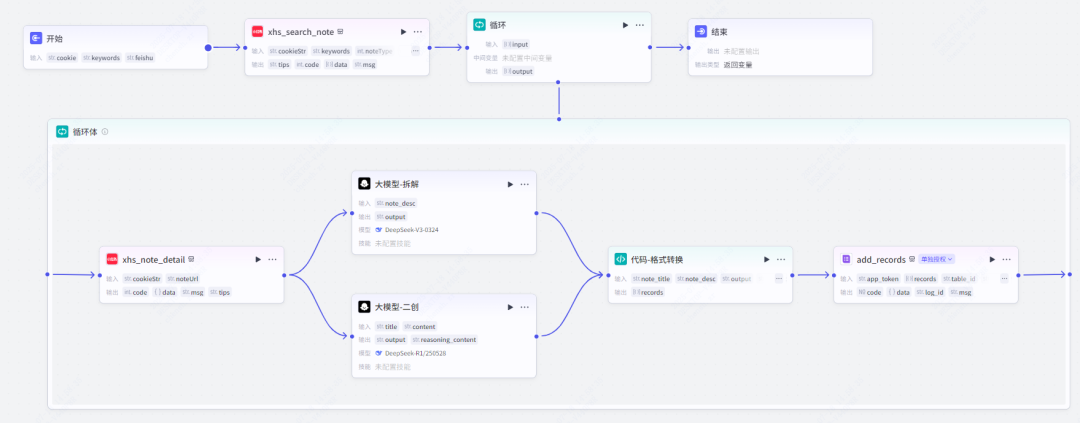
保姆级工作流教程
第零步,数据获取
在开始第一步之前,我们需要先获取小红书的 cookie。
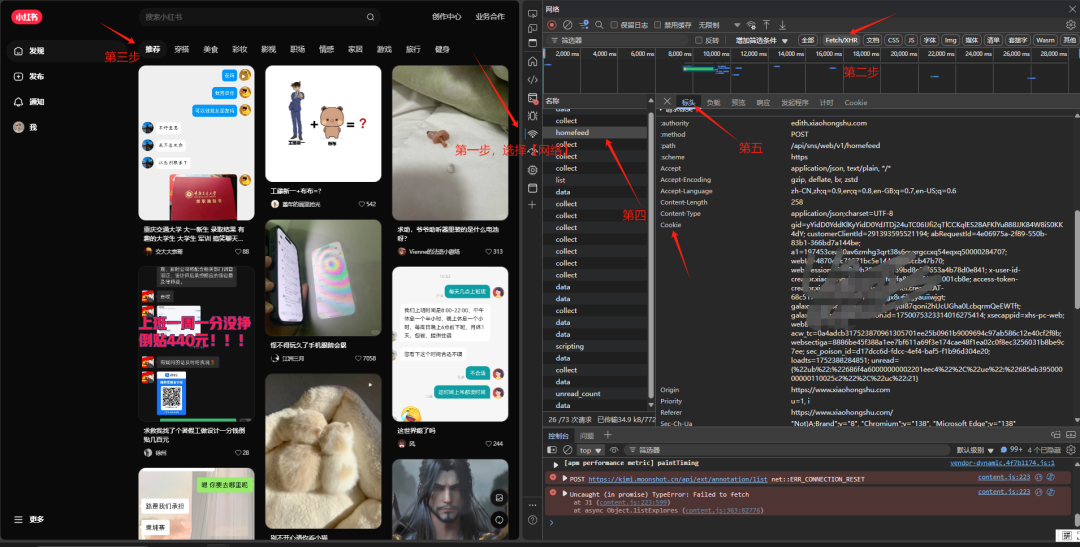
这里也要把飞书多维表格的权限给打开,否则存在写不进去的情况。
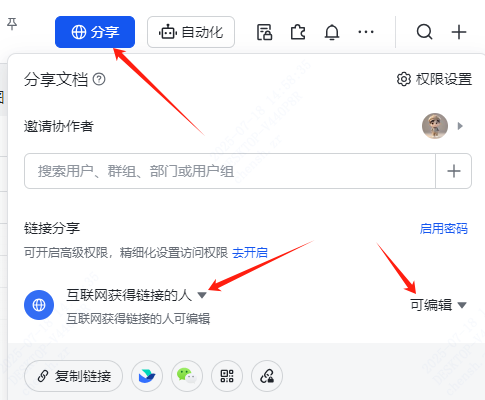
feishu 这个变量的参数就是多维表格的链接。
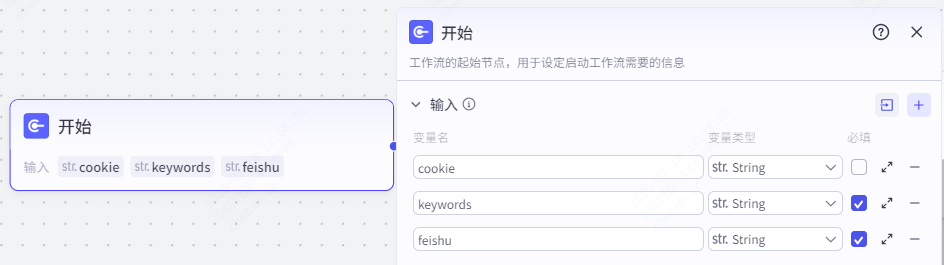
第一步,开始节点
开始节点我们设置三个参数,cookie,keywords,feishu,分别代表的是小红书的 cookie,需要搜索内容的关键词,以及飞书多维表格的 token。
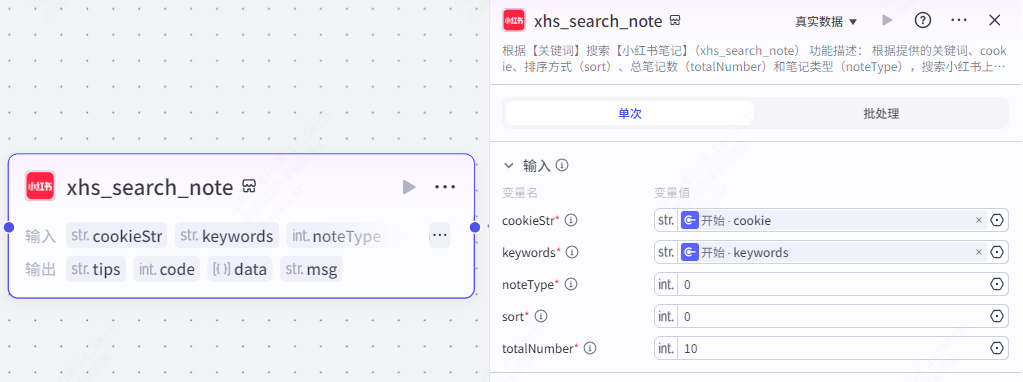
第二步,笔记搜索(小红书)
这个节点的作用是根据关键词去搜索小红书的笔记。
它一共拥有 5 个参数,cookieStr 是小红书的 cookie ,keyword 是关键词。
noteType 是查询类型( 0 表示全部,1 表示视频,2 表示图文)
sort 是排序( 0 表示综合,1 表示最新,2 表示最热)
totalNumber 是查询总数
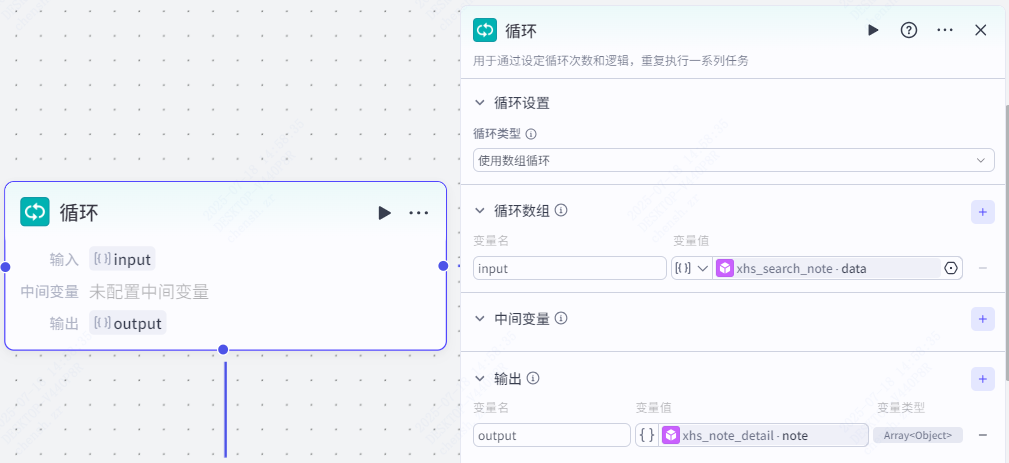
第三步,循环
循环节点的作用是根据上一节点获取的小红书笔记去循环获取所有笔记的详情。
这里我们设置循环类型为使用数组循环,设置循环数组 input 变量值为数组形式,数据来源为 xhs_search_note data 。
设置输出参数 output 变量值类型为 object ,变量值为 xhs_note_detail note。
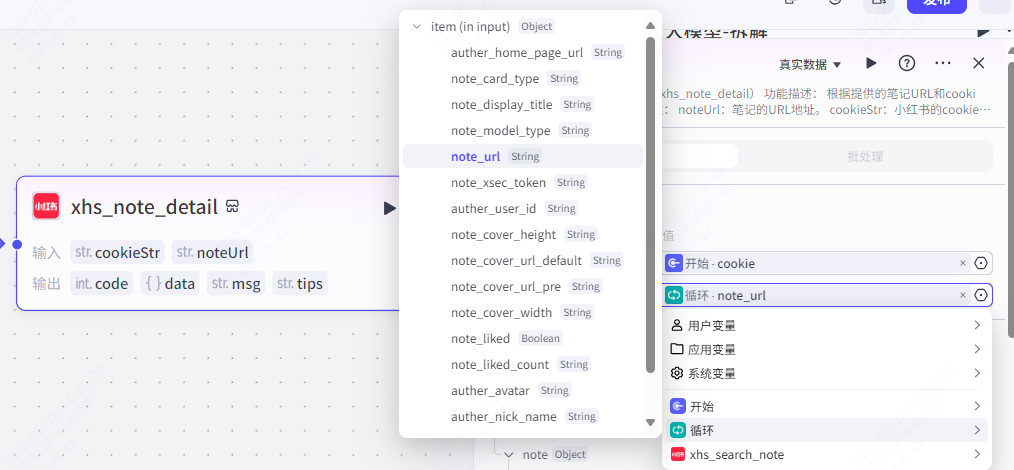
循环体:笔记详情获取(小红书)
这个节点的作用就是获取单个小红书笔记的笔记详情了。
这里我们需要设置输入变量名 cookieStr 数据来源为开始节点的 cookie,noteUrl 数据来源为循环节点的 note_url。
循环体:笔记拆解(大模型)
这一节点的作用是对小红书详细笔记进行拆解。
这里我们选择 DeepSeek-v3-0324 模型,设置输入参数为 note_desc,数据来源为 xhs_note_detail note_desc,设置输出参数为 output。
注:这里每个人拆解笔记的方式不一定是一样的,所有这里我就不提供系统提示词了,大家自行填写就行,我提供一个用户提示词,如果要用我的直接找我要。
用户提示词:
{{note_desc}}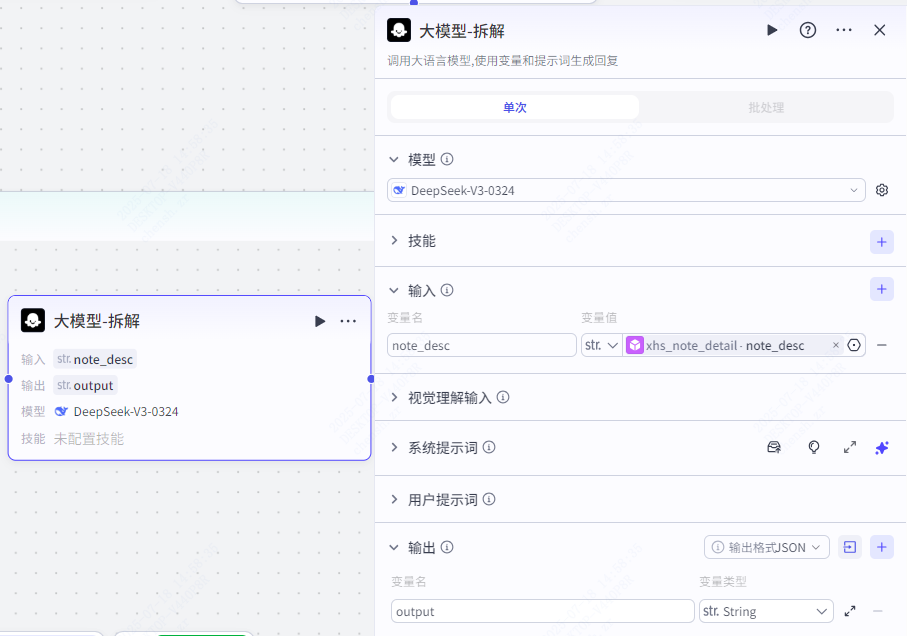
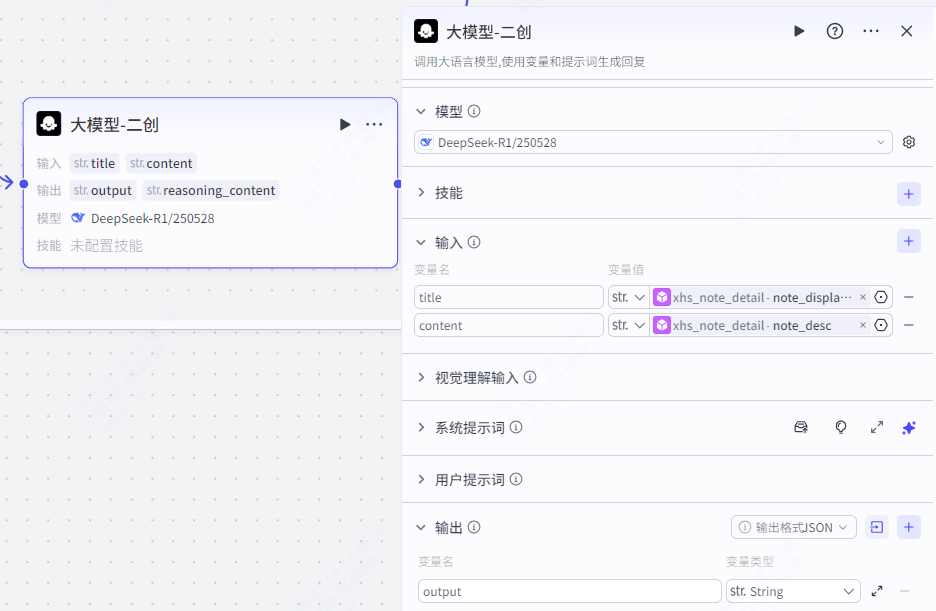
循环体:笔记二创(大模型)
这个节点的作用就是根据我们获得的小红书笔记详情,对小红书笔记进行二创了。
这里我们设置大模型为 DeepSeek R1,设置输入参数为 title,content,分别代表笔记的标题和笔记的内容,设置输出参数为 output。
title 的数据来源为 xhs _note_detail.note_display_title,content 的数据来源为xhs_note_detail.note_desc。
注:这里提示词和上面一样,需要的找我就行,我这里提供用户提示词。
用户提示词:
标题:{{title}}
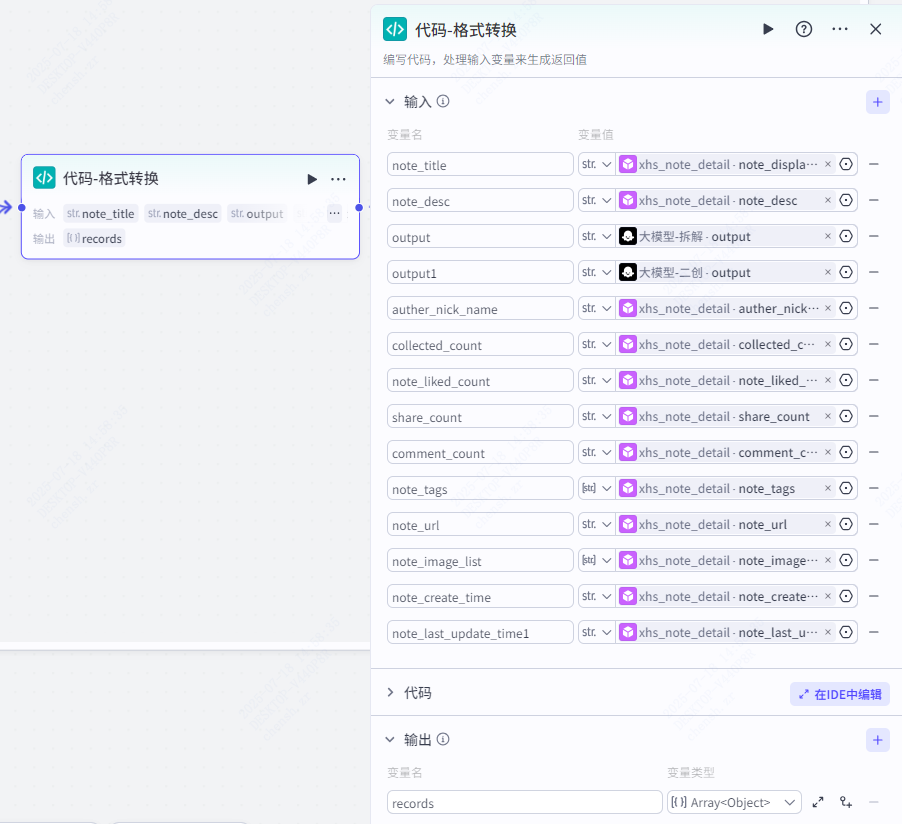
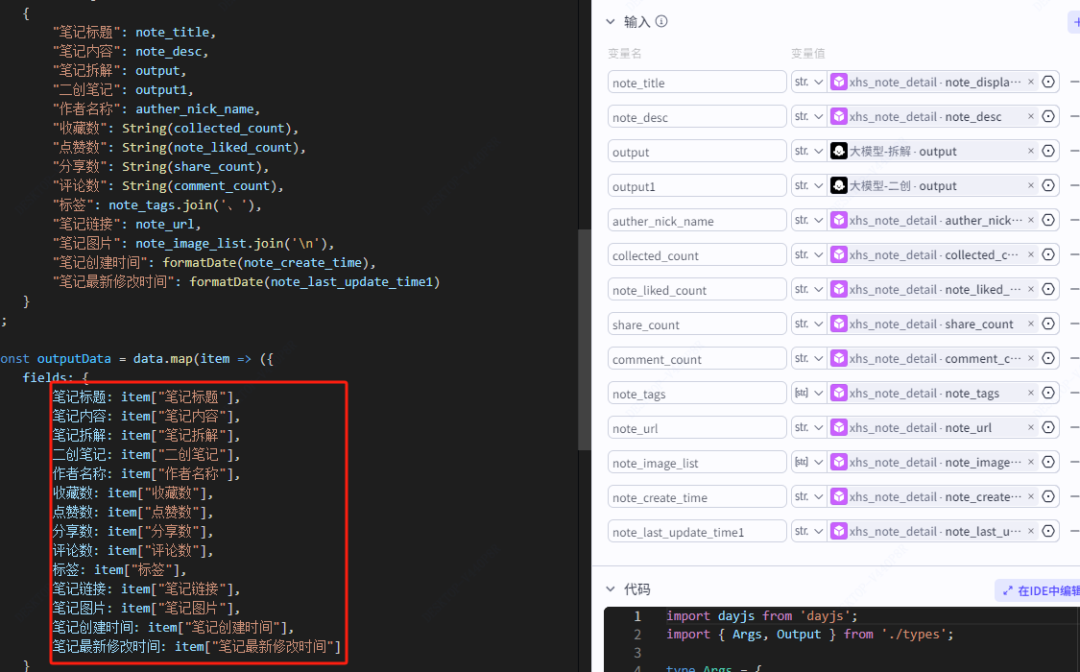
内容:{{content}}循环体:数据格式转化(代码)
这个节点的作用主要是将数据格式转化为可以导入飞书文档的数据格式,所有输入参数都来源小红书笔记详情节点,具体的内容可以看下面。
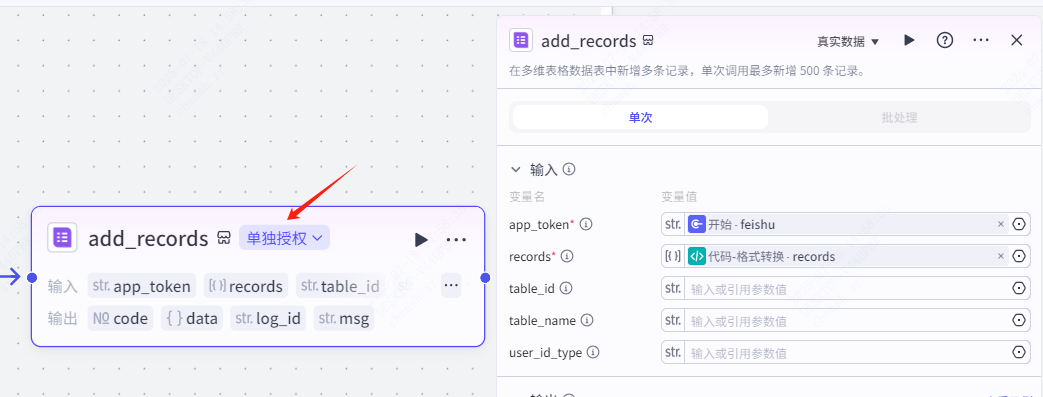
循环体:飞书多维表格节点
飞书多维表格就是作为一个数据存储的作用。
这里我们设置输入参数 app_token,recods,数据来源为开始节点的 feishu,以及代码节点的 records。
注:这里要进行授权!!
同时我们也要设置多维表格的表头格式,如果不设置好的话,我们的数据就会写不进去,具体的表头类型是以下这几种。
第四步,结束节点
结束节点的话,我们这里形成一个闭环就行了,不需要输出什么东西。
总结
整体一共有 4 步,并不算麻烦,如果你感兴趣的话,那就快去试试看吧。
下期即将分享关于【闲鱼上下架商品】的工作流,如果有兄弟们做副业要用到闲鱼的,千万别错过哟。
在更新几期工作流,就要更新一些其它内容了,有可能是 AI 编程,有可能是 AI 知识库。
如果兄弟们对这个感兴趣的话,持续关注,咱们一起学习吧。
对了,你还想看什么样的工作流,也可以在评论区留言喔。
我们会根据实际情况,搭建你们想看的工作流教程的。
本期的内容就到这里了,感谢你的耐心。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 18
18 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)