
嵌入式全栈开发学习笔记---C语言(数组/函数/关键字)
上一篇复习了8个编程题,这一片开始复习数组和函数。数组分为:一维数组,二维数组,字符数组(笔试重点)我们先来看一维数组1、一维数组的定义格式为:类型说明符 数组名[常量表达式];例如: int a[10]; //它表示定义了一个整形数组,数组名为a,有10个元素。2、在定义数组时,需要指定数组中元素的个数,方括号中的常量表达式用来表示元素的个数,即数组长度。
目录
上一篇复习了8个编程题,这一片开始复习数组和函数。
数组
数组分为:
一维数组
二维数组
字符数组(笔试重点)
我们先来看一维数组
一维数组
1、一维数组的定义格式为:
类型说明符 数组名[常量表达式];
例如: int a[10]; //它表示定义了一个整形数组,数组名为a,有10个元素。
2、在定义数组时,需要指定数组中元素的个数,方括号中的常量表达式用来表示元素的个数,即数组长度。
数组的地址
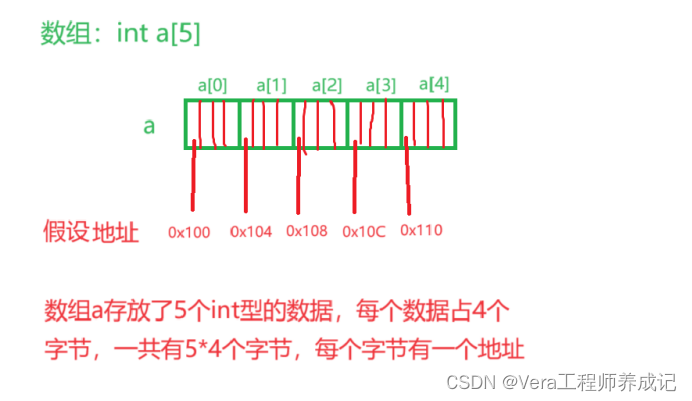
注意:每个字节有一个地址,每个数组元素的地址是它的首字节的地址
记住:数组元素的地址是从低地址到高地址,也就是说a[0]存放在低地址,a[4]存放在高地址。
一定要记住这一点,今后我们在嵌入式设备里面会涉及到一个字节序的问题。
为什么要记住这一点呢?
比如我们定义一个变量int num=1;
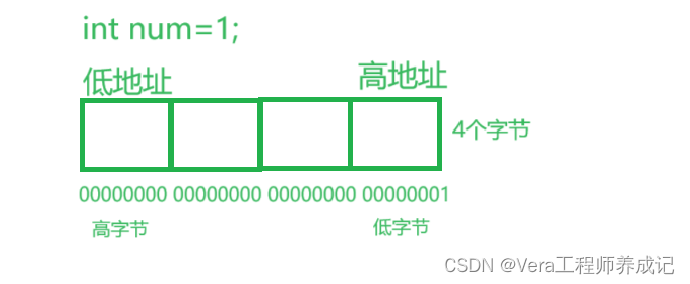
我们来思考一个问题:
num的高字节应该放在低地址还是高地址?或者低字节应该放在低地址还是高地址?
答案是两种情况都会存在,也就是说既有高字节存放在高地址的情况,也有高字节放在低地址的情况。不同的平台(比如ARM,X86等平台)字节序可能不太一样。
一般ARM,X86等小端字节序我们常见的是低字节存放在低地址,高字节存放在高地址。
大端字节序常见的是高字节存放在低地址,低字节存放在高地址。
我们后面复习到联合体的时候,我们会讲如何判断设备的字节序。
我们的数组无疑是:数组元素的地址是从低地址到高地址,也就是说a[0]存放在低地址,a[4]存放在高地址。但是每个元素内部的地址和字节存放方式就取决于设备的字节序了。
一维数组的初始化
1、在定义数组时对数组元素赋以初值。
例如:int a[10] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
2、 可以只给一部分元素赋值。例如:
int a[10] = {0, 1, 2, 3, 4};
定义a数组有10个元素,但花括弧内只提供5个初值,这表示只给前面5个元素赋初值,后5个元素值为0。
3、如果想使一个数组中全部元素值为0,可以写成:
int a[10] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
或int a[10]={0};
不能写成:int a[10] = {0 * 10};
4、在对全部数组元素赋初值时,由于数据的个数已经确定,因此可以不指定数组长度。
例如:int a[5] = {1,2,3,4,5};
也可以写成 int a[]={1,2,3,4,5};
注意:全局变量未初始化,默认是0;局部变量未初始化,默认是随机值。
补充:常量表达式中可以包括常量和符号常量,但不能包含变量。
注意:C语言不允许对数组的大小作动态定义,即数组的大小不依赖于程序运行过程中变量的值。
比如,我们不能这样定义数组:int k=100; int a[k]={0}; 但是我们可以这样写,先定义一个宏常量#define size 5 再将宏常量作为数组的长度int a[size];
遍历数组
用for循环
int i;
for(i=0;i<5;i++)
{
printf(“%d “,a[i]};
}
数组名的含义(笔试重点)
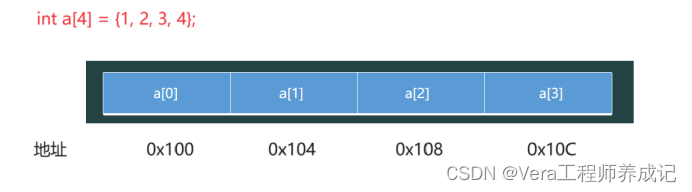
1、数组名a就是数组首元素地址,即0x100;
2、数组名a是地址常量,不能被修改;
3、a + 1 = 0x104;(前面说过每个字节有一个地址,每个数组元素的地址是它的首字节的地址,a+1表示首元素的地址加1,那到个第二个元素的地址,而第二个元素的地址即它首字节的地址)
4、&a表示整个数组的地址;
5、&a + 1 = 0x110;(整个数组元素的地址加1,那就是跨越了这个数组,不在这个数组的存放范围了)
6、&a[0]+1的含义和a+1的含义是一样的。
强调:
%p就用来打印地址,带0x
&在C语言中表示取地址,如&a[0]表示取地址a[0]
一维数组常见的编程题:冒泡排序
冒泡排序规则:从左到右,相邻的两个数比较大小,如果要求从小到大排序,那么比较后,如果前一个数比后一个数大,那么就将这两个数的位置调换,如此反复,直到所有数的大小满足从小到大顺序排序。
笔试题10
问:从键盘中输入乱序的10个数字,用冒泡排序将这个10个数字按从小到大排序
提示:比如说用冒泡排序将5 6 4 7 3 8 按从小到大排序
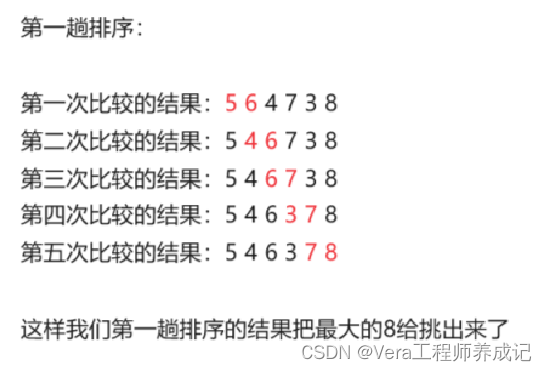


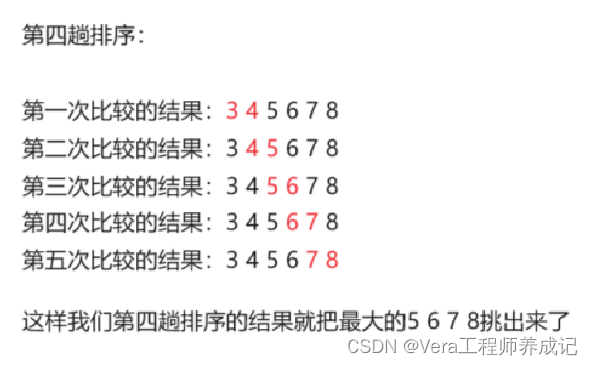

剩下的3无疑是最小的了,就不需要继续比较了,因此我们需要两层循环,一个是趟数循环(一共是5趟),一个是每趟里面的次数循环(一共是5次)。
但是,我们为了保证程序的效率,当我们挑出来最大的几个数后,下一趟循环我们就没必要再进行比较后面的了。

因此我们每一趟循环中的次数都比上一趟循环的次数要少一次。
解题:
参考代码:
#include <stdio.h>
int main()
{
int a[10]={0};
int i,j,num;
//获取数组元素
for(num=0;num<sizeof(a)/sizeof(a[0]);num++)
{
scanf("%d",&a[num]);
}
//冒泡排序
for(i=0;i<sizeof(a)/sizeof(a[0])-1;i++)
{
for(j=0;j<sizeof(a)/sizeof(a[0])-1-i;j++)
{
if(a[j]>a[j+1])
{
int tmp=a[j];
a[j]=a[j+1];
a[j+1]=tmp;
}
}
}
//遍历数组
for(num=0;num<sizeof(a)/sizeof(a[0]);num++)
{
printf("%d ",a[num]);
}
return 0;
}运行结果:

请务必要把冒泡排序搞懂并且把这段代码牢记!
补充命令3:“gcc 文件名.c -o 文件名 -wall ”查看隐藏的警告
把所有的警告打开,有时候我们写错了程序但是也能正常编译,并且没有显示有警告,但是程序我们明明知道是错误的,我们可以使用这条命令查看隐藏的警告。
补充命令4:“&”在Linux中表示后台运行
在Linux中表示后台运行的意思。以后遇到要用的时候再详细讲。
二维数组
二维数组定义的一般形式为:
类型说明符 数组名[常量表达式][常量表达式];
例如:float a[3][4],b[5][10];
定义a为3×4(3行4列)的数组,b为5×10(5行10列)的数组。
二维数组的初始化
1、分行给二维数组赋初值。
例如: int a[2][3]={{1,2,3},{4,5,6}}; //最正规的写法
2、可以将所有数据写在一个花括号内,按数组排列的顺序对各元素赋初值。
例如:int a[2][3]={1,2,3,4,5,6}; //编译会报警告
3、可以对部分元素赋初值。
例如:
int a[2][3]={{1}, {5}, {9}}; //没有赋值的为0
int a[2][3]={{1}, {2, 3}};
4、如果对全部元素都赋初值,则定义数组时对第一维的长度可以不指定,但第二维的长度不能省。即行可以省,列不可以省。
例如:int a[2][3]={1, 2, 3, 4, 5, 6};
等价于:int a[ ][3]={1, 2, 3, 4, 5, 6};
5、二维数组初始化为全0,int a[2][3]={{0},{0}};有些编译器还支持写成int a[2][3]={0};
遍历二维数组
int a[3][4];
int i,j;
for(i=0;i<3;i++)
{
for(j=0;j<4;j++)
{
printf(“%d “,a[i][j])
}
printf(“\n”);
}
二维数组的数组名
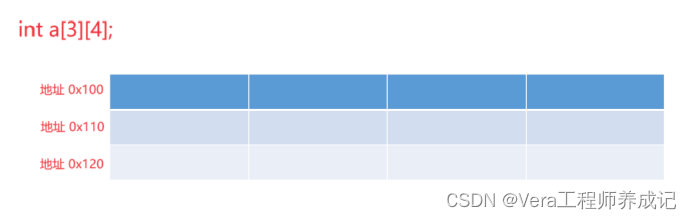
1、数组名a表示首行地址,即0x100,a + 1 = 0x110;(加1就到了下一行的地址)
2、a[0](也可以写成a[0][0])表示首行首元素地址,即0x100,a[0] + 1 = 0x104;(加1就到了当行的第二个元素的地址);注意a[0]表示首行首元素的地址,a[1]表示第二行首元素的地址,以此类推
3、&a表示数组地址,即0x100,&a + 1 = 0x12C。(加1跨越了整个数组)
笔试题11
数组a[3][4],哪个不能表示a[1][1]的地址?
A、a[1] + 1
B、&a[1][1]
C、(*(a + 1)) +1
D、a+5
答案是:D
a表示首行的地址,+5就跳到第六行了,但是这个数组只有4行,所以已经不在这个数组范围内了。
a + 1是第二行的地址,*(a + 1)变成第二行首元素的地址,(*(a + 1)) +1就变成了第二行第二个元素的地址。
字符数组(笔试重点)
字符数组初始化
字符数组的初始化有两种方法,一种是逐个赋值,一种是用字符串赋值。
1.char ch[5] = {'h', 'e', 'l', 'l', 'o'}; //麻烦,一般不用
2.char ch[10] = “helloworld”; //方便实用,但是存在bug,有些平台上这样写打印出来后面会跟着很多乱七八糟的东西,如果这样写的话字符数组定义要大一些。
3.推荐写法:char ch[11] = “helloworld”,把’\0’计算进数组长度中。
注意:凡是数组,尽量初始化!要不然数组的元素就会是随机值。
字符串数组输出
Printf(“%s\n”, a); //a是字符串数组的地址,也就是首字符的地址
字符串的输入
1、获取单个字符串
char ch[32] = {0};
scanf(“%s”, ch); //数组名本身就是地址,不需要再取地址
2、获取多个字符串
ch ch1[32] = {0}; char ch2[32] = {0};
scanf(“%s%s”, ch1, ch2); //两个%s之间不需要空格 但是输入的时候需要空格隔开
3、获取字符串和字符
char ch1[32] = {0}, ch;
scanf(“%s %c”, ch1, &ch); //%s和%c之间需要空格,输入的时候字符串和字符也需要空格
4、获取字符串和数字
char ch1[32] = {0}; int n;
scanf(“%s %d”, ch1, &n); //同上,都需要空格隔开
字符串处理函数
puts()输出字符串
1.函数原型:
int puts(const char *s);
作用:
其作用是将一个字符串(以′\0′结束的字符序列)输出到终端
用法:
char ch[32] = “helloworld”;
puts(ch);
类似的函数:
int putchar(int c);
注:这个很少用,我们一般都是直接用printf输出就行
gets()输入字符串
2.函数原型:
char *gets(char *s);
作用:
其作用是从终端输入一个字符串到字符数组,并且得到一个函数值。该函数返回值是字符数组的起始地址。它和scanf的区别是,scanf遇到空格结束,gets遇到换行才结束。(Linux下编译会出现警告,可用getchar代替)
用法:
char ch[32];
gets(ch); //可以输入带有空格的字符串,比如hello world
类似的函数:
int getchar(void);
注:这个也很少用,我们一般都是直接用scanf输入就行
strlen()计算字符串长度
3.函数原型:
size_t strlen(const char *s);
作用:
获取字符串的长度,遇到'\0'结束。
用法:
char str1[32] = “helloworld”; char str2[32] = “welcome\0tonanjing”;
printf(“%lu %lu\n”, strlen(str1), strlen(str2));
注:size_t就是unsigned long类型。
strcpy()将后面的字符串拷贝到前面的字符串数组里面
4.函数原型:
char *strcpy(char *dest, const char *src);
char *strncpy(char *dest, const char *src, size_t n);
作用:
把src指向的字符串拷贝到dest指向的内存中,包括字符串结尾的'\0'。
strncpy可以指定拷贝固定的字节。
用法:
char str1[32] = “helloworld”; char str2[32] = “welcome”;
strcpy(str1, str2); //str1变成了welcome
strncpy(str1, str2, 2); //str1变成了welloworld
size_t就是unsigned long类型。
注:数组的赋值,要么在定义的时候初始化,要么逐个元素赋值,要么拷贝
char str[32] = {0}; str = “helloworld”;//错误
笔试题12
问:以下程序输出的结果是什么?
char s3[32]=”helloworld”;
char s4[32]=”111111111222222222”;
strcpy(s4,s3);
printf(“%s\n”,s4);
答案是:helloworld
因为把s3拷贝到s4的时候把s3的结束标志’\0’也拷贝过去了,’\0’覆盖掉了一个第一个2,实际s4变成了helloworld\022222222,但是printf在输出的时候遇到’\0’就结束了,因此输出的结果我们只能看到helloworld。
如果我们不想要将’\0’拷贝过去,想把2也输出,可以用strncpy( )指定拷贝的长度,strncpy(s4,s3,10)指定拷贝长度为10,即不包含helloworld后面的’\0’。这样printf输出的时候就能把后面的2也输出了,最终我们看到的结果就是helloworld222222222
strcmp()比较字符串的大小
5.函数原型:
int strcmp(const char *s1, const char *s2);
int strncmp(const char *s1, const char *s2, size_t n);
作用:
比较s1指向的字符串和s2指向的字符串;(按字符的ASCII码比较,abcd小于acde)
strncmp指定比较固定的长度,即指定比较前几个字符。
用法:
char str1[32] = “helloworld”; char str2[32] = “welcome”;
strcmp(str1, str2); //结果小于0
返回值:
(如果前面的比后面的大)返回值大于0、(如果前面的比后面的小)返回值小于0、(如果前面的等于后面的)返回值等于0(如if(strcmp(str1, str2)==0) printf(“%s=%s\n”,s1,s2);)
strcat()将后面的字符串接到前面的字符串数组中
6.函数原型:
char *strcat(char *dest, const char *src);
char *strncat(char *dest, const char *src, size_t n);
作用:
把src指向的字符串接在dest指向的字符串后面(要求dest指向的内存空间足够大)
strncat连接指定长度的字符串。
用法:
char str1[32] = “helloworld”; char str2[32] = “welcome”;
strcat(str1, str2); //str1变成了helloworldwelcome
strncat(str1, str2, 2); //str1变成了helloworldwe
strchr()查找字符的位置
7.函数原型:
char *strchr(const char *s, int c);
char *strrchr(const char *s, int c);
作用:
查找字符c在字符串s中的位置,返回的是字符c的地址;
strrchr其实r就是reverse的意思,反向查找字符c在字符串s中的位置。
用法:
char str1[32] = “helloworld”; char ch = 'o';
strchr(str1, ch); //结果是第一个o的位置
strrchr(str1, ch) - str1; //结果是6
笔试题13
问:以下程序输出的什么?
char str1[32] = “helloworld”;
printf(“%s\n”,strchr(str1, ‘w’);
答案是:world
因为strchr(str1, ‘w’)返回的是‘w’的地址,而printf打印的是%s字符串,因此输出为world。
笔试题14
问:以下程序输出的什么?
char str1[32] = “helloworld”;
printf(“%s\n”,strrchr(str1, ‘o’);
答案是:orld
因为从后往前查找,直到找到第一个o,因此结果输出也会把o字符的右边的字符也printf输出。
注意:使用任何一个字符串处理函数都要包含头文件:#include <string.h>
笔试题15
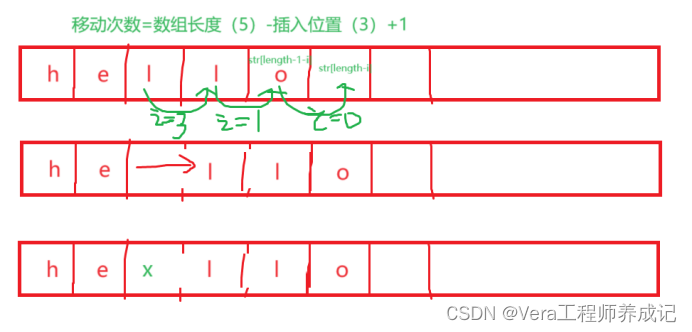
问:字符数组中在指定位置插入字符;(输入hello 3 x 输出hexllo)
我们可以把后面三个字符向后移动三位,然后将a放在第三个位置,然后将那三个字符赋值给后面三个位置。
参考代码:
#include <stdio.h>
#include <string.h>
int main()
{
int num;
int ch;
char str[32]={0};
int i;
printf("输入 字符串 插入位置 插入字符\n");
scanf("%s %d %c",str,&num,&ch);
int length=strlen(str);//计算字符串长度
for(i=0;i<length-num+1;i++)
{
str[length-i]=str[length-1-i]; //移动后三位字符
}
str[num-1]=ch;//插入字符
printf("%s\n",str);
return 0;
}运行结果:

函数
函数是一组一起执行一个任务的语句。每个 C 程序都至少有一个函数,即主函数 main() ,所有简单的程序都可以定义其他额外的函数。
库函数
别人已经实现好的函数,我们只要安装了对应的库可以直接拿过来用,比如printf strlen等等。
自定义函数
很多时候我们需要实现的功能并没有对应的函数,于是需要自己来实现
函数的格式
函数类型 函数名(形式参数类型说明表)
{
声明部分
执行部分
返回部分
}
例:
int func(int a, int b)//int是函数的类型 func是函数名 a b是形式参数
{
int sum; //声明部分
sum = a + b; //执行部分
return sum; //返回部分
}参数
形参:即形式参数,定义函数时函数名后面括号中的变量;如果没有定义形参,则表示函数可以接收任意个数的参数,而并非是没有形参。
实参:即实际参数,调用函数时函数名后面括号中的表达式。
实参--传递-->形参(值传递和地址传递)
注意:函数名就是地址,这个地址就是函数的入口地址。
函数调用过程
思考:函数调用过程是在怎么样的?
第一步:通过函数名找到函数的入口地址,然后程序就跳到函数的入口地址;
第二步:给形参分配空间;
第三步:传参(值传递和地址传递(如果是传一维数组,则传递数组名,传的只是首元素的地址,如果是传二维数组名,传的只是数组首行的地址));
第四步:执行函数体;
第五步:返回数据;
第六步:释放空间(栈空间:局部变量)
宏函数
可以把函数定义为宏,在编译的预处理阶段对函数直接展开。
#define PRINT printf(“helloworld\n”) //无参宏函数
调用:PRINT;
#define PRINT(S) printf(“%s\n”, S) //有参宏函数
调用:PRINT(“this is test...”);
宏函数和普通函数的优缺点
宏函数
优点:节省空间、执行效率高;
缺点:编译时间长、没有语法检查、不安全。
比如,#define PRINT(S) printf(“%s\n”, S) 调用:PRINT(1);这样会报警告,因为1和int型,不是字符。如果我们强制转换成char型PRINT((char)1);这样也能编译(没有语法检查),但是运行的时候会报警告:段错误,因为宏函数只是做一个简单的替换,将S替换成1,但是%s获取的空间是给字符串的,它会去1这个地方找字符串,但其实并没有1的地址,因为1的类型是char字符,也就是说内存中根本没有开辟1的空间,所以产生了段错误。
普通函数
优点:节省编译时间、有语法检查、执行更安全;
缺点:需要更多的空间、执行效率不高。
笔试题16
问:以下程序输出的结果是什么?
#define SQR(X) X * X
int main()
{
int m = 1, n = 2;
printf(“%d\n”, SQR(m + n));
return 0;
}答案是:5
很多人以为是3*3等于9,但并不是,因为宏函数替换的结果是1+2*1+2,由于运算符有优先级,编译器会优先编译2*1=2,,最终输出1+2+2=5。
结论:宏函数最好能加括号尽量加括号,如果#define SQR(X) X * X 加上括号的话就是#define SQR(X) (X) *(X),这样替换后括号还是存在的,结果是(1+2)*(1+2)这样输出才是9。
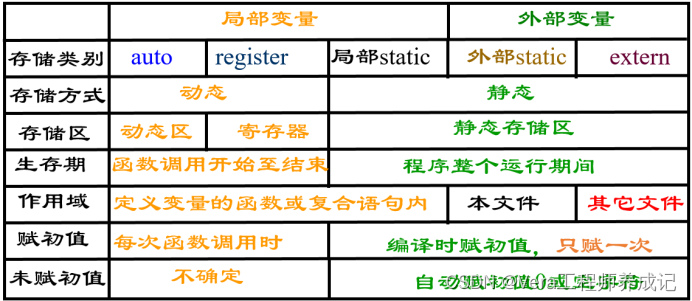
关键字(面试笔试重点)
auto
auto一般是我们定义局部变量的时候自带的。比如我们定义int a=0;的时候,其实int前面就省略了一个auto,一般我们都不写出来。
register
register翻译过来为寄存器的意思。比如说i++这个运算过程,首先寄存器要到内存中把i取出来进行操作,+1之后再把i放回到内存中,如果for循环10000次,那么就意味着寄存器要和内存交互上万次,那么为了程序的运行效率,我们通常在定义i的时候加上register,即register int i=0;这样i就变成了寄存器变量,也就是说我们直接把i放在寄存器里面,不放在内存中,当i要进行+1的时候,直接就在寄存器中操作了,就不用跟内存交互了。但是,这种寄存器变量不能进行取地址操作。C语言中,“&”这个符号取的是内存的地址,如果我们把变量放在寄存器中,那么这个变量就没有地址。
static、const、extern做笔试重点!
extern
extern声明外部变量;假设一个目录下有两个.c文件,如果在1.c文件里面定义了一个变量int num=100;,而2.c文件的程序也要访问这个变量,那么2.c文件可以加上extern int num;,告诉编译器这个变量在外部定义,即声明外部变量,注意在2.c声明外部变量时不能写成extern int num=100;这是声明和定义的区别,定义是要分配内存的,声明只是告诉编译器,而不需要分配内存。
static
static有三个作用;
1、如果定义了一个全局变量,那么该工程目录下的每一个.c文件都能使用它,那就会有安全隐患,如果不想让其他.c文件使用它,只能在本文件中使用,我们可以在全局变量前加上static,如static int num=100;这样即使别的文件加上extern声明了外部变量,也不能使用它了。因此static修饰全局变量,可以改变变量的作用域,只能在本文件被使用。
2、如果在一个函数前面加上static,那么这个函数也不能被其他.c文件使用,因此static也可以修饰函数,改变函数的作用域,只能在本文件中被调用。
3、当static在函数内修饰局部变量时,会改变局部变量的声明周期。比如当函数执行完之后该变量的空间不会被释放,下次进入该函数时,该变量的初值就会是上次执行完的结果。直到整个程序执行结束才会被释放。只要是因为局部变量不加static时是存放在栈空间,加static后是放在静态数据区。
const
const修饰只读变量;这个关键字是介于常量和变量之间的,很多人把它理解为是将变量定义为常量,但其实它是用来把变量定义为只读变量。将变量num定义成了只读变量,那就不能再直接通过num这个变量名来修改对应内存的值,如果硬改就会报错,我们可以通过地址(指针)来间接修改num对应内存的值。上次我们也具体讲过const了,不懂的可以去翻一翻。
补充命令5:“cat *”在终端中查看当前目录下所有文件内的内容
cat *表示在终端中查看当前目录下所有文件内的内容,不如extern目录下有两个文件1.c 和2.c,那么我们在Linux终端的extern目录下输入cat *,就会在终端面板上同时显示1.c 和2.c的内容。
补充命令6:“gcc 文件名1 文件名2 -o main”同时编译两个文件
像上面这种一个工程目录下有多个.c文件的话,我们可以放在一起编译。“gcc 文件名1 文件名2 -o main”就是编译文件1和文件2,编译的结果放在main文件中。
补充命令7:Ctrl+S锁定编辑器Ctrl+Q打开编辑
如果你在vim编译器中写代码,不小心按了Ctrl+S就会被锁定不能编译代码,可以按Ctrl+Q打开。
下节开始学习指针(初级)!
如有问题可评论区或者私信留言,如果想要进交流群请私信!

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 14
14 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)