
视觉深度学习:提高图像分类中的模型准确性
由于大多数视觉数据集都具有一些共同特征,因此可以采用在类似数据集上训练的网络,并使用训练后的特征来减少在不同数据集上的训练时间。我们可以将知识从在复杂任务上训练的网络转移到更简单的网络,或者从在大量数据上训练的网络转移到数据较少的网络。因此,迁移学习是多任务学习的潜在关键,多任务学习是深度学习的一个活跃研究领域。在此图中可以看到提前停止的想法。这是记忆训练数据和泛化到看不见的数据之间的平衡,找到正

概述
提高图像分类精度是深度学习的最大障碍之一。除了使用更深的网络和更好的数据外,还开发了许多技术来优化网络性能。一些技术(如 Dropout)针对架构本身的训练瓶颈,而其他技术(如正则化)则更侧重于改进整体管道。
先决条件
在进入实际代码之前,我们必须了解一些先决条件术语。它们在这里解释。
- 了解训练、测试和验证数据拆分。
- 对图像分类概念的理解。
- 熟悉简单的神经网络架构。
- 如上所述,了解深度学习中的挑战。
介绍
在深度学习中,由于资源有限、计算能力或数据访问等限制,有时才有可能拥有大量数据和复杂模型。这些挑战可能使模型难以很好地泛化并导致过度拟合,即模型变得过于复杂并记住训练数据,从而导致在看不见的数据上性能不佳。在这种情况下,正则化和迁移学习技术可以优化训练时间并弥补数据的不足。此外,Dropout 和 Early Stopping 等算法可以帮助解决过拟合问题。
本文介绍了可以提高图像分类模型准确性的各种算法和流水线调整。通过了解这些技术,我们可以有效地应对培训过程中出现的挑战并取得更好的结果。
提高模型精度
训练神经网络的两个最大障碍是过拟合和欠拟合。在第一种情况下,网络会记住数据;其次,网络需要学习更多。根据这两个概念,可以将以下技术分为几类。 Dropout 层、数据增强、正则化、早期停止、解决过拟合问题。迁移学习和超参数调优可解决欠拟合问题。 如果缺少数据,我们可以使用迁移学习和数据增强。如果模型失败,可以试验其他算法。 以下各节将介绍所有这些算法。
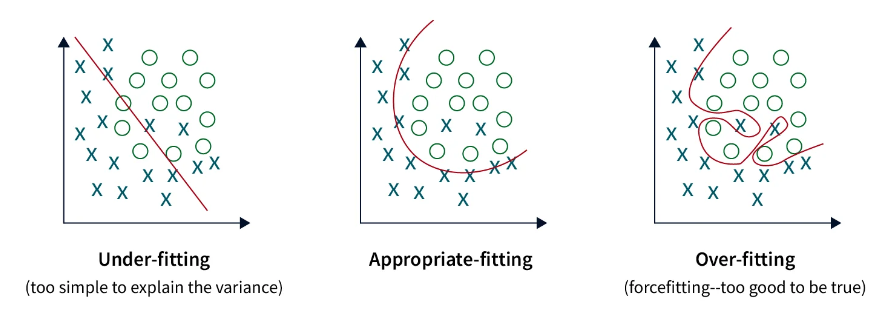
过拟合和欠拟合
重要的是要记住,过拟合和欠拟合不是二元状态,而是一个连续体。这是记忆训练数据和泛化到看不见的数据之间的平衡,找到正确的平衡可能很困难,需要实验。除了过拟合和欠拟合之外,我们还应该监控其他指标,例如准确性、精确度、召回率和训练期间的损失。这些挑战使得训练神经网络成为一种平衡行为。
- 训练准确性是模型在训练/测试数据拆分期间的准确性。
- 验证准确性是模型在模型从未见过的真实数据上进行测试时的性能。
- 当训练精度远高于许多时期的验证精度时,就会发生过拟合。
- 当模型过于关注训练数据而无法预测尚未看到的任何样本时,就会发生欠拟合。
如果训练精度非常低,并且验证精度似乎波动或远高于训练精度,则称为欠拟合。在欠拟合中,模型必须更强大才能拟合数据。 过拟合和欠拟合都可以通过多种方式进行抵消,但需要注意的是,它们具有微妙的平衡。了解网络正在经历哪些事件对于提高图像分类准确性至关重要。
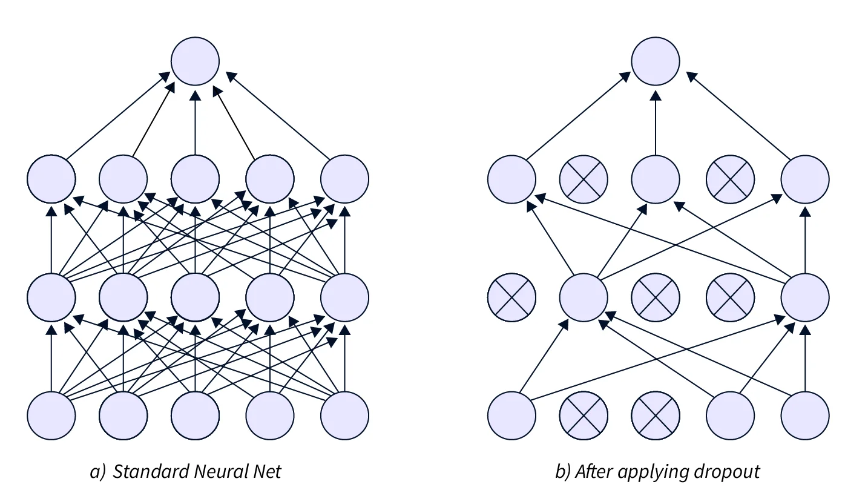
Dropout 图层
当网络中的单个单元计算误差梯度时,它还会考虑其他单元并尝试修复它们的错误。这种依赖关系被称为协同适应,并导致形成鼓励过拟合的复杂关系。辍学层通过随机(概率 p)将神经元激活设置为 0 来减少网络中神经元之间的相互依赖性。此图层应用于网络中的密集(完全连接)图层。 Dropout 有助于处理较小的数据集,而略微有助于处理较大的数据集。如果数据集较大,则 Dropout 可以在恢复更多信息时提高性能。同样,如果数据集太大,模型性能也可能变差。 在测试过程中,权重按概率 p 进行缩放。
数据增强
神经网络对数据的需求非常大,训练它们需要许多训练示例。当然,只有有时才有可能拥有大量的训练数据。我们可以使用数据增强来人为地扩展可用示例的数量。数据增强是以不同的方式多次调整给定示例以从现有图像生成新的训练样本的过程。图像数据增强的一些示例包括随机翻转、抖动亮度/对比度、随机调整大小和随机裁剪。 下面显示了一些数据增强技术。

数据增强是提高图像分类准确率的好方法。这种技术不仅限于图像;我们可以将类似的概念应用于其他所有数据域。数据增强还具有作为正则化器的额外好处,即从不同角度显示模型数据。
正规化
神经网络在训练过程中面临的最大挑战之一是过拟合。惩罚在训练期间表现更好但在验证期间表现不佳的复杂模型是减少过拟合影响的一种方法。训练神经网络的目的是将它们用于训练集之外的真实数据。对学习过多训练集的模型进行惩罚称为正则化。正则化项用于控制应用于模型的惩罚。此术语也是一个超参数,因为过多地增加它可能会损害模型性能。 许多算法在训练过程中会进行正则化,例如数据增强、提前停止、丢弃等。
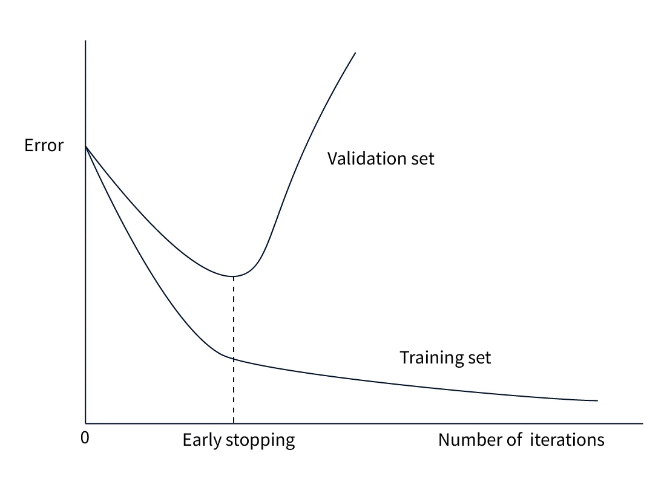
提早停止
早期停止是一种正则化技术,通过在验证损失增加时有意停止训练来提高图像分类准确性。训练将停止,因为训练模型的时间过多,有时会导致过度拟合。在“提前停止”中,纪元数变为可调超参数。我们在训练期间不断存储最佳参数,当这些参数在几个时期内不再变化时,我们就会停止训练。 在此图中可以看到提前停止的想法。
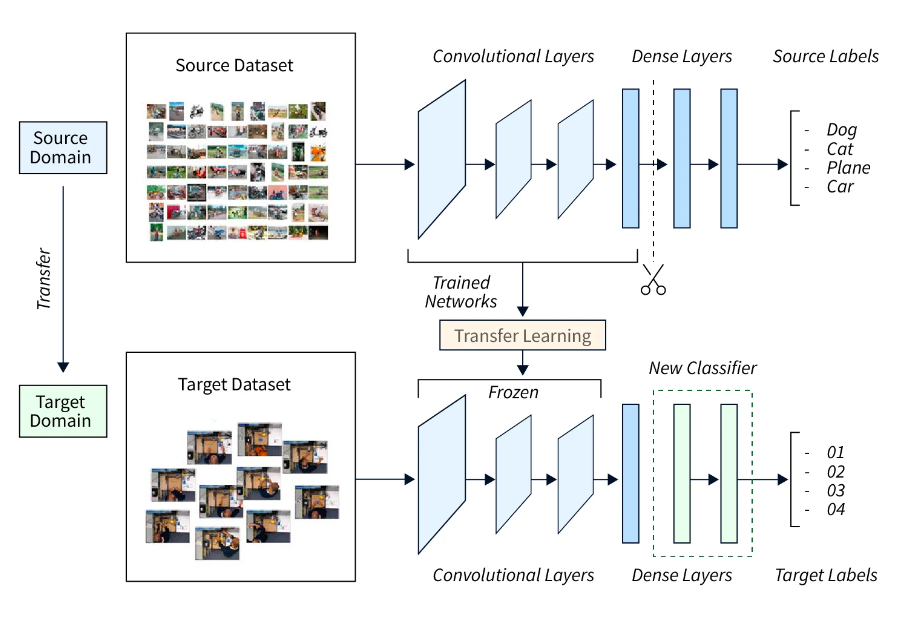
迁移学习
训练大型图像模型既费时又费力。由于大多数视觉数据集都具有一些共同特征,因此可以采用在类似数据集上训练的网络,并使用训练后的特征来减少在不同数据集上的训练时间。 迁移学习是一个过程,它允许将预训练的模型用作特征提取器或权重初始值设定项。在大多数情况下,迁移学习用于微调。我们可以将知识从在复杂任务上训练的网络转移到更简单的网络,或者从在大量数据上训练的网络转移到数据较少的网络。 因此,迁移学习是多任务学习的潜在关键,多任务学习是深度学习的一个活跃研究领域。该技术也是以更少的数据快速提高图像分类精度的关键。 下图显示了使用迁移学习提高图像分类准确性背后的概念。
超参数调优
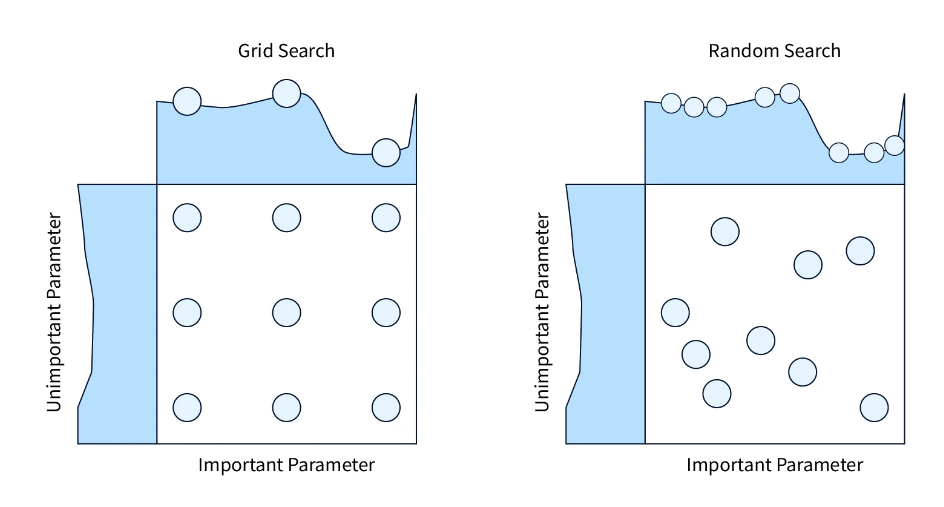
每个 DL 模型和训练管道都有参数,我们可以对其进行调整以优化性能。参数可以包括 - 训练网络的 epoch 数、权重衰减、优化器、学习率等。每个超参数可以有多个值,这些值会迅速加起来,形成数百个或更多不同的案例。 超参数调优是调整这些参数以快速创建最佳模型的艺术。我们只能测试一些参数,但优化服务可以估计要保留哪些超参数以及要丢弃哪些超参数。许多算法都支持这样的服务,包括对超参数空间的网格搜索。如果所讨论的超参数降低了模型性能,则会将其删除,有时类似的超参数也会被删除。 超参数调优是一个具有挑战性的问题,因为每个任务都需要不同的要求。调整数百个参数是选择之间的平衡行为。 该技术是导致提高图像分类准确性的管道的最后一部分。
结论
- 在本文中,我们了解了其他算法在提高图像分类准确性方面的重要性。
- 我们研究了过拟合和欠拟合的概念,并了解了它们如何影响模型训练。
- 我们还研究了许多算法,这些算法通过修改架构或改变我们训练网络的方式来提高性能。
- 我们了解在缺乏数据时应使用哪些技术。
- 我们还通过调整现有模型的超参数来提高其性能。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 15
15 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)