
如何在本地搭建部署Deep Seek大模型智能体?
如何在本地搭建部署Deep Seek大模型智能体?部署大型模型通常需要安装Python环境和必要的深度学习框架,比如PyTorch。然后,用户需要获取模型的权重文件,这可能涉及到申请权限或者从官方渠道下载。接下来,设置模型的环境变量和依赖库,比如transformers库。可能还需要安装CUDA和cuDNN来支持GPU加速。
如何在本地搭建部署Deep Seek大模型智能体?
AI回答
好的,用户想在本地的环境中部署Deep Seek大模型,需要一份详细的教程或指南。首先,我需要确认用户的具体需求,例如他们是否有GPU资源,操作系统是什么,以及是否有相关的机器学习基础。不过,用户可能没有明确提到这些细节,所以需要假设他们使用的是常见的Linux环境,并拥有NVIDIA
GPU。
首先,部署大型模型通常需要安装Python环境和必要的深度学习框架,比如PyTorch。然后,用户需要获取模型的权重文件,这可能涉及到申请权限或者从官方渠道下载。接下来,设置模型的环境变量和依赖库,比如transformers库。可能还需要安装CUDA和cuDNN来支持GPU加速。
用户可能遇到的问题包括依赖项冲突、GPU内存不足、或者模型文件下载困难。因此,在步骤中需要包含虚拟环境的创建,以及如何分步验证安装是否正确。此外,示例代码需要简洁明了,帮助用户快速测试模型是否正常运行。
还需要考虑模型的具体版本,例如Deep Seek是否有不同的模型尺寸(如7B、13B等),不同版本对硬件的要求不同。用户可能需要调整batch size或者使用量化技术来减少内存占用。另外,部署时可能需要用到推理加速框架,如vLLM或DeepSpeed,这些也需要在教程中提及。
最后,生成的相关问题需要覆盖用户可能遇到的后续疑问,比如性能优化、硬件要求、模型微调等。确保回答中引用的来源可靠,例如官方文档或社区推荐的优化方法。
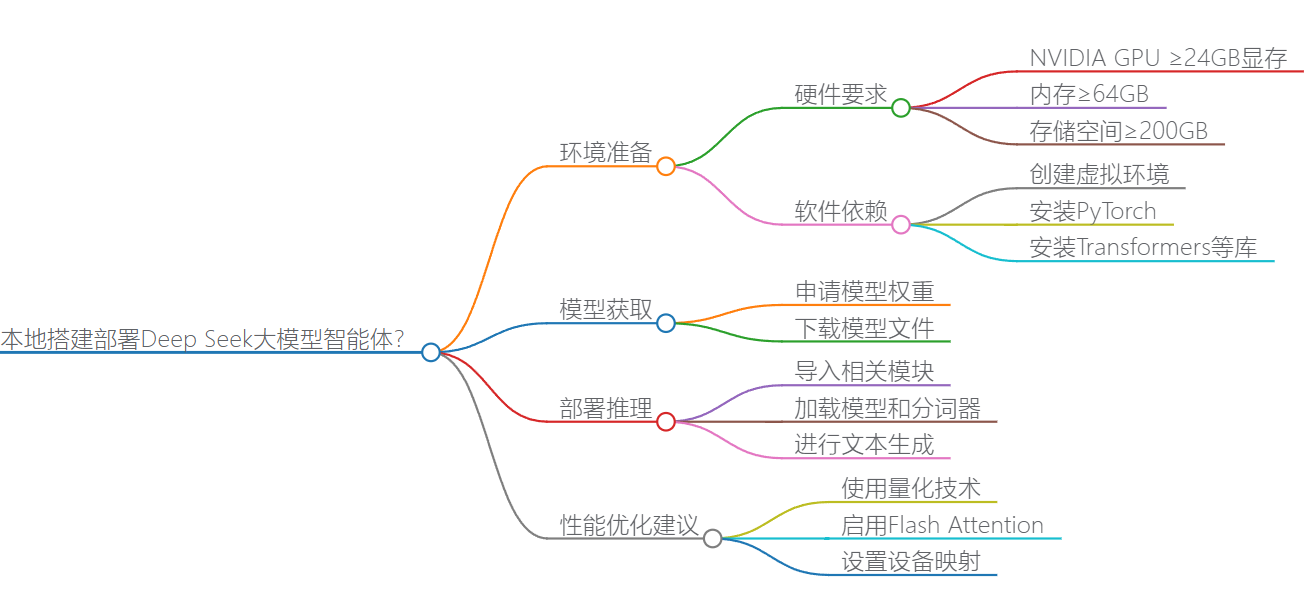
本地部署Deep Seek大模型的步骤指南
一、环境准备
硬件要求:
推荐使用NVIDIA GPU(如A100/V100/RTX 3090)显存≥24GB
内存建议≥64GB,存储空间≥200GB(模型文件约60-180GB)1
软件依赖:
# 创建虚拟环境
conda create -n deepseek python=3.10
conda activate deepseek
# 安装基础框架
pip install torch==2.1.0+cu121 torchvision==0.16.0+cu121 --extra-index-url https://download.pytorch.org/whl/cu121
pip install transformers>=4.33 accelerate sentencepiece
二、模型获取
访问 https://www.deepseek.com/models 申请模型权重
下载模型文件(示例结构):
deepseek-llm-7b-base/
├── config.json
├── pytorch_model.bin
└── tokenizer.model
三、部署推理
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "/path/to/deepseek-llm-7b-base"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype=torch.float16
)
inputs = tokenizer("人工智能的未来发展", return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(outputs[0]))
四、性能优化建议
使用量化技术降低显存占用:model=model.to(torch.bfloat16)
启用Flash Attention加速计算:
pip install flash-attn --no-build-isolation
思维导图

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 4
4 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)