
人工智能/机器学习基础知识——生成对抗网络系列(Generative Adversarial Networks,GAN)
人工智能/机器学习基础知识——生成对抗网络系列(Generative Adversarial Networks,GAN)
生成对抗网络系列
Generative Adversarial Networks(GAN)
Paper : Generative Adversarial Networks
生成对抗网络
Discriminator Network
判别网络
-
判别网络 D ( x ; ϕ ) D(\boldsymbol{x} ; \phi) D(x;ϕ)的目标是区分出一个样本是否来自于真实分布还是来自于生成网络生成的数据,所以判别网络是一个二分类器
-
给定一个样本 ( x , y ) , y = 1 , 0 (x,y), y = {1,0} (x,y),y=1,0表示其来自于真实样本或生成样本,判别网络的损失函数为交叉熵
min ϕ − ( E x [ y log p ( y = 1 ∣ x ) + ( 1 − y ) log p ( y = 0 ∣ x ) ] ) \min _{\phi}-\left(\mathbb{E}_{x}[y \log p(y=1 \mid \boldsymbol{x})+(1-y) \log p(y=0 \mid \boldsymbol{x})]\right) ϕmin−(Ex[ylogp(y=1∣x)+(1−y)logp(y=0∣x)])
- 若训练中判别网络输入的样本数据由真实样本和生成样本各参半混合而成,则损失函数等价于
max ϕ E x ∼ p r ( x ) [ log D ( x ; ϕ ) ] + E x ′ ∼ p θ ( x ′ ) [ log ( 1 − D ( x ′ ; ϕ ) ) ] = max ϕ E x ∼ p r ( x ) [ log D ( x ; ϕ ) ] + E z ∼ p ( z ) [ log ( 1 − D ( G ( z ; θ ) ; ϕ ) ) ] \begin{aligned} & \max _{\phi} \mathbb{E}_{x \sim p_{r}(x)}[\log D(\boldsymbol{x} ; \phi)]+\mathbb{E}_{\boldsymbol{x}^{\prime} \sim p_{\theta}\left(x^{\prime}\right)}\left[\log \left(1-D\left(\boldsymbol{x}^{\prime} ; \phi\right)\right)\right] \\ =& \max _{\phi} \mathbb{E}_{\boldsymbol{x} \sim p_{r}(x)}[\log D(\boldsymbol{x} ; \phi)]+\mathbb{E}_{\boldsymbol{z} \sim p(z)}[\log (1-D(G(\boldsymbol{z} ; \theta) ; \phi))] \end{aligned} =ϕmaxEx∼pr(x)[logD(x;ϕ)]+Ex′∼pθ(x′)[log(1−D(x′;ϕ))]ϕmaxEx∼pr(x)[logD(x;ϕ)]+Ez∼p(z)[log(1−D(G(z;θ);ϕ))]
其中 θ \theta θ和 ϕ \phi ϕ分别是生成网络和判别网络的参数
Generator Network
生成网络
-
生成网络的目标是生成让判别网络判别为真实样本的生成样本,损失函数为
max θ ( E z ∼ p ( z ) [ log D ( G ( z ; θ ) ; ϕ ) ] ) = min θ ( E z ∼ p ( z ) [ log ( 1 − D ( G ( z ; θ ) ; ϕ ) ) ] ) \begin{aligned} & \max _{\theta}\left(\mathbb{E}_{z \sim p(z)}[\log D(G(\boldsymbol{z} ; \theta) ; \phi)]\right) \\ =& \min _{\theta}\left(\mathbb{E}_{z \sim p(z)}[\log (1-D(G(\boldsymbol{z} ; \theta) ; \phi))]\right) \end{aligned} =θmax(Ez∼p(z)[logD(G(z;θ);ϕ)])θmin(Ez∼p(z)[log(1−D(G(z;θ);ϕ))])
min θ ( E z ∼ p ( z ) [ − log D ( G ( z ; θ ) ; ϕ ) ] ) \min _{\theta}\left(\mathbb{E}_{z \sim p(z)}[-\log D(G(\boldsymbol{z} ; \theta) ; \phi)]\right) θmin(Ez∼p(z)[−logD(G(z;θ);ϕ)])
-
上述两个目标函数其实是等价的,但实际一般选择前者,因为其梯度性质更好。 l o g log log函数在x接近于1时的梯度要比接近0时的梯度小很多。当判别网络 D D D以很高的概率认为生成网络 G G G产生的样本是“假”样本(往往发生在训练初期),即 ( 1 − D ( G ( z ; θ ) ; ϕ ) ) → 1 (1-D(G(z ; \theta) ; \phi)) \rightarrow 1 (1−D(G(z;θ);ϕ))→1,这时目标函数关于 θ \theta θ的梯度相对很小,从而不利于优化。
-
可以将 D ( G ( z ; θ ) ; ϕ ) D(G(\boldsymbol{z} ; \theta) ; \phi) D(G(z;θ);ϕ)与 ( 1 − D ( G ( z ; θ ) ; ϕ ) ) (1-D(G(\boldsymbol{z} ; \theta) ; \phi)) (1−D(G(z;θ);ϕ))分别看成一个整体 y y y,从而损失函数对模型参数 θ \theta θ的导数可以看成先对 log y \log{y} logy求导,再乘上 y y y对 θ \theta θ求导。而 y y y对 θ \theta θ求导的结果绝对值是一样的,正好对应max和min。损失函数对 y y y的导数在使用后者作为损失函数时,且当 ( 1 − D ( G ( z ; θ ) ; ϕ ) ) → 1 (1-D(G(z ; \theta) ; \phi)) \rightarrow 1 (1−D(G(z;θ);ϕ))→1时,梯度接近于 l o g log log函数 x = 1 x=1 x=1处的导数值,较小,优化力度小
-
这种梯度优化手段还可通过交换真实与生成样本的标签来实现,即真实样本标签改为 0 0 0,生成样本标签改为 1 1 1
-
训练
-
GAN的训练比较难,往往不太稳定,因为两个网络的优化目标刚好相反。一般情况下,需要平衡两个网络的能力。对于判别网络来说,一开始的判别能力不能太强,否则难以提升生成网络的能力。但是,判别网络的判别能力也不能太弱,否则针对它训练的生成网络也不会太好。在训练时需要使用一些技巧,使得在每次迭代中,判别网络比生成网络的能力强一些,但又不能强太多。
-
训练流程如下所示:每次迭代时,判别网络更新K次(超参数),而生成网络更新一次,即首先要保证判别网络足够强才能开始训练生成网络。

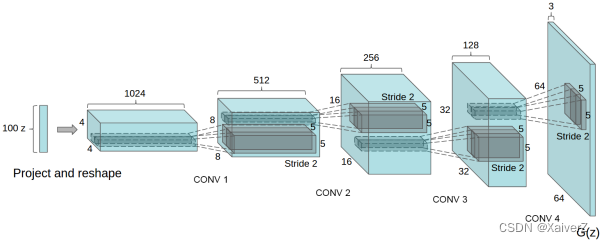
Deep Convolutional Generative Adversarial Network(DCGAN)
Paper : Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
深度卷积生成对抗网络
-
判别网络为一个简单的DNN
-
生成网络使用微步卷积来实现。最开始的输入为从均匀分布中随机采样的100维向量 z z z,通过全连接层将其映射到 4 × 4 × 1024 4×4×1024 4×4×1024的维度上
GAN Training Problem
Paper : TOWARDS PRINCIPLED METHODS FOR TRAINING GENERATIVE ADVERSARIAL NETWORKS
本部分分析GAN的训练问题
Training Stability
训练稳定性
-
GAN的判别器 D D D的目标函数为最大化如下式子,即尽可能将真实样本分成正例,将生成样本分成负例
max { E x ∼ P r [ log D ( x ) ] + E x ∼ P g [ log ( 1 − D ( x ) ) ] } \max{\{\mathbb{E}_{x \sim \mathbb{P}_{r}}[\log D(x)]+\mathbb{E}_{x \sim \mathbb{P}_{g}}[\log (1-D(x))]\}} max{Ex∼Pr[logD(x)]+Ex∼Pg[log(1−D(x))]}
其中 P r P_r Pr为真实样本分布, P g P_g Pg为生成器产生的样本分布 -
GAN的生成器 G G G的目标函数为最小化如下式子,即尽生成样本能尽可能欺骗过判别器,使其判断为真实样本
min { E x ∼ P g [ log ( 1 − D ( x ) ) ] } \min{\{\mathbb{E}_{x \sim P_{g}}[\log (1-D(x))]\}} min{Ex∼Pg[log(1−D(x))]}
-
从判别器 D D D的损失函数我们可以推出,当 P r P_r Pr与 P g P_g Pg固定时,即生成器参数不变时,最优的判别器 D D D应该是怎样的,判别器的损失函数可以等价为最大化如下式子
m a x { P r ( x ) log [ D ( x ) ] + P g ( x ) log [ 1 − D ( x ) ] } max{\{P_{r}(x) \log [D(x)]+P_{g}(x) \log [1-D(x)]\}} max{Pr(x)log[D(x)]+Pg(x)log[1−D(x)]}
- 令上式关于 D ( x ) D(x) D(x)的导数为零
P r ( x ) D ( x ) − P g ( x ) 1 − D ( x ) = 0 \frac{P_{r}(x)}{D(x)}-\frac{P_{g}(x)}{1-D(x)}=0 D(x)Pr(x)−1−D(x)Pg(x)=0
得到最优判别器D ∗ ( x ) = P r ( x ) P r ( x ) + P g ( x ) D^{*}(x)=\frac{P_{r}(x)}{P_{r}(x)+P_{g}(x)} D∗(x)=Pr(x)+Pg(x)Pr(x)
其中,判别器 D ( x ) D(x) D(x)输入样本 x x x,输出该样本来自真实分布的概率- 给生成器的目标函数加上一个与生成器无关的项
min { E x ∼ P r [ log D ( x ) ] + E x ∼ P g [ log ( 1 − D ( x ) ) ] } \min{\{\mathbb{E}_{x \sim P_{r}}[\log D(x)]+\mathbb{E}_{x \sim P_{g}}[\log (1-D(x))]\}} min{Ex∼Pr[logD(x)]+Ex∼Pg[log(1−D(x))]}
最小化上式等价于最小化生成器的目标函数- 为了探究当判别器 D D D最优时,会对生成器 G G G的训练有什么影响,将 D ∗ ( x ) D^{*}(x) D∗(x)代入上式
min { E x ∼ P r log P r ( x ) 1 2 [ P r ( x ) + P g ( x ) ] + E x ∼ P g log P g ( x ) 1 2 [ P r ( x ) + P g ( x ) ] − 2 log 2 } = min { 2 J S ( P r ∥ P g ) − 2 log 2 } \min{\{\mathbb{E}_{x \sim P_{r}} \log \frac{P_{r}(x)}{\frac{1}{2}\left[P_{r}(x)+P_{g}(x)\right]}+\mathbb{E}_{x \sim P_{g}} \log \frac{P_{g}(x)}{\frac{1}{2}\left[P_{r}(x)+P_{g}(x)\right]}-2 \log 2\}} = \min{\{2 J S\left(P_{r} \| P_{g}\right)-2 \log 2\}} min{Ex∼Prlog21[Pr(x)+Pg(x)]Pr(x)+Ex∼Pglog21[Pr(x)+Pg(x)]Pg(x)−2log2}=min{2JS(Pr∥Pg)−2log2}
所以,当判别器 D D D越接近最优,生成器 G G G的目标函数就越等价于最小化 P r P_{r} Pr与 P g P_{g} Pg的JS散度。当两个分布越接近时,JS散度的值越小;当两个分布完全相同时,其JS散度为0。但JS散度存在一个问题,当两个分布完全不相关不重叠(或有部分可忽略的小范围重叠)时,JS散度的值为一个常数。-
由 K L ( P 1 ∥ P 2 ) = E x ∼ P 1 log P 1 P 2 K L\left(P_{1} \| P_{2}\right)=\mathbb{E}_{x \sim P_{1}} \log \frac{P_{1}}{P_{2}} KL(P1∥P2)=Ex∼P1logP2P1与 J S ( P 1 ∥ P 2 ) = 1 2 K L ( P 1 ∥ P 1 + P 2 2 ) + 1 2 K L ( P 2 ∥ P 1 + P 2 2 ) J S\left(P_{1} \| P_{2}\right)=\frac{1}{2} K L\left(P_{1} \| \frac{P_{1}+P_{2}}{2}\right)+\frac{1}{2} K L\left(P_{2} \| \frac{P_{1}+P_{2}}{2}\right) JS(P1∥P2)=21KL(P1∥2P1+P2)+21KL(P2∥2P1+P2)可知,当两个分布 P 1 P_1 P1, P 2 P_2 P2无重叠或重叠部分可忽略时,有如下四种情况
-
P 1 ( x ) = 0 , P 2 ( x ) = 0 P_1(x)=0, P_2(x)=0 P1(x)=0,P2(x)=0
-
P 1 ( x ) ≠ 0 , P 2 ( x ) ≠ 0 P_1(x)\neq0, P_2(x)\neq0 P1(x)=0,P2(x)=0
-
P 1 ( x ) = 0 , P 2 ( x ) ≠ 0 P_1(x)=0, P_2(x)\neq0 P1(x)=0,P2(x)=0
-
P 1 ( x ) ≠ 0 , P 2 ( x ) = 0 P_1(x)\neq0, P_2(x)=0 P1(x)=0,P2(x)=0
-
-
第一种情况下JS散度为 0 0 0;第二种情况由于重叠可忽略所以JS散度也为 0 0 0;第三种情况JS散度为 log 2 \log{2} log2;第四种情况类似JS散度为 log 2 \log{2} log2
-
因此,在近似最优判别器条件下,最小化生成器的目标函数等价于最小化 P r P_{r} Pr与 P g P_{g} Pg之间的JS散度,而由于 P r P_{r} Pr与 P g P_{g} Pg几乎不可能有不可忽略重叠(特别是在训练刚开始时)(详见知乎解释),所以无论它们相距多远JS散度都是常数 log 2 \log{2} log2,最终导致生成器的梯度接近于0,生成器梯度消失
-
综上,GAN训练不稳定的原因如下
-
判别器训练地太好,生成器梯度消失,Loss降不下去
-
判别器训练得不好,生成器梯度不准
-
只有当判别器训练地不好不坏才行,但这个程度很难把握,因此GAN很难训练
-
Model Collapse
模型坍塌
-
生成器 G G G的目标函数可以等价地写成
min { E x ∼ P g [ − log D ( x ) ] } \min{\{\mathbb{E}_{x \sim P_{g}}[-\log D(x)]\}} min{Ex∼Pg[−logD(x)]}
将最优判别器 D ∗ ( x ) D^{*}(x) D∗(x)代入上式E x ∼ P g [ − log D ∗ ( x ) ] = K L ( P g ∥ P r ) − E x ∼ P g log [ 1 − D ∗ ( x ) ] = K L ( P g ∥ P r ) − 2 J S ( P r ∥ P g ) + 2 log 2 + E x ∼ P r [ log D ∗ ( x ) ] \begin{aligned} \mathbb{E}_{x \sim P_{g}}\left[-\log D^{*}(x)\right] &=K L\left(P_{g} \| P_{r}\right)-\mathbb{E}_{x \sim P_{g}} \log \left[1-D^{*}(x)\right] \\ &=K L\left(P_{g} \| P_{r}\right)-2 J S\left(P_{r} \| P_{g}\right)+2 \log 2+\mathbb{E}_{x \sim P_{r}}\left[\log D^{*}(x)\right] \end{aligned} Ex∼Pg[−logD∗(x)]=KL(Pg∥Pr)−Ex∼Pglog[1−D∗(x)]=KL(Pg∥Pr)−2JS(Pr∥Pg)+2log2+Ex∼Pr[logD∗(x)]
注意到最后两项不依赖于生成器 G G G,所以最小化上式等价于最小化min { K L ( P g ∥ P r ) − 2 J S ( P r ∥ P g ) } \min{\{K L\left(P_{g} \| P_{r}\right)-2 J S\left(P_{r} \| P_{g}\right)\}} min{KL(Pg∥Pr)−2JS(Pr∥Pg)}
-
最小化上式等价于最小化 P r P_{r} Pr与 P g P_{g} Pg之间的KL散度,同时又要最大化两者的JS散度,直观上就非常的不靠谱。JS散度的问题前述已经讨论过,下面讨论KL散度的问题。
-
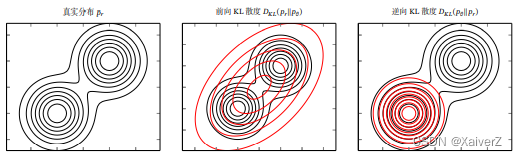
由于KL散度是一种非对称的散度,在计算 P r P_r Pr与 P g P_g Pg之间的KL散度时,按照顺序的不同,存在两种KL散度:(假设真实分布 P r P_r Pr为混合高斯分布,生成器样本分布 P g P_g Pg为高斯分布)
-
前向KL散度
Forward KL Divergence
K L ( P r , P g ) = ∫ P r ( x ) log P r ( x ) P g ( x ) d x \mathrm{KL}\left(P_r, P_g\right)=\int P_r(\boldsymbol{x}) \log \frac{P_r(\boldsymbol{x})}{P_g(\boldsymbol{x})} \mathrm{d} \boldsymbol{x} KL(Pr,Pg)=∫Pr(x)logPg(x)Pr(x)dx
-
当 P r ( x ) → 0 P_r(x) \rightarrow 0 Pr(x)→0, P g ( x ) > 0 P_g(x) > 0 Pg(x)>0时,KL散度为 0 0 0
-
当 P r ( x ) > 0 P_r(x) > 0 Pr(x)>0, P g ( x ) → 0 P_g(x) \rightarrow 0 Pg(x)→0时,KL散度趋于无穷大
-
在前向KL散度中,第二种情况会使 P g P_g Pg会倾向于生成更多多样性样本,覆盖 P r P_r Pr的整个分布区域;第一种情况会使 P g P_g Pg覆盖 P r P_r Pr分布之外的邻近区域,因为这不会造成KL散度增大
-
-
逆向KL散度
Reverse KL Divergence
K L ( P g , P r ) = ∫ P g ( x ) log P g ( x ) P r ( x ) d x \mathrm{KL}\left(P_g, P_r\right)=\int P_g(\boldsymbol{x}) \log \frac{P_g(\boldsymbol{x})}{P_r(\boldsymbol{x})} \mathrm{d} \boldsymbol{x} KL(Pg,Pr)=∫Pg(x)logPr(x)Pg(x)dx
-
当 P r ( x ) → 0 P_r(x) \rightarrow 0 Pr(x)→0, P g ( x ) > 0 P_g(x) > 0 Pg(x)>0时,KL散度趋于无穷大
-
当 P r ( x ) > 0 P_r(x) > 0 Pr(x)>0, P g ( x ) → 0 P_g(x) \rightarrow 0 Pg(x)→0时,KL散度为 0 0 0
-
在逆向KL散度中,第一种情况使 P g P_g Pg会倾向于生成更“安全”的样本,避免覆盖到 P r P_r Pr无分布或分布中较稀疏的区域;第二种情况使 p g p_g pg对 P r P_r Pr的分布区域不敏感,就算 P r P_r Pr有分布的区域,若 P g P_g Pg无分布,KL散度也不会增大。
-
-
-
由前述分析可知,在最优判别器条件下,生成器实际上最小化的是分布 P r P_r Pr与 P g P_g Pg的逆向KL散度,因此会使生成器倾向于生成一些更“安全”的样本,减少了样本多样性,产生模型坍塌(Model Collapse)
-
Wasserstein GAN
WGAN
-
WGAN是一种使用(1st)Wasserstein距离来代替JS散度优化GAN的训练过程
W ( P r , P g ) = inf γ ∼ Π ( P r , P g ) E ( x , y ) ∼ γ [ ∥ x − y ∥ ] W\left(P_{r}, P_{g}\right)=\inf _{\gamma \sim \Pi\left(P_{r}, P_{g}\right)} \mathbb{E}_{(x, y) \sim \gamma}[\|x-y\|] W(Pr,Pg)=γ∼Π(Pr,Pg)infE(x,y)∼γ[∥x−y∥]
其中 Π ( P r , P g ) \Pi\left(P_{r}, P_{g}\right) Π(Pr,Pg)是所有可能的联合分布的集合- 两个分布 P r P_r Pr和 P g P_g Pg的Wasserstein距离往往难以计算,作者用了一个已有定理将其等价替换为如下形式
W ( P r , P g ) = 1 K sup ∥ f ∥ L ≤ K E x ∼ P r [ f ( x ) ] − E x ∼ P g [ f ( x ) ] W\left(P_{r}, P_{g}\right)=\frac{1}{K} \sup _{\|f\|_{L} \leq K} \mathbb{E}_{x \sim P_{r}}[f(x)]-\mathbb{E}_{x \sim P_{g}}[f(x)] W(Pr,Pg)=K1∥f∥L≤KsupEx∼Pr[f(x)]−Ex∼Pg[f(x)]
其中 ∥ f ∥ L ≤ K \|f\|_{L} \leq K ∥f∥L≤K表示函数 f f f的Lipschitz常数 ∥ f ∥ L \|f\|_{L} ∥f∥L要小于 K K K -
评价网络
Critic Network
- 我们可以用一组参数 w w w来定义一系列可能的函数 f w f_w fw,求解上式可近似为求解
K ⋅ W ( P r , P g ) ≈ max w : ∣ f w ∣ L ≤ K E x ∼ P r [ f w ( x ) ] − E x ∼ P g [ f w ( x ) ] K \cdot W\left(P_{r}, P_{g}\right) \approx \max _{w:\left|f_{w}\right|_{L} \leq K} \mathbb{E}_{x \sim P_{r}}\left[f_{w}(x)\right]-\mathbb{E}_{x \sim P_{g}}\left[f_{w}(x)\right] K⋅W(Pr,Pg)≈w:∣fw∣L≤KmaxEx∼Pr[fw(x)]−Ex∼Pg[fw(x)]
其中 f w f_w fw称为评价网络(Critic Network),代替了判别网络。和标准GAN中判别网络有所不同,判别网络是做分类任务,而评价网络是回归任务,即对于真实样本,打分尽可能高;对于生成样本,打分尽可能低。所以评价网络无需sigmoid函数。-
另外,由于 ∥ f ∥ L ≤ K \|f\|_{L} \leq K ∥f∥L≤K的限制,作者直接限制 f w f_w fw的所有参数值域不超过某个范围 [ − c , c ] [-c,c] [−c,c]( c c c为一个比较小的正数,例如0.01)。由于偏导数的大小一般和参数取值有关,所以将参数限制在某个范围,其实也能达到使其梯度限制在某个范围。
-
综上,评价网络的损失函数为
个人理解:评价网络的损失函数含义并不是最小化真实分布与生成分布之间的Wasserstein距离(虽然是它的形式),但在本文 f w f_w fw判别网络的设定下,使其表面上的含义恰好与评价网络的优化目标吻合,即真实样本打分尽量高,生成样本打分尽量低
E x ∼ P g [ f w ( x ) ] − E x ∼ P r [ f w ( x ) ] \mathbb{E}_{x \sim P_{g}}\left[f_{w}(x)\right]-\mathbb{E}_{x \sim P_{r}}\left[f_{w}(x)\right] Ex∼Pg[fw(x)]−Ex∼Pr[fw(x)]
-
生成网络
Generator Network
K ⋅ W ( P r , P g ) ≈ max w : ∣ f w ∣ L ≤ K E x ∼ P r [ f w ( x ) ] − E x ∼ P g [ f w ( x ) ] K \cdot W\left(P_{r}, P_{g}\right) \approx \max _{w:\left|f_{w}\right|_{L} \leq K} \mathbb{E}_{x \sim P_{r}}\left[f_{w}(x)\right]-\mathbb{E}_{x \sim P_{g}}\left[f_{w}(x)\right] K⋅W(Pr,Pg)≈w:∣fw∣L≤KmaxEx∼Pr[fw(x)]−Ex∼Pg[fw(x)]
- 上式衡量了Wasserstein距离,所以生成器的损失函数可以是最小化上式,但由于第一项与生成器无关,所以生成器的损失函数为
− E x ∼ P g [ f w ( x ) ] -\mathbb{E}_{x \sim P_{g}}\left[f_{w}(x)\right] −Ex∼Pg[fw(x)]
-
综上所示,WGAN相对于GAN其实就改了四点
-
判别器取消最后一层的sigmoid
-
生成器和判别器的Loss不取Log(即不使用交叉熵,直接将神经网络的输出Logit当Loss用;为什么这么做都是基于前述理论推导出来的,推导很复杂,但改动的地方很简单)
-
每次更新判别器的参数之后,都将它们的值截断到不超过一个固定常数 c c c(因为在推导过程中将 f f f参数化为 f w f_w fw,作为判别器或评价网络,必须满足Lipschitz的条件,而生成器与 f w f_w fw无关,不需要截断)
-
不要用基于动量的优化算法(如Adam和Momentum),推荐RMSProp,SGD也可
-


技术共进,成长同行——讯飞AI开发者社区
更多推荐


 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)