
mysql 大数据量统计重复问题
上亿条数据(有重复),统计其中出现次数最多的前N个数。以上类型题目其本质其实是属于统计类型的业务,比如:统计目前商品表中各个分类的商品数量,并排出前十的分类以及分类商品数量。对于这种业务我们有多种不同的方案,一下的方案解释:该类型的案例:统计目前商品表中各个分类的商品数量,并排出前十的分类以及分类商品数量。设计SQL语句以及表此时数据量:select count(*) as count,categ
上亿条数据(有重复),统计其中出现次数最多的前N个数。
以上类型题目其本质其实是属于统计类型的业务,比如:统计目前商品表中各个分类的商品数量,并排出前十的分类以及分类商品数量。
对于这种业务我们有多种不同的方案,以下的方案解释:
该类型的案例:统计目前商品表中各个分类的商品数量,并排出前十的分类以及分类商品数量。
设计SQL语句以及表此时数据量:
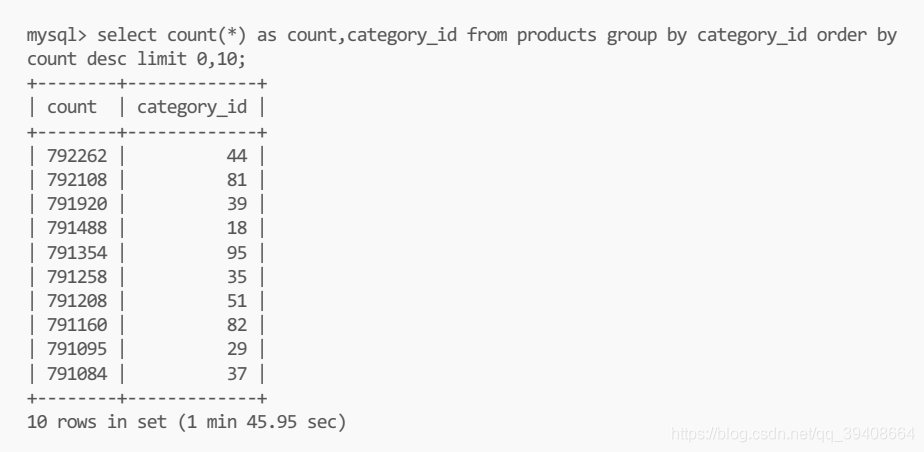
select count(*) as count,category_id from products group by category_id order by count desc limit 0,10;
为优化此SQL语句,我们加了一个 idx_category_id(category_id) 的索引。但是这个索引的优化并不理想。所以我们需要另辟蹊跷。
查询效率比较低:多达45s
解决方案一、
1.在shell脚本中查询出需要的数据
#!/bin/bash
#IP地址
HOME_NAME='192.168.29.1'
#端口号
DB_PORT='3306'
#数据库名称
DB_NAME='starsky'
#用户名
USER_NAME='starsky'
#密码
PASSWORD='root'
#定义mysql链接语句
MYSQL_ETL="/usr/local/mysql/bin/mysql -h$HOME_NAME -P$DB_PORT $DB_NAME -s -e"
#定义mysql查询语句
HIVE_TABLE_SQL="select count(*) as count,category_id from products group by category_id
order by count desc limit 0,10"
#执行查询语句
HIVE_TABLE=$($MYSQL_ETL "${HIVE_TABLE_SQL}"|while read a b;do echo "$a:$b";done)
#清空count统计表数据
DELETE_TABLE="truncate table count"
#执行清空表计划
$($MYSQL_ETL "${DELETE_TABLE}")
#循环
for i in $HIVE_TABLE
do
#赋值
count=`echo $i |cut -d: -f 1`
category_id=`echo $i |cut -d: -f 2`
#定义插入语句
INSERT_TABLE="insert into count (count,category_id)values($count,$category_id);commit;"
#执行语句
$($MYSQL_ETL "${INSERT_TABLE}")
done
echo "已更新最新排名"
2.将数据新增到统计表中
在MySQL中我们建了一张存储各个分类的商品数量以及排名前十的分类ID
CREATE TABLE `count`(
`id` int(11) NOT NULL AUTO_INCREMENT,
`COUNT` bigint(255) DEFAULT NULL,
`level` int(255) DEFAULT NULL,
`category_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
)ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8
id:主键索引 coun统计的数据量
level:等级(可不要)
category_id:分类id
3.定时执行shell脚本
crontab 是 Linux 系统中的定时任务,我们可以借助他来完成延迟性的数据统计问题,比如每天的凌晨三点进行统计
crontab -e:进入编辑定时任务 进入按 i 键,退出保存先按 ESC 键,再打出英文冒号 : ,输入 wq 保存退出。
编辑定时任务:
[root@localhost bin]# crontab -e
***** /home/count.sh
~
:wq
使用 crontab -l 进行查看定时任务
[root@localhost bin]# crontab -l
* * * * * /home/count.sh
4.查询数据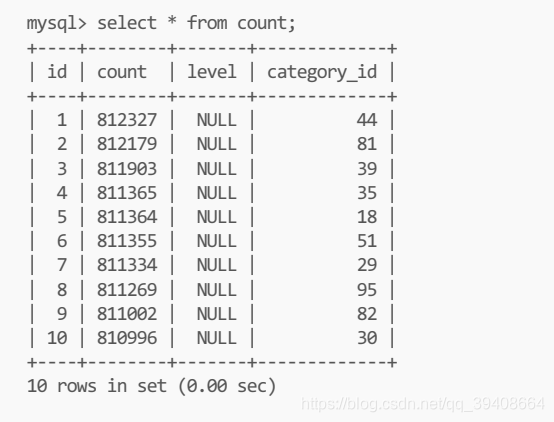
查询的速度明显提高
缺点:数据不够实时。
解决方案二、
使用 redis 消息队列来解决问题,原理是在每次新增商品,都往队列中插入一个任务,去按照分类统计商品数据量,排出前十的分类id
数据一样也是可以新增到统计表中,也可以使用 redis 进行缓存。
步骤如下:
- 新增一个商品到数据库中
- 数据库完成新增之后程序调用队列,插入一个任务
- 执行任务,统计数据,将结果写入统计表
- 查询数据

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)