
人工智能--Keras数据加载与增强
Keras图像数据加载和增强的方法
·
目录
一、实验目的和要求
- 掌握Keras图像数据加载的方法
- 掌握Keras图像数据增强的方法
二、实验内容
假设cifar10有10类的数据,分别存在10个文件夹,每个文件夹的图像来自同一类。训练数据文件夹结构如下所示,验证数据类似。
|
training_data/ ...class_a/ ......a_image_1.jpg ......a_image_2.jpg ...class_b/ ......b_image_1.jpg ......b_image_2.jpg ...... |
用Keras构造深度神经网络,并且实现一下步骤:
- 从文件夹中分批读取图像数据进行训练,对比一次性读取图像数据的方法的实验结果。
- 利用ImageDataGenerator类进行实时数据增强,对比无增强时的实验结果。
三、实验过程
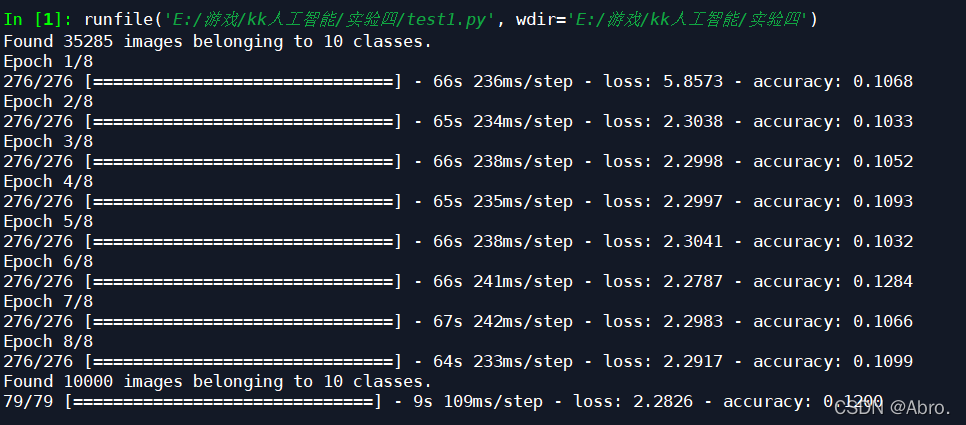
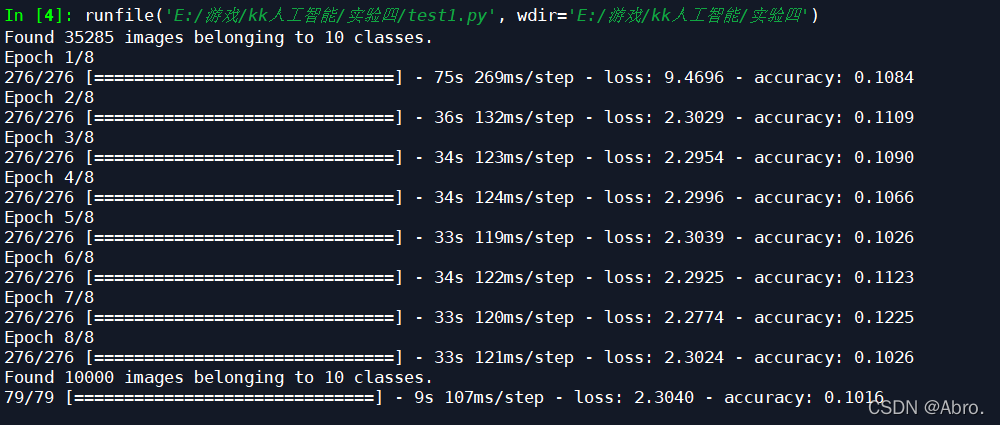
1.从文件夹中读取数据,学习率设为0.48,迭代次数为8次的结果如下:
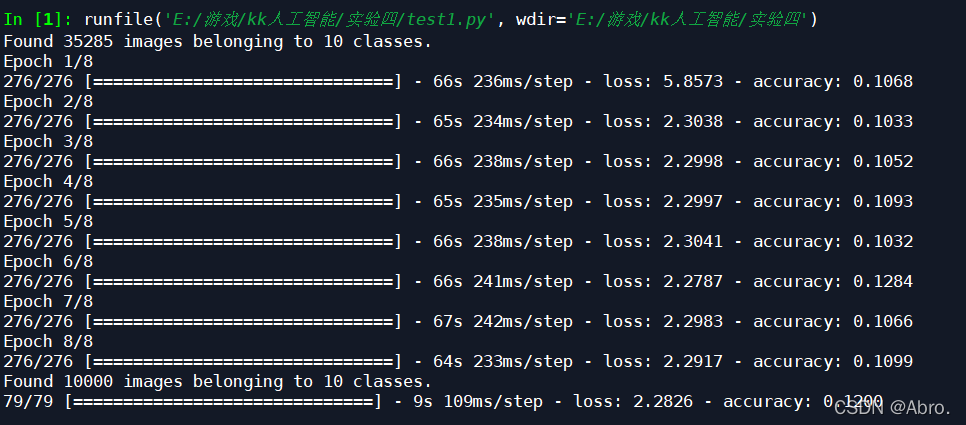
一次性读取图像数据,学习率设为0.48,迭代次数为8次的结果如下:
一次性读取图像数据,学习率设为0.5,迭代次数为8次的结果如下:
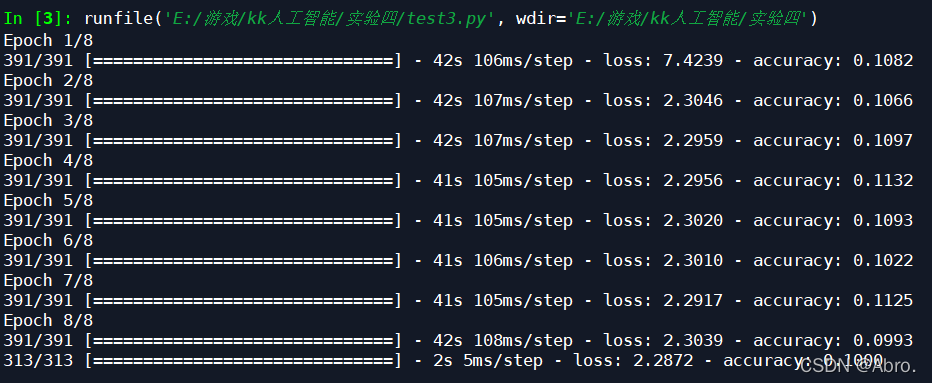
2.利用ImageDataGenerator类进行实时数据增强的结果如下:
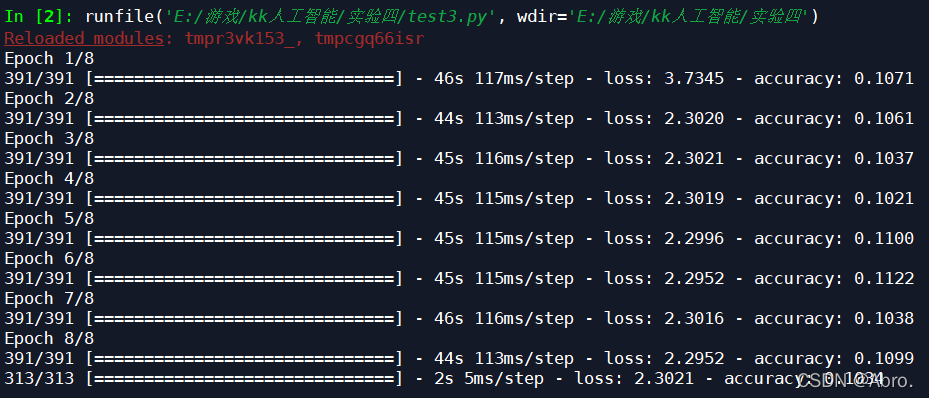
无数据增强的实验结果如下:
四、源码
第一问代码
# In[2]:构造网络
#文件夹分批读取图片
from keras import Sequential,layers,optimizers
model = Sequential()
# ImageDataGenerator要求输入为 [宽度,高度,通道数]
model.add(layers.Reshape((32*32*3,),input_shape=(32,32,3)))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
optimizer = optimizers.SGD(lr=0.48)
model.compile(optimizer,loss='categorical_crossentropy', metrics=['accuracy'])
# In[3]:数据增强
from keras.preprocessing.image import ImageDataGenerator
datagen_train = ImageDataGenerator(
rescale=1/255.0 # 像素转换为0到1,对识别率影响比较大
#添加增强语句
# rotation_range=10, # 每张图片随机旋转10度以内进行增强
# width_shift_range=0.1, # 左右随机平移10%以内
# height_shift_range=0.1 # 上下随机平移10%以内
#)
)
# In[4]:从硬盘分批读取数据并训练
generator_train = datagen_train.flow_from_directory(
#r'F:\data\Train', # 训练集所在路径,子目录为类别
r'D:\Cadabra_tools002\kkdata\cifar10\train', # 训练集所在路径,子目录为类别
target_size=(32, 32), # 统一resize所有图片的大小为 (32,32)
color_mode='rgb', # 读取单通道的彩色
batch_size=128, # 输入到fit函数中的批的大小
)
model.fit(generator_train,epochs=8)
# In[5]:从硬盘分批读取数据并测试
datagen_test = ImageDataGenerator(rescale=1/255.0)
generator_test = datagen_test.flow_from_directory(
#r'F:\data\Test',
r'D:\Cadabra_tools002\kkdata\cifar10\test',
target_size=(32,32),
color_mode='rgb', # 读取彩色
batch_size=128,
)
loss, accuracy = model.evaluate(generator_test)
第二问代码
# 读取数据
#from keras.datasets import mnist
#从keras数据集中导入包,一次性读取cifar10数据集
from keras.datasets import cifar10 #读取cifar10数据
from keras import utils
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train=utils.to_categorical(y_train,num_classes=10)
y_test=utils.to_categorical(y_test,num_classes=10)
x_train,x_test = x_train/255.0, x_test/255.0
# 构造网络
from keras import Sequential,layers,optimizers
model = Sequential()
model.add(layers.Reshape((32*32*3,),input_shape=(32,32,3)))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
optimizer = optimizers.SGD(lr=0.48)
model.compile(optimizer,loss='categorical_crossentropy', metrics=['accuracy'])
# 数据增强
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
#添加增强语句
rotation_range=10, # 每张图片随机旋转10度以内进行增强
width_shift_range=0.1, # 左右随机平移10%以内
height_shift_range=0.1, # 上下随机平移10%以内
#shear_range = 0.2,
#zoom_range = 0.2,
#horizontal_flip = True,
#fill_mode = 'nearest'
)
# ImageDataGenerator只接收多通道的彩色图像,即输入大小为:[样本数,宽度,高度,通道数]
x_train=x_train.reshape(-1,32,32,3)
x_test=x_test.reshape(-1,32,32,3)
# fit函数拟合特征变换需要的参数,不是必须的。只有用到中心化、标准化和ZCA变换时才要用
#datagen.fit(x_train)
# 用实时数据增强得到一个个batch拟合模型
model.fit(datagen.flow(x_train, y_train, batch_size=128), epochs=8)
# 数据增强后,模型的推广能力可能会有所提高
loss, accuracy = model.evaluate(x_test, y_test)
五、学习收获
- 对于cifar10数据集,进行了学习率的调整和增加迭代次数,以及增加一些其他的增强语句,但迭代出来的结果仍然是不理想,准确率只达到了0.10+;
- 一次性读取cifar10数据集的效果要比分批从目录中读取cifar10数据集的结果要差
- 可以发现添加了增强语句的效果比没添加增强语句的效果要好,但是没有添加增强语句时的运行速度较快。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 1
1 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)