
西湖大学自然语言处理(八)——朴素贝叶斯文本分类
西湖大学自然语言处理(八)—— 朴素贝叶斯文本分类Text classification under MLEThe Bayes ruleNaive Bayes model parameterisation processTraining a Navie Bayes classifierNavie Bayes text classificationGenerative modelsEvaluatin
西湖大学自然语言处理(八)—— 朴素贝叶斯文本分类
Text classification under MLE
文本分类问题建模:
**公式描述:**标签为c的文档d在D中出现的次数初一文档d在D中出现的次数
存在问题:文档D是稀疏的,D中没有出现的文本是大多数;换而言之,给定一个测试文本,它在测试集中出现几乎是不可能的
那么为什么不用之前的平滑技术对稀疏问题进行平滑呢?
通过观察发现,d是处于条件位置的,而之前的所有平滑技术都是针对非条件的随机变量而言的
The Bayes rule

Naive Bayes model parameterisation process

给定任何一个输入文本, P ( d ) P(d) P(d)是一个常数
P ( c ) P(c) P(c)是类别标签的相对频率
词袋假设→iid
朴素贝叶斯朴素在哪里?
我们假定了文档d中 w 1 , w 2 , … … , w n w_1,w_2,……,w_n w1,w2,……,wn是相互独立的,事实上, w 1 , w 2 , … … , w n w_1,w_2,……,w_n w1,w2,……,wn是可能相互依赖的,这就是朴素贝叶斯的朴素
Training a Navie Bayes classifier

P ( c ) P(c) P(c)计算方法:标签是c的文档个数除以D中文档的总个数
P ( w ∣ c ) P(w|c) P(w∣c)计算方法:在标签为c的文档中w出现的次数除以标签为c文档的这类词的总个数
Navie Bayes text classification

Generative models
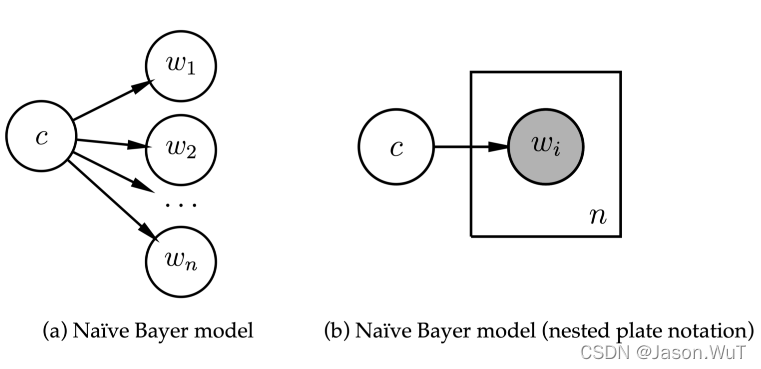
给定类别c,独立地生成文档中的 w 1 , w 2 … … w n w_1,w_2……w_n w1,w2……wn
Evaluating a Text Classifier

用训练集训练模型,在测试集上看模型表现
为什么需要Development set?
确定超参数
模型的调整过程:
在训练集上训练好模型,在development set上确定好超参数,不断调整,直到developmet set上出现满意的结果,最后拿到测试集上做一次测试
Features in NLP

贝叶斯公式推导



技术共进,成长同行——讯飞AI开发者社区
更多推荐



 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)