
AI 爱好者必读!Manus 采用上下文工程构建AI智能体经验分享
在当前阶段,构建高效、可靠的AI智能体(Agent),其成功的关键并不在于从零开始训练一个更庞大的模型,而在于对输入给模型的“上下文(Context)”进行精心设计和管理,即所谓的“上下文工程”(Context Engineering)
有同事致力于AI的研究,经常有高质量的文章出品。
他的主战场在VX,好文章搬一搬,让更多人看到。
【作者:两克伴】
Manus 的公司官网站上上周发表了一篇他们联合创始人季逸超 (Peak)最新的技术文章《Context Engineering for AI Agents: Lessons from Building Manus》[1],讲述了 Manus 团队通过上下文工程构建智能体过程中的第一手经验。文章干货满满,强烈推荐给每位对 AI 智能体感兴趣的朋友。
坦白说,Peak 的这篇文章一经发出就引起广泛关注,我平时所订阅的不管是主流技术媒体还是 AI 博主们,不少都已经在公众号进行了转发,可见这篇文章的受欢迎程度。
那我为什么还要写这篇文章呢?主要是想把我通过这篇文章收获的一些知识做个简单记录,方便未来随时查阅。如果对这部分不感兴趣的朋友,可以直接跳至文章后半部分,看全文翻译。
我的阅读记录
Peak 在这篇文章表达的核心观点是:在当前阶段,构建高效、可靠的AI智能体(Agent),其成功的关键并不在于从零开始训练一个更庞大的模型,而在于对输入给模型的“上下文(Context)”进行精心设计和管理,即所谓的“上下文工程”(Context Engineering)。
通过这篇文章我收获的知识点包括:
1. 优先进行“上下文工程”,而非模型训练 (Prioritize Context Engineering over Model Training)
经验总结: Peak 在文中一开头就提到,他们在项目启动之初,团队就面临一个关键决策:是使用开源基础模型来训练端到端的智能体模型,还是基于前沿模型的“上下文学习”能力之来构建智能体。最终从时效的角度考虑,他们选择 Manus 押注于上下文工程。
"This allows us to ship improvements in hours instead of weeks, and kept our product orthogonal to the underlying models: If model progress is the rising tide, we want Manus to be the boat, not the pillar stuck to the seabed."
2. 为KV缓存而设计,以优化成本和延迟 (Design for the KV-cache)"
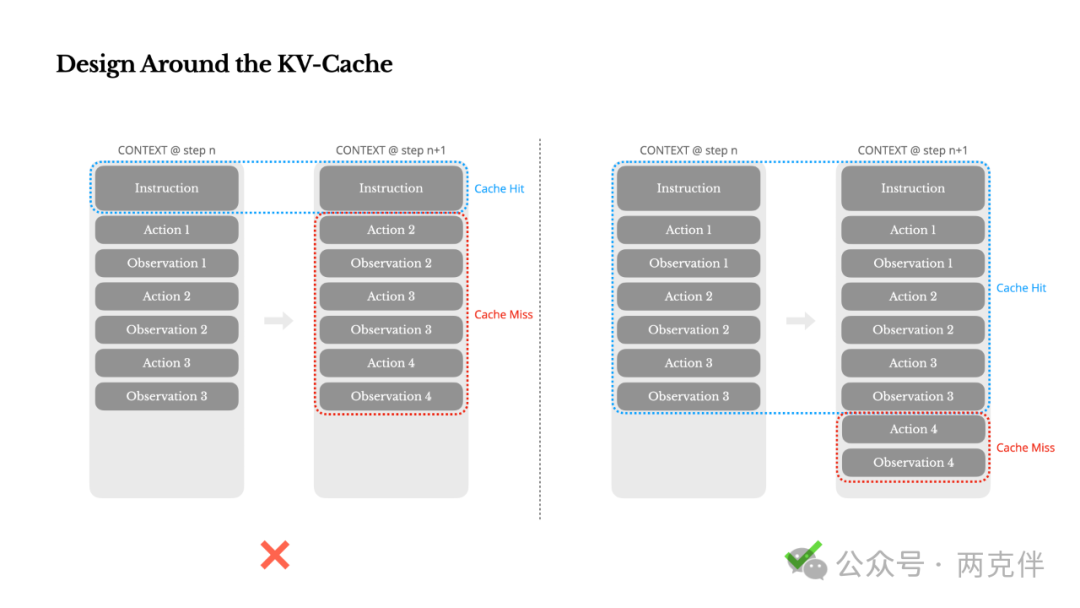
经验总结: Peak 认为KV 缓存命中率是生产阶段 AI 智能体最重要的单一指标。 大模型在处理信息时,会将提示(Prompt)的前半部分缓存起来(即KV缓存),以加速后续的计算。因此,我们应该尽量保持这部分前缀的稳定,并将新的信息以“仅追加”(append-only)的方式添加到末尾。这能极大地降低API调用的成本和响应时间。
"If I had to choose just one metric, I'd argue that the KV-cache hit rate is the single most important metric for a production-stage AI agent... contexts with identical prefixes can take advantage of KV-cache, which drastically reduces time-to-first-token (TTFT) and inference cost... "
3. 利用“工具屏蔽”而非“移除”来引导模型 (Guide the model by masking tools)"
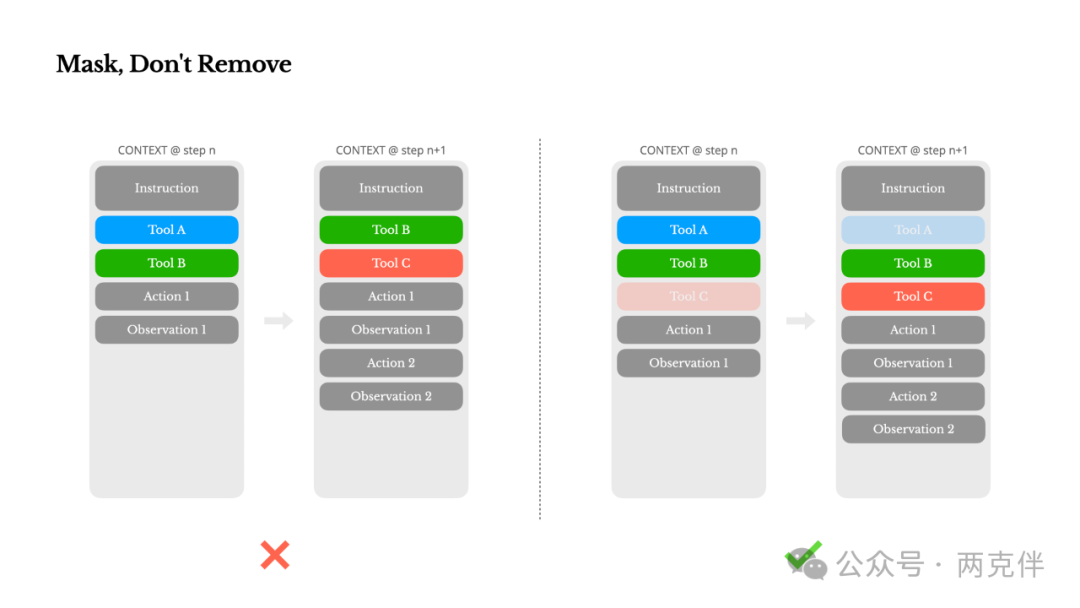
经验总结: 当我们希望限制智能体只能使用某些工具时,传统的做法是从上下文中移除其他工具的描述,但这会破坏KV缓存的稳定性。一个更优的策略是,保留所有工具的描述,但通过指令告诉模型:“你现在只能使用A、B、C这三个工具”。这种“屏蔽”而非“移除”的方式,既能有效引导模型,又不会牺牲性能。
"Manus uses a context-aware state machine to manage tool availability. Rather than removing tools, it masks the token logits during decoding to prevent (or enforce) the selection of certain actions based on the current context."
4. 将文件系统作为智能体的“无限记忆” (The file system is your agent’s infinite memory)"
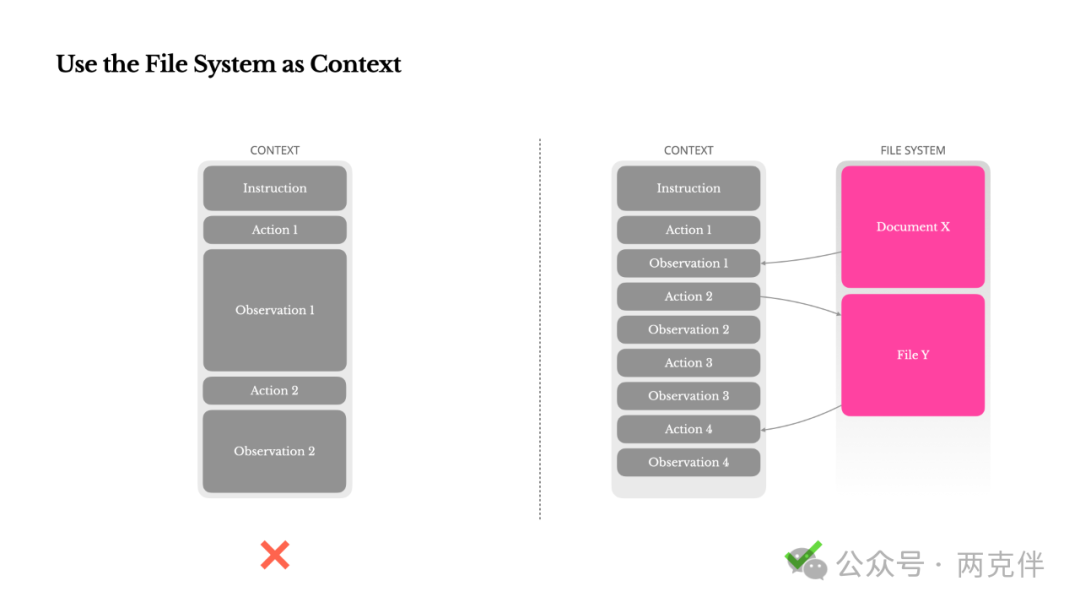
经验总结: 大模型的上下文窗口是有限的,无法为长期记忆。Peak 发现,文件系统是一个完美的替代品。让智能体学会将思考过程、中间结果和长期计划写入文件,并在需要时读取,就相当于给了它一个几乎无限且持久的记忆系统。
"we treat the file system as the ultimate context in Manus: unlimited in size, persistent by nature, and directly operable by the agent itself. The model learns to write to and read from files on demand—using the file system not just as storage, but as structured, externalized memory."
5. 让智能体“复述目标”以保持专注 (Have the agent recite its goals)"
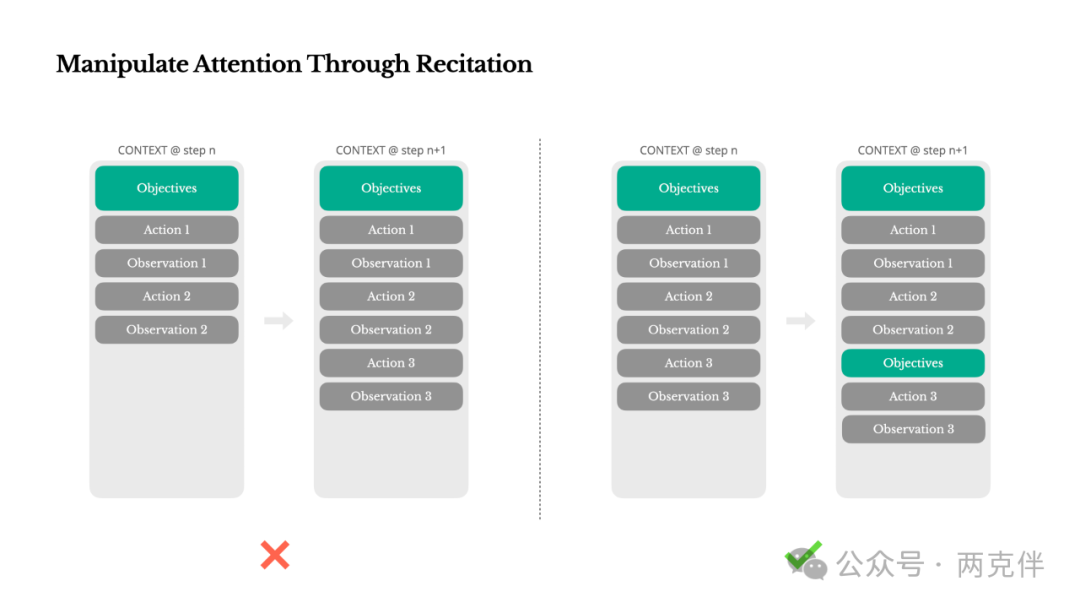
经验总结: 在处理复杂的多步任务时,智能体常常会“分心”或“忘记”最初的目标。一个简单而极其有效的技巧是,在每次行动前,都要求智能体在上下文中重新陈述一遍它的核心目标和计划。这种“复述”行为能极大地帮助模型保持专注,确保其所有行动都服务于最终目的。
"By constantly rewriting the todo list, Manus is reciting its objectives into the end of the context. This pushes the global plan into the model's recent attention span, avoiding "lost-in-the-middle" issues and reducing goal misalignment. "
6. 让智能体保留错误内容 (Keep the wrong stuff in the agent)"
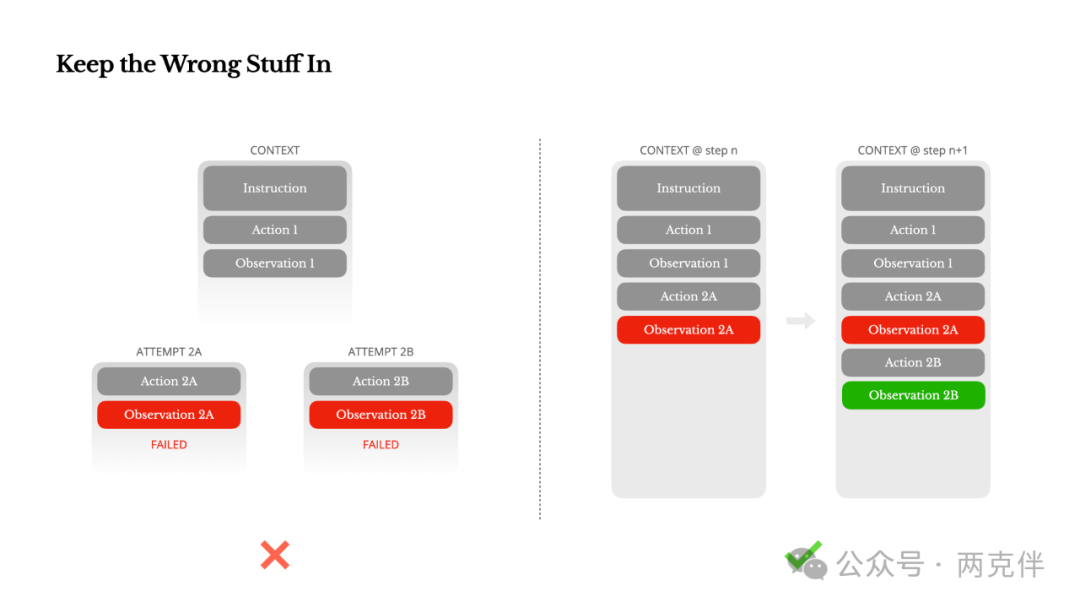
经验总结: 智能体会因为 LLM 产生幻觉、环境返回错误或者外部工具异常运行而产生错误,在多步骤任务中,失败应作为循环的一部分,则不是例外被抹除。 因为错误是智能体学习和改进的机会,保留错误内容可以帮助智能体从错误中学习,避免重复同样的错误。
"In our experience, one of the most effective ways to improve agent behavior is deceptively simple: leave the wrong turns in the context. When the model sees a failed action... This shifts its prior away from similar actions, reducing the chance of repeating the same mistake."
全文翻译
以下为 Peak 的文章全文翻译 ( 用 Google Gemini 2.5 pro 翻译,仅供参考):
AI 智能体的上下文工程:从构建Manus中汲取的经验教训
作者:Yichao 'Peak' Ji,7月18日,星期五
在Manus项目的最初阶段,我和我的团队面临一个关键决策:我们是应该使用开源基础模型来训练一个端到端的智能体模型,还是在一个前沿模型的“上下文学习”(in-context learning)能力之上构建智能体?
在我从事自然语言处理(NLP)的第一个十年里,我们并没有这样的选择。在遥远的BERT时代(是的,已经过去七年了),模型必须经过微调和评估,才能迁移到新的任务上。这个过程每次迭代通常需要数周时间,尽管那时的模型与今天的大语言模型(LLM)相比要小得多。对于快速迭代的应用,尤其是在产品与市场匹配(pre-PMF)之前,如此缓慢的反馈循环是致命的。这是我上一次创业时得到的惨痛教训,当时我从零开始为开放信息提取和语义搜索训练模型。然后,GPT-3和Flan-T5横空出世,我自研的模型一夜之间变得无足轻重。讽刺的是,正是这些模型开启了上下文学习的时代——以及一条全新的前进道路。
这个来之不易的教训让我们的选择变得清晰:Manus将赌注押在“上下文工程”(context engineering)上。这使我们能将产品改进的周期从数周缩短到几小时,并让我们的产品与底层 模型的发展保持正交关系:如果模型的进步是上涨的潮水,我们希望Manus是那艘船,而不是被固定在海床上的柱子。
然而,上下文工程的实践远非一帆风顺。它是一门实验科学——我们已经重构了我们的智能体框架四次,每一次都是在发现了更好的构建上下文的方法之后。我们亲切地将这种架构搜索、提示词调整和经验猜测的手动过程称为“随机研究生下降”(Stochastic Graduate Descent)。这个说法虽然不那么优雅,但确实有效。
这篇文章分享了我们通过自己的“SGD”过程所达到的局部最优解。如果你正在构建自己的AI智能体,我希望这些原则能帮助你更快地收敛。
围绕KV缓存进行设计
如果我只能选择一个指标,我认为KV缓存命中率是衡量一个生产级AI智能体最重要的单一指标。它直接影响延迟和成本。要理解其中原因,让我们看看一个典型智能体的运作方式:在收到用户输入后,智能体通过一系列的工具使用来完成任务。在每次迭代中,模型根据当前上下文从预定义的行动空间中选择一个动作。该动作随后在环境(例如,Manus的虚拟机沙箱)中执行,以产生一个观察结果。这个动作和观察结果被追加到上下文中,形成下一次迭代的输入。这个循环持续进行,直到任务完成。
可以想象,上下文在每一步都会增长,而输出——通常是一个结构化的函数调用——则相对较短。这使得智能体与聊天机器人相比,其“预填充”(prefilling)与“解码”(decoding)的比例高度倾斜。例如,在Manus中,平均的输入输出Token比例约为100:1。
幸运的是,具有相同前缀的上下文可以利用KV缓存,这极大地减少了首个Token生成时间(TTFT 和推理成本——无论你是使用自托管模型还是调用推理API。我们谈论的不是小数目:以Claude Sonnet为例,缓存过的输入Token成本为0.30美元/百万Token,而未缓存的成本为3美元/百万Token——相差10倍。
从上下文工程的角度来看,提高KV缓存命中率涉及几个关键实践:
-
1. 保持你的提示词前缀稳定。
由于LLM的自回归特性,即使是单个Token的差异也可能使其后的缓存全部失效。一个常见的错误是在系统提示的开头包含时间戳——尤其是精确到秒的时间戳。当然,这能让模型告诉你当前 时间,但它也扼杀了你的缓存命中率。 -
2. 让你的上下文成为“仅追加”模式。
避免修改之前的动作或观察结果。确保你的序列化过程是确定性的。许多编程语言和库在序列化JSON对象时不保证键的顺序稳定,这可能会悄无声息地破坏缓存。 -
3. 在需要时明确标记缓存断点。
一些模型提供商或推理框架不支持自动的增量式前缀缓存,而是需要手动在上下文中插入缓存断点。在设置这些断点时,要考虑到潜在的缓存过期问题,并至少确保断点包含系统提示的末尾部分。
此外,如果你正在使用像vLLM这样的框架自托管模型,请确保启用了前缀/提示词缓存,并使用会话ID等技术来确保请求在分布式工作节点间的一致路由。
屏蔽,而非移除
随着你的智能体能力越来越强,其行动空间自然会变得更加复杂——简单来说,就是工具的数量会爆炸式增长。最近流行的模型上下文协议(MCP)更是火上浇油。如果你允许用户配置工具,相信我:总会有人把你精心策划的行动空间里塞进几百个神秘的工具。结果就是,模型更容易选错动作或采取低效路径。简而言之,你那全副武装的智能体变笨了。
一个自然而然的反应是设计一个动态的行动空间——也许像RAG(检索增强生成)那样按需加载工具。我们在Manus中也尝试过。但我们的实验得出了一个明确的规则:除非绝对必要,否则避免在迭代中动态添加或移除工具。主要有两个原因:
-
1. 在大多数LLM中,工具定义在序列化后位于上下文的前部,通常在系统提示之前或之后。因此,任何改动都会使所有后续动作和观察结果的KV缓存失效。 2. 当之前的动作和观察结果仍然引用当前上下文中已不存在的工具时,模型会感到困惑。如果没有约束解码,这通常会导致模式(schema)违规或产生幻觉动作。
为了在解决这个问题的同时仍能改善动作选择,Manus使用了一个感知上下文的状态机来管理工具的可用性。它不是移除工具,而是在解码时屏蔽某些Token的logits,从而根据当前上下文来阻止(或强制)选择某些动作。
在实践中,大多数模型提供商和推理框架都支持某种形式的响应预填充,这允许你在不修改工具定义的情况下约束行动空间。函数调用通常有三种模式(我们以NousResearch的Hermes格式为例):
-
• 自动(Auto) – 模型可以选择调用或不调用函数。通过仅预填充回复前缀实现:
<|im_start|>assistant -
• 必须(Required) – │
模型必须调用一个函数,但具体调用哪个不受限制。通过预填充至工具调用Token实现:<|im_start|>assistant<tool_call> -
• 指定(Specified) –
模型必须从一个特定的子集中调用函数。通过预填充至函数名的开头实现:<|im_start|>assistant<tool_call>{"name": “browser_
利用这一点,我们通过直接屏蔽Token logits来约束动作选择。例如,当用户提供新输入时,Manus必须立即回复而不是执行动作。我们还特意设计了具有一致前缀的动作名称——例如,所有浏览器相关的工具都以browser_ 开头,命令行工具以shell_ 开头。这使我们能够轻松地强制智能体在给定状态下只从某个工具组中进行选择,而无需使用有状态的logits处理器。
这些设计有助于确保Manus的智能体循环保持稳定——即使在模型驱动的架构下也是如此。
将文件系统作为上下文
现代的前沿LLM现在提供128K甚至更长的上下文窗口。但在真实的智能体场景中,这通常是不够的,有时甚至是一种负担。有三个常见的痛点:
-
1. 观察结果可能非常巨大,尤其是当智能体与网页或PDF等非结构化数据交互时。很容易就超出上下文限制。
-
2. 即使窗口在技术上支持,模型的性能在超过一定上下文长度后也往往会下降。
-
3. 长输入是昂贵的,即使有前缀缓存。你仍然需要为传输和预填充每个Token付费。
为了解决这个问题,许多智能体系统采用了上下文截断或压缩策略。但过于激进的压缩不可避免地会导致信息丢失。问题是根本性的:一个智能体,其本质决定了它必须基于所有先前的状态来预测下一个动作——而你无法可靠地预测哪个观察结果会在十步之后变得至关重要。从逻辑上讲,任何不可逆的压缩都带有风险。
这就是为什么我们将文件系统视为Manus中的终极上下文:它的大小无限,本质上是持久的,并且可以由智能体自己直接操作。模型学会了按需读写文件——将文件系统不仅仅用作存储,而是作为结构化的、外部化的记忆体。
们的压缩策略总是被设计成可恢复的。例如,只要保留了URL,网页的内容就可以从上下文中丢弃;只要文档的路径在沙箱中可用,其内容就可以被省略。这使得Manus可以在不永久丢失信息的情况下缩减上下文长度。
在开发这个功能时,我发现自己开始思考,要让一个状态空间模型(SSM)在智能体环境中有效工作需要什么。与Transformer不同,SSM缺乏全局注意力,并且难以处理长距离的向后依赖。但如果它们能够掌握基于文件的记忆——将长期状态外部化而不是保留在上下文中——那么它们的速度和效率可能会开启一类新的智能体。智能体化的SSM可能是神经图灵机的真正继承者。
通过“复述”来操控注意力
如果你使用过Manus,你可能已经注意到一个奇特的现象:在处理复杂任务时,它倾向于创建一个todo.md文件——并随着任务的进展逐步更新它,勾掉已完成的项目。
这不仅仅是一种可爱的行为——它是一种刻意操控注意力的机制。
在Manus中,一个典型的任务平均需要大约50次工具调用。这是一个很长的循环——而且由于Manus依赖LLM进行决策,它很容易偏离主题或忘记早期的目标,尤其是在长上下文或复杂任务中。
通过不断重写待办事项列表,Manus正在将它的目标“复述”到上下文的末尾。这将全局计划推入模型的近期注意力范围,避免了“迷失在中间”的问题,并减少了目标偏离。实际上,它是在用自然语言来引导自身的焦点朝向任务目标——而无需特殊的架构更改。
把错误的东西留在原地
智能体会犯错。这不是一个bug——这是现实。语言模型会产生幻觉,环境会返回错误,外部工具会行为异常,意想不到的边缘情况随时都会出现。在多步骤任务中,失败不是例外,而是循环的一部分。
然而,一个常见的冲动是隐藏这些错误:清理痕迹,重试动作,或者重置模型状态然后寄希望于神奇的“温度”(temperature)参数。这感觉更安全、更可控。但这是有代价的:
抹去失败就移除了证据。而没有证据,模型就无法适应。
根据我们的经验,改善智能体行为最有效的方法之一简单得令人意外:把错误的尝试留在上下文中。当模型看到一个失败的动作——以及由此产生的观察结果或堆栈跟踪(stack trace)——它会隐式地更新其内部信念。这会将其先验概率从相似的动作上移开,减少重复同样错误的机会。事实上,我们相信错误恢复是真正智能体行为最清晰的指标之一。然而,在大多数学术工作和公开基准测试中,这一点仍然被低估了,它们通常只关注理想条件下的任务成功率。
别被“少样本”套路了
少样本提示(Few-shot prompting)是改善LLM输出的常用技术。但在智能体系统中,它可能会以微妙的方式适得其反。
语言模型是出色的模仿者;它们会模仿上下文中的行为模式。如果你的上下文中充满了相似的过往“动作-观察”对,模型就会倾向于遵循这种模式,即使它已不再是最佳选择。
在涉及重复性决策或动作的任务中,这可能很危险。例如,当使用Manus帮助审查一批20份简历时,智能体常常会陷入一种节奏——仅仅因为它在上下文中看到了这种模式,就开始重复相似的动作。这会导致偏离、过度泛化,有时甚至是幻觉。
解决方法是增加多样性。Manus在动作和观察结果中引入了少量结构化的变体——不同的序列化模板、不同的措辞、顺序或格式上的微小噪音。这种受控的随机性有助于打破模式,并调整模型的注意力。换句话说,不要让自己陷入少样本的窠臼。你的上下文越统一,你的智能体就越脆弱。
结论
上下文工程仍然是一门新兴的科学——但对于智能体系统来说,它已经至关重要。模型可能会变得更强、更快、更便宜,但任何原始能力都无法取代对记忆、环境和反馈的需求。你如何塑造上下文,最终定义了你的智能体的行为方式:它运行得多快,恢复得多好,以及能扩展多远。
在Manus,我们通过反复的重构、走过的死胡同以及在数百万用户中的真实世界测试,学到了这些教训。我们在此分享的一切都不是普适真理——但这些是于我们而言行之有效的模式。如果它们能帮助你哪怕避免一次痛苦的迭代,那么这篇文章就完成了它的使命。
智能体的未来将由一个个上下文构建而成。请精心设计它们。
引用链接
[1] 《Context Engineering for AI Agents: Lessons from Building Manus》: https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
———— THE END ————

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 17
17 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)