
文本转语音TTS工具合集(上)
TTS:TTS和T2A、ElevenLabs、CosyVoice、Speech、Gemini 2.5、Dia-1.6B、Higgs Audio V2、OpenAudio S1、Vui、MeloTTS、Spark-TTS、Index-TTS、ChatTTS、MOSS-TTSD
本文搜集于网络资料。接上一篇ASR。
TTS
Text To Speech,文本转语音。
技术难点
- 自然度与情感表达
- 合成语音需避免机械感,需模拟语调、重音、停顿等副语言特征;
- 情感合成需要细粒度控制。
- 多音字与韵律处理
- 文本歧义依赖上下文;
- 韵律生成(如诗歌朗诵的节奏)需符合人类习惯。
- 个性化与音色克隆:定制化音色需少量样本即可模仿,涉及伦理问题。
- 跨语言合成:中英混合文本需无缝切换发音规则。
传统的TTS系统虽然能生成高质量语音,但往往存在控制能力有限、跨语言表现较差、声音风格固定等问题。
HuggingFace维护的TTS-Arena2榜单。
TTS和T2A
Text to Audio,T2A,TTS和T2A通常可以互换使用,但在某些情况下可能指代略有不同。
T2A,不特指生成语音,而是指任何形式的音频生成,比如将文本转换为音效、背景音乐或其他类型的音频内容。T2A包括TTS。
ElevenLabs
CosyVoice
阿里开源的超强TTS模型,支持多种生成模式,具有极强的语音自然可控性。
特点
- 语音合成:能够将文本转换为自然流畅的语音输出。
- 多语种支持:支持多种语言的语音合成,例如英语、中文等。
- 个性化调整:可能支持音色、语速等参数的调整,以实现个性化的语音输出。
SenseVoice也是阿里FunAudioLLM开源,是ASR模型。
CosyVoice系列论文地址:
系列对比:
| 对比项 | CosyVoice1 | CosyVoice2 | CosyVoice3 |
|---|---|---|---|
| 主要目标 | 多语种零样本克隆,提升语义一致性 | 支持流式/非流式统一TTS,低延迟高一致性 | 面向真实场景(in-the-wild),多语言多情绪多方言 |
| 语义Token提取 | 监督式语义Token(Whisper Encoder+向量量化VQ) | 监督式语义Token+FSQ(Finite Scalar Quantization) | 多任务训练语音Tokenizer(ASR+SER+LID+AED+SA)增强情绪韵律表达 |
| tokenizer特性 | VQ离散化,Token利用率低,冗余高 | FSQ高效压缩,Token利用率提升,离散表达更稳健 | 多任务Token,涵盖内容、韵律、情绪、语言、说话人多维信息 |
| LLM结构 | 小型Token predictor+自定义encoder,LLM仅用于embedding | LLM backbone直接生成语义Token,无需Token predictor | LLM backbone+DiffRO可微后训练reward优化,生成Token更稳健 |
| 生成策略 | 非流式,离线生成 | 支持chunk-aware flow matching 流式+非流式统一 | 同上,流式延迟稳定更低,内容一致性显著提升 |
| 优化策略 | 标准cross-entropy token loss | chunk-aware causal flow matching+FSQ+简化LLM接口 | DiffRO:可微reward强化内容一致性+KL正则防漂移 |
| 数据规模 | 万小时级,9语种 | 10万小时级,9语种 | 100万小时,9语种+18方言,多情绪多域 |
| 评测体系 | SEED-TTS等通用评测集 | SEED-TTS+自建流式延迟评测 | CV3-Eval:涵盖多语种多方言多情绪多场景,有噪环境,客观+主观全维度评价 |
| 性能亮点 | 内容一致性和说话人相似性初步提升 | CER/WER、流式延迟显著下降;更自然流畅 | CER/WER进一步降44%+;情绪韵律更丰富,说话人一致性最高;支持真实场景 |
安装
git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git
# If you failed to clone submodule due to network failures, pls run following command until success
cd CosyVoice
git submodule update --init --recursive
# conda环境
conda create -n cosyvoice python=3.8
conda activate cosyvoice
# pynini is required by WeTextProcessing, use conda to install it as it can be executed on all platform.
conda install -y -c conda-forge pynini==2.1.5
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
# If you encounter sox compatibility issues
sudo apt-get install sox libsox-dev
# 下载模型
from modelscope import snapshot_download
snapshot_download('iic/CosyVoice-300M', local_dir='models/CosyVoice-300M')
# 开启WebUI
python3 webui.py --port 5000 --model_dir models/CosyVoice-300M
nohup python3 webui.py --port 5000 --model_dir models/CosyVoice-300M > nohup.out 2>&1 &
Speech
MiniMax推出的付费API形式的TTS库,体验地址。
功能:
- 提供4款模型:Speech-02-HD、Speech-02-Turbo、Speech-01-HD、Speech-01-HD;
- 基础设置:语速、声调、音量
- 特效:回声、广播等
- 音色调节:提供音色库,支持搜索,如明亮与低沉、柔和与力量感、清脆与磁性等;
- 情绪调节:开心、难过、生气、惊讶、厌恶等;
- 长文本支持:最大可支持20w字符文本;
- MCP支持:
Gemini 2.5
支持多说话人场景,支持24种不同语言,几乎覆盖全球主要语言。提供30种不同的音色选择,从清晰的"Iapetus"到温和的"Vindemiatrix",从活泼的"Puck"到信息丰富的"Charon",每一种音色都有着鲜明的个性特征。
| Zephyr - Bright | Erinome- C/ear | Puck - Upbeat | Algenib- Gravelly | Charon - Informative | Rasalgethi - Informative |
|---|---|---|---|---|---|
| Kore – Firm | Laomedeia-Upbeat | Fenrir - Excitable | Achernar- Soft | Leda - Youthful | Alnilam-Firm |
| Orus – Firm | Schedar-Even | Aoede - Breezy | Gacrux - Mature | Callirrhoe - Easy-going | Pulcherrima-Forward |
| Autonoe- Bright | Achird - Friendly | Enceladus- Breathy | Zubenelgenubi - Casual | lapetus - Clear | Vindemiatrix-Gent/e |
| Umbriel - Easy-going | Sadachbia - Lively | Algieba-Smooth | Sadaltager - Knowledgeable | Despina-Smooth | Sulafat -Warm |
通过自然语言提示,可以精确控制AI的语音表现,维度包括:语调、情感、语速、口音、节奏等。
所有由Gemini 2.5生成的音频都嵌入SynthID水印技术,确保AI生成的内容可以被识别出来。
Dia-1.6B
Nari Labs开发推出,作为一款16亿参数规模的开源TTS模型,Dia不仅能够自然生成对话式语音,还首次在开源TTS模型中大规模引入情感控制、非语言表达合成与音频提示语音克隆等前沿特性,大大拓展语音生成的表现力和应用场景。
初步测试结果显示,Dia-1.6B在自然度、表现力和上下文适应性方面,均优于当前流行的模型如Sesame CSM-1B和ElevenLabs,尤其在复杂、多轮对话生成任务中表现出色。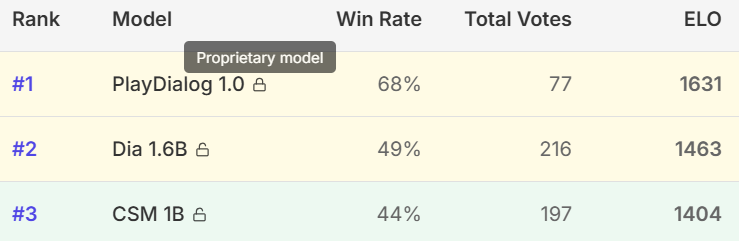
虽然官方尚未公布标准化量化指标,但得益于:
- 更大的模型参数规模;
- 先进的调节机制;
- 独特的非语言线索处理能力
Dia展现出更强的情绪细腻度和上下文理解能力,使得生成的语音作品更加接近真实人声。
核心功能
- 一次性生成完整对话流:不再逐行合成,支持直接输入包含多轮互动的剧本,自动生成自然连贯的对话语音,营造沉浸式体验。
- 多说话人标记支持:通过在文本中添加[S1]、[S2]等说话人标签,可以轻松合成多角色对话,适用于有声读物、广播剧、游戏配音等场景。
- 精准的情感和语气控制:支持通过音频提示引导生成不同情绪的语音风格,实现更细腻的人机交流体验。
- 语音克隆与复制:通过提供参考音频,Dia可以复制特定说话人的声音特性,支持定制化语音合成(需遵循合法授权规范)。
- 自然插入非语言表达:在文本中加入如
laughs,coughs等指令,Dia会自动在合成语音中插入自然的非语言声音,提升表现力。
局限:目前仅支持英文语音生成。
计划推出:
- 模型优化版:推理更快,资源占用更低;
- 量化版模型:适配低资源环境,如移动设备。
入门示例:
import soundfile as sf
from dia.model import Dia
from IPython.display importAudio
model = Dia.from_pretrained(
"nari-labs/Dia-1.6B"
)
# 输入文本(支持多说话人和非语言指令)
text = "[S1] Dia is an open weights text to dialogue model (sneezes). [S2] You get full control over scripts and voices. [S1] Wow. Amazing. (laughs) [S2] Try it now on GitHub or Hugging Face."
output = model.generate(text)
sf.write("simple.mp3", output, 44100)
# 播放音频
Audio("simple.mp3")
Higgs Audio V2
采用Apache 2.0开源许可,允许商业应用。包含:
- 模型训练代码:包含数据预处理、模型训练和评估的完整流程
- 预训练模型:提供多个版本的预训练模型,适应不同场景需求
- 推理示例:丰富的Jupyter Notebook示例;
- 语音克隆工具:简单易用的语音克隆接口,只需几行代码即可实现
- 多语言支持
功能:
- 多人对话生成能力:自动识别对话场景中的不同角色,并为每个角色匹配相应的情感和能量水平。在长对话中,能够保持角色声音的一致性,同时根据对话内容动态调整语气和情感,使生成的对话如真人交流般自然流畅。
- 智能韵律调整系统:传统TTS系统在长文本朗读中往往显得机械生硬,Higgs Audio V2引入自动韵律调整系统 。能根据文本内容自动调整语速、停顿和语调,无需人工干预即可生成富有生命力的语音。
- 零样本语音克隆与歌声合成:用户只需提供3-5秒的简短语音样本,模型就能准确复制特定人物的声音特征,包括音色、语调和说话习惯。还能让克隆的声音哼唱旋律 ,并同步生成背景音乐,真正实现
写一首歌并唱出来的创作流程。 - 实时语音交互能力:能理解用户的语音情绪,并做出相应的情感化表达,大大超越机械式问答的局限。这种能力为虚拟主播、实时语音助手等场景提供接近人类的交互体验。
关键技术突破:
- 1000万小时数据的自动化标注系统
自动化标注系统 整合多个ASR模型、声音事件分类模型和内部音频理解模型。清洗并标注1000万小时的音频数据,其中音频理解模型是在Higgs Audio v1 Understanding基础上微调而来,确保数据标注的高质量。 - 统一的Higgs Audio Tokenizer
能够同时捕获语义和声学特征,解决传统语音模型中语义与声学特征分离的问题,使模型能够更全面地理解语音内容。 - DualFFN架构:高效音频建模
提出DualFFN架构 ,在保持LLM核心能力的同时,以最小的计算开销实现对音频的高效建模。
性能表现:全面超越行业标准
在权威评测中,Higgs Audio V2展现令人印象深刻的表现:
- EmergentTTS-Eval基准 :情绪表达胜率超过GPT-4o-mini-tts达75.7%,问题处理胜率高出55.7%
- Seed-TTS、ESD等传统测试 :在多项语音合成基准测试中全面领先行业现有模型
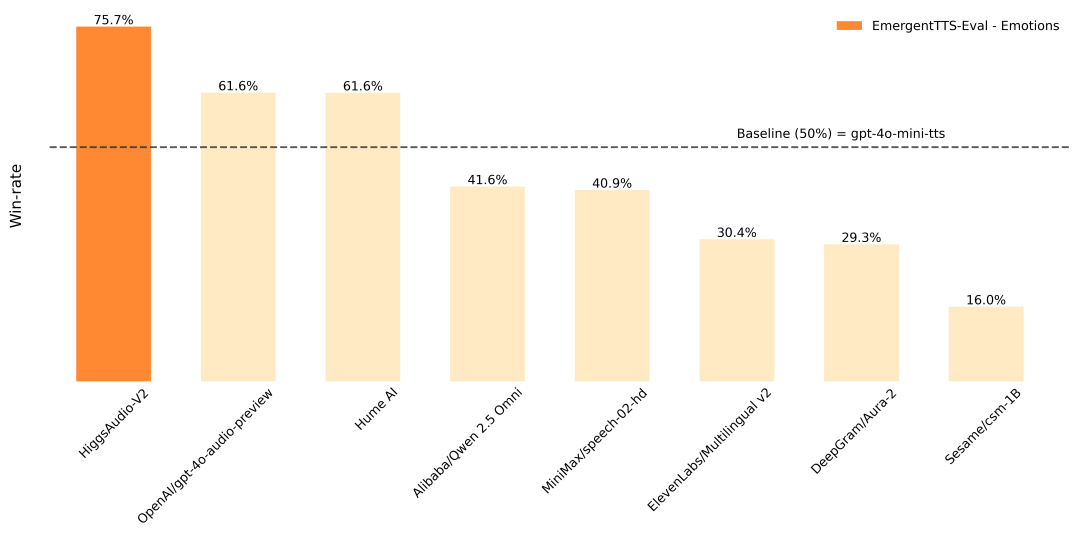
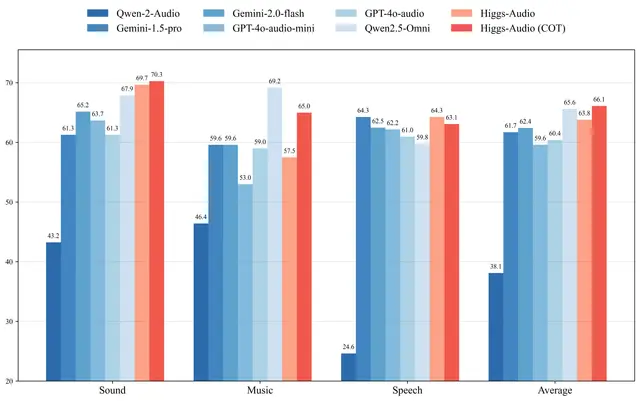
- MMAU音频推理能力评估 :尽管在音乐任务上因数据覆盖有限而表现稍逊,但通过利用基础LLM的COT能力,其音乐生成性能得到显著增强;
Higgs Audio V2在情感表达方面的突破性进展。能够准确捕捉并表达愤怒、喜悦、悲伤等多种复杂情感,富有温度和个性。
OpenAudio S1
OpenAudio S1是FishAudio发布的领先的端到端TTS模型,训练数据超过200万小时,覆盖多语言多场景,性能全面超越市面主流方案。
核心亮点
- 极致准确率:
S1 WER(词错误率):0.008
CER(字符错误率):0.004
支持基于GPT-4o的自动评估 - 多语言支持;
- 情感语音合成支持:超过50+种情绪标签&特殊语气标记
情绪:愤怒、高兴、忧虑、感动、轻蔑…
语气:耳语、匆忙、喊叫……
拟声:笑、叹气、抽泣、观众笑…… - 零样本/少样本克隆:只需10~30秒语音样本,就可实现个性化语音合成。
高推理效率
- RTX 4060:实时因子1:5
- RTX 4090:实时因子1:15
部署:支持Linux、Windows
模型规格对比
| 模型 | 参数量 | WER | CER | 说话人距离 |
|---|---|---|---|---|
| S1 | 4B | 0.008 | 0.004 | 0.332 |
| S1-mini | 0.5B | 0.011 | 0.005 | 0.380 |
两者均支持RLHF(人类反馈强化学习),在不同算力条件下灵活部署。
不足:尽管在自动评估指标上表现非常亮眼,但在人工主观测评中,生成语音在情绪连贯性和自然语气表达上仍显生硬,特别是在多轮对话、微妙语境表达等场景下。
优化与改进思路:
- 基于LLM的上下文建模:引入LLM对文本进行情感语境感知,辅助情绪embedding的动态生成,而非使用静态标签;
- Prosody Predictor优化:设计更细粒度的Prosody编码器,如基于扩散模型或flow-based网络建模韵律曲线;
- Prompt-Tuning情感模板机制:结合Prompt Learning,让语音风格与情境描述自然映射,而非硬编码;
- 多模态对齐学习:引入图像或视频作为额外条件,辅助训练跨模态情感表达,适用于虚拟人、客服等应用场景。
Vui
Fluxions-AI团队开源的轻量级、可在消费级设备端运行的语音对话模型Vui。
作为NotebookLM风格的语音模型,不仅能生成流畅的对话,还能精准模拟语气词(如呃、嗯)、笑声和犹豫等非语言元素,带来沉浸式的交互体验。可被应用于语音助手、播客生成、客服AI等场景。
提供三款模型:
- Vui.BASE:通用基础模型,4万小时对话训练;
- Vui.ABRAHAM:单说话人模型,单人上下文感知;
- Vui.COHOST:双说话人模型,双人互动。
Vui的轻量设计和逼真语音让它适用于多种场景:
- 播客生成:Vui.COHOST模拟双人对话,快速生成访谈或辩论音频;
- 语音助手:Vui.ABRAHAM提供上下文感知回复,适合智能客服或个人助理;
- 内容创作:生成自然语音,添加[laugh]、[hesitate],提升视频/播客真实感;
- 教育培训:模拟对话场景,生成教学音频,助力语言学习;
- 语音克隆:个性化语音定制,适合品牌营销或虚拟主播。
使用
git clone https://github.com/fluxions-ai/vui.git
cd vui
pip install -e .
# 运行在线Demo
python demo.py
MeloTTS
由MIT和MyShell.ai联合开源的TTS模型,采用MIT License。基于VITS2 + Bert-VITS2融合架构,其中VITS系列是目前最先进的端到端TTS架构,Bert让语音的韵律和情感表达更自然。
特性:
- 10种语言全覆盖:英语4种口音(美英澳印)、西班牙语、法语、中文、日语、韩语;
- 中英混读无压力:可在一句话里随意切换,不像某些TTS还要停顿切换;
- CPU实时推理:i7-10700K,延迟低到感觉不出来,无需显卡;
- 音质吊打商业方案:基于VITS2架构,比市面上大部分付费方案都强;
- 部署简单。
安装:pip install melotts
使用:
from melo.api import TTS
tts = TTS(language='EN', device='auto')
speaker_ids = tts.hps.data.spk2id
tts.tts_to_file('Hello world!', speaker_ids['EN-Default'], "output.wav")
Spark-TTS
论文,GitHub
凭借BiCodec编解码器和Qwen-2.5思维链技术,实现高质量、可控的语音生成。支持零样本语音克隆,还能进行细粒度语音控制,包括语速、音调、语气等多项参数调节,具备跨语言生成能力,让AI语音变得更加灵活、多样化。
核心能力
- 零样本语音克隆:只需提供几秒钟语音样本,便能克隆目标说话人的声音;
- 细粒度控制调整:粗粒度控制(性别、说话风格等);调整(音高、语速等);
- 跨语言语音生成:支持跨语言语音合成,支持中文和英文,并保持自然度和准确性;
- 高质量自然语音:结合Qwen-2.5思维链技术,增强语音表达逻辑,自动调整语气、停顿、强调等语音表达;
- 音质&语音控制能力:采用BiCodec单流语音编解码器,将语音分解为语义信息和说话人属性;
- Web界面支持:提供Web UI,方便进行语音克隆和语音创建的界面。
应用场景
- 有声读物:通过调整语速、音高和风格,生成富有表现力的朗读语音,提升听众体验。
- 多语言内容:支持中英文跨语言生成,适用于国际化应用。
- AI角色配音:利用零样本克隆技术,快速生成特定说话者的声音,用于虚拟角色或定制化服务。
架构图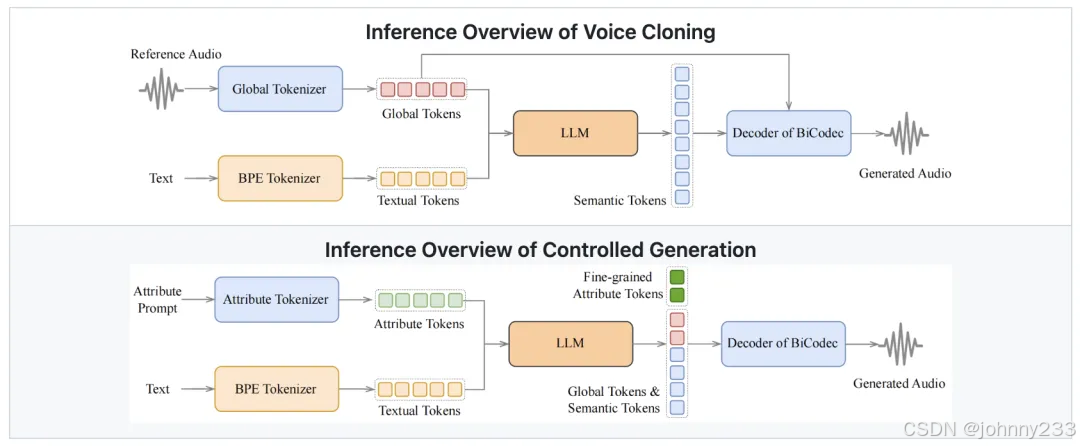
本地部署
git clone https://github.com/SparkAudio/Spark-TTS.git
cd Spark-TTS
# 创建虚拟环境,下载Python依赖
conda create -n sparktts -y python=3.12
conda activate sparktts
pip install -r requirements.txt
模型下载
- 通过Python代码下载
from huggingface_hub import snapshot_download
snapshot_download("SparkAudio/Spark-TTS-0.5B", local_dir="pretrained_models/Spark-TTS-0.5B")
- 通过Git下载
mkdir -p pretrained_models
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/SparkAudio/Spark-TTS-0.5B pretrained_models/Spark-TTS-0.5B
运行演示
cd example
bash infer.sh
命令行推理:
python -m cli.inference \
--text "text to synthesis." \
--device 0 \
--save_dir "path/to/save/audio" \
--model_dir pretrained_models/Spark-TTS-0.5B \
--prompt_text "transcript of the prompt audio" \
--prompt_speech_path "path/to/prompt_audio"
运行Web界面:python webui.py --device 0。
浏览器打开:
可直接通过界面执行语音克隆和语音创建,支持上传参考音频或直接录制音频。
Index-TTS
官网,哔哩哔哩推出的开源工业级TTS系统,论文,通过混合建模与模块化声学架构,基于开源项目XTTS和Tortoise深度优化,融合类GPT的生成架构与中文场景的针对性创新。其核心突破在于中文字符-拼音混合建模,结合Conformer条件编码器和BigVGAN 2解码器,显著提升中文发音准确性与语音自然度。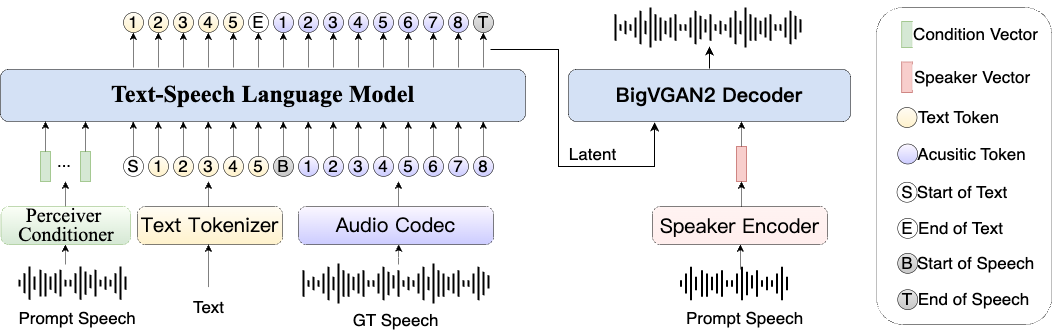
技术突破:解决中文合成痛点
- 混合建模:拼音纠错与多音字消歧
IndexTTS首创汉字与拼音联合输入机制,用户可直接输入拼音纠正多音字发音(如行动态切换xíng/háng),通过对抗训练将同音异义字误读率从8.7%降至0.9%。训练时随机将20%非多音字符替换为拼音,增强模型对发音规则的泛化能力。 - 精准停顿控制:通过时间戳嵌入技术,模型将标点符号转化为精确的停顿时长(逗号0.3秒,句号0.8秒),在《红楼梦》等古文测试中实现98.6%的断句准确率。
- 声学模型升级
- Conformer条件编码器:融合Transformer全局注意力与CNN局部感知优势,提升长文本韵律一致性42%;
- BigVGAN 2解码器:直接生成24kHz高保真波形,替代传统梅尔谱转换流程,降低延迟并提升音质。
在四大测试集(Aishell-1、CommonVoice 等)的评测结果:
| 指标 | IndexTTS | CosyVoice 2 | Fish-Speech |
|---|---|---|---|
| 平均WER | 3.7% | 5.9% | 8.3% |
| SS | 0.776 | 0.788 | 0.612 |
| MOS音质评分 | 4.01 | 3.81 | 3.57 |
注:WER越低越好,SS与MOS越高越好。
本地部署硬件参考:RTX 3060显卡生成15秒音频耗时约4.5秒。CPU支持但速度较慢,建议至少6GB显存。
conda create -n index-tts python=3.10
conda activate index-tts
# 2.克隆仓库并安装依赖
git clone https://github.com/index-tts/index-tts
cd index-tts
pip install -r requirements.txt
apt-get install ffmpeg # Linux需安装FFmpeg
# 3.下载预训练模型,国内镜像加速
export HF_ENDPOINT="https://hf-mirror.com"
huggingface-cli download IndexTeam/Index-TTS \
bigvgan_discriminator.pth bigvgan_generator.pth bpe.model dvae.pth
gpt.pth unigram_12000.vocab \
--local-dir checkpoints
命令行使用:
# 生成中文语音(需准备参考音频demo.wav)
indextts "欢迎体验IndexTTS的精准发音控制" \
--voice demo.wav \
--model_dir checkpoints \
--output output.wav
Web UI页面使用:
pip install -e ".[webui]"
python webui.py
体验地址:http://127.0.0.1:7860。
IndexTTS2
自回归模型虽然在语音自然度方面表现出色,但因其逐标记生成的机制,难以实现对语音时长的精准控制。IndexTTS2,解决这一问题,兼顾音质情感与时长控制。支持两种生成模式:用户可显式指定语音标记数量以精确控制语音长度,或让模型自由生成自然节奏的语音内容。
不仅在时长控制方面实现突破,还实现情感表达与音色的解耦。它支持从不同来源获取音色提示和情感提示,并在零样本条件下复现复杂的情绪风格。为提升强情感表达时的语音清晰度,系统还引入GPT模型的潜在表示,从而提升语音的稳定性与可听度。Bilibili团队设计基于自然语言的软指令机制,借助微调后的Qwen3模型,让用户可以直接用文字描述情感(如温柔地说)引导语音生成,极大降低情绪控制门槛。
提出IndexTTS2这一新颖的零样本语音生成模型,既可满足固定时长语音生成的应用需求,又能充分发挥自回归模型逐标记生成的优势,自然地生成更具韵律感的语音。此外,该模型在提升语音清晰度的同时,强化情感表达能力,并实现通过自然语言控制情感的功能,大大降低使用门槛。IndexTTS2三个核心模块: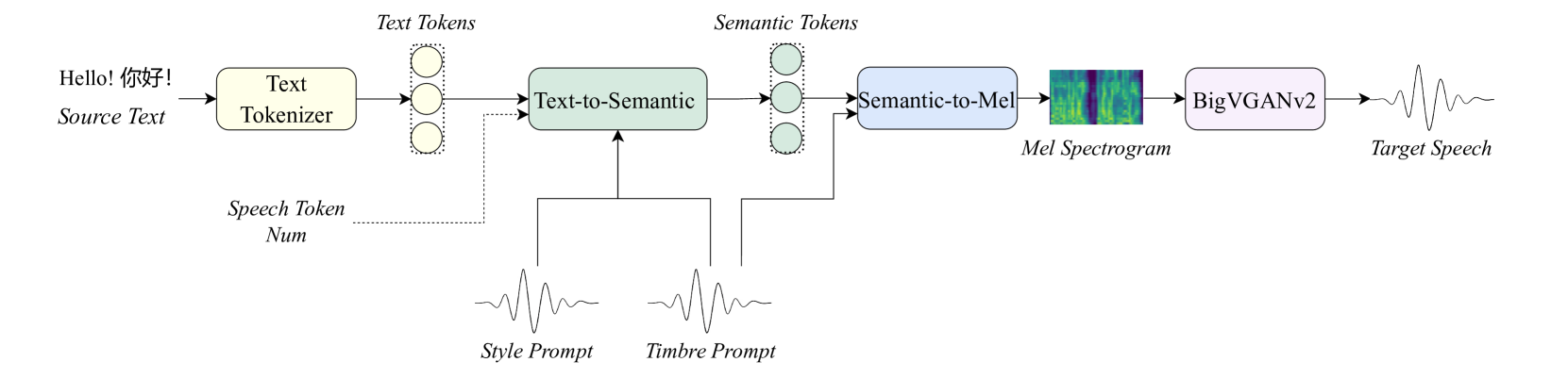
- 文本转语义:T2S,Text-to-Semantic,采用基于Transformer的自回归结构,输入文本、音色提示(timbre prompt)、风格提示(style prompt)以及可选的语音标记数量,输出语义标记(semantic tokens)。在情感表达方面,该模块会从风格提示中提取情绪特征。为了去除与情绪无关的信息,模型结构中引入梯度反转层(Gradient Reversal Layer,GRL)。
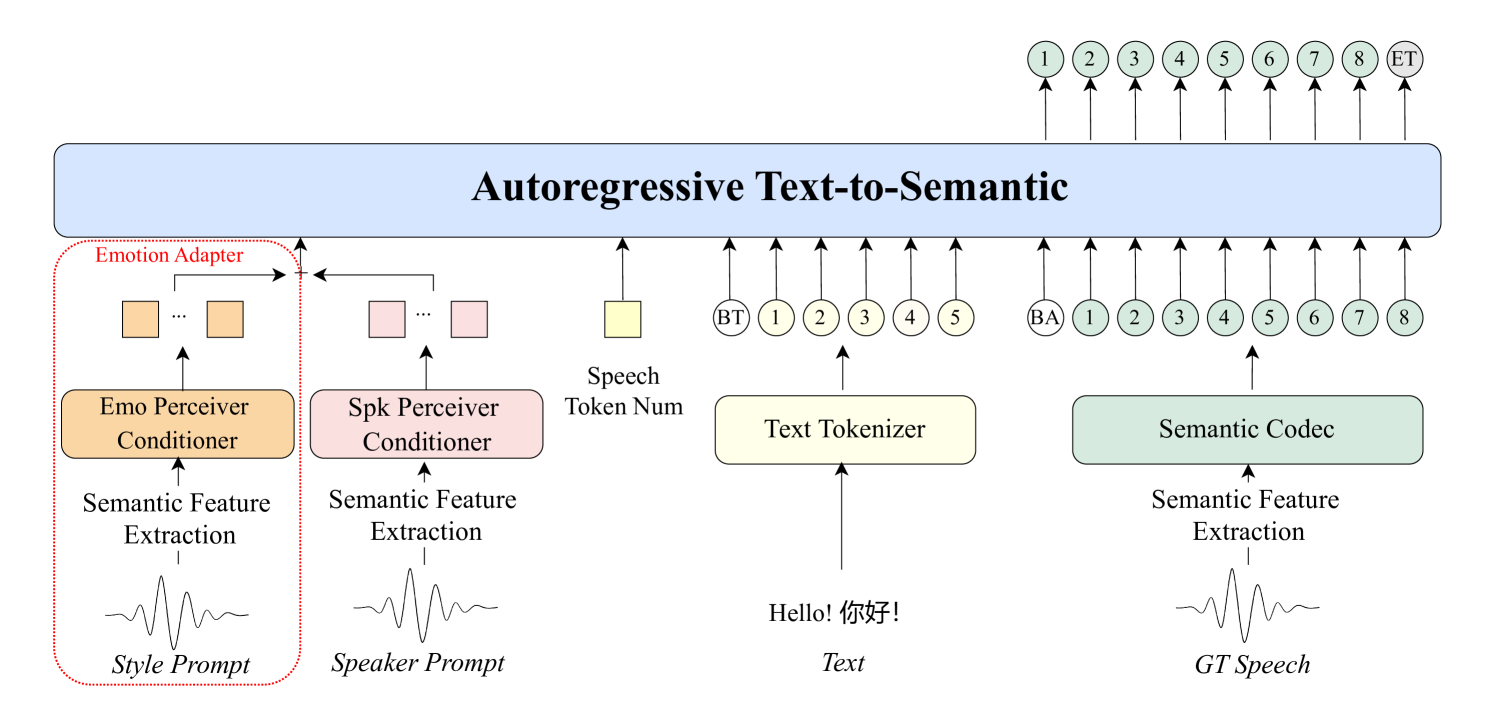
- 语义转梅尔谱:S2M, Semantic-to-Mel,采用非自回归结构,将语义标记与音色提示作为输入,生成对应的梅尔频谱图(mel-spectrograms),为后续语音合成做准备。
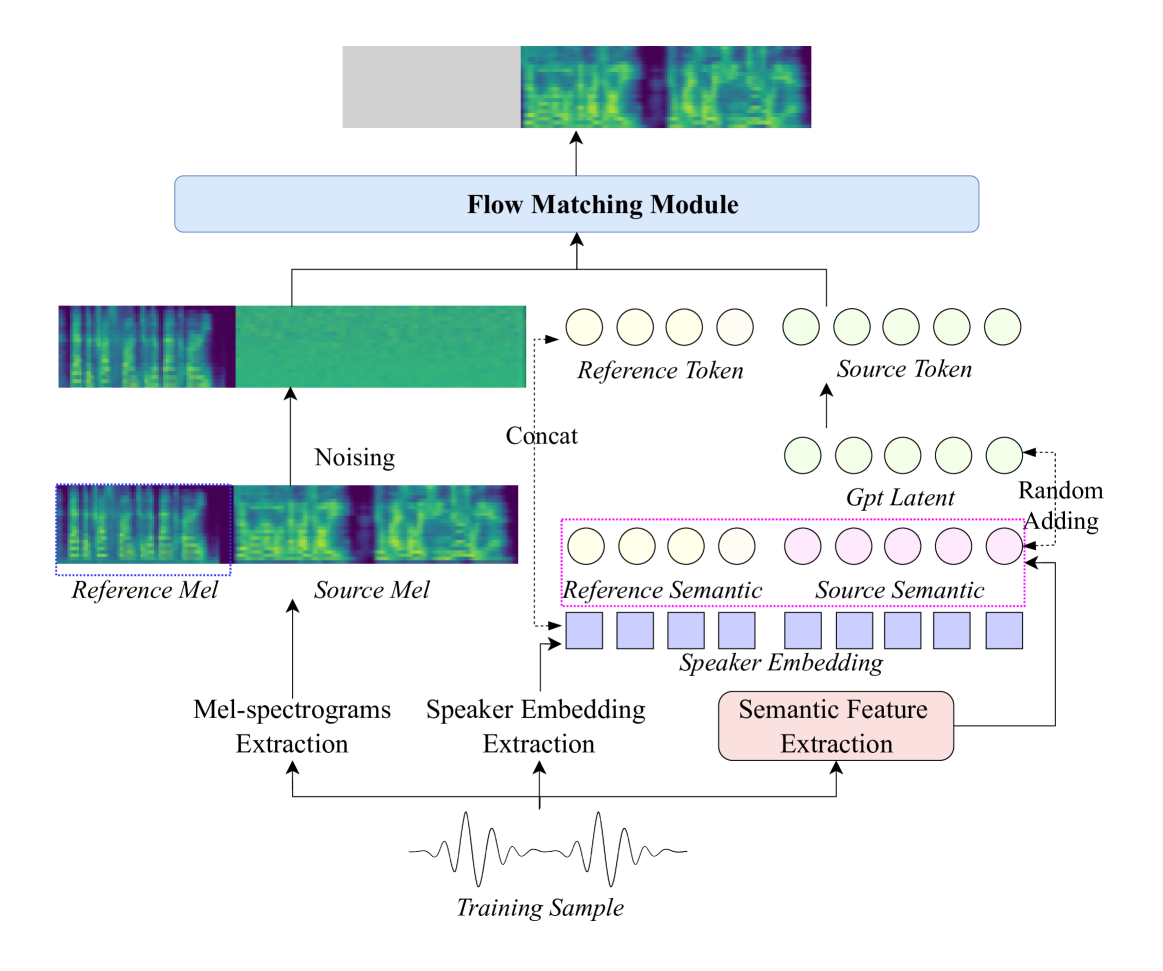
- 声码器:Vocoder,用于将梅尔谱图转化为真实可听的语音波形。为了提升在强烈情绪表达时的语音清晰度与稳定性,引入GPT 模型的潜在表示(latent representations),显著增强语音合成的表现力与可靠性。
IndexTTS-vLLM
GitHub,让语音合成更快速、更高效。核心价值在于通过vLLM加速IndexTTS的推理过程,显著提升语音合成的速度和并发能力。亮点:
- 单个请求RTF从0.3降至0.1;
- GPT模型decode速度提升至280 token/s;
- 支持多角色音频混合,为语音合成带来更多创意可能。
ChatTTS
专为对话场景设计的开源TTS,特别适用于LLM助手类对话任务,如对话式音频和视频介绍等应用。使用大约10w小时的中英文数据进行训练。
MOSS-TTSD
Text to Spoken Dialogue,由清华大学语音与腾讯语言实验室(Tencent AI Lab)开源的口语对话语音生成模型。基于先进的语义-音学神经网络音频编解码器和大规模预训练语言模型,结合超过100万小时的单人语音数据和40万小时的对话语音数据进行训练,能够将文本对话脚本转化为自然流畅、富有表现力的对话语音,支持中英文双语生成,并具备零样本语音克隆能力。
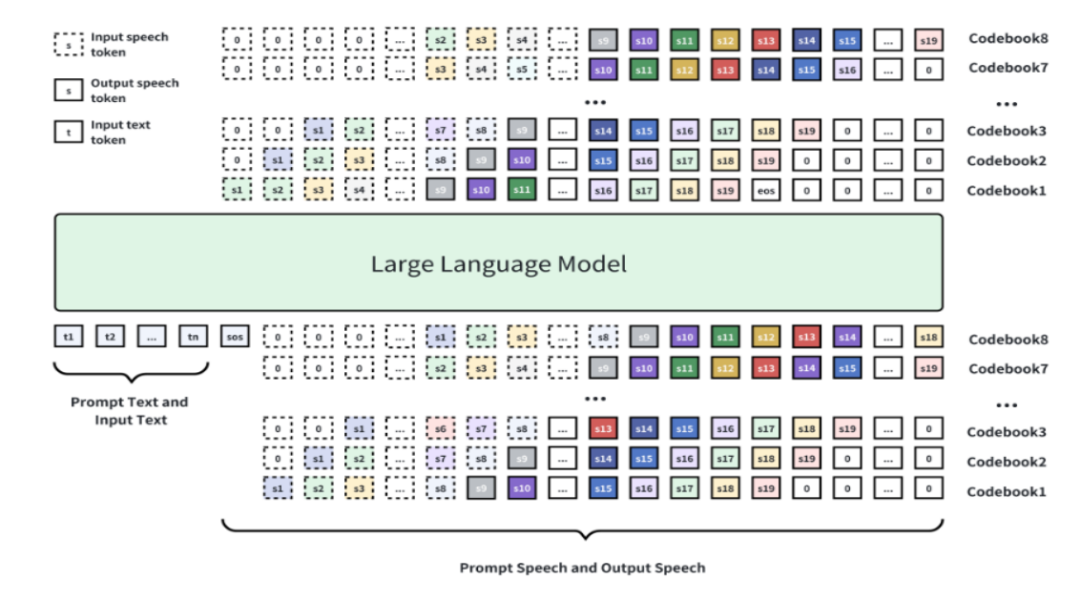
功能
- 高表现力对话语音生成:能够将对话脚本转换为自然、富有表现力的对话语音,准确捕捉对话中的韵律、语调等特性。
- 零样本多说话人音色克隆:支持根据对话脚本生成准确的对话者切换语音,无需额外样本即可实现两位对话者的音色克隆。
- 中英双语支持
- 长篇语音生成:基于低比特率编解码器和优化的训练框架,能够一次性生成超长语音,避免拼接语音片段的不自然过渡。
- 完全开源且商业就绪:模型权重、推理代码和API接口均已开源,支持免费商业使用。
原理
- 基础模型架构
MOSS-TTSD基于Qwen3 - 1.7B-base模型进行续训练,采用离散化语音序列建模方法。通过八层RVQ(Residual Vector Quantization)码本对语音进行离散化处理,将连续的语音信号转换为离散的Token序列。这些Token序列通过自回归加Delay Pattern的方式生成,最后通过Tokenizer的解码器将Token还原为语音。 - 语音离散化与编码器创新:XY - Tokenizer,专门设计的语音离散化编码器,采用双阶段多任务学习方式训练:
- 第一阶段:训练自动语音识别(ASR)任务和重建任务,让编码器在编码语义信息的同时保留粗粒度的声学信息。
- 第二阶段:固定编码器和量化层,仅训练解码器部分,通过重建损失和GAN损失补充细粒度声学信息。在1kbps的比特率和12.5Hz的帧率下,能同时建模语义和声学信息,性能优于其他同类Codec。
- 数据处理与预训练
使用约100万小时的单说话人语音数据和40万小时的对话语音数据进行训练。团队设计高效的数据处理流水线,从海量原始音频中筛选出高质量的单人语音和多人对话语音进行标注。使用110万小时的中英文TTS数据显著增强了语音韵律和表现力。 - 长语音生成能力
基于超低比特率的Codec,MOSS-TTSD支持最长960秒的音频生成,能一次性生成超长语音,避免了拼接语音片段之间的不自然过渡。
本地部署
conda create -n moss_ttsd python=3.10 -y && conda activate moss_ttsd
pip install -r requirements.txt
pip install flash-attn
# 下载模型
mkdir -p XY_Tokenizer/weights
huggingface-cli download fnlp/XY_Tokenizer_TTSD_V0 xy_tokenizer.ckpt --local-dir ./XY_Tokenizer/weights/
准备配置文件config.jsonl:
{
"base_path": "examples",
"text": "[S1]Speaker 1 dialogue content[S2]Speaker 2 dialogue content[S1]...",
"prompt_audio_speaker1": "path/to/speaker1_audio.wav",
"prompt_text_speaker1": "Reference text for speaker 1 voice cloning",
"prompt_audio_speaker2": "path/to/speaker2_audio.wav",
"prompt_text_speaker2": "Reference text for speaker 2 voice cloning"
}
使用:
- 命令行:
python inference.py --jsonl config.jsonl --output_dir outputs --seed 42 --use_normalize - Web UI:
python gradio_demo.py

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 32
32 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)