
AIGC工具平台-XTTS语音合成
本文介绍了XTTS语音合成模型的本地部署与应用流程,涵盖从环境配置到模型训练、推理的完整工作流。主要内容包括: 提供了XTTS整合包下载与环境部署指南,支持一键解压使用 详细说明了数据处理模块的功能,包括音频上传、Whisper自动转写及多语言支持 阐述了模型训练环节的关键配置参数,如训练轮数、批量大小等,并给出了常见错误解决方法 展示了WebUI推理界面,支持文本转语音、语音克隆等高级功能 该项
XTTS语音合成与文本转语音应用的需求正不断扩大,XTTS 模型作为开源语音合成框架,提供了完整的声音合成与合成能力。本项目构建了一个集训练、推理、增强与字幕转配音为一体的操作系统,适用于本地部署与批量处理任务。
文章将围绕 XTTS 模型的实际使用展开,从环境部署、数据处理、模型训练到Web界面交互,逐步呈现一个可运行的语音生成平台。内容适合学习构建 TTS 系统、模型训练及语音处理工作流的开发者参考。
操作使用
进入软件后在 整合包 里可以直接搜索 XTTS 进入该模块。
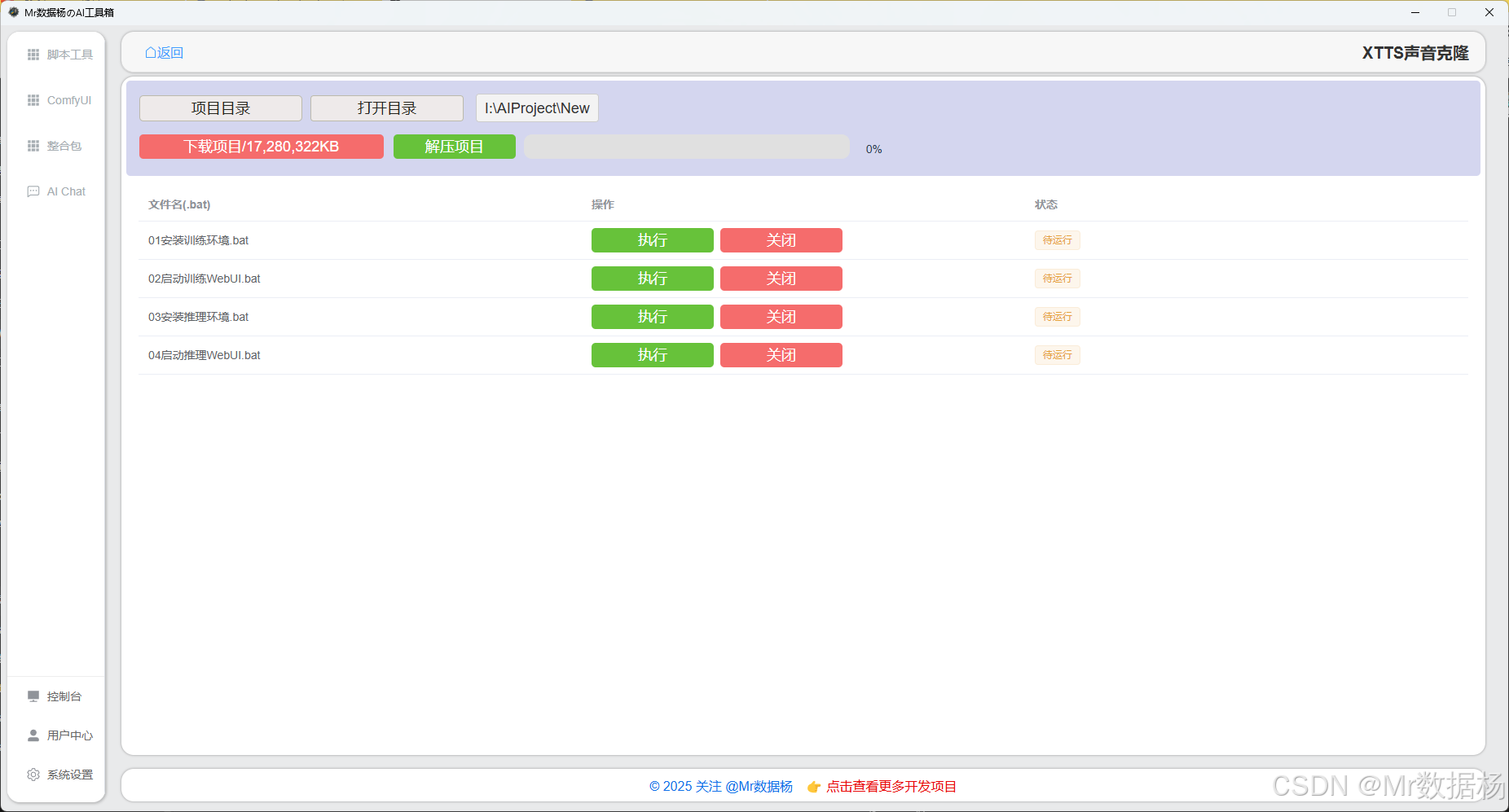
点击【下载选项卡】可获取完整项目整合包的下载地址,或直接使用下方链接下载。将文件保存至项目目录下后,点击解压按钮,等待解压完成即可开始使用。
| - | 说明 |
|---|---|
| 源码使用教程 | 基于XTTS的语音合成 |
| 整合包下载地址 | 基于XTTS的语音合成 |
项目脚本配置
通过 Gradio 或其他本地可视化工具提供图形化界面,用户可上传视频与音频并实时查看唇形同步效果,适合在本地测试与调整模型效果。只需运行脚本,待界面加载完成后即可在浏览器中访问操作界面,无需手动配置环境或命令行调用。
| 脚本名称 | 功能说明 |
|---|---|
| 01安装训练环境.bat | 安装模型训练所需的环境与依赖,为后续训练做好准备。 |
| 02启动训练WebUI.bat | 启动用于模型训练的图形化界面,可通过浏览器进行训练操作。 |
| 03安装推理环境.bat | 安装模型推理所需的依赖与运行环境,确保推理功能正常。 |
| 04启动推理WebUI.bat | 启动用于推理(语音合成或TTS)的图形化界面,在浏览器中进行语音生成操作。 |
应用示例
模型训练
XTTS 语音模型微调工作流中的第一步,用于将原始语音数据处理为标准化训练输入。通过结合上传音频、目录加载与 Whisper 自动识别文本,它可以高效生成对齐的音频-文本对,供后续模型训练使用。用户只需配置路径与参数,系统即可自动完成语音清洗、格式转换与字幕标注,是实现高质量语音合成训练的基础环节。
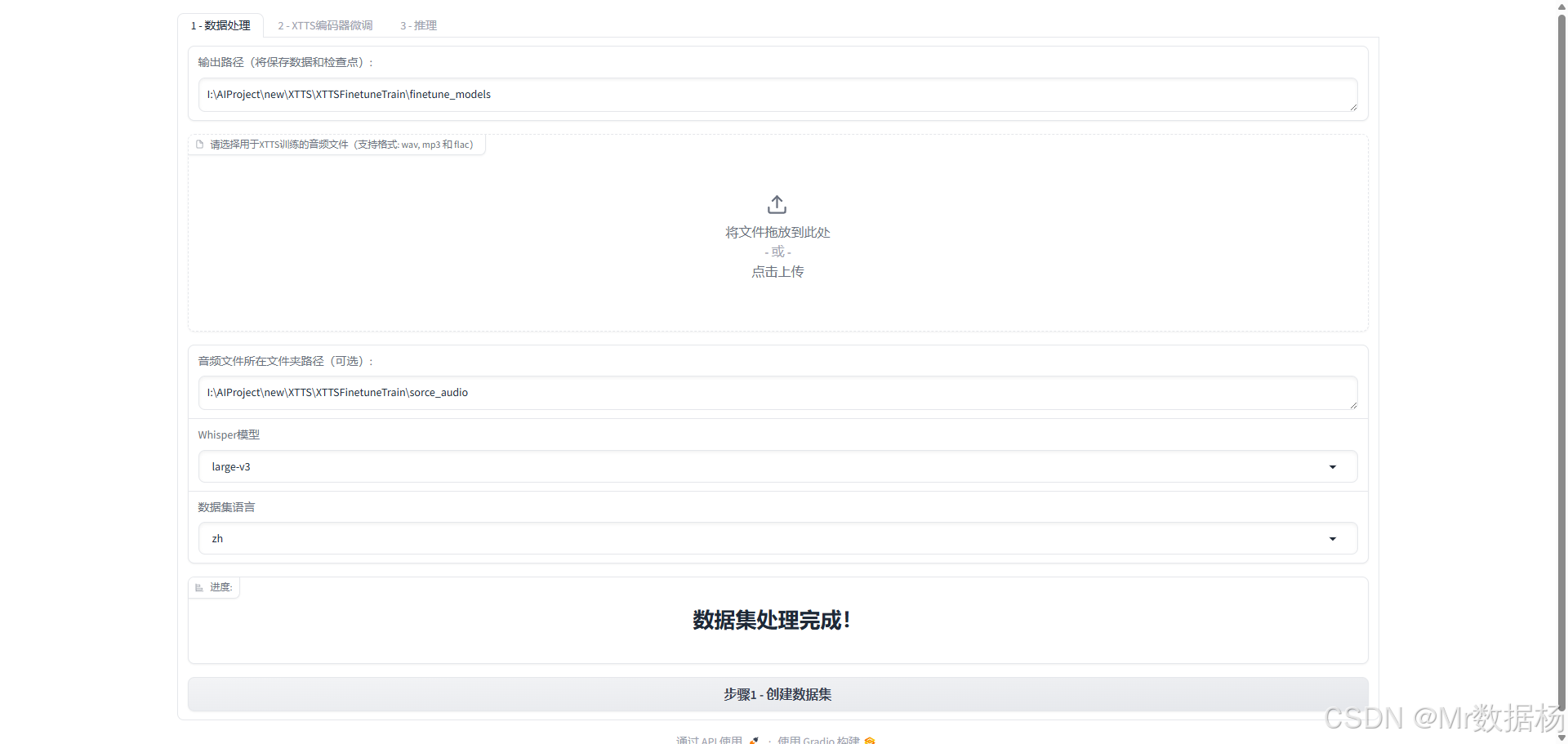
数据处理模块
本模块用于配置训练语音数据的输入路径、格式、语言与识别模型,以便后续微调 XTTS 模型(如语音合成)。它支持音频上传、路径指定、Whisper 自动转写及多语言识别,是语音数据集构建的核心环节。
| 功能项 | 描述 |
|---|---|
| 输出路径配置 | 指定数据处理后保存模型和中间结果的目标路径 |
| 音频上传区 | 拖入或点击上传语音文件(支持 wav、mp3、flac 格式) |
| 音频目录路径(可选) | 可直接指定本地已有音频数据所在的文件夹路径 |
| Whisper 模型选择 | 选择用于语音转文本(ASR)的 Whisper 模型版本(如 large-v3) |
| 数据语言选择 | 设置音频语言编码(如 zh 表示中文、en 表示英文) |
| “进度”区/提示输出 | 实时显示当前处理状态,例如“数据集处理完成!” |
执行会自动下载对应的whisper模型文件,然后再 finetune_models\dataset 目录下生成识别的结果数据
编码器微调
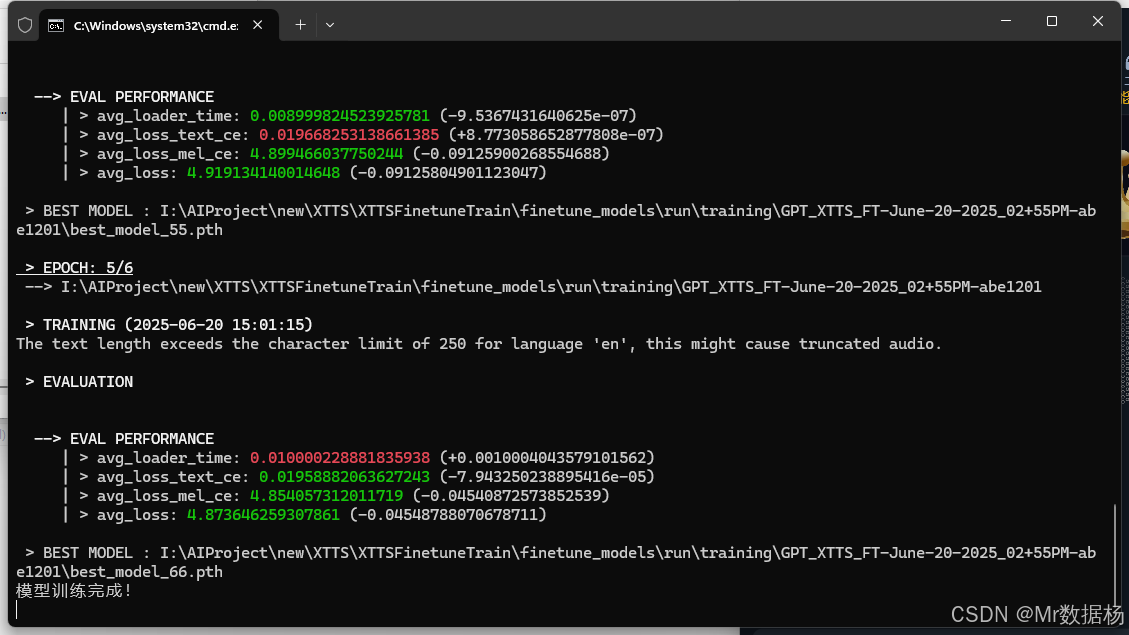
XTTS 模型微调的实质性步骤,用户在此配置核心训练参数并正式执行模型优化。系统支持自定义预训练模型继续训练,也可从头开始学习特定说话人风格。通过调整训练轮数、批量大小与音频长度限制,用户可灵活控制训练时长、资源消耗与模型精度。整体设计适合具备基础 AI 训练经验的用户使用,操作流程清晰明确,是高质量语音合成能力的关键落地环节。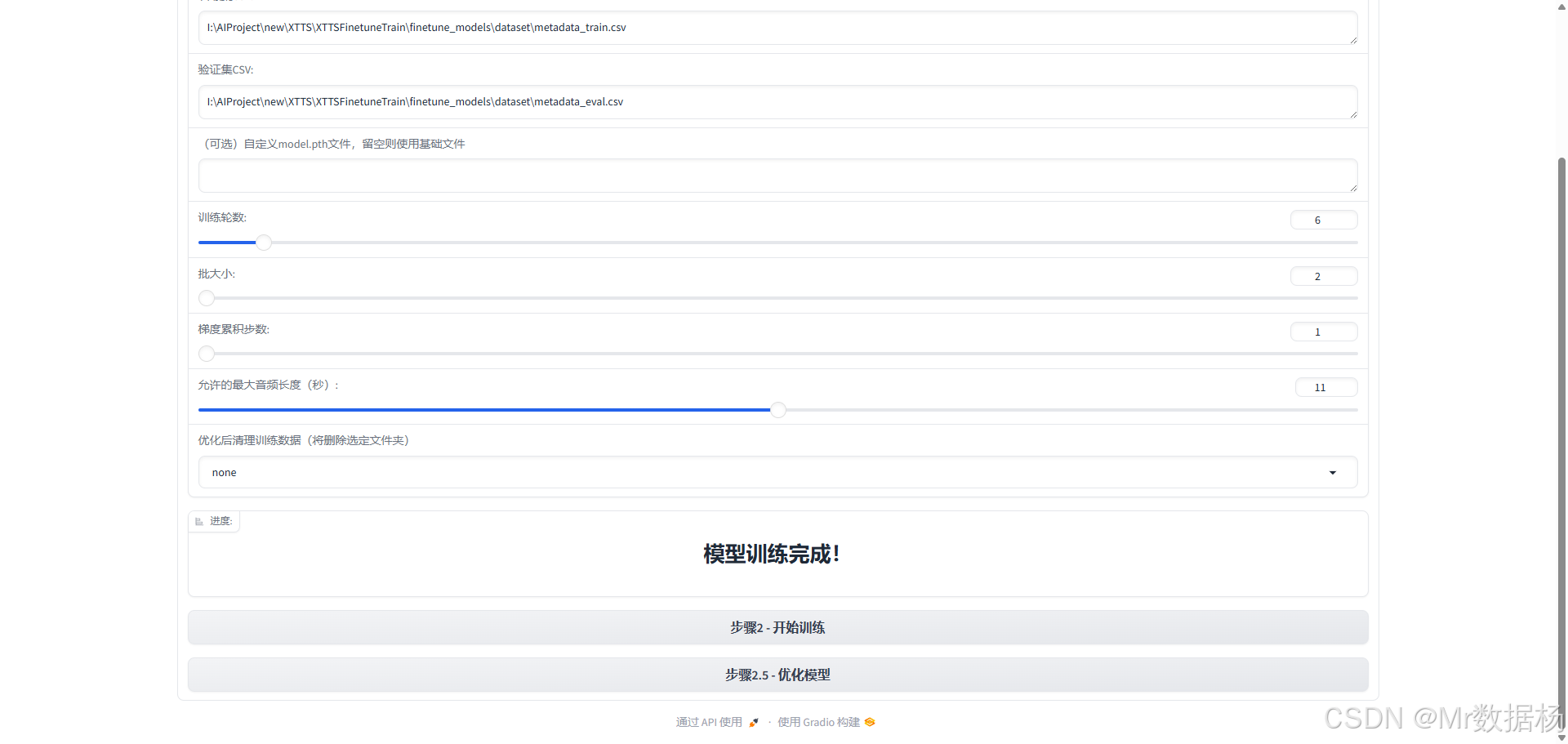
该模块用于设定 XTTS 语音合成模型的训练参数,涵盖训练数据路径、训练轮数、批处理大小、步长控制等核心设置。配置完成后,系统将启动模型训练并在终端输出训练进度。
| 功能项 | 描述 |
|---|---|
| 训练集 CSV 路径 | 指定包含训练音频与文本配对信息的 metadata_train.csv 路径 |
| 验证集 CSV 路径 | 指定验证集的 metadata_eval.csv 路径,用于评估训练效果 |
| 预训练模型路径(可选) | 可指定已有 .pth 模型作为初始点进行增量训练,留空则使用默认基线模型 |
| 训练轮数 | 设置训练 epoch 次数(如设置为 6 表示全数据集循环 6 轮) |
| 批大小 | 每轮训练中使用的样本数量,值越大显存占用越高 |
| 梯度累积步数 | 控制在多少步后更新梯度,辅助低显存设备训练 |
| 最长音频时长(秒) | 超出该长度的音频将在训练前被过滤,以避免异常样本影响 |
| 清理训练数据选项 | 训练完成后可选是否清理训练文件或临时数据 |
| 训练进度显示区域 | 输出训练状态,如“模型训练完成!”提示结果 |
这里第一次启动开始训练需要下载模型,确保网络畅通。
如果训练过程中出现
["The training was interrupted due an error !! Please check the console to check the full error message!
Error summary: Traceback (most recent call last):
File "E:\RVC\xtts-finetune-webui\xtts_demo.py", line 380, in train_model
speaker_xtts_path,config_path, original_xtts_checkpoint, vocab_file, exp_path, speaker_wav = train_gpt(custom_model,version,language, num_epochs, batch_size, grad_acumm, train_csv, eval_csv, output_path=output_path, max_audio_length=max_audio_length)
File "E:\RVC\xtts-finetune-webui\utils\gpt_train.py", line 177, in train_gpt
train_samples, eval_samples = load_tts_samples(
File "E:\RVC\xtts-finetune-webui\venv\lib\site-packages\TTS\tts\datasets\__init__.py", line 132, in load_tts_samples
meta_data_eval = formatter(root_path, meta_file_val, ignored_speakers=ignored_speakers)
File "E:\RVC\xtts-finetune-webui\venv\lib\site-packages\TTS\tts\datasets\formatters.py", line 74, in coqui
assert all(x in metadata[0] for x in ["audio_file", "text"])
File "E:\RVC\xtts-finetune-webui\venv\lib\site-packages\TTS\tts\datasets\formatters.py", line 74, in <genexpr>
assert all(x in metadata[0] for x in ["audio_file", "text"])
IndexError: list index out of range
", "", "", "", ""]
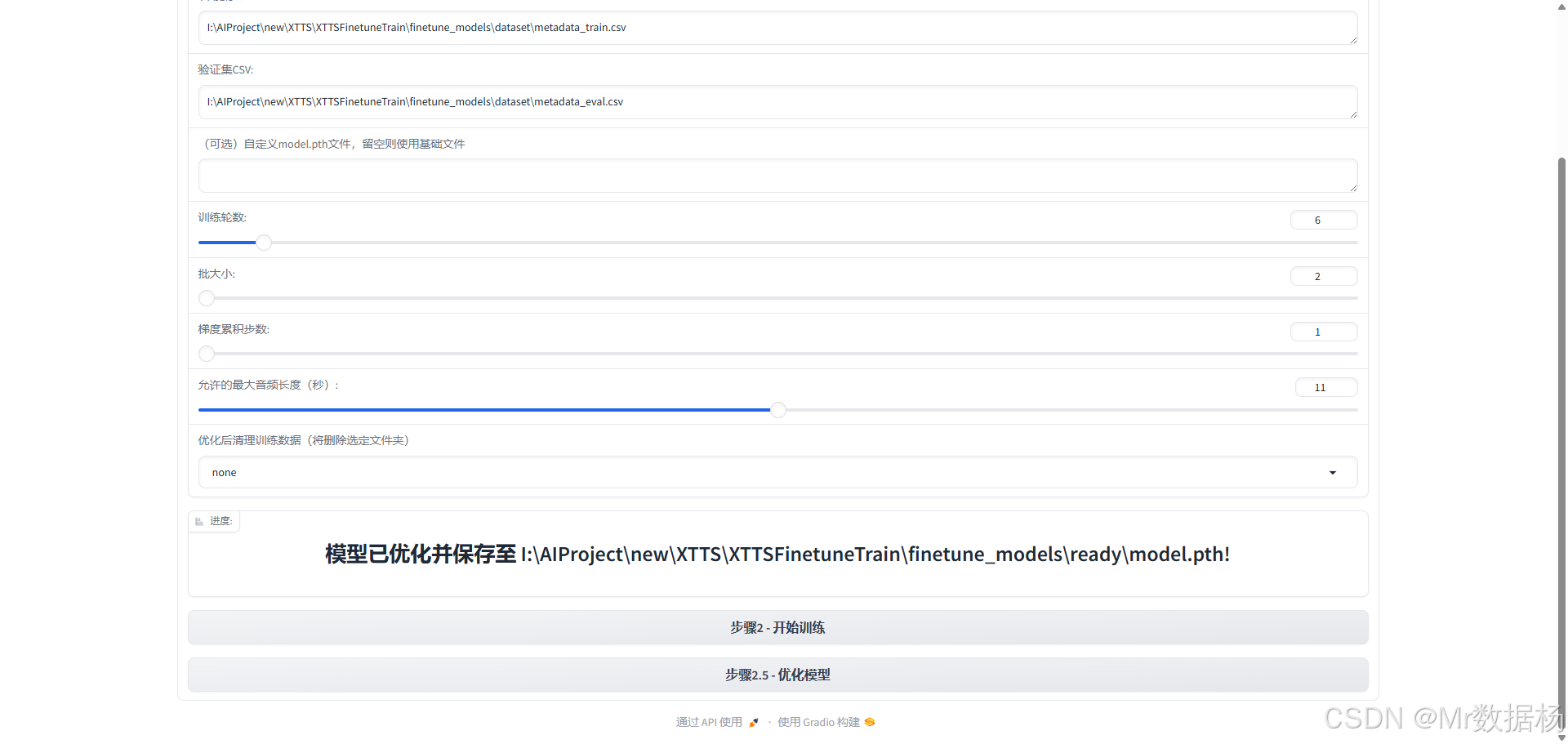
这个是数据集的问题需要自己手动修改 metadata_eval.csv 和 metadata_train.csv 文件,确保测试集和训练都要有数据。如果不行就多切换几种whisper方式进行生成训练样本数据,然后再进行训练。
然后点击优化模型会保存最终的模型 .pth 文件。
WebUI
文本转语音 XTTS-webui 提供了一个强大而灵活的本地文本转语音平台,涵盖从模型调用、文本输入、语音合成到输出增强的完整流程。它支持语言切换、参考语音风格模拟、训练样本管理、RVC/OpenVoice 混合增强以及导出格式控制等多项高级功能。界面结构清晰,功能模块分区合理,既满足语音合成的常规需求,也为发烧友和研究者提供深度调优能力,是专业语音合成工作的利器。
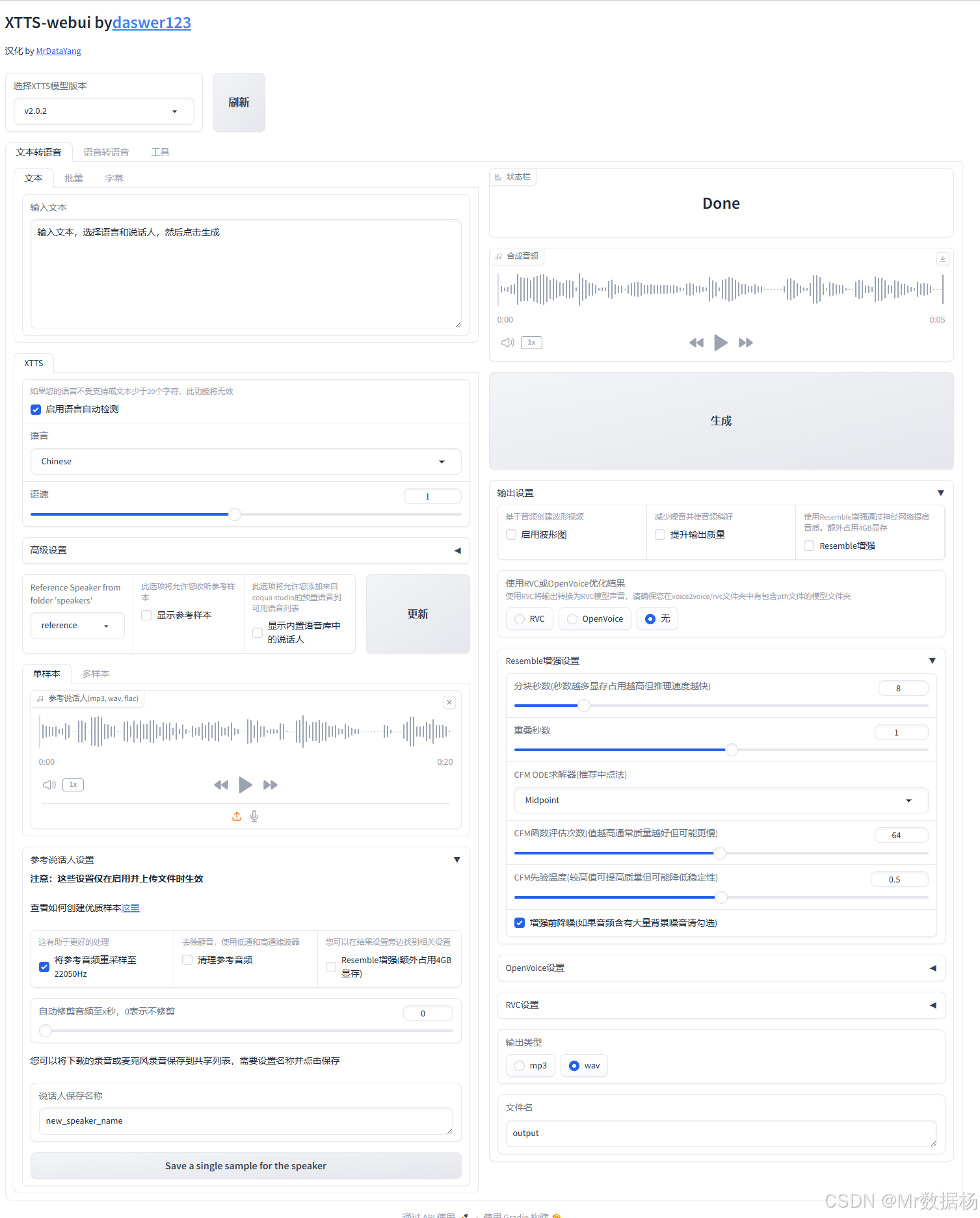
模型加载与版本控制模块
该模块用于选择当前运行的 XTTS 模型版本,并进行热更新,是系统初始化阶段的入口配置区域。
| 功能项 | 描述 |
|---|---|
| 模型选择下拉框 | 切换不同版本的 XTTS 模型(如 v2.0.2) |
| 刷新按钮 | 强制重新加载当前选择的模型及其配置 |
文本转语音输入模块
这是生成语音的核心入口,用户在此输入想要朗读的文本,然后点击右侧“生成”按钮即可听取合成语音。
| 功能项 | 描述 |
|---|---|
| 文本输入框 | 输入要被合成的文字内容 |
| 播放控制区域 | 合成完成后可在右侧播放试听 |
| 状态反馈 | 显示合成进度与完成状态(如 “Done”) |
语言与语速控制模块
该区域用于设置合成语音的语言类型(如中文/英文)与语速,适配多语种朗读场景。
| 功能项 | 描述 |
|---|---|
| 语言下拉框 | 选择朗读语种(如 Chinese、English) |
| 语速滑块 | 控制语音播放语速,数值越高语速越快 |
参考音色配置模块
该模块用于选择参考说话人,实现特定声音风格的合成。可从已有文件夹中调用样本,或上传新音频生成临时音色。
| 功能项 | 描述 |
|---|---|
| 参考音色文件夹选择 | 从已有“speakers”文件夹中选择一个参考音色 |
| 语音样本播放器 | 播放选中的参考音频文件以确认效果 |
| 上传按钮 | 上传新的 .wav/.mp3/.flac 文件作为参考样本 |
| 嵌入更新按钮 | 更新参考音色向量,供后续语音生成调用 |
声音样本管理与训练设置模块
这是对新参考声音样本进行处理的区域,支持添加新说话人、设置训练细节、指定样本名、保存嵌入等。
| 功能项 | 描述 |
|---|---|
| 训练配置滑块 | 设置样本片段数、训练轮数、使用的 GPU 内存等 |
| 保存按钮 | 保存当前音色为新说话人样本,生成语者嵌入向量 |
| 新建语者命名输入框 | 指定保存该参考音色的唯一标识名 |
输出设置与格式控制模块
该模块控制语音生成时的格式与后处理方式,如是否使用 RVC/OpenVoice 混合、导出格式等。
| 功能项 | 描述 |
|---|---|
| 输出增强选项 | 是否启用高保真增强器,如 OpenVoice/RVC |
| 文件输出格式选择 | 支持 .mp3 或 .wav 导出 |
| 文件名设置 | 自定义生成音频的文件名 |
混合音频设置(Resemble/OpenVoice/RVC)
该区域针对不同后处理器提供更细化的控制项,提升语音质量或实现风格迁移。
| 功能项 | 描述 |
|---|---|
| Resemble 权重 | 控制语音生成时语音风格和原始样本之间的融合程度 |
| RVC 重采样等级 | 控制是否重采样用于增强语音的清晰度(如 0 为关闭) |
| OpenVoice 权重 | 可调节增强比例,用于改善声音细节表现 |
| 混音参数设置项(CFM) | 包括中点位置、频段范围、信号比例等参数,精细控制音质表现 |
字幕文件转录 融合了文本提取、语言配置、音色合成和语音增强四大功能,允许用户将完整字幕文件自动转化为连续语音内容,并配合特定音色生成统一风格的配音结果。它适合影视本地化、多语言播报、教育字幕配音等批量 TTS 应用场景,同时支持输出高质量 .mp3/.wav 文件,是文本字幕向声音输出的高效桥梁。
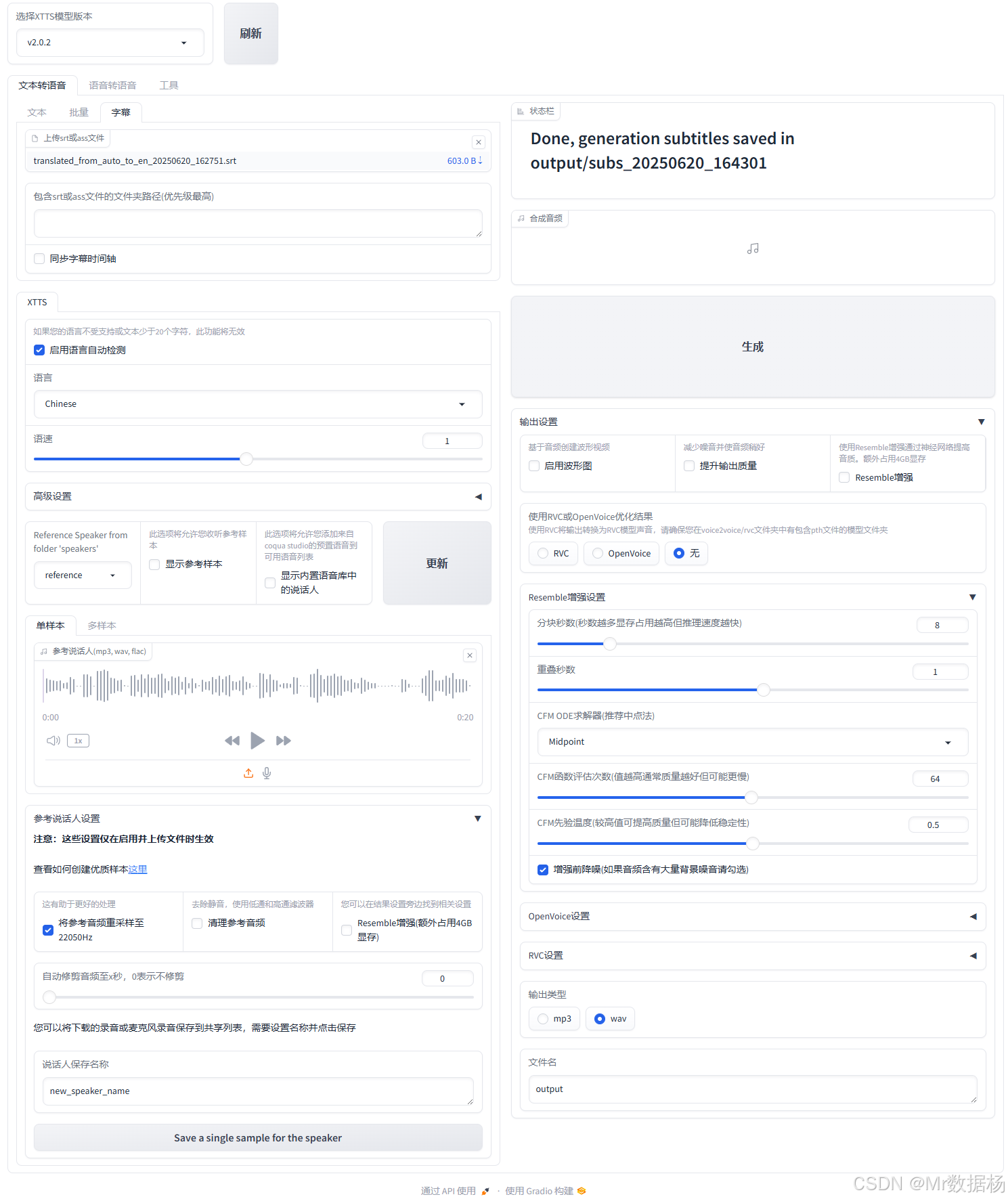
字幕输入与处理模块
本模块用于上传 .srt 或 .vtt 字幕文件,系统会自动提取其中的文本片段作为语音合成内容,适合用于影视剧配音、翻译播报等场景。
| 功能项 | 描述 |
|---|---|
| 字幕文件上传框 | 上传字幕文件(如 translated_from_auto_to_en_xxx.srt) |
| 字幕语言同步开关 | 可勾选是否同时翻译/输出字幕语种对应的语音内容 |
| 文件路径展示 | 显示当前已加载字幕文件的文件名与大小 |
文本合成状态与进度模块
用于显示字幕处理及语音生成的状态,包括合成完成提示、日志反馈及错误提醒等。
| 功能项 | 描述 |
|---|---|
| 状态文本区域 | 显示“Done”标志及生成结果保存路径(如 output/subs_时间戳) |
| 合成日志输出框 | 实时反馈语音生成过程状态,方便定位错误或检查进度 |
语言与语速设置模块
此处决定生成语音的语言类型和朗读语速,是跨语种字幕合成时的关键参数。
| 功能项 | 描述 |
|---|---|
| 语言下拉框 | 指定语音输出的目标语言(如 Chinese、English) |
| 语速滑块 | 调整朗读语音的语速,适配不同说话节奏 |
参考音色配置模块
用于选择并加载已有的参考说话人音色,实现字幕语音合成为特定声音风格,是配音一致性的关键环节。
| 功能项 | 描述 |
|---|---|
| 参考说话人选择 | 从文件夹 speakers 中选择一个参考音色 |
| 音频播放器 | 播放参考语音片段确认风格是否匹配 |
| 上传音频 | 支持上传 .wav/.mp3/.flac 音频用于语音风格提取 |
| 更新按钮 | 用当前音频重新生成嵌入并更新合成风格 |
输出设置与增强模块
控制语音生成的输出格式(mp3/wav)、语音增强方式(如 RVC、OpenVoice),提升合成音质与真实感。
| 功能项 | 描述 |
|---|---|
| 输出格式选择 | 可选择生成 .mp3 或 .wav 音频 |
| 输出路径设置 | 设置生成音频的保存文件名和路径 |
| 增强方式选择 | 是否启用 OpenVoice 或 RVC 模型对语音进行增强处理 |
| Resemble混响设置 | 控制语音混响、频率分布等特征强化 |
| CFM ODE 参数 | 微调增强强度、效果范围、灵敏度等 |
| 嵌入保存与新说话人命名 | 可保存当前参考声音并命名为新语者,便于后续复用 |
语音转语音翻译 集成了音频识别(ASR)、自动翻译(MT)、字幕生成与语音合成预设,是一个完整的语音翻译与字幕制作工作流平台。用户仅需上传一段语音,系统即可智能识别语言内容、自动翻译并输出字幕格式,甚至进一步配合 XTTS 生成跨语种配音。其翻译精度、处理灵活性和导出格式支持,适用于教育字幕生成、影片本地化、跨境教学等多场景应用。
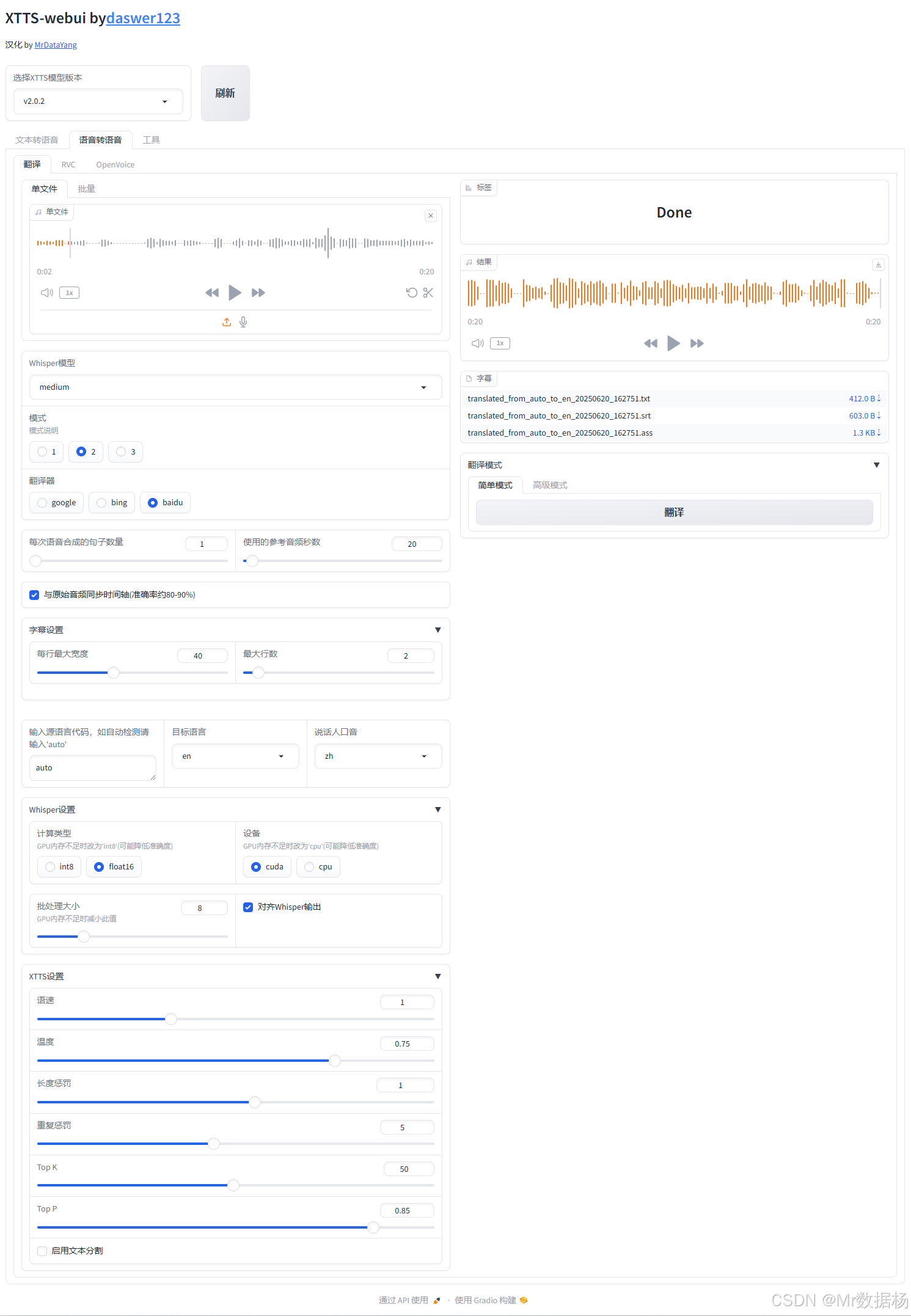
音频输入与播放模块
该模块用于上传音频文件进行语音识别,支持多种格式。用户可试听上传的音频片段,并在左侧波形区域观察其结构。
| 功能项 | 描述 |
|---|---|
| 上传音频区域 | 支持 .wav、.mp3 等格式上传 |
| 音频播放控制 | 播放已上传音频,支持暂停、跳转 |
| 波形可视化图 | 显示音频声波结构,便于观察语音段落位置 |
识别与翻译配置模块
这是设置 Whisper 模型进行语音识别及翻译流程的核心区域。可选择模型大小、语言、翻译方式及相关翻译引擎。
| 功能项 | 描述 |
|---|---|
| Whisper 模型选择 | 选择识别模型精度(如 medium, large, small 等) |
| 语言检测方式 | 可指定原语言或设置为 auto 自动识别 |
| 翻译目标语言 | 指定识别后要翻译成的语言(如 en, zh) |
| 使用翻译引擎 | 支持调用 google、bing、baidu 等翻译服务 |
| 翻译模式选择 | 可切换为简单模式或高级模式(默认简单) |
| 翻译按钮 | 启动翻译任务并生成 .txt、.srt、.ass 字幕文件 |
字幕与结果导出模块
处理完成后将自动生成字幕文件,显示在右侧结果栏,并允许用户直接点击下载。支持多种格式导出,适用于视频配音、翻译标注等任务。
| 功能项 | 描述 |
|---|---|
| 状态提示栏 | 显示识别和翻译完成标志,如“Done” |
| 字幕结果播放器 | 播放处理后自动对齐语音的片段(和字幕同步) |
| 导出文件列表 | 显示 .txt、.srt、.ass 格式的字幕结果并可直接下载 |
识别与翻译行为控制模块
提供若干高级控制项,用于细粒度调节识别精度、翻译行为及输出字幕的可读性。适用于需要特定格式控制的用户。
| 功能项 | 描述 |
|---|---|
| 每次最大生成字数限制 | 控制单段字幕文本的最大长度 |
| 分段最大静音时长 | 超过该静音时间将自动分割为新段落 |
| 字幕行长与数量 | 控制字幕输出格式,如每行最大字符数与最大行数 |
| Whisper计算精度与推理设备选择 | 设置推理时使用 int8/float16 以及 cuda/cpu 运算方式 |
| 批处理线程数 | 控制同时处理的音频任务线程数量(适用于并行处理) |
XTTS语音参数设置模块
下方区域提供与 XTTS 模型相关的音色生成参数设置,适用于识别后直接合成目标语言语音(多用于转译 TTS)。
| 功能项 | 描述 |
|---|---|
| 温度/Top-K/Top-P | 控制语音输出的随机性、多样性与采样范围 |
| 重复惩罚/长度惩罚 | 用于限制输出内容冗余与调整语速、停顿表现 |
| 应用文本分割 | 启用自动根据标点/停顿拆分为适合语音生成的片段 |
音质增强 工具页提供了一套完整的语音清洗与增强处理方案,适用于提升语音数据集质量、优化语音合成前处理,或提升已合成语音的听感表现。通过灵活的操作模式与可调参数,用户可以在去噪、增强或两者结合间自由切换,并即时对比结果,确保语音数据在各类语音任务中达到最优表现。工具界面直观、功能细致,是语音处理流程中不可或缺的增强环节。
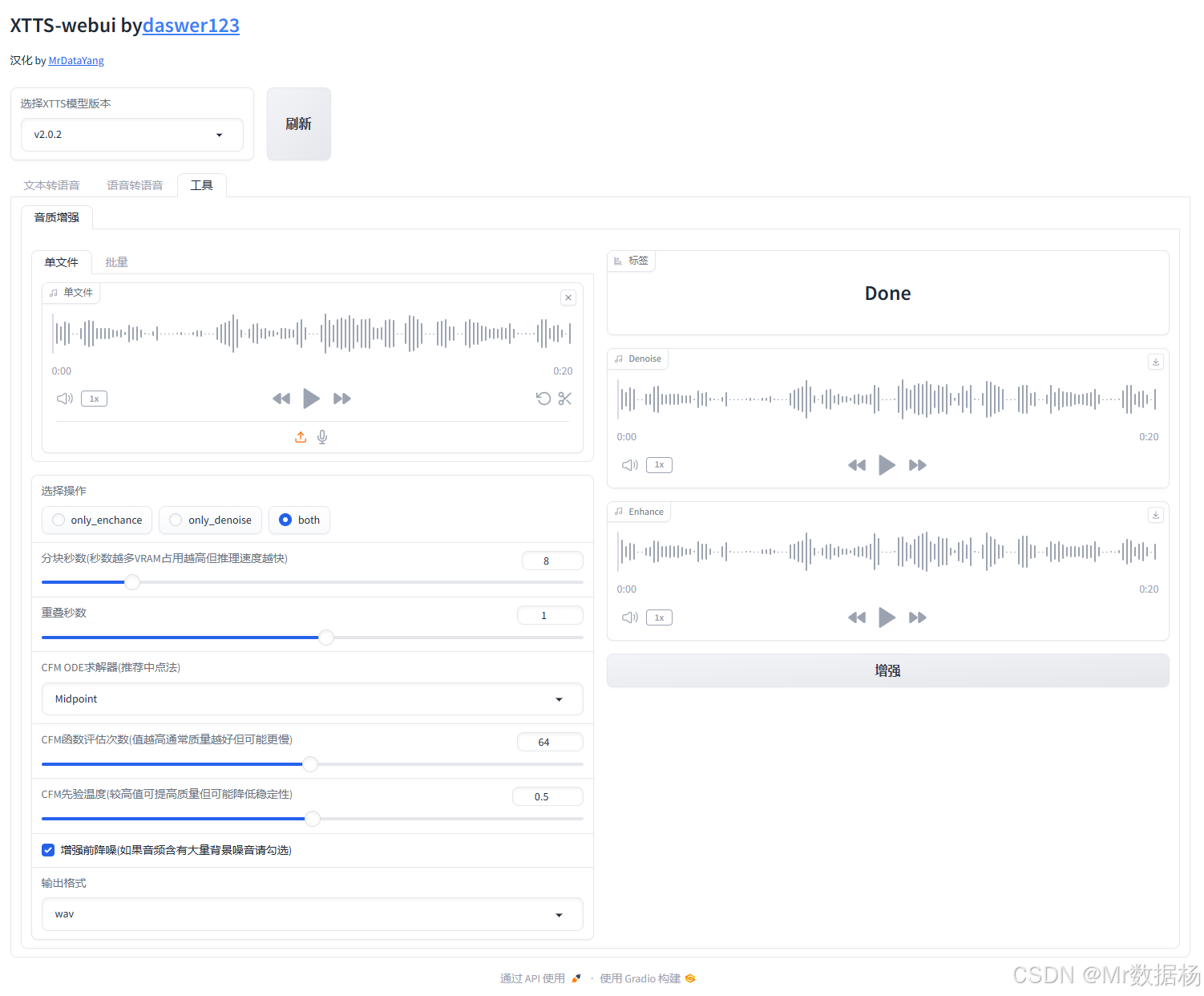
音频上传与预览模块
该模块允许用户上传原始语音片段,并在页面中进行播放试听。用户可确认噪声干扰或发音质量是否需要处理。
| 功能项 | 描述 |
|---|---|
| 音频上传区域 | 拖拽或选择本地音频文件上传(支持 wav 等格式) |
| 播放器 | 试听原始音频片段,波形可视化显示 |
| 播放控制按钮 | 控制播放、暂停、跳转,便于逐句校验 |
| 波形显示 | 展示原始音频声波,有助于观察语音密度与背景杂音结构 |
处理模式选择模块
在进行音频处理前,用户需选择操作模式:只去噪(Denoise)、只增强(Enhance)或两者同时(Both),适配不同清洗需求。
| 功能项 | 描述 |
|---|---|
| only_denoise | 仅执行去噪,适用于背景噪音较多的情况 |
| only_enhance | 仅执行音质增强,提升清晰度和响度 |
| both | 同时执行去噪和增强,推荐用于一般语音清洗流程 |
增强参数控制模块
用于微调增强算法的关键参数,影响处理强度与速度,适合追求不同处理精度或硬件适配的用户使用。
| 参数项 | 描述 |
|---|---|
| 分块数量 | 控制音频处理时的分块程度,越大越细致但占用 VRAM |
| 重叠参数 | 音频块之间的交叠程度,影响平滑过渡与去噪效果 |
| CFM ODE 求解器 | 算法中处理策略(如 Midpoint、RK4 等) |
| CFM 频段分区数量 | 控制频域分析的分辨率,值越高处理越精细,但处理时间越长 |
| CFM热敏感度 | 调节高频率敏感度,数值越大越激进,可能去除更多噪音 |
| 增强时修复缺帧 | 若语音存在卡顿或跳帧问题,启用此项以平滑过渡 |
输出结果与试听模块
处理完成后,系统会展示处理后的两种音频版本(去噪与增强),用户可直接进行 AB 对比,检验效果是否达标。
| 功能项 | 描述 |
|---|---|
| Denoise 播放器 | 播放去噪后的音频,突出背景清理 |
| Enhance 播放器 | 播放增强后的音频,突出语音音质 |
| Done 提示区 | 显示处理已完成并更新播放组件 |
输出设置模块
用户可自定义音频输出格式,当前支持 .wav 格式导出,未来版本可能扩展其他格式。
| 功能项 | 描述 |
|---|---|
| 输出格式选择 | 设置最终输出文件的格式(默认 WAV) |
总结
XTTS 模型整合包提供了简洁完整的语音合成操作路径。从数据预处理到模型训练,再到本地部署的文本转语音系统,整个流程依赖图形界面完成,大幅降低了环境配置与指令调用的门槛。无论是语音样本管理、参考音色合成,还是字幕转语音、翻译合成等流程,均可在浏览器中直观控制,适合构建定制化语音生成工具。通过 Gradio 等本地化工具,训练与推理功能可以在不同机器上高效复现。
未来可探索自动化训练流程优化、引入更高质量的音频增强算法,并尝试云端部署方式实现跨平台接入。同时,提升对异常样本的容错能力,加入更多智能提示机制,也将进一步增强 XTTS 在教育、影视、播报等实际场景下的应用体验。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 28
28 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)