
【博学谷学习记录】超强总结,用心分享|狂野大数据课程 【MapReduce组件】
1、定义类继承Partitioner类2、重写getPartition方法,在该方法中对每一个K2和V2打标记,标记从0开始,0标记的键值对会被0编号的Reduce拉取进行聚合,1标记的键值对会被1编号的Reduce进行聚合/*** @param i Reduce的个数* @return*/@Override// 长度>=5的单词打标记为0// 长度小于5的单词打标记为1return 0;3、设置
一、分布式计算历代引擎
第一代:MapReduce(MR) 离线分析
第二代:Tez 离线分析
第三代:Spark 离线分析 + 实时分析
第四代:Flink 离线分析 + 实时分析
第五代:Doris , kylin ,ClickHouse, ES,
二、MapReduce的思想
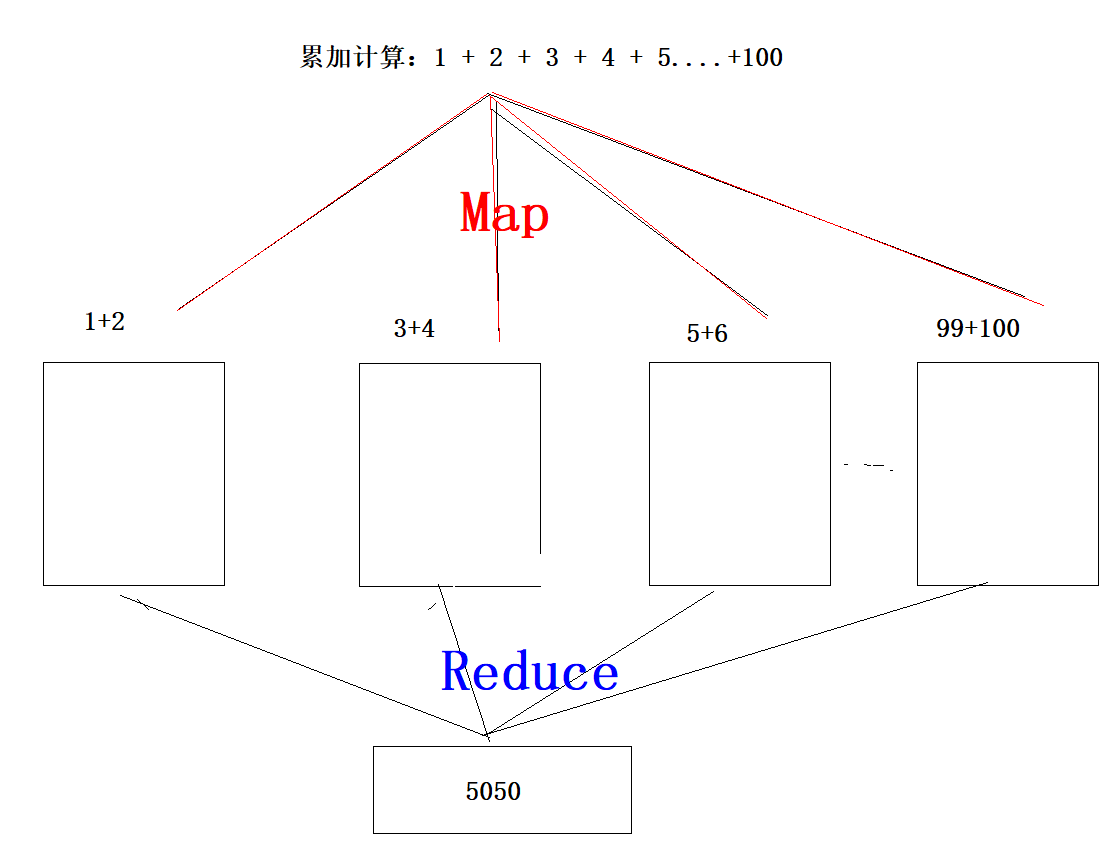
1、MapReduce有两个阶段,一个Map阶段,负责任务的拆分,一个Reduce阶段负责任务的合并
2、MapReduce将一个大的任务进行拆分,拆分成小任务,拆分之后,放在不同的主机上运行,运行之后再将这些结果合并
3、MapReduce整个处理过程就是将原始数据转成一个个键值对,然后不断的对这些键值对进行迭代处理,直到得到最理想的键值对位,最后的键值对就是我们想要的结果
2.1 MapReduce的分区
自定义分区代码编写思路:
1、定义类继承Partitioner类
2、重写getPartition方法,在该方法中对每一个K2和V2打标记,标记从0开始,0标记的键值对会被0编号的Reduce拉取进行聚合,1标记的键值对会被1编号的Reduce进行聚合
public class MyPartitioner extends Partitioner<Text, LongWritable> {
/**
*
* @param text K2
* @param longWritable V2
* @param i Reduce的个数
* @return
*/
@Override
public int getPartition(Text text, LongWritable longWritable, int i) {
// 长度>=5的单词打标记为0
// 长度小于5的单词打标记为1
if(text.toString().length() >= 5){
return 0;
}else {
return 1;
}
}
}
3、设置job你的自定义分区类
job.setPartitionerClass(MyPartitioner.class);
4、在主类中要设置Reduce的个数为
job.setNumReduceTasks(2);
默认分区代码
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public HashPartitioner() {
}
//根据每一个K2的hash进行分区,分区的效果是:每一个Reduce可以均衡的聚合数据
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & 2147483647) % numReduceTasks;
}
}
//----------------------------------------------------------------------
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public HashPartitioner() {
}
//根据每一个K2的hash进行分区,分区的效果是:每一个Reduce可以均衡的聚合数据
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode()+随机数 & 2147483647) % numReduceTasks;
}
}2.2 MapReduce的自定义类案例
数据为以下类型:
|
时间 |
县名 |
州名 |
县编码 |
确诊人数 |
死亡人数 |
|
2021-01-28 |
Autauga |
Alabama |
01001 |
5554 |
69 |
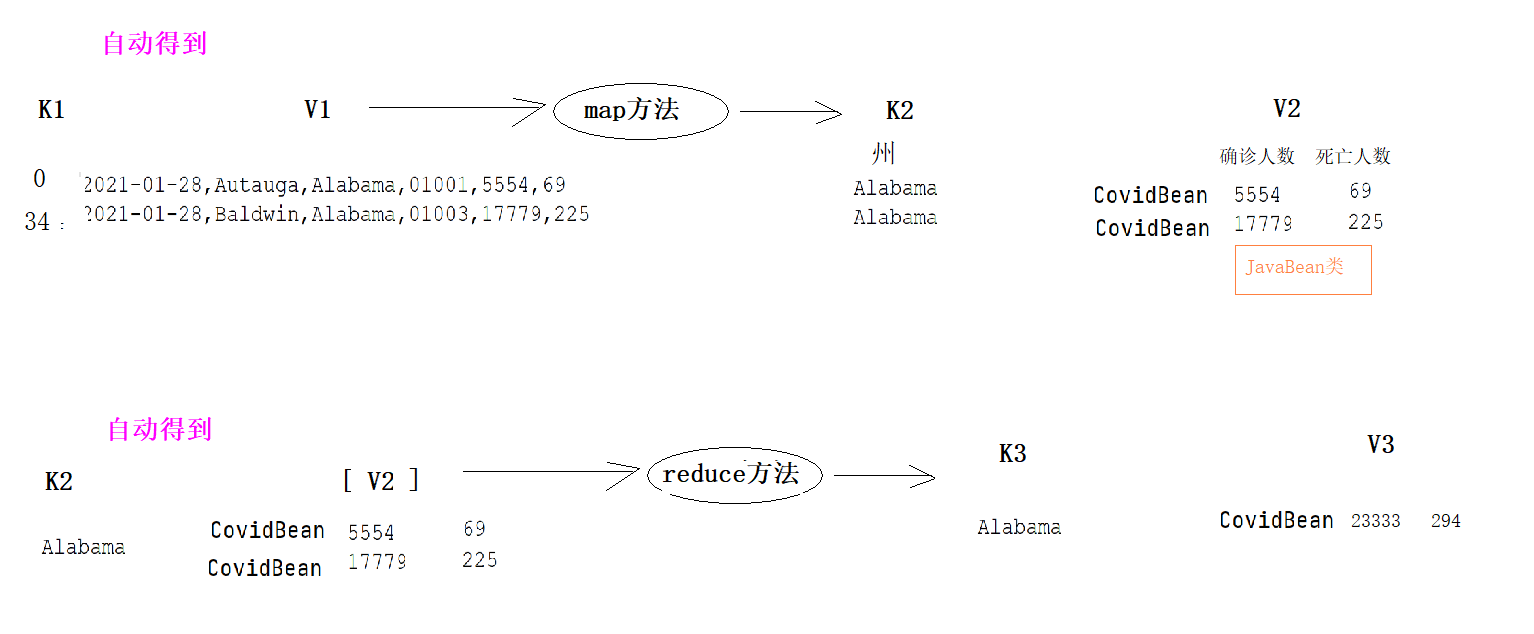
思路:
1、将州名作为K2,将确诊人数 死亡人数作为V2
2、可以将V2封装成一个Java类,如果一个自定义类出现在MapReduce中,必须保证该类能够被序列化和反序列化
--方式1:实现Writable
#应用场景:JavaBean类对象不作为K2,不需要能够被排序
public class CovidBean implements Writable {
//实现序列化
@Override
public void write(DataOutput out) throws IOException {
}
//实现反序列化
@Override
public void readFields(DataInput in) throws IOException {
}
}
--方式2:#应用场景:JavaBean类对象作为K2,需要能够被排序
public class CovidBean implements WritableComparable<CovidBean> {
//定义类对象排序的比较规则
@Override
public int compareTo(CovidBean o) {
return 0;
}
//实现序列化
@Override
public void write(DataOutput out) throws IOException {
}
//实现反序列化
@Override
public void readFields(DataInput in) throws IOException {
}
}2.3MapReduce的排序
-
需求
#数据
Alabama 452734 7340
Alaska 53524 253
Arizona 745976 12861
#要求
基于以上数据对确诊病例数进行降序排序,如果确诊病例数相同 ,则按照死亡病例数升序排序
select * from A order by cases desc , deaths asc;
-
思路
1、MR的排序只能按照K2排序,哪个字段要参与排序,则哪个字段就应该包含在K2中
2、如果你自定义类作为K2,则必须指定排序规则,实现WritableComparable接口,重写compareTo方法,其他的地方不需要再做任何的设置

2.4MapReduce的串联
介绍:
当我们在使用MapReduce进行大数据分析时,很多时候使用一个MR并不能完成分析任务,需要使用多个MR进行串联
则我们可以使用MR提供的Job控制器来实现多个MR的依赖串联执行
//todo 将普通的作用包装成受控作业
ControlledJob cj1 = new ControlledJob(configuration);
cj1.setJob(job1);
//todo 将普通的作用包装成受控作业
ControlledJob cj2 = new ControlledJob(configuration);
cj2.setJob(job2);
//todo 设置作业之间的依赖关系
cj2.addDependingJob(cj1);
//todo 创建主控制器 控制上面两个作业 一起提交
JobControl jc = new JobControl("myctrl");
jc.addJob(cj1);
jc.addJob(cj2);
//使用线程启动JobControl
Thread t = new Thread(jc);
t.start();
while (true){
if(jc.allFinished()){
System.out.println(jc.getSuccessfulJobList());
jc.stop();
break;
}
}2.5mapreduced逻辑切片
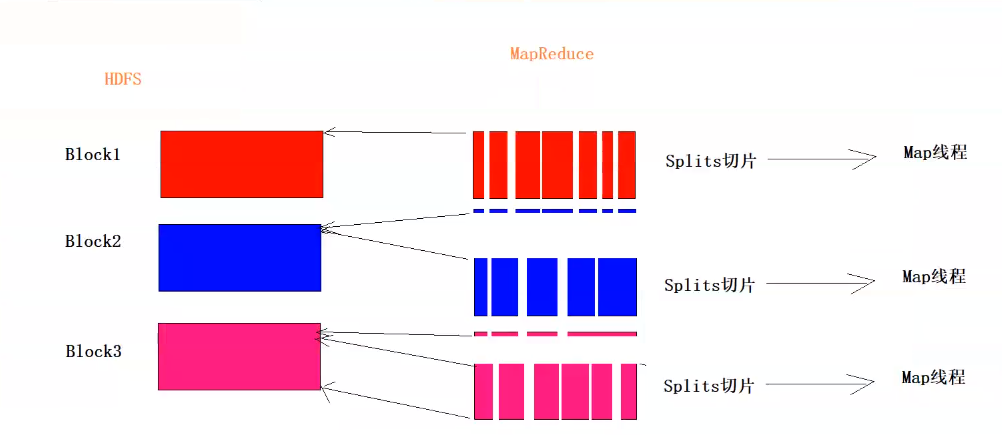
block1向后多读一行(多读一个换行符)
2.6mapreduced规约(combiner)
介绍:
1、规约是MapReduce的一种优化手段,可有可无,有了就属于锦上添花,有或者没有,都不会改变最终的结果
2、规约并不是所有MapReduce任务都能使用,前提是不能影响最终结果
3、规约主要是对每一个Map端的数据做提前的聚合,减少Map端和Reduce端传输的数据量,提交计算效率
4、规约可以理解为将Reduce端代码在Map端提前执行
5、如果你的规约代码和Reducer代码一致,则规约代码可以不用写,直接使用Reducer代码即可
job.setCombinerClass(WordCountReducer.class);
6.规约算平均值会出现精度损失
代码编写步骤:
1、自定义一个combiner继承Reducer,重写reduce方法,逻辑和Reducer一样
2、在job中设置:
job.setCombinerClass(CustomCombiner.class)
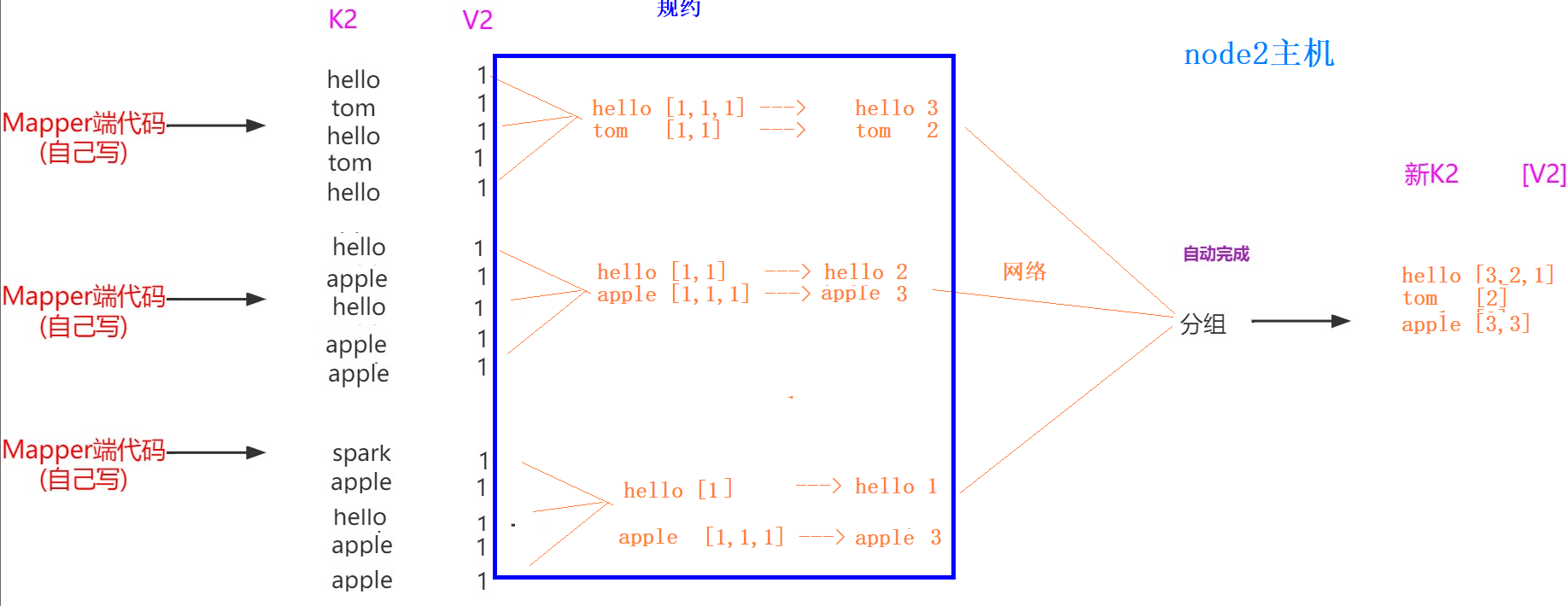
2.7mapreduced分组
介绍:
1、分组是对Map端传输过来的数据进行去重聚合
# K2 V2
hello 1
hello 1 --分组--> hello [1,1,1] --reduce方法--> hello 3
hello 1
world 1 2、分区和分组区别?
分区是决定K2和V2去往哪一个Reduce进行处理
分组是在同一个Reduce内部进行聚合
3、一般默认的分组就能完成分析操作,但是有时候在特定场景下,默认的分组不能满足我们的需求,则需要我们自定义分组
需求:
找出美国每个州state的确诊案例数最多的县county是哪一个。该问题也是俗称的TopN问题。
select * from t_covid order by cases desc limit 1;
找出美国每个州state的确诊案例数最多前三个县county是哪些。该问题也是俗称的TopN问题。
select * from t_covid order by cases desc limit 3;思路:
#如何自定义分组
1、写类继承 WritableComparator,重写Compare方法。
2、job.setGroupingComparatorClass(xxxx.class);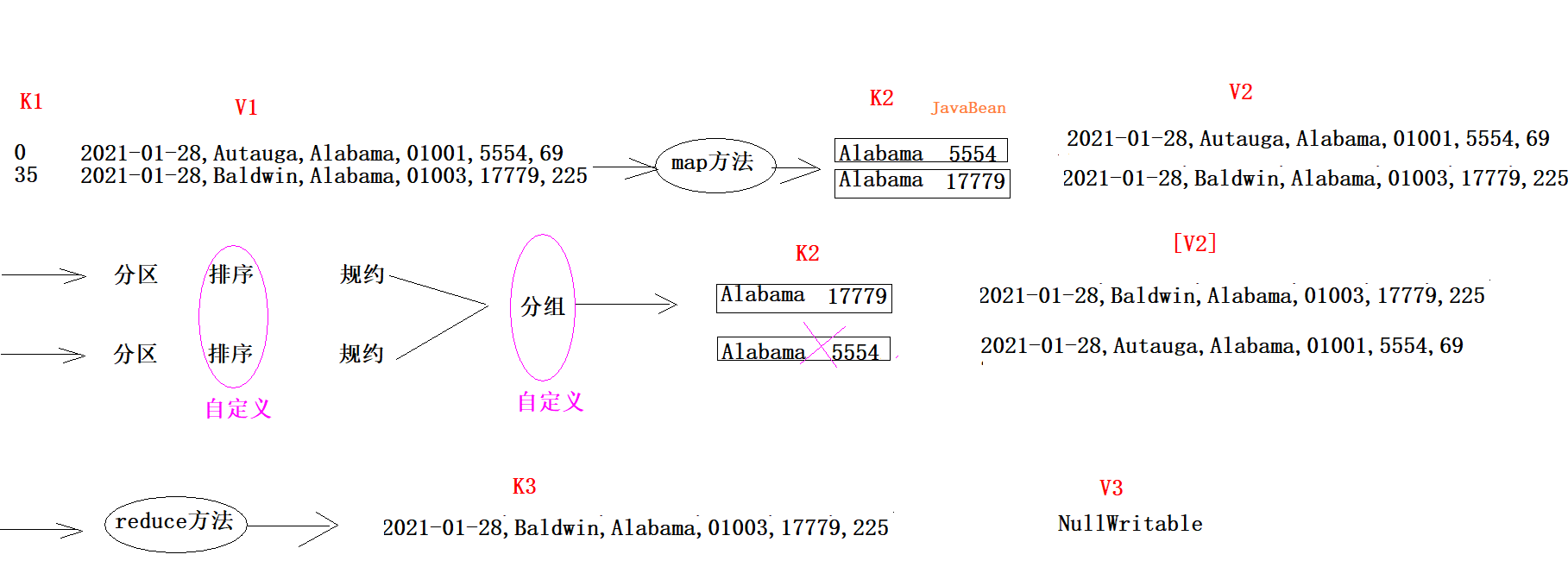
相同州名,分组后只留下一个K2
//1.自定义类
public class MyGroupingComparator extends WritableComparator {
//2.编写无参构造,将自定义类传给父类
/*
参1:表示传给父类的JavaBean类型
参2:表示允许父类通过反射造子类对象
*/
public MyGroupingComparator(){
super(GroupingBean.class,true);
}
//3.在该方法中指定分组的规则:两个GroupingBean对象只要state是一样的,就应该分到同一组
//这个方法会被自动调用,只要该方法返回0,则两个GroupingBean对象会被分到同一组
@Override
public int compare(WritableComparable a, WritableComparable b) {
GroupingBean g1 = (GroupingBean) a;
GroupingBean g2 = (GroupingBean) b;
//如果g1,g2的州相同,应该return 0
return g1.getState().compareTo(g2.getState());
}
}
技术共进,成长同行——讯飞AI开发者社区
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)