
目标检测系列2——R-CNN(IoU和非极大抑制代码)
目录1 R-CNN1.1 简介1.2 结构1.3 特点2 实现1 R-CNN1.1 简介1.2 结构1.3 特点2 实现
目录
1 R-CNN
1.1 简介
R-CNN的全称是Region-CNN,是第一个成功将深度学习应用到目标检测上的算法。
在CVPR 2014年中Ross Girshick提出R-CNN。论文名称:用于精确的对象检测和语义分割的丰富功能层次结构(Rich feature hierarchies for accurate object detection and semantic segmentation
不使用暴力方法,而是用候选区域方法(region proposal method),创建目标检测的区域改变了图像领域实现物体检测的模型思路,R-CNN是以深度神经网络为基础的物体检测的模型 ,R-CNN在当时以优异的性能令世人瞩目,以R-CNN为基点,后续的SPPNet、Fast R-CNN、Faster R-CNN模型都是照着这个物体检测思路。

论文:
http://fcv2011.ulsan.ac.kr/files/announcement/513/r-cnn-cvpr.pdf
论问翻译
https://www.cnblogs.com/wj-1314/p/13209009.html
1.2 结构
如下图过程为:输入一张图像,提取约2000个自下而上区域提案,使用大卷积神经网络(CNN)计算每个提案的特征,然后使用类别特定的线性SVM。
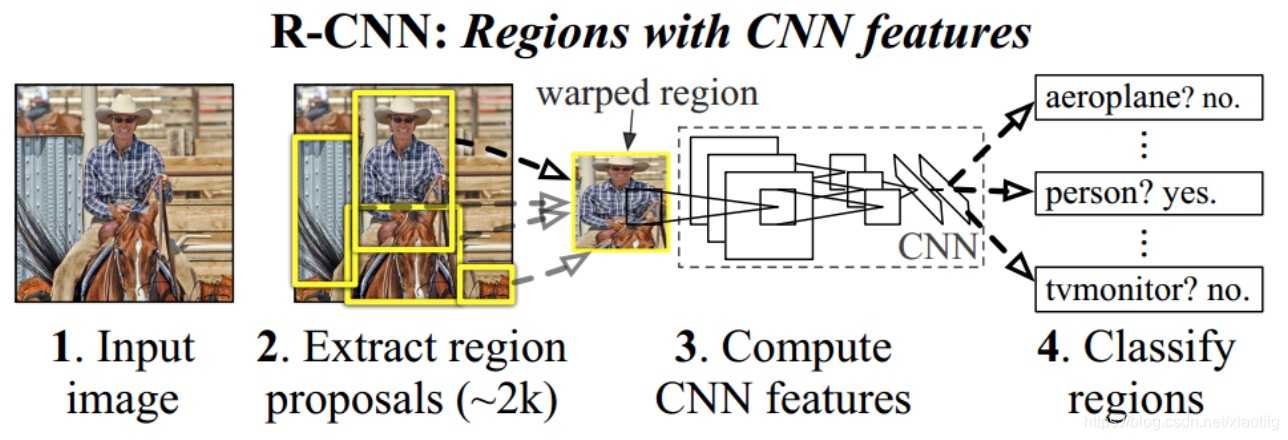

更好的理解步骤,一共经过了5步
1 先进行候选框的提取
2 进行裁剪和warp变形
3 卷积特征提取
4 分类
5 加入一个框回归,使定位更准确
(1)上面得到2000*20的矩阵,具体的数值使得分,各个类的scores
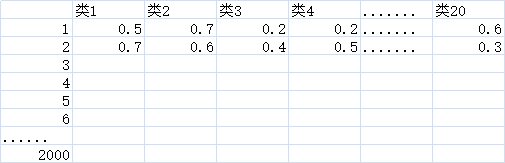
(2)对一幅图像进行检测相当于对2000幅图像进行了分类
下面4篇文章很好:
https://blog.csdn.net/weixin_41923961/article/details/80113669
https://blog.csdn.net/briblue/article/details/82012575
https://www.jianshu.com/p/5056e6143ed5
https://www.cnblogs.com/zf-blog/p/6740736.html
1.2.1 第一步,候选区域
选择性搜索(SelectiveSearch,SS)中,selective search方法是一个语义分割的方法,它通过在像素级的标注,把颜色、边界、纹理等信息作为合并条件,多尺度的综合采样方法,划分出一系列的区域,这些区域要远远少于传统的滑动窗口的穷举法产生的候选区域。

SelectiveSearch在一张图片上提取出来约2000个侯选区域,需要注意的是这些候选区域的长宽不固定。 而使用CNN提取候选区域的特征向量,需要接受固定长度的输入,所以需要对候选区域做一些尺寸上的修改。
1.2.2 CNN特征提取
通过训练好的Alex-Net,先将每个region固定到227*227的尺寸,然后对于每个region都提取一个4096维的特征。在侯选区域的基础上提取出更高级、更抽象的特征,这些高级特征是作为下一步的分类器、回归的输入数据。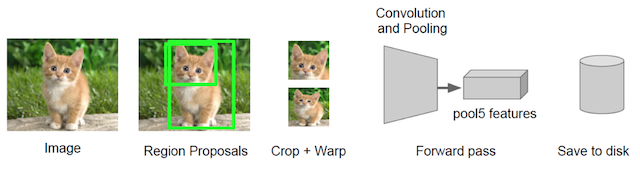
提取的这些特征将会保存在磁盘当中(这些提取的特征才是真正的要训练的数据)
重点:
重点:
重点:
注:为什么CNNs需要一个固定的输入尺寸呢?CNN主要由两部分组成,卷积部分和其后的全连接部分。卷积部分通过滑窗进行计算,并输出代表激活的空间排布的特征图(feature map)。事实上,卷积并不需要固定的图像尺寸,可以产生任意尺寸的特征图。而另一方面,根据定义,全连接层则需要固定的尺寸输入。**因此固定尺寸的问题来源于全连接层,也是网络的最后阶段。**含有全连接层的网络输入数据的大小应该是固定的,这是因为全连接层和前面一层的连接的参数数量需要事先确定,不像卷积核的参数个数就是卷积核大小,前层的图像大小不管怎么变化,卷积核的参数数量也不会改变,但全连接的参数是随前层大小的变化而变的,如果输入图片大小不一样,那么全连接层之前的feature map也不一样,那全连接层的参数数量就不能确定, 所以必须实现固定输入图像的大小
1.2.3 训练(3个方面)

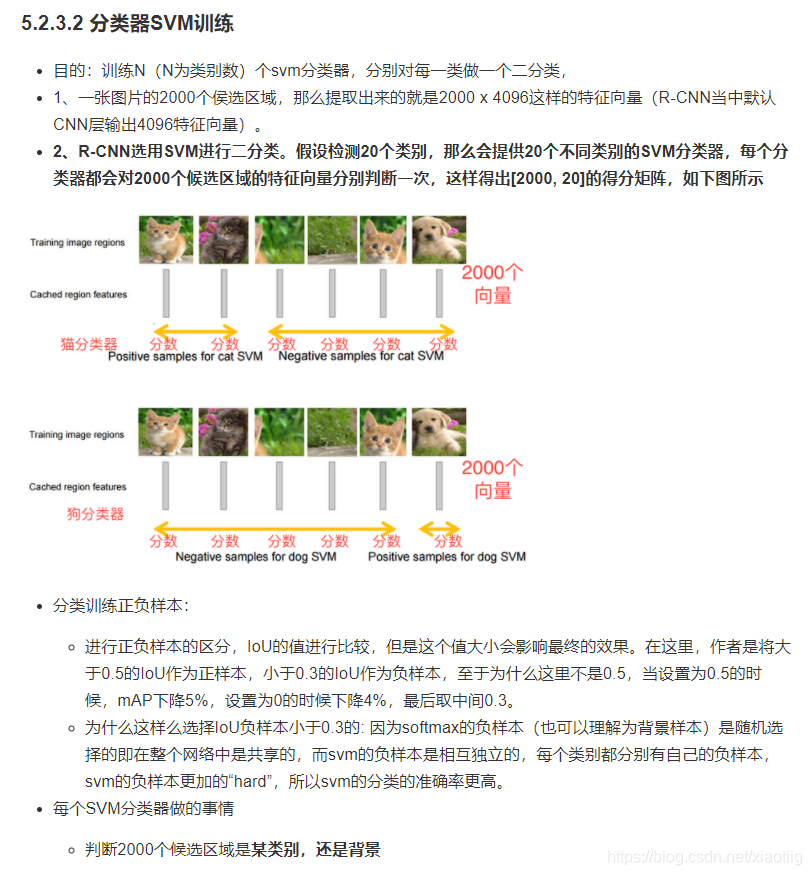

1.3 特点
1.3.1 候选框
1.3.2 正负样本分配

1.3.3 非极大抑制

# 实现非极大抑制
import numpy as np
def nms(dets, thresh):
# dets: 检测的 boxes 及对应的 scores
# thresh: 设定的阈值
# boxes 位置
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
# boxes scores
scores = dets[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1) # 各 box 的面积
order = scores.argsort()[::-1] # boxes 的按照 score 排序
keep = [] # 记录保留下的 boxes
while order.size > 0:
i = order[0] # score 最大的 box 对应的 index
keep.append(i) # 将本轮 score 最大的 box 的 index 保留
# 计算剩余 boxes 与当前 box 的重叠程度 IoU
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1) # IoU
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter)
# 保留 IoU 小于设定阈值的 boxes
inds = np.where(ovr <= thresh)[0]
order = order[inds + 1]
return keep
1.3.4 Iou

def union(au, bu, area_intersection):
"""
计算并集
:param au:
:param bu:
:param area_intersection:
:return:
"""
# 计算a的面积
area_a = (au[2] - au[0]) * (au[3] - au[1])
# 计算b的面积
area_b = (bu[2] - bu[0]) * (bu[3] - bu[1])
# a和b的面积-交集面积=总共面积
area_union = area_a + area_b - area_intersection
return area_union
def intersection(ai, bi):
"""
计算交集
:param ai:a框坐标
:param bi:b框坐标
:return:
"""
# 1、取出交集的左上角点
x = max(ai[0], bi[0])
y = max(ai[1], bi[1])
# 2、取出交集的右下角点,并减去左上角点值,计算出交集长宽
w = min(ai[2], bi[2]) - x
h = min(ai[3], bi[3]) - y
# 3、如果一个为0,返回交集面积为0
if w < 0 or h < 0:
return 0
return w*h
def iou(a, b):
"""
计算交并比
:param a: a框坐标
:param b: b框坐标
:return:
"""
# 1、如果a,b 传入有问题
if a[0] >= a[2] or a[1] >= a[3] or b[0] >= b[2] or b[1] >= b[3]:
return 0.0
# 2、计算IOU
# 交集区域
area_i = intersection(a, b)
# 并集区域
area_u = union(a, b, area_i)
return float(area_i) / float(area_u + 1e-6) # 防止分母为0,加一个稳定系数
if __name__ == '__main__':
# 假设一个图片10 x 10的大小,左上角(0, 0) 右下角(10, 10)
# A框:(1, 1, 5, 5),B框:(3, 3, 6, 6)
a = (1, 1, 5, 5)
b = (3, 3, 6, 6)
print("交并比为:%f" % iou(a, b))
1.3.5 mAP(mean average precision用到了精度)
是在非极大抑制后用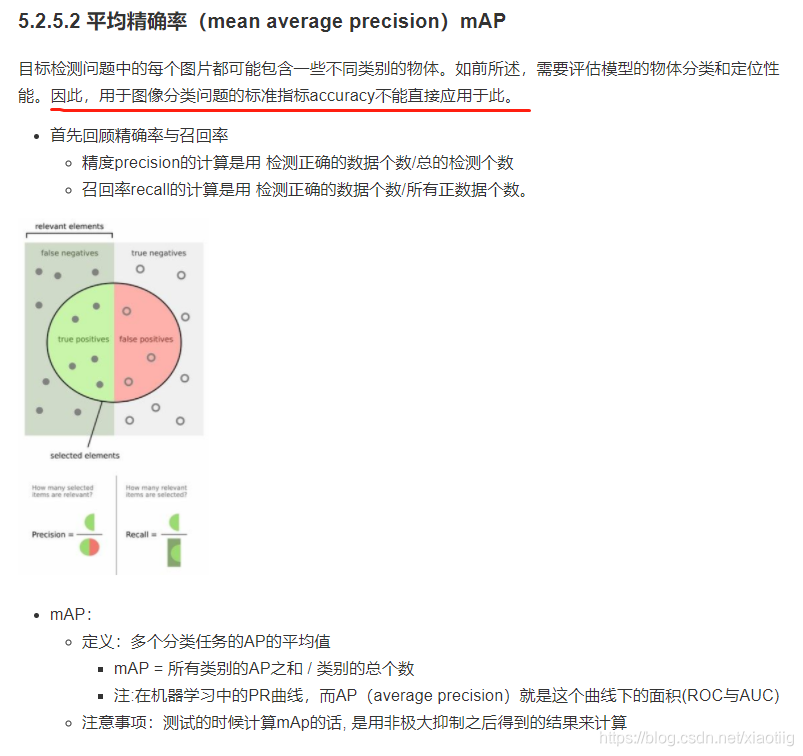

1.3.6 缺点

1.4 结果
1 PASCAL VOC2010-12上的结果

2 ILSVRC13上的结果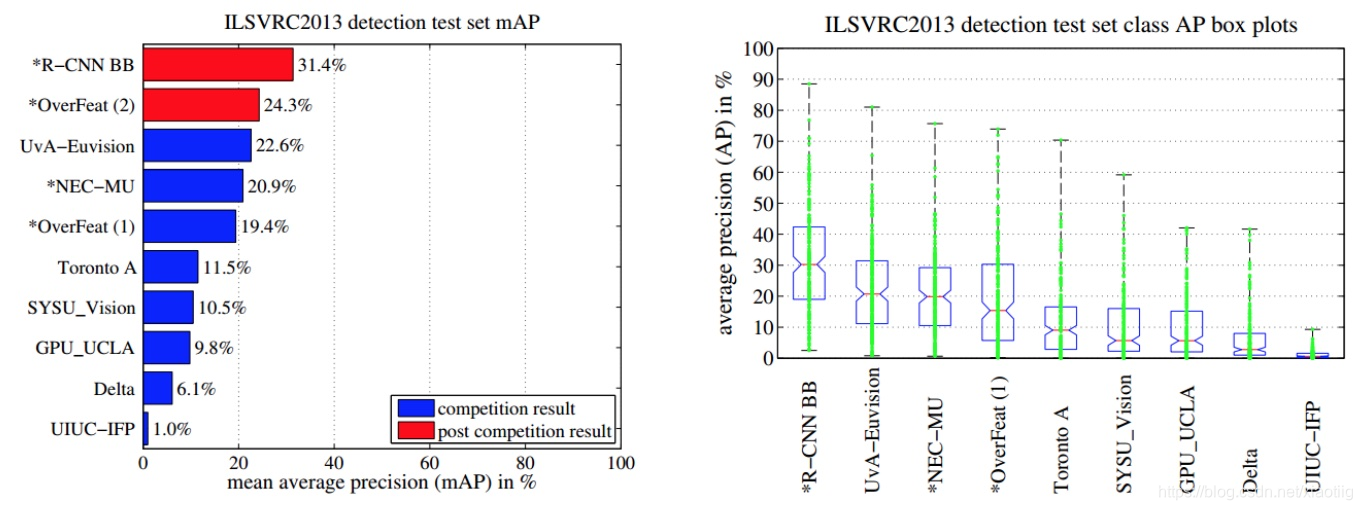
1.4.1 特征提取实现对比(全连接层微调效果好)
微调不同层的效果: 分别是pool5,fc6和fc7经过finetuning之后的结果,由上图可以看出,pool5经过finetuning之后,mAP的提高不大,所以可以说明卷积层提取出来的特征是更具有泛化性的,而fc7经过finetuning之后的提升最大,说明finetuning主要作用于全连接层。
与近期特征学习方法的比较
所有R-CNN变体的都优于三个DPM基线(第8-10行),包括使用特征学习的两个。与仅使用HOG特征的最新版本的DPM相比,我们的mAP提高了20个百分点以上:54.2%对比33.7%,相对改进61%。HOG和草图表征的组合与单独的HOG相比mAP提高2.5个点,而HSC在HOG上mAP提高了4个点(使用内部私有的DPM基线进行比较,两者都使用非公开实现的DPM,低于开源版本20)。这些方法的mAP分别达到29.1%和34.3%。
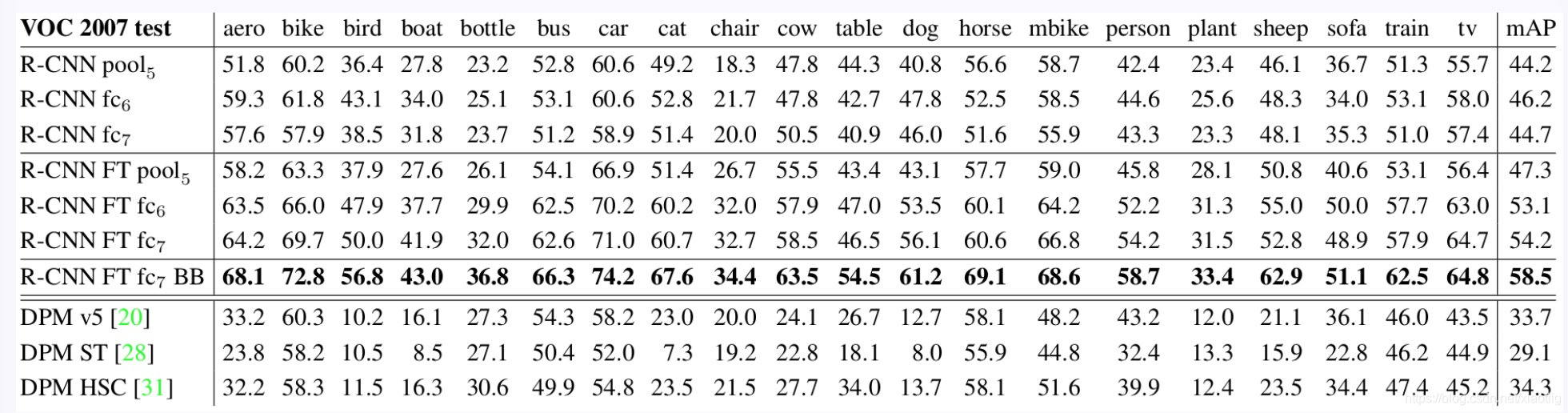
1.4.2 网络架构(主干网络不同,效果不同)


总结:结果显示使用O-Net的R-CNN表现优越,将mAP从58.5%提升到了66.0%。然后它有个明显的缺陷就是计算耗时。O-Net的前向传播耗时大概是T-Net的7倍。
2 实现

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 0
0 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)