
进击大数据系列(五):Hadoop 统一资源管理和调度平台 YARN
点击下方名片,设为星标!回复“1024”获取2TB学习资源!前面介绍了 Hadoop 基本概念与生态、安装(HDFS+YARN+MapReduce)实战操作、常用命令、架构基石 HDFS等相关的知识点,今天我将详细的为大家介绍 大数据 Hadoop 统一资源管理和调度平台 YARN 相关知识,希望大家能够从中收获多多!如有帮助,请点在看、转发支持一波!!!Yarn 概述Apache Yarn(Ye
点击下方名片,设为星标!
回复“1024”获取2TB学习资源!
前面介绍了 Hadoop 基本概念与生态、安装(HDFS+YARN+MapReduce)实战操作、常用命令、架构基石 HDFS等相关的知识点,今天我将详细的为大家介绍 大数据 Hadoop 统一资源管理和调度平台 YARN 相关知识,希望大家能够从中收获多多!如有帮助,请点在看、转发支持一波!!!
Yarn 概述
Apache Yarn(Yet Another Resource Negotiator的缩写)是hadoop集群资源管理器系统,Yarn从hadoop 2引入,最初是为了改善MapReduce的实现,但是它具有通用性,同样执行其他分布式计算模式。
Yarn特点
-
支持非mapreduce应用的需求
-
可扩展性
-
提高资源是用率
-
用户敏捷性
-
可以通过搭建为高可用
YARN 架构组件
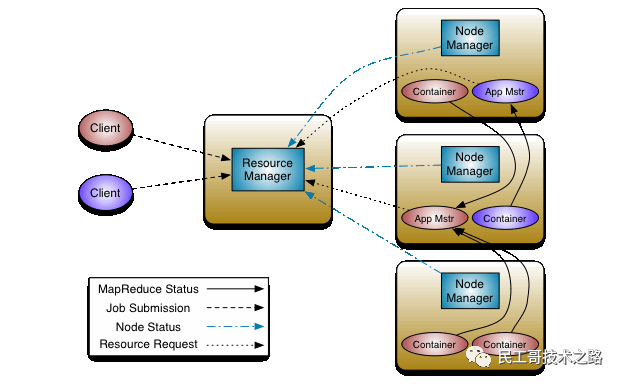
Yarn从整体上还是属于master/slave模型,主要依赖于三个组件来实现功能。
-
第一个就是
ResourceManager,是集群资源的仲裁者,它包括两部分:一个是可插拔式的调度Scheduler,一个是ApplicationManager,用于管理集群中的用户作业。 -
第二个是每个节点上的
NodeManager,管理该节点上的用户作业和工作流,也会不断发送自己Container使用情况给ResourceManager。 -
第三个组件是
ApplicationMaster,用户作业生命周期的管理者它的主要功能就是向ResourceManager(全局的)申请计算资源(Containers)并且和NodeManager交互来执行和监控具体的task。
架构图如下:
ResourceManager(RM)
RM是一个全局的资源管理器,管理整个集群的计算资源,并将这些资源分配给应用程序。包括:
-
与客户端交互,处理来自客户端的请求
-
启动和管理ApplicationMaster,并在它运行失败时重新启动它
-
管理NodeManager ,接收来自NodeManager 的资源汇报信息,并向NodeManager下达管理指令
-
资源管理与调度,接收来自ApplicationMaster 的资源申请请求,并为之分配资源
RM关键配置参数
最小容器内存:
yarn.scheduler.minimum-allocation-mb容器内存增量:
yarn.scheduler.increment-allocation-mb最大容器内存:
yarn.scheduler.maximum-allocation-mb最小容器虚拟 CPU 内核数量:
yarn.scheduler.minimum-allocation-mb容器虚拟 CPU 内核增量:
yarn.scheduler.increment-allocation-vcores最大容器虚拟 CPU 内核数量:
yarn.scheduler.maximum-allocation-mbResourceManager Web 应用程序 HTTP 端口:
yarn.resourcemanager.webapp.addressApplicationMaster(AM)
应用程序级别的,管理运行在YARN上的应用程序。包括:
-
用户提交的每个应用程序均包含一个AM,它可以运行在RM以外的机器上。
-
负责与RM调度器协商以获取资源(用Container表示)
-
将得到的资源进一步分配给内部的任务(资源的二次分配)
-
与NM通信以启动/停止任务。
-
监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务
AM关键配置参数:
ApplicationMaster 最大尝试次数:
yarn.resourcemanager.am.max-attemptsApplicationMaster 监控过期:
yarn.am.liveness-monitor.expiry-interval-msNodeManager(NM)
YARN中每个节点上的代理,它管理Hadoop集群中单个计算节点。包括:
-
启动和监视节点上的计算容器(Container)
-
以心跳的形式向RM汇报本节点上的资源使用情况和各个Container的运行状态(CPU和内存等资源)
-
接收并处理来自AM的Container启动/停止等各种请求
NM关键配置参数:
节点内存:
yarn.nodemanager.resource.memory-mb节点虚拟 CPU 内核:
yarn.nodemanager.resource.cpu-vcoresNodeManager Web 应用程序 HTTP 端口:
yarn.nodemanager.webapp.addressContainer
Container是YARN中资源的抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。Container由AM向RM申请的,由RM中的资源调度器异步分配给AM。Container的运行是由AM向资源所在的NM发起。
一个应用程序所需的Container分为两大类:
-
运行AM的Container:这是由RM(向内部的资源调度器)申请和启动的,用户提交应用程序时,可指定唯一的AM所需的资源;
-
运行各类任务的Container:这是由AM向RM申请的,并由AM与NM通信以启动之。
以上两类Container可能在任意节点上,它们的位置通常而言是随机的,即AM可能与它管理的任务运行在一个节点上。更多关于大数据 Hadoop系列的学习文章,请参阅:进击大数据系列,本系列持续更新中。
YARN容错性
-
失败类型
-
程序失败 进程崩溃 硬件问题
-
-
如果作业失败了
-
作业异常会汇报给Application Master
-
通过心跳信号检查挂住的任务
-
一个作业的任务失败比例超过配置,就会认为该任务失败
-
-
如果Application Master失败了
-
Resource Manager接收不到心跳信号时会重启Application Master
-
-
如果Node Manager失败了
-
Resource Manager接收不到心跳信号时会将其移出
-
Resource Manager接收Application Master,让Application Master决定任务如何处理
-
如果某个Node Manager失败任务次数过多,Resource Manager调度任务时不再其上面运行任务
-
-
如果Resource Manager运行失败
-
通过checkpoint机制,定时将其状态保存到磁盘,失败的时候,重新运行
-
通过Zooleeper同步状态和实现透明的HA
-
YARN运行流程
Application在Yarn中的执行过程如下图所示: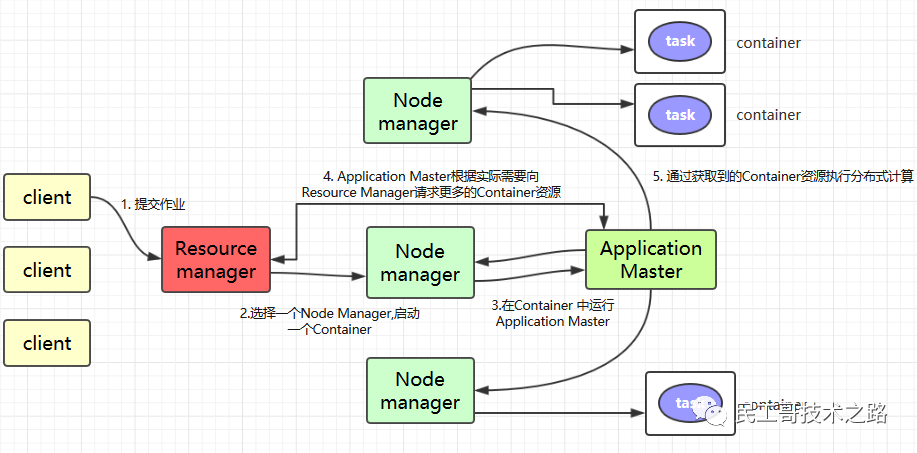
1.客户端程序向ResourceManager提交应用并请求一个ApplicationMaster实例,ResourceManager在应答中给出一个applicationID以及有助于客户端请求资源的资源容量信息。
2.ResourceManager找到可以运行一个Container的NodeManager,并在这个Container中启动ApplicationMaster实例
-
Application Submission Context发出响应,其中包含有:ApplicationID,用户名,队列以及其他启动ApplicationMaster的信息,Container Launch Context(CLC)也会发给ResourceManager,CLC提供了资源的需求,作业文件,安全令牌以及在节点启动ApplicationMaster所需要的其他信息。
-
当ResourceManager接收到客户端提交的上下文,就会给ApplicationMaster调度一个可用的container(通常称为container0)。然后ResourceManager就会联系NodeManager启动ApplicationMaster,并建立ApplicationMaster的RPC端口和用于跟踪的URL,用来监控应用程序的状态。
3.ApplicationMaster向ResourceManager进行注册,注册之后客户端就可以查询ResourceManager获得自己ApplicationMaster的详细信息,以后就可以和自己的ApplicationMaster直接交互了。在注册响应中,ResourceManager会发送关于集群最大和最小容量信息,
4.在平常的操作过程中,ApplicationMaster根据resource-request协议向ResourceManager发送resource-request请求,ResourceManager会根据调度策略尽可能最优的为ApplicationMaster分配container资源,作为资源请求的应答发个ApplicationMaster
5.当Container被成功分配之后,ApplicationMaster通过向NodeManager发送container-launch-specification信息来启动Container, container-launch-specification信息包含了能够让Container和ApplicationMaster交流所需要的资料,一旦container启动成功之后,ApplicationMaster就可以检查他们的状态,Resourcemanager不在参与程序的执行,只处理调度和监控其他资源,Resourcemanager可以命令NodeManager杀死container,
6.应用程序的代码在启动的Container中运行,并把运行的进度、状态等信息通过application-specific协议发送给ApplicationMaster,随着作业的执行,ApplicationMaster将心跳和进度信息发给ResourceManager,在这些心跳信息中,ApplicationMaster还可以请求和释放一些container。
7.在应用程序运行期间,提交应用的客户端主动和ApplicationMaster交流获得应用的运行状态、进度更新等信息,交流的协议也是application-specific协议
8.一但应用程序执行完成并且所有相关工作也已经完成,ApplicationMaster向ResourceManager取消注册然后关闭,用到所有的Container也归还给系统,当container被杀死或者回收,Resourcemanager都会通知NodeManager聚合日志并清理container专用的文件。
更多关于大数据 Hadoop系列的学习文章,请参阅:进击大数据系列,本系列持续更新中。
YARN 调度
YARN调度框架
-
双层调度框架
-
RM将资源分配给AM
-
AM将资源进一步分配给各个Task
-
-
基于资源预留的调度策略
-
资源不够时,会为Task预留,直到资源充足
-
与“all or nothing”策略不同(Apache Mesos)
-
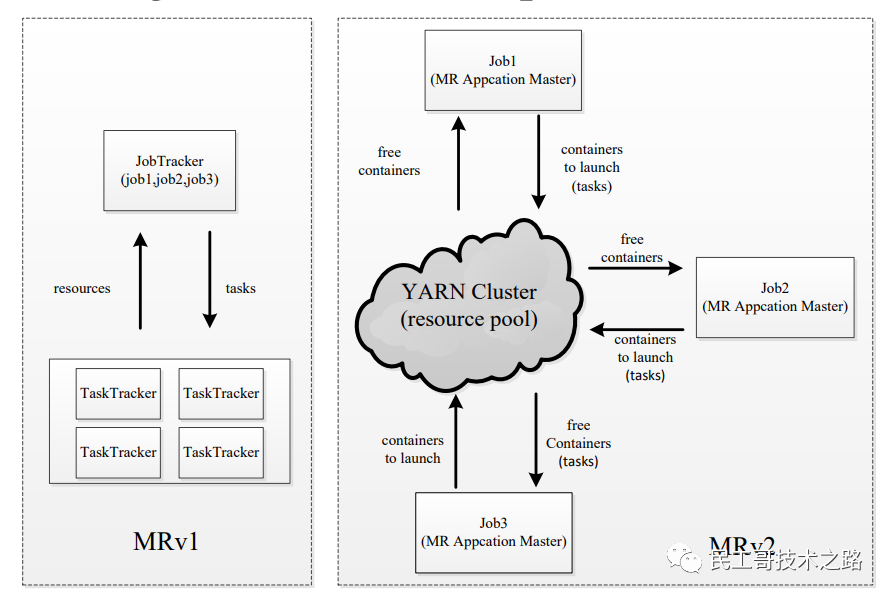
三种调度器
FIFO调度器(FIFO Scheduler)
FIFO调度器的优点是简单易懂不需要任何配置,但是不适合共享集群。大型应用会占用集群中的所有资源,所以每个应用必须等待直到轮到自己运行。在一个共享集群中,更适合使用容量调度器或公平调度器。这两种调度器都允许长时间运行的作业能及时完成,同时也允许正在进行较小临时查询的用户能够在合理时间内得到返回结果。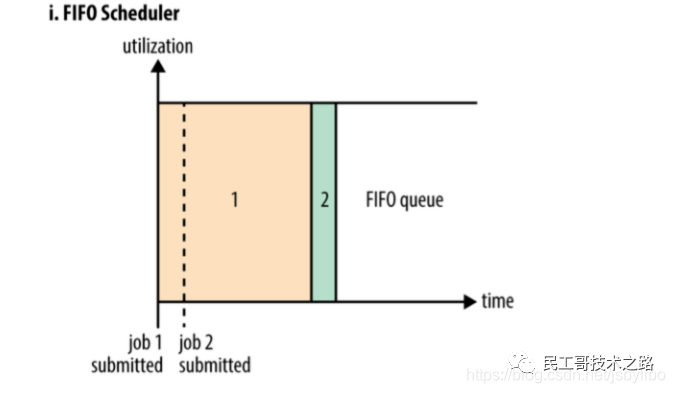
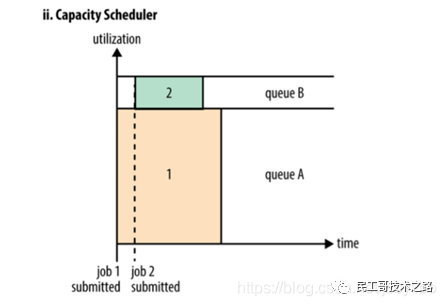
容量调度器(Capacity Scheduler)
容量调度器允许多个组织共享一个Hadoop集群,每个组织可以分配到全部集群资源的一部分。每个组织被配置一个专门的队列,每个队列被配置为可以使用一定的集群资源。队列可以进一步按层次划分,这样每个组织内的不同用户能够共享该组织队列所分配的资源。在一个队列内,使用FIFO调度策略对应用进行调度。
-
单个作业使用的资源不会超过其队列容量。然而如果队列中有多个作业,并且队列资源不够了呢?这时如果仍有可用的空闲资源那么容量调度器可能会将空余的资源分配给队列中的作业,哪怕这会超出队列容量。这被称为弹性队列(queue elasticity)。
资源调度器- Fair
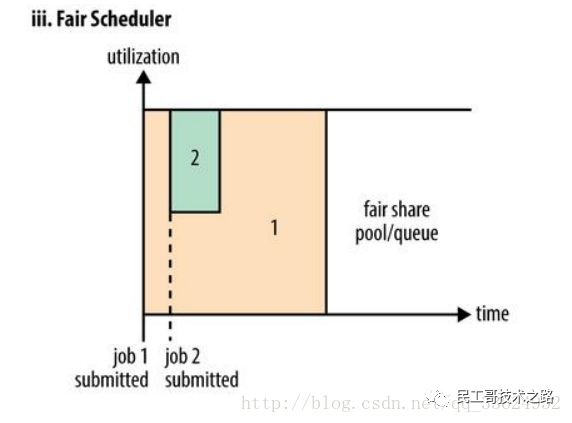
公平调度是一种对于全局资源,对于所有应用作业来说,都均匀分配的资源分配方法。默认情况,公平调度器FairScheduler基于内存来安排公平调度策略。也可以配置为同时基于内存和CPU来进行调度(Dominant Resource Fairness)。在一个队列内,可以使用FIFO、FAIR、DRF调度策略对应用进行调度。FairScheduler允许保障性的分配最小资源到队列。
-
【注意】在下图 Fair 调度器中,从第二个任务提交到获得资源会有一定的延迟,因为它需要等待第一个任务释放占用的 Container。小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。最终效果就是 Fair 调度器即得到了高的资源利用率又能保证小任务及时完成。
 更多关于大数据 Hadoop系列的学习文章,请参阅:进击大数据系列,本系列持续更新中。
更多关于大数据 Hadoop系列的学习文章,请参阅:进击大数据系列,本系列持续更新中。
YARN 部署
配置各服务器之间的免密登录
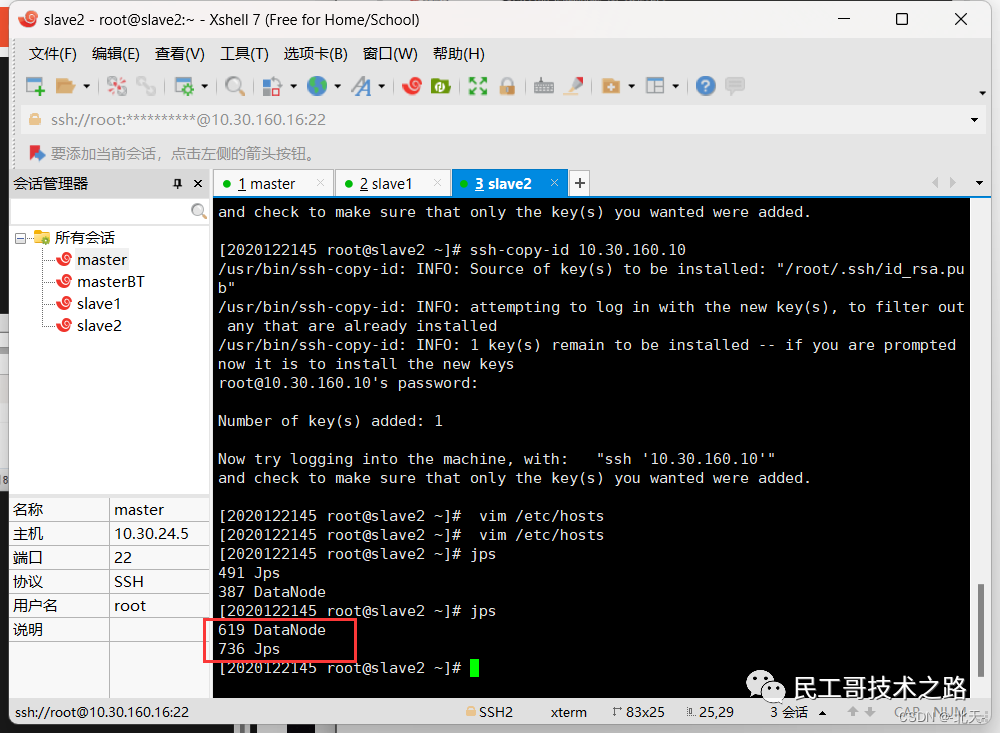
首先配置 master,slave1和slave2之间的免密登录和各虚拟机的/etc/hosts文件,参考前面的配置过程,这里不做赘述。
启动 HDFS
启动 HDFS ,配置过程参考:
在master机上配置YARN
首先指定YARN主节点,输入如下命令编辑文件/usr/cstor/hadoop/etc/hadoop/yarn-site.xml:
vim /usr/cstor/hadoop/etc/hadoop/yarn-site.xml将如下内容嵌入此文件里configuration标签间:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>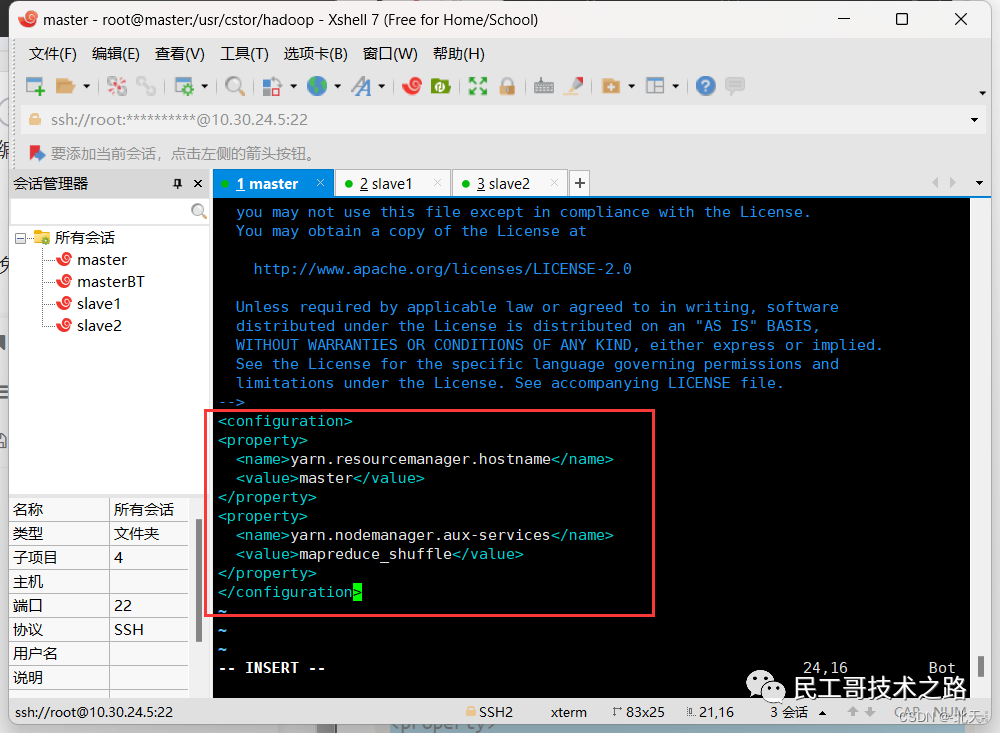
yarn-site.xml是YARN守护进程的配置文件。第一句配置了ResourceManager的主机名,第二句配置了节点管理器运行的附加服务为mapreduce_shuffle,只有这样才可以运行MapReduce程序。
紧接着在master机上操作,将配置好的YARN配置文件拷贝至slaveX,也就是拷贝到其他服务器上:
for x in `cat ~/data/4/machines`;
do
echo $x;
scp /usr/cstor/hadoop/etc/hadoop/yarn-site.xml $x:/usr/cstor/hadoop/etc/hadoop/;
done;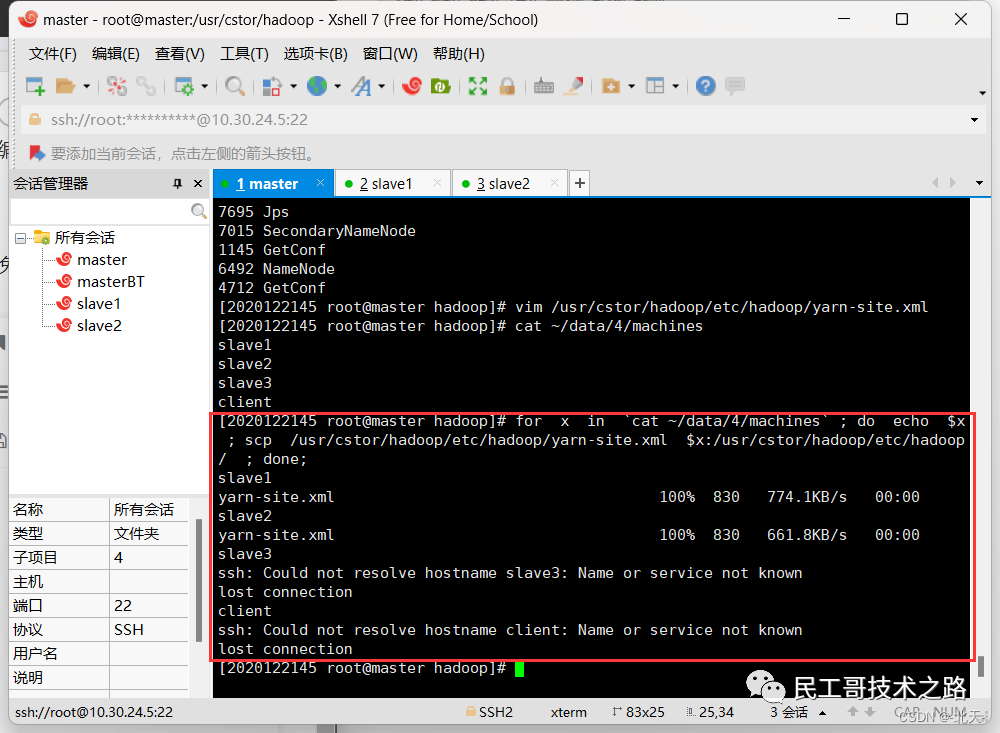
统一启动YARN
确认已配置slaves文件,在master机器上查看:
cat /usr/cstor/hadoop/etc/hadoop/slaves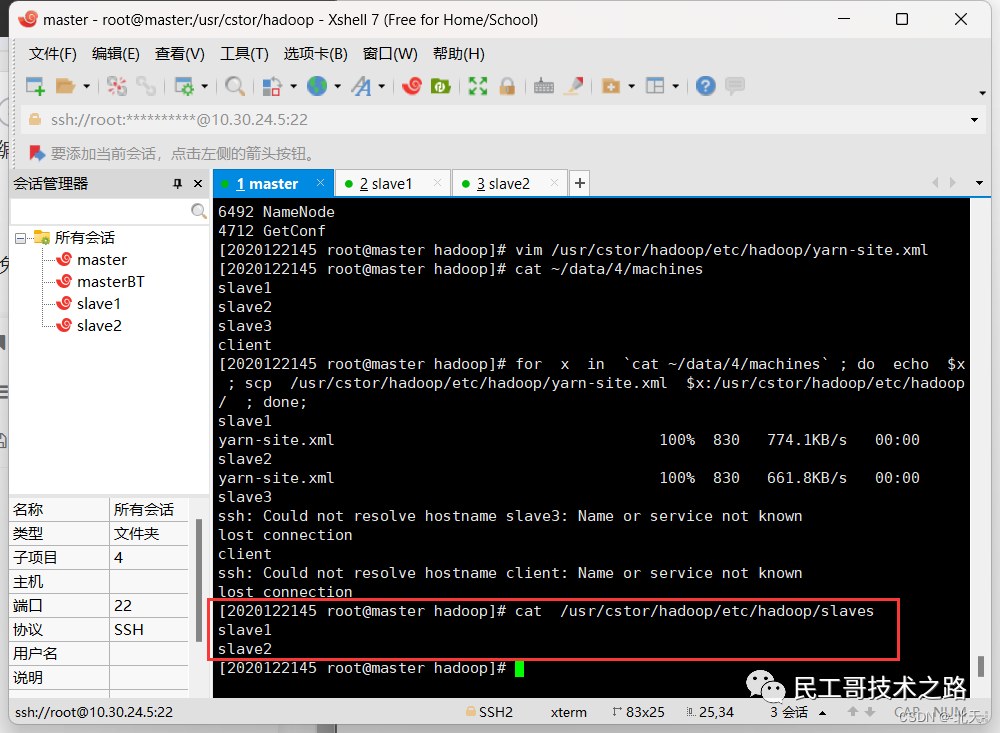 YARN配置无误,统一启动YARN:
YARN配置无误,统一启动YARN:
/usr/cstor/hadoop/sbin/start-yarn.sh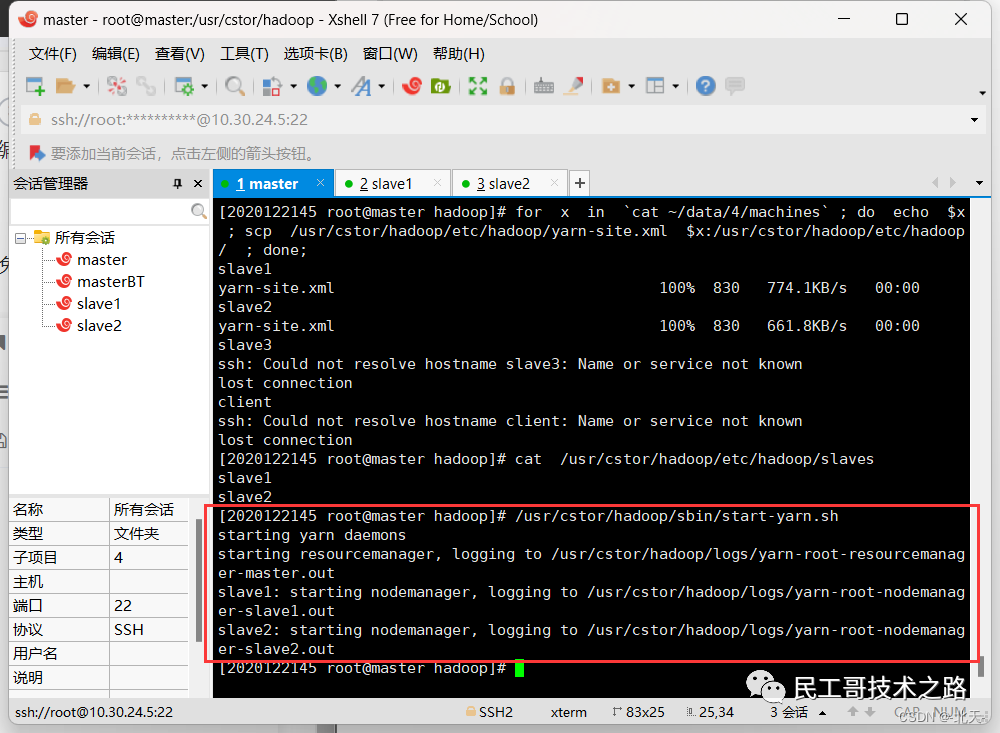
验证YARN启动成功
分别在三台虚拟机上输入jps查看YARN服务是否已启动: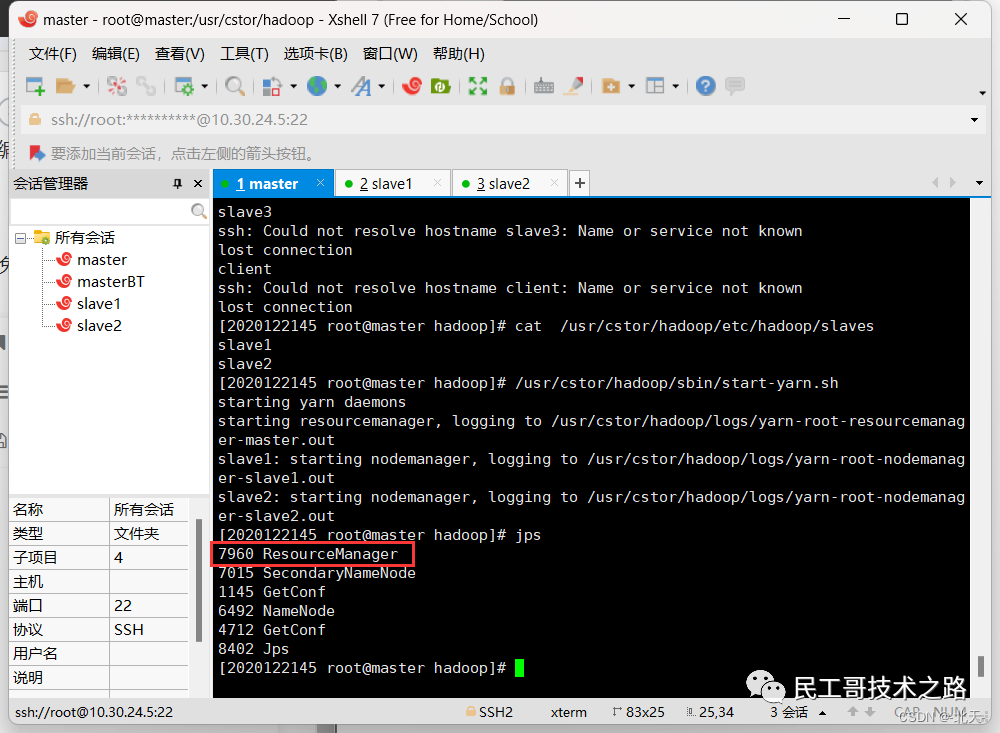
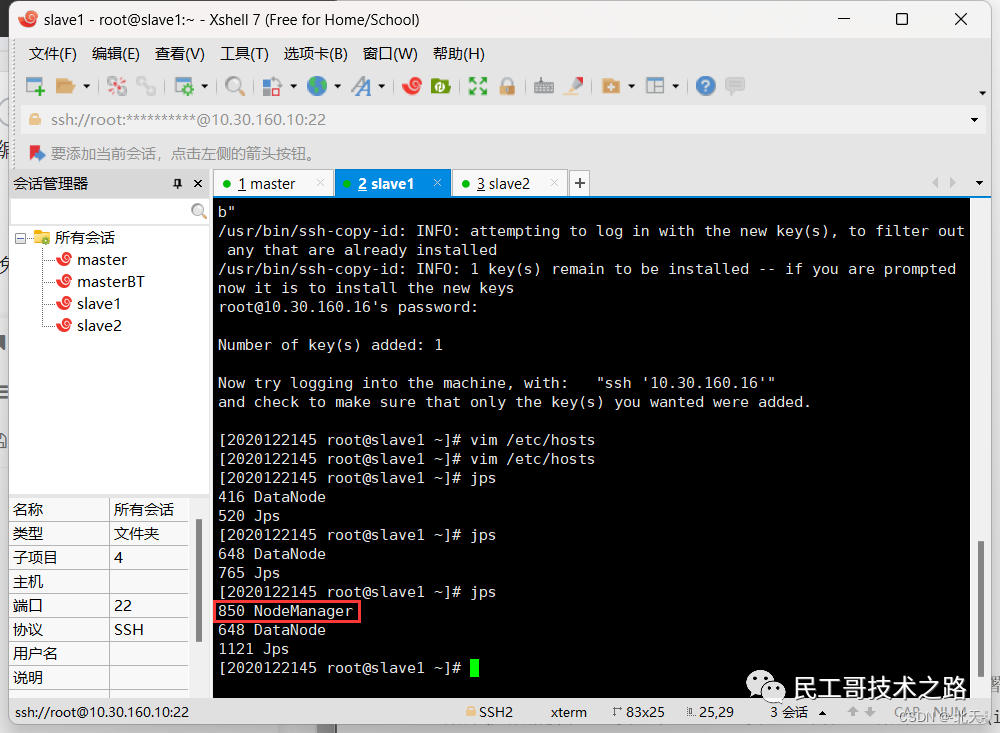
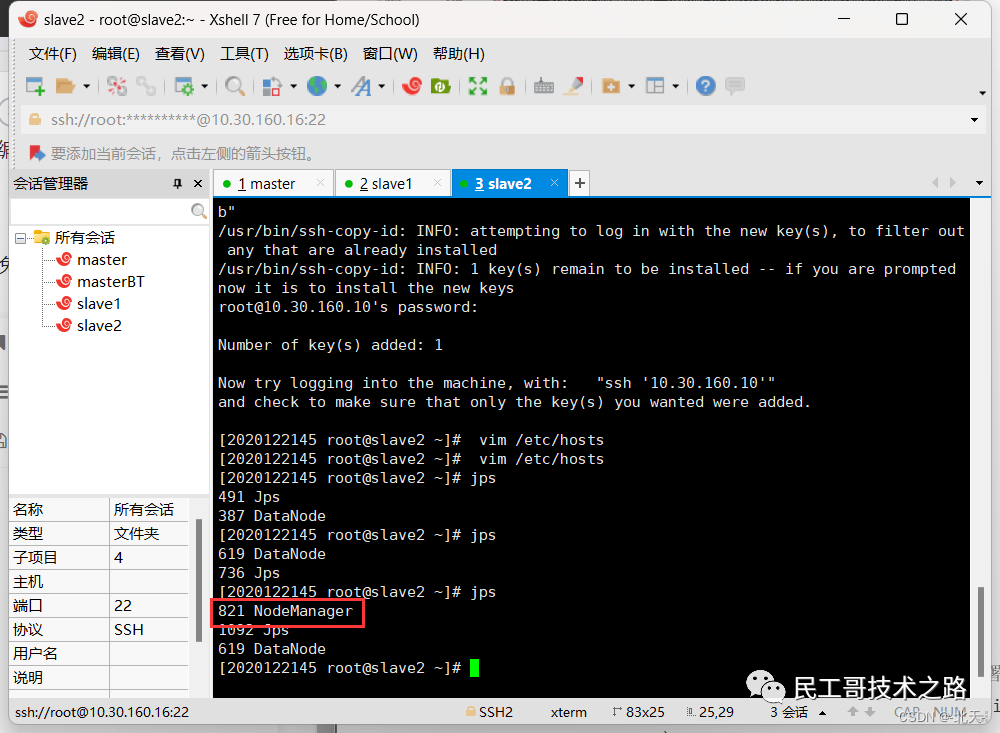 可以看出我们成功启动了。
可以看出我们成功启动了。
在 master 节点成功启动 ResourceManager,它负责整个集群的资源管理分配,是一个全局的资源管理系统。
NodeManager 是每个节点上的资源和任务管理器,它是管理这台机器的代理,负责该节点程序的运行,以及该节点资源的管理和监控。YARN 集群每个节点都运行一个 NodeManager。
在当前的Windows机器上打开浏览器,地址栏输入master的IP和端口号8088(例:10.1.1.7:8088),即可在Web界面看到YARN相关信息。
YARN常用命令
列出所有的 Application:
yarn application -list根据Application状态过滤:
yarn application -list -appStates ACCEPTEDKill掉Application:
yarn application -kill [ApplicationId]查看Application日志:
yarn logs -applicationId [ApplicationId]查询Container日志:
yarn logs -applicationId [ApplicationId] -containerId [containerId] -nodeAddress [nodeAddress]配置是配置文件中:
yarn.nodemanager.webapp.address 参数指定链接:blog.csdn.net/qq_52417436/article/details/
127766099 cnblogs.com/liugp/p/16101242.html
读者专属技术群
构建高质量的技术交流社群,欢迎从事后端开发、运维技术进群(备注岗位),相互帮助,一起进步!请文明发言,主要以技术交流、内推、行业探讨为主。
广告人士勿入,切勿轻信私聊,防止被骗

推荐阅读 点击标题可跳转

PS:因为公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。点“在看”支持我们吧!

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)