
玩转企业云计算平台系列(十七):Openstack 大数据项目 Sahara
点击下方名片,设为星标!回复“1024”获取2TB学习资源!前面介绍了OpenStackKeystone、Glance、Nova、Neutron、Horizon、Cinder、Swift、基础组件使用、Heat、Manila、Zun、Barbican、Cloudkitty、Telemetry 系统架构等相关的知识点,今天我将详细的为大家介绍Openstack 大数据项目 Sah...
点击下方名片,设为星标!
回复“1024”获取2TB学习资源!
前面介绍了OpenStack Keystone 、Glance、Nova 、Neutron 、Horizon 、Cinder 、Swift 、基础组件使用、Heat、Manila、Zun、Barbican 、 Cloudkitty 、Telemetry 系统架构等相关的知识点,今天我将详细的为大家介绍Openstack 大数据项目 Sahara相关知识,希望大家能够从中收获多多!如有帮助,请点在看、转发分享朋友圈支持一波!!! 2013年4月,OpenStack社区知名厂商Mirantis正式宣布了基于OpenStack的开源BDaaS(BigData-as-a-Service)项目——Sahara(原名Savanna),正式开始了在OpenStack上构建大数据服务能力的努力。
2013年4月,OpenStack社区知名厂商Mirantis正式宣布了基于OpenStack的开源BDaaS(BigData-as-a-Service)项目——Sahara(原名Savanna),正式开始了在OpenStack上构建大数据服务能力的努力。
Sahara 介绍
Apache Hadoop是目前被广泛使用的主流大数据处理计算框架,Sahara项目旨在使用用户能够在Openstack平台上便于创建和管理Hadoop以及其他计算框架集群,实现类似AWS的EMR(Amazon Elastic MapReduce service)服务。
用户只需要提供简单的参数,如版本信息、集群拓扑、节点硬件信息等,利用Sahara服务能够在数分钟时间内快速地部署Hadoop、Spark、Storm集群。Sahara 还支持节点的弹性扩展,能够方便地按需增加或者减少计算节点,实现弹性数据计算服务。它特别适合开发人员或者QA在Openstack平台上快速部署大数据处理计算集群。
特性包括:
-
Openstack的标准组件之一;
-
通过REST API和Dashboard UI界面管理集群;
-
支持多种数据处理计算框架,包括:
-
多种Hadoop厂商发行版,比如CDH等;
-
Apache Spark和Storm;
-
可插除的Hadoop安装引擎;
-
集成厂商的特定管理工具,如Apache Ambari and Cloudera Management Console。
-
支持配置模板。
Sahara 与 OpenStack的Horizon(提供GUI)、Keystone(提供鉴权功能)、Nova(为了创建Hadoop集群虚拟机)、Heat(Sahara可以配置成使用Heat来协调Hadoop集群所需要的服务)、Glance(存放Hadoop虚拟机镜像)、Swift(可以用于存放Hadoop任务处理的数据)、Cinder(用于提供块存储)、Neutron(提供网络服务)、Ceilometer(用于收集集群的信息来达到计量和监控的目的)有交互。
它和其他Openstack组件交互,如图: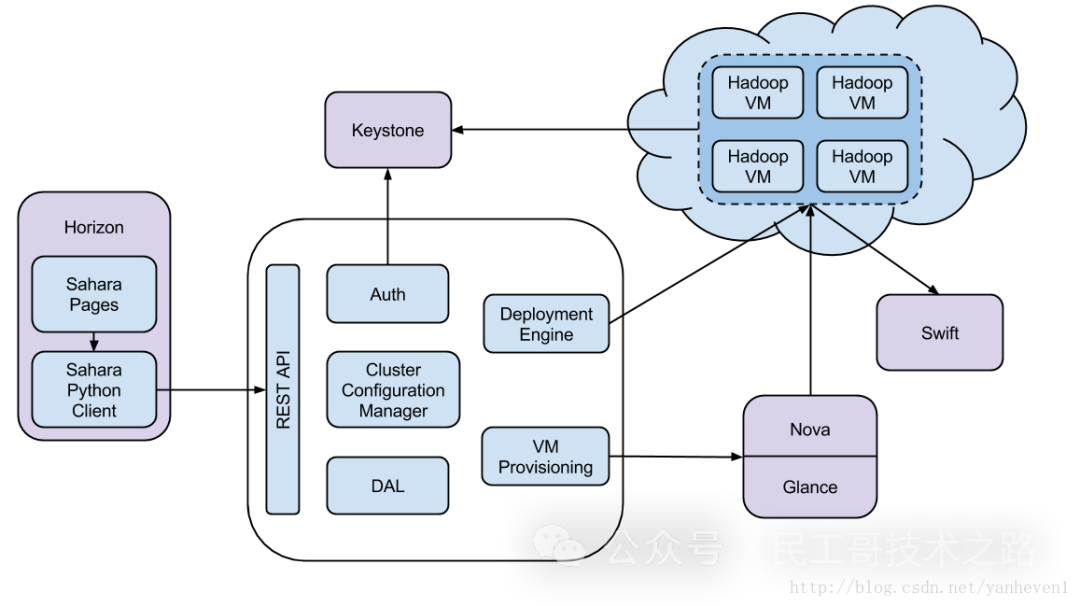 更多关于云计算服务 Openstack 系列的学习文章,请参阅:企业云计算平台 Openstack ,本系列持续更新中。
更多关于云计算服务 Openstack 系列的学习文章,请参阅:企业云计算平台 Openstack ,本系列持续更新中。
Sahara 架构
主要包括以下几个组件:
-
Auth component(认证组件) - 负责和认证服务交互完成客户认证。
-
DAL - 数据访问层, 负责为持久化数据提供数据库访问接口。
-
Secure Storage Access Layer(安全存储访问层) - 保存用户认证信息,比如用户、密钥等。
-
Provisioning Engine - 该组件负责和Openstack其他组件交互,比如Nova组件、Heat组件、Cinder组件以及Glance组件等。
-
Vendor Plugins(厂商插件) - 负责配置和启动计算框架,不同的计算框架启动方式和配置都不一样,因此提供插件机制,使sahara同时可支持多种计算框架。已经完成集成的插件包括Apache Ambari和Cloudera Management Console等。
-
EDP - Elastic Data Processing,负责调度和管理任务。
-
REST API - 通过REST HTTP API接口暴露sahara管理功能。
-
Python Sahara Client - sahara命令行管理工具。
-
Sahara pages - Openstack Dashboard显示页面。
Sahara 工作流程
sahara提供两个层次的API,分别为集群管理(cluster provisioning)和任务管理(analytics as a service)。
集群管理工作流
-
选择Hadoop发行版本;
-
选择base镜像,base镜像用于生成工作节点,base镜像或者已经预先安装了Hadoop的必要组件,或者提供可插除的可自动快速部署Hadoop的工具。base镜像可以自己制作,也可以直接下载: http://sahara-files.mirantis.com/images/upstream/liberty/
-
集群配置,包括集群大小、集群拓扑(配置组件角色)和一些附加参数(如堆大小、HDFS冗余份数等);
-
创建集群,sahara将自动创建虚拟机、部署和配置数据分析计算框架集群;
-
集群管理,如增加或者删除节点;
-
集群销毁,用户不需要时,可以删除集群,释放所有的资源。
任务管理工作流
-
选择预先定义的数据处理计算框架以及版本;
-
任务配置:
-
选择任务类型:pig,hive,java-jar等;
-
提供任务脚本源或者jar包地址;
-
选择输入、输出地址。
-
-
限制集群大小;
-
执行任务,注意所有底层的集群管理和任务执行流程对用户是完全透明的,当任务执行完后,集群将会自动移除提交的任务;
-
获取处理结果(如Swift)。
通过sahara管理集群,用户主要需要操作以下三个实体对象:Node Group Templates, Cluster Templates and Clusters:
-
Node Group Templates:设置单一节点的模板,包括启动虚拟机的flavor、安全组、可用域、镜像等,以及配置Hadoop角色,比如namenode、secondarynamenode、resourcemanager。比如我们可以创建Master节点模板,flavor为m1.large,启动镜像为sahara-mitaka-vanilla-hadoop-2.7.1-ubuntu-14.04,配置namenode、resourcemanager、secondarynamenode角色,创建Slave节点模板,flavor为m1.large,镜像为sahara-mitaka-vanilla-hadoop-2.7.1-ubuntu-14.04,配置角色为datanode、nodemanager等。
-
Cluster Templates:即集群拓扑,包括节点数量(如Master数量、Slave数量)、Hadoop参数配置,比如HDFS配置、YARN配置等。
-
Clusters:集群管理,包括集群扩容、集群启动、集群删除等。
sahara允许用户自由组合节点角色,比如Job Tracker和NameNode可以运作在同一个虚拟机中,也可以分离在不同的虚拟机中。但是sahara会检查集群是否有效,比如不允许创建只有一系列DataNode节点但不存在NameNode节点的集群。
sahara遵从Openstack的通用访问策略,即支持租户、用户等权限管理。更多关于云计算服务 Openstack 系列的学习文章,请参阅:企业云计算平台 Openstack ,本系列持续更新中。
安装 Sahara
yum install openstack-sahara gcc python-setuptools python-devel配置文件位于/etc/sahara/sahara.conf 中。有关详细信息,请参阅官方 Sahara 配置指南。
创建数据库架构
sahara-db-manage --config-file /etc/sahara/sahara.conf upgrade head创建keystone账号,并添加角色
keystone user-password-update --pass openstack sahara
keystone user-role-list --user sahara --tenant service
keystone user-role-add --user sahara --tenant service --role admin添加keystone的endpoint
keystone service-create --name sahara --type data_processing \
--description "Sahara Data Processing"
keystone endpoint-create --service sahara --region RegionOne \
--publicurl "http://192.168.206.190:8386/v1.1/%(tenant_id)s" \
--adminurl "http://192.168.206.190:8386/v1.1/%(tenant_id)s" \
--internalurl "http://192.168.206.190:8386/v1.1/%(tenant_id)s"修改mysql的配置
vim /etc/mysql/my.cnf
max_allowed_packet = 256M修改完重启数据库服务
service mysql restart登录数据库,创建sahara用户和sahara数据库,并添加权限
create user sahara IDENTIFIED by 'openstack';
grant alert,select,insert,update,delete,create,drop on sahara.* to sahara identified by 'openstack';创建sahara的数据库表
sahara-db-manage --config-file /etc/sahara.conf upgrade head进行Shara的配置,配置模板在/usr/local/share/sahara/sahara.conf.sample-basic目录下
cp /usr/local/share/sahara/sahara.conf.sample-basic /etc/sahara.conf修改sahara.conf的配置文件(配置的含义,在/usr/local/share/sahara/sahara.conf.sample-basic中有比较详细的描述,需要配置rabbit database keystone等配置。
[DEFAULT]
use_neutron=true
use_floating_ips=false
debug=true
verbose=true
log_file=sahara.log
log_dir=/var/log
#plugins=vanilla,hdp,spark
rpc_backend = rabbit
rabbit_host=192.168.206.190
rabbit_port=5672
rabbit_hosts=$rabbit_host:$rabbit_port
rabbit_userid=guest
rabbit_password=openstack
rabbit_virtual_host=/
[database]
connection = mysql://sahara:openstack@192.168.206.190/sahara
[keystone_authtoken]
auth_uri = http://192.168.206.190:5000
identity_uri=http://192.168.206.190:35357/
admin_tenant_name = service
admin_user = sahara
admin_password = openstack设置policy文件
在sahara配置文件的同一个目录(/etc/sahara)下,创建一个policy.json的文件,当然也可以在配置文件中指定policy_file 和 policy_dirs。
默认是运行所有用户访问所有的方法:
{
"default": ""
}下面这个配置不允许非admin用户访问镜像的主要方法:
{
"default": "",
"images:register": "role:admin",
"images:unregister": "role:admin",
"images:add_tags": "role:admin",
"images:remove_tags": "role:admin"
}启动 sahara-api 和 sahara-engine 服务
# systemctl start openstack-sahara-api
# systemctl start openstack-sahara-engine配置开机启动
# systemctl enable openstack-sahara-api
# systemctl enable openstack-sahara-engine更多关于云计算服务 Openstack 系列的学习文章,请参阅:企业云计算平台 Openstack ,本系列持续更新中。
使用 Sahara 部署 Hadoop 集群
身份服务配置
指定环境变量
export OS_AUTH_URL=http://127.0.0.1:5000/v2.0/
export OS_PROJECT_NAME=admin
export OS_USERNAME=admin
export OS_PASSWORD=nova上传镜像
需要将虚拟机映像上传到 OpenStack 映像服务。您可以自己构建映像。本指南使用最新生成的 Ubuntu 原版镜像(称为 sahara-vanilla-latest-ubuntu.qcow2)和最新版本的 vanilla 插件作为示例。
将生成的镜像上传到 OpenStack Image 服务:
$ openstack image create sahara-vanilla-latest-ubuntu --disk-format qcow2 \
--container-format bare --file sahara-vanilla-latest-ubuntu.qcow2
+------------------+--------------------------------------+
| Field | Value |
+------------------+--------------------------------------+
| checksum | 3da49911332fc46db0c5fb7c197e3a77 |
| container_format | bare |
| created_at | 2016-02-29T10:15:04.000000 |
| deleted | False |
| deleted_at | None |
| disk_format | qcow2 |
| id | 71b9eeac-c904-4170-866a-1f833ea614f3 |
| is_public | False |
| min_disk | 0 |
| min_ram | 0 |
| name | sahara-vanilla-latest-ubuntu |
| owner | 057d23cddb864759bfa61d730d444b1f |
| properties | |
| protected | False |
| size | 1181876224 |
| status | active |
| updated_at | 2016-02-29T10:15:41.000000 |
| virtual_size | None |
+------------------+--------------------------------------+记住镜像名称或保存映像 ID。这将在Sahara 镜像注册期间使用。您可以使用 openstack 命令行工具获取映像 ID,如下所示:
$ openstack image list --property name=sahara-vanilla-latest-ubuntu
+--------------------------------------+------------------------------+
| ID | Name |
+--------------------------------------+------------------------------+
| 71b9eeac-c904-4170-866a-1f833ea614f3 | sahara-vanilla-latest-ubuntu |
+--------------------------------------+------------------------------+注册镜像到Sahara
openstack dataprocessing image register sahara-vanilla-latest-ubuntu \
--username ubuntu添加标签
$ openstack dataprocessing image tags add sahara-vanilla-latest-ubuntu \
--tags vanilla 1.2.1
+-------------+--------------------------------------+
| Field | Value |
+-------------+--------------------------------------+
| Description | None |
| Id | 71b9eeac-c904-4170-866a-1f833ea614f3 |
| Name | sahara-vanilla-latest-ubuntu |
| Status | ACTIVE |
| Tags | 1.2.1, vanilla |
| Username | ubuntu |
+-------------+--------------------------------------+创建节点组模板
可以使用以下命令获取有关可用插件的信息:
openstack dataprocessing plugin list您还可以使用 plugin show 命令获取有关特定插件的可用服务的信息。例如:
$ openstack dataprocessing plugin show vanilla --plugin-version <plugin_version>
+---------------------+-----------------------------------------------------------------------------------------------------------------------+
| Field | Value |
+---------------------+-----------------------------------------------------------------------------------------------------------------------+
| Description | The Apache Vanilla plugin provides the ability to launch upstream Vanilla Apache Hadoop cluster without any |
| | management consoles. It can also deploy the Oozie component. |
| Name | vanilla |
| Required image tags | <plugin_version>, vanilla |
| Title | Vanilla Apache Hadoop |
| | |
| Service: | Available processes: |
| | |
| HDFS | datanode, namenode, secondarynamenode |
| Hadoop | |
| Hive | hiveserver |
| JobFlow | oozie |
| Spark | spark history server |
| MapReduce | historyserver |
| YARN | nodemanager, resourcemanager |
+---------------------+-----------------------------------------------------------------------------------------------------------------------+使用以下命令创建主节点组模板:
$ openstack dataprocessing node group template create \
--name vanilla-default-master --plugin vanilla \
--plugin-version <plugin_version> --processes namenode resourcemanager \
--flavor 2 --auto-security-group --floating-ip-pool <pool-id>
+---------------------+--------------------------------------+
| Field | Value |
+---------------------+--------------------------------------+
| Auto security group | True |
| Availability zone | None |
| Flavor id | 2 |
| Floating ip pool | dbd8d1aa-6e8e-4a35-a77b-966c901464d5 |
| Id | 0f066e14-9a73-4379-bbb4-9d9347633e31 |
| Is boot from volume | False |
| Is default | False |
| Is protected | False |
| Is proxy gateway | False |
| Is public | False |
| Name | vanilla-default-master |
| Node processes | namenode, resourcemanager |
| Plugin name | vanilla |
| Security groups | None |
| Use autoconfig | False |
| Version | <plugin_version> |
| Volumes per node | 0 |
+---------------------+--------------------------------------+使用以下命令创建工作线程节点组模板:
$ openstack dataprocessing node group template create \
--name vanilla-default-worker --plugin vanilla \
--plugin-version <plugin_version> --processes datanode nodemanager \
--flavor 2 --auto-security-group --floating-ip-pool <pool-id>
+---------------------+--------------------------------------+
| Field | Value |
+---------------------+--------------------------------------+
| Auto security group | True |
| Availability zone | None |
| Flavor id | 2 |
| Floating ip pool | dbd8d1aa-6e8e-4a35-a77b-966c901464d5 |
| Id | 6546bf44-0590-4539-bfcb-99f8e2c11efc |
| Is boot from volume | False |
| Is default | False |
| Is protected | False |
| Is proxy gateway | False |
| Is public | False |
| Name | vanilla-default-worker |
| Node processes | datanode, nodemanager |
| Plugin name | vanilla |
| Security groups | None |
| Use autoconfig | False |
| Version | <plugin_version> |
| Volumes per node | 0 |
+---------------------+--------------------------------------+您还可以创建节点组模板,设置标志-从卷引导。这将告知节点组从卷而不是映像启动其实例。此功能允许更轻松地进行实时迁移并提高性能。
$ openstack dataprocessing node group template create \
--name vanilla-default-worker --plugin vanilla \
--plugin-version <plugin_version> --processes datanode nodemanager \
--flavor 2 --auto-security-group --floating-ip-pool <pool-id> \
--boot-from-volume
+---------------------+--------------------------------------+
| Field | Value |
+---------------------+--------------------------------------+
| Auto security group | True |
| Availability zone | None |
| Flavor id | 2 |
| Floating ip pool | dbd8d1aa-6e8e-4a35-a77b-966c901464d5 |
| Id | 6546bf44-0590-4539-bfcb-99f8e2c11efc |
| Is boot from volume | True |
| Is default | False |
| Is protected | False |
| Is proxy gateway | False |
| Is public | False |
| Name | vanilla-default-worker |
| Node processes | datanode, nodemanager |
| Plugin name | vanilla |
| Security groups | None |
| Use autoconfig | False |
| Version | <plugin_version> |
| Volumes per node | 0 |
+---------------------+--------------------------------------+或者,您可以从 JSON 文件创建节点组模板。更多关于云计算服务 Openstack 系列的学习文章,请参阅:企业云计算平台 Openstack ,本系列持续更新中。
示例如下
创建一个名为 my_master_template_create.json 的文件,其中包含以下内容:
{
"plugin_name": "vanilla",
"hadoop_version": "<plugin_version>",
"node_processes": [
"namenode",
"resourcemanager"
],
"name": "vanilla-default-master",
"floating_ip_pool": "<floating_ip_pool_id>",
"flavor_id": "2",
"auto_security_group": true
}创建一个名为 my_worker_template_create.json 的文件,其中包含以下内容:
{
"plugin_name": "vanilla",
"hadoop_version": "<plugin_version>",
"node_processes": [
"nodemanager",
"datanode"
],
"name": "vanilla-default-worker",
"floating_ip_pool": "<floating_ip_pool_id>",
"flavor_id": "2",
"auto_security_group": true
}使用 openstack 客户端上传节点组模板:
openstack dataprocessing node group template create \
--json my_master_template_create.json
openstack dataprocessing node group template create \
--json my_worker_template_create.json列出可用的节点组模板,以确保已正确添加它们:
$ openstack dataprocessing node group template list --name vanilla-default
+------------------------+--------------------------------------+-------------+--------------------+
| Name | Id | Plugin name | Version |
+------------------------+--------------------------------------+-------------+--------------------+
| vanilla-default-master | 0f066e14-9a73-4379-bbb4-9d9347633e31 | vanilla | <plugin_version> |
| vanilla-default-worker | 6546bf44-0590-4539-bfcb-99f8e2c11efc | vanilla | <plugin_version> |
+------------------------+--------------------------------------+-------------+--------------------+记住主节点和工作节点组模板的名称或保存 ID,因为它们将在创建群集模板时使用。
创建集群模板
使用以下命令创建群集模板:
$ openstack dataprocessing cluster template create \
--name vanilla-default-cluster \
--node-groups vanilla-default-master:1 vanilla-default-worker:3
+----------------+----------------------------------------------------+
| Field | Value |
+----------------+----------------------------------------------------+
| Anti affinity | |
| Description | None |
| Id | 9d871ebd-88a9-40af-ae3e-d8c8f292401c |
| Is default | False |
| Is protected | False |
| Is public | False |
| Name | vanilla-default-cluster |
| Node groups | vanilla-default-master:1, vanilla-default-worker:3 |
| Plugin name | vanilla |
| Use autoconfig | False |
| Version | <plugin_version> |
+----------------+----------------------------------------------------+或者,可以从 JSON 文件创建群集模板:
创建一个名为 my_cluster_template_create.json 的文件,其中包含以下内容:
{
"plugin_name": "vanilla",
"hadoop_version": "<plugin_version>",
"node_groups": [
{
"name": "worker",
"count": 3,
"node_group_template_id": "6546bf44-0590-4539-bfcb-99f8e2c11efc"
},
{
"name": "master",
"count": 1,
"node_group_template_id": "0f066e14-9a73-4379-bbb4-9d9347633e31"
}
],
"name": "vanilla-default-cluster",
"cluster_configs": {}
}使用 openstack 命令行工具上传集群模板:
openstack dataprocessing cluster template create --json my_cluster_template_create.json记住群集模板名称或保存群集模板 ID,以便在集群配置中使用。可以在创建命令的输出中找到集群 ID,也可以通过列出集群模板找到,如下所示:
$ openstack dataprocessing cluster template list --name vanilla-default
+-------------------------+--------------------------------------+-------------+--------------------+
| Name | Id | Plugin name | Version |
+-------------------------+--------------------------------------+-------------+--------------------+
| vanilla-default-cluster | 9d871ebd-88a9-40af-ae3e-d8c8f292401c | vanilla | <plugin_version> |
+-------------------------+--------------------------------------+-------------+--------------------+创建集群
使用以下命令创建集群:
$ openstack dataprocessing cluster create --name my-cluster-1 \
--cluster-template vanilla-default-cluster --user-keypair my_stack \
--neutron-network private --image sahara-vanilla-latest-ubuntu
+----------------------------+----------------------------------------------------+
| Field | Value |
+----------------------------+----------------------------------------------------+
| Anti affinity | |
| Cluster template id | 9d871ebd-88a9-40af-ae3e-d8c8f292401c |
| Description | |
| Id | 1f0dc6f7-6600-495f-8f3a-8ac08cdb3afc |
| Image | 71b9eeac-c904-4170-866a-1f833ea614f3 |
| Is protected | False |
| Is public | False |
| Is transient | False |
| Name | my-cluster-1 |
| Neutron management network | fabe9dae-6fbd-47ca-9eb1-1543de325efc |
| Node groups | vanilla-default-master:1, vanilla-default-worker:3 |
| Plugin name | vanilla |
| Status | Validating |
| Use autoconfig | False |
| User keypair id | my_stack |
| Version | <plugin_version> |
+----------------------------+----------------------------------------------------+或者,您可以从 JSON 文件创建群集模板:更多关于云计算服务 Openstack 系列的学习文章,请参阅:企业云计算平台 Openstack ,本系列持续更新中。
创建一个名为 my_cluster_create.json 的文件,其中包含以下内容:
{
"name": "my-cluster-1",
"plugin_name": "vanilla",
"hadoop_version": "<plugin_version>",
"cluster_template_id" : "9d871ebd-88a9-40af-ae3e-d8c8f292401c",
"user_keypair_id": "my_stack",
"default_image_id": "71b9eeac-c904-4170-866a-1f833ea614f3",
"neutron_management_network": "fabe9dae-6fbd-47ca-9eb1-1543de325efc"
}具有值my_stack的参数user_keypair_id是通过创建密钥对生成的。您可以在 OpenStack 仪表板中或通过 openstack 命令行客户端创建自己的密钥对,如下所示:
openstack keypair create my_stack --public-key $PATH_TO_PUBLIC_KEY如果 sahara 配置为使用中子进行网络,则还需要在cluster create命令中包含 ----neutron-network 参数,或在 my_cluster_create.json 中包含 neutron_management_network 参数。如果您的环境不使用中子,则应省略这些参数。您可以使用以下命令确定中子网络 ID:
openstack network list创建并启动群集:
openstack dataprocessing cluster create --json my_cluster_create.json使用 openstack 命令行工具验证集群状态,如下所示:
$ openstack dataprocessing cluster show my-cluster-1 -c Status
+--------+--------+
| Field | Value |
+--------+--------+
| Status | Active |
+--------+--------+群集创建操作可能需要几分钟才能完成。在此期间,从上一个命令返回的“状态”可能会显示Active以外的状态。还可以使用wait标志创建集群。在这种情况下,在将群集移动到Active”状态之前,群集创建命令将不会完成。
运行 MapReduce 检查 Hadoop 安装
检查 Hadoop 安装是否正常工作。使用上面使用的 ssh 密钥通过 ssh 登录到 NameNode(通常是主节点):
ssh -i my_stack.pem ubuntu@<namenode_ip>
#切换到 hadoop 用户
sudo su hadoop
#转到共享的Hadoop目录并运行最简单的MapReduce示例
cd /opt/hadoop-<plugin_version>/share/hadoop/mapreduce
/opt/hadoop-<plugin_version>/bin/hadoop jar hadoop-mapreduce-examples-<plugin_version>.jar pi 10 100祝贺!您的Hadoop集群已准备就绪,可以在OpenStack云上运行。
弹性数据处理 (EDP)
作业二进制文件是你为作业定义/上传源代码(主电源和库)的实体。首先,您需要将二进制文件或脚本下载到 swift 容器,并使用以下命令在Sahara中注册您的文件:
(openstack) dataprocessing job binary create --url "swift://integration.sahara/hive.sql" \
--username username --password password --description "My first job binary" hive-binary数据来源
数据源是存放作业的输入和输出的实体。您可以创建与 Swift、manila或 HDFS 相关的数据源。您需要设置数据源的类型(swift,hdfs,manila,maprfs),名称和url。接下来的两个命令将在 swift 中创建输入和输出数据源。
$ openstack dataprocessing data source create --type swift --username admin --password admin \
--url "swift://integration.sahara/input.txt" input
$ openstack dataprocessing data source create --type swift --username admin --password admin \
--url "swift://integration.sahara/output.txt" output如果要在 hdfs 中创建数据源,请使用有效的 hdfs url:
$ openstack dataprocessing data source create --type hdfs --url "hdfs://tmp/input.txt" input
$ openstack dataprocessing data source create --type hdfs --url "hdfs://tmp/output.txt" output工作模板(API 中)
在此步骤中,您需要创建作业模板。您必须使用 type 参数设置作业模板的类型。使用在上一步中创建的作业二进制文件选择主库,并为作业模板设置名称。
命令示例:
$ openstack dataprocessing job template create --type Hive \
--name hive-job-template --main hive-binary工作(API 中的执行)
要启动作业,需要传递以下参数:
-
作业的输入/输出数据源的名称或 ID
-
作业模板的名称或 ID
-
要在其上运行作业的群集的名称或 ID
例如:
$ openstack dataprocessing job execute --input input --output output \
--job-template hive-job-template --cluster my-first-cluster可以使用以下命令检查作业的状态:
$ openstack dataprocessing job show <id_of_your_job>如果有工作输出数据。祝贺你!更多关于云计算服务 Openstack 系列的学习文章,请参阅:企业云计算平台 Openstack ,本系列持续更新中。
参考来源:https://docs.openstack.org/sahara/
latest/user/quickstart.html
读者专属技术群
构建高质量的技术交流社群,欢迎从事后端开发、运维技术进群(备注岗位,已在技术交流群的请勿重复添加)。主要以技术交流、内推、行业探讨为主,请文明发言。广告人士勿入,切勿轻信私聊,防止被骗。
扫码加我好友,拉你进群

推荐阅读 点击标题可跳转

PS:因为公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。点“在看”支持我们吧!

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 0
0 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)