
MachineLearning 33. 机器学习之时间-事件预测与神经网络和Cox回归
简 介利用神经网络对Cox比例风险模型进行扩展,提出了时间-事件预测的新方法。基于嵌套病例对照研究的方法,我们提出了一个损失函数,可以很好地扩展到大型数据集,并可以拟合Cox模型的比例和非比例扩展。通过仿真研究,验证了所提出的损失函数是Cox部分对数似然的良好近似。将提出的方法与现有方法在实际数据集上进行比较,发现具有很强的竞争力,通常在Brier分数和二项对数似然方面产生最佳性能。软件包安装..

简 介
利用神经网络对Cox比例风险模型进行扩展,提出了时间-事件预测的新方法。基于嵌套病例对照研究的方法,我们提出了一个损失函数,可以很好地扩展到大型数据集,并可以拟合Cox模型的比例和非比例扩展。通过仿真研究,验证了所提出的损失函数是Cox部分对数似然的良好近似。将提出的方法与现有方法在实际数据集上进行比较,发现具有很强的竞争力,通常在Brier分数和二项对数似然方面产生最佳性能。
软件包安装
survivalmodels包使用reticulate从Python实现模型。为了使用这些模型,必须按照reticulate::py_install安装所需的Python包。Survivalmodels包含一个辅助函数,用于安装所需的pycox函数(如果还需要,则使用pytorch)。在运行此包中的任何模型之前,如果您尚未安装pycox,请运行。
install_pycox(pip = TRUE, install_torch = FALSE)然后再次安装survivalmodels:
remotes::install_github("RaphaelS1/survivalmodels")
install.packages("survivalmodels")数据读取
library(survival)
library(sampling)
dim(lung)
## [1] 228 10
lung = na.omit(lung)
set.seed(123)
# 每层抽取70%的数据
train_id <- strata(lung, "status", size = rev(round(table(lung$status) * 0.7)))$ID_unit
# 训练数据
trainData <- lung[train_id, ]
# 测试数据
testData <- lung[-train_id, ]实例操作
构建模型
library(survivalmodels)
fit = coxtime(data = trainData)验证
预测predict()参数中type有三种选择:"survival", "risk", "all", 可以获得预测生存矩阵和相对风险:
pred <- predict(fit, testData, type = "survival")
str(pred)
## num [1:50, 1:106] 1 0.999 0.962 0.965 1 ...
## - attr(*, "dimnames")=List of 2
## ..$ : chr [1:50] "0 " "1 " "2 " "3 " ...
## ..$ : chr [1:106] "5" "11" "13" "15" ...一致性
survivalmodels包含了一致性分析的函数cindex(),跟survival包里面的survival::concordance()使用非常相似。
p <- predict(fit, type = "risk", newdata = testData)
cindex(risk = p, truth = testData[, "time"])
## [1] 0.5473856生存分析
根据风险值我们可以将患者分为高低风险组,然后绘制生存曲线:
library(survminer)
testData$risk = p
group = ifelse(testData$risk > mean(testData$risk), "High", "Low")
f <- survfit(Surv(testData$time, testData$status) ~ group)
f
## Call: survfit(formula = Surv(testData$time, testData$status) ~ group)
##
## n events median 0.95LCL 0.95UCL
## group=High 22 16 267 176 NA
## group=Low 28 20 310 210 524
ggsurvplot(f, data = testData, surv.median.line = "hv", legend.title = "Risk Group",
legend.labs = c("Low Risk", "High Risk"), pval = TRUE, ggtheme = theme_bw())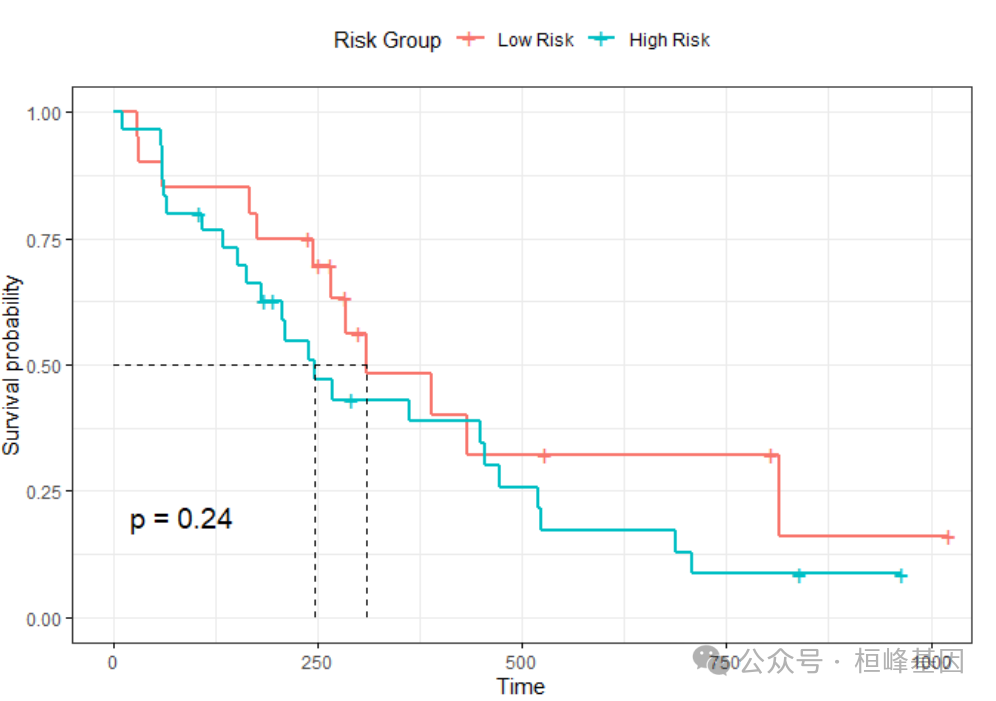
绘制ROC曲线
由于我们所作的模型根时间密切相关因此我们选择timeROC,可以快速的技术出来不同时期的ROC,进一步作图:
library(timeROC)
res <- timeROC(T = testData$time, delta = testData$status, marker = testData$risk,
cause = 1, weighting = "marginal", times = c(1 * 365, 2 * 365), ROC = TRUE, iid = TRUE)
res$AUC_1
## t=365 t=730
## 0.4962963 0.4200000
confint(res, level = 0.95)$CI_AUC
## NULL
plot(res, time = 1 * 365, col = "red", title = FALSE, lwd = 2)
plot(res, time = 2 * 365, add = TRUE, col = "blue", lwd = 2)
legend("bottomright", c("1 Years 0.54", "2 Years 0.72"), col = c("red", "blue", "green"),
lty = 1, lwd = 2)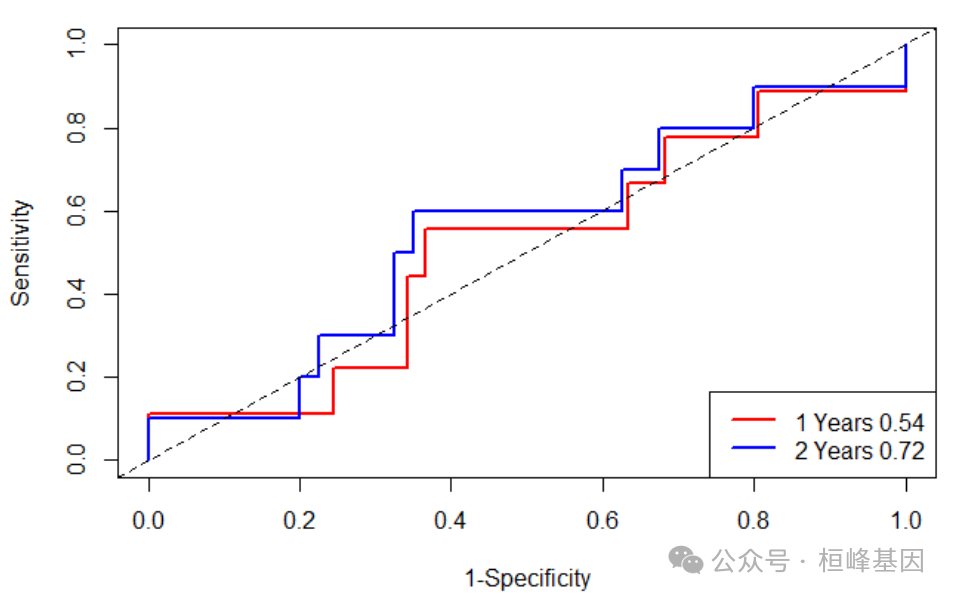
不同时间节点的AUC曲线及其置信区间
再分析不同时间节点的AUC曲线及其置信区间,由于数据量非常小,此图并不明显。
plotAUCcurve(res, conf.int = TRUE, col = "red")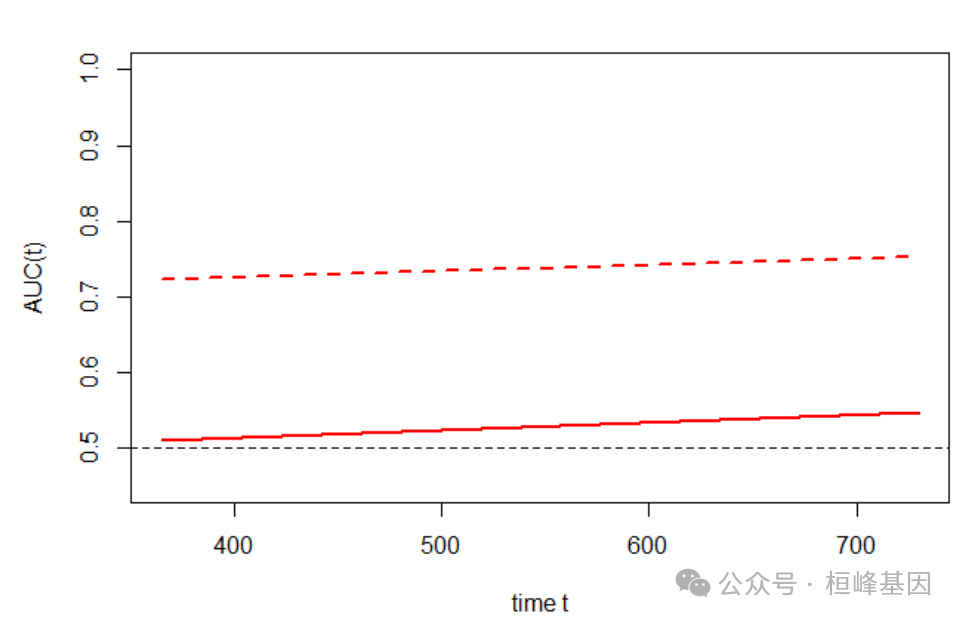
Reference
Kvamme, H., Borgan, Ø., & Scheel, I. (2019). Time-to-event prediction with neural networks and Cox regression. Journal of Machine Learning Research, 20(129), 1–30.
桓峰基因,铸造成功的您!
未来桓峰基因公众号将不间断的推出单细胞系列生信分析教程,
敬请期待!!
桓峰基因官网正式上线,请大家多多关注,还有很多不足之处,大家多多指正!http://www.kyohogene.com/
桓峰基因和投必得合作,文章润色优惠85折,需要文章润色的老师可以直接到网站输入领取桓峰基因专属优惠券码:KYOHOGENE,然后上传,付款时选择桓峰基因优惠券即可享受85折优惠哦!https://www.topeditsci.com/

机器学习42
临床预测54
筛选基因8
支持向量机2
机器学习 · 目录
上一篇MachineLearning 31. 机器学习之基于RNA-seq的基因特征筛选 (GeneSelectR)下一篇IF: 10+ 基于10种人工智能确定预后指数揭示高危骨肉瘤的代谢易感性

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 23
23 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)