
目标检测 SSD: Single Shot MultiBox Detector - Hard Negative Mining
MobileNetV1的深度可分离卷积(depthwise separable convolution)分为Depthwise convolution与Pointwise convolution层级结构是这样1、Depthwise convolution2、Pointwise convolution类似这样的结构(0): Conv2d(128, 128, kernel_size=(3...
目标检测 SSD: Single Shot MultiBox Detector - Hard Negative Mining
flyfish
首先介绍Negative
这还要从伊索寓言:狼来了(精简版)说起
有一位牧童要照看镇上的羊群,但是他开始厌烦这份工作。为了找点乐子,他大喊道:“狼来了!”其实根本一头狼也没有出现。村民们迅速跑来保护羊群,但他们发现这个牧童是在开玩笑后非常生气。
[这样的情形重复出现了很多次。]
一天晚上,牧童看到真的有一头狼靠近羊群,他大声喊道:“狼来了!”村民们不想再被他捉弄,都待在家里不出来。这头饥饿的狼对羊群大开杀戒,美美饱餐了一顿。这下子,整个镇子都揭不开锅了。恐慌也随之而来.
我们做出以下定义:
“狼来了”是正类别( positive class)。
“没有狼”是负类别( negative class)。
我们可以使用一个 2x2 混淆矩阵来总结我们的“狼预测”模型,该矩阵描述了所有可能出现的结果(共四种):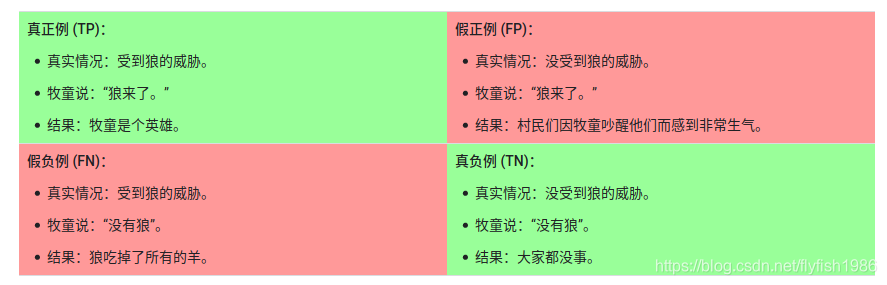 真正例 (TP,True Positive)
真正例 (TP,True Positive)
假正例 (FP,False Positive)
假负例 (FN,False Negative)
真负例 (TN,True Negative)
True Positive是指模型将正类别样本正确地预测为正类别。
True Negative是指模型将负类别样本正确地预测为负类别。
False Positive是指模型将负类别样本错误地预测为正类别。
False Negative是指模型将正类别样本错误地预测为负类别。
问题是什么
我们手工设计算法生成了一堆prior boxs,因为不是所有的prior boxs正好与ground truth正好重合,有完全不包含目标的,也有部分含有目标的.大部分的prior boxs是不包含目标的,不包含目标属于背景类,就是negative class, IoU 超过一定阈值(例如0.5)才认为是positive class,样本的正负类极度的不平衡. 往极端的想,假设一共100个数,99个1,和1个0,模型每次判断是1就行,因为即使这样模型也是能够判断99%的正确.
解决方案
我们把我们的prior boxs分个类分为positive prior和 negative prior,negative prior太多就会造成negative class太多,这样根据high confidence就可以减少negative class,
high confidence才算negative class,low confidence不算negative class
拥有high confidence的negative加入数据集
拥有low confidence的negative忽略它,扔了
原来是 所有样本=正样本+负样本
现在是 所有样本=正样本+拥有high confidence的负样本,而且数量比例为1:3(正样本是1,负样本是3)
这样结果False Negative 就会少.相当于把非背景类识别成了背景类的这种情况就少了
代码
在看代码前先看一个函数的用法
import torch
a = torch.randn(4, 3)
print(a)
print("0:",torch.max(a, 0))
print("1:",torch.max(a, 1))
tensor([[ 0.2292, -1.0423, 0.4708],
[-0.5750, 0.7802, 0.1230],
[-0.0415, -0.3830, -0.3594],
[ 0.7926, -0.6060, -0.7392]])
dim=0:
torch.return_types.max(
values=tensor([0.7926, 0.7802, 0.4708]),
indices=tensor([3, 1, 0]))
dim=1:
torch.return_types.max(
values=tensor([ 0.4708, 0.7802, -0.0415, 0.7926]),
indices=tensor([2, 1, 0, 0]))
4行3列,dim=0按列找最大的,dim=1是按行找最大的
#VGG版的priors有8732个,我们设计的有2278个
# predicted_locs: torch.Size([32, 2278, 4])
# predicted_scores: torch.Size([32, 2278, 21])
# self.priors_cxcy torch.Size([2278, 4])
class MultiBoxLoss(nn.Module):
def __init__(self, priors_cxcy, threshold=0.5, neg_pos_ratio=3, alpha=1.):
super(MultiBoxLoss, self).__init__()
self.priors_cxcy = priors_cxcy
self.priors_xy = cxcy_to_xy(priors_cxcy)
self.threshold = threshold
self.neg_pos_ratio = neg_pos_ratio
self.alpha = alpha
self.smooth_l1 = nn.L1Loss()
self.cross_entropy = nn.CrossEntropyLoss(reduce=False)
def forward(self, predicted_locs, predicted_scores, boxes, labels):
batch_size = predicted_locs.size(0)#这个是根据我们的配置输出,用字母N替代,这里假设是32
n_priors = self.priors_cxcy.size(0)#2278 ,prior的个数
n_classes = predicted_scores.size(2)#21 这个是根据我们数据集一共有多少类
assert n_priors == predicted_locs.size(1) == predicted_scores.size(1)#必须全部是2278,如果不相同说明,设计的网络有问题
true_locs = torch.zeros((batch_size, n_priors, 4), dtype=torch.float).to(device) #N,2278,4
true_classes = torch.zeros((batch_size, n_priors), dtype=torch.long).to(device) #N,2278
for i in range(batch_size):
n_objects = boxes[i].size(0)#n_objects可以是任意个数的目标
overlap = find_jaccard_overlap(boxes[i],
self.priors_xy) #输出的维度是(n_objects, 2278)
#对于每个 prior,,查找重叠最大的目标,
overlap_for_each_prior, object_for_each_prior = overlap.max(dim=0) #2278
# 输出结果先是values,再是indices
#overlap_for_each_prior和object_for_each_prior的shape都是 [2278]
#找出每个目标具有最大重叠的prior
_, prior_for_each_object = overlap.max(dim=1) # 输出两个shape是n_objects
#将每个对象分配给相应的最大重叠prior
object_for_each_prior[prior_for_each_object] = torch.LongTensor(range(n_objects)).to(device)
#为确保这些prior合格,人为地将它们的重叠部分设置为大于0.5
overlap_for_each_prior[prior_for_each_object] = 1.
#每个prior的标签
label_for_each_prior = labels[i][object_for_each_prior]
#将与目标重叠小于阈值的prior 设置为背景类
label_for_each_prior[overlap_for_each_prior < self.threshold] = 0
true_classes[i] = label_for_each_prior
true_locs[i] = cxcy_to_gcxgcy(xy_to_cxcy(boxes[i][object_for_each_prior]), self.priors_cxcy)
#确定prior是positive,目标不是背景类
positive_priors = true_classes != 0
#一共两个loss,confidence loss和localization loss
#Localization loss 的计算仅仅是 positive priors (非背景)
loc_loss = self.smooth_l1(predicted_locs[positive_priors], true_locs[positive_priors])
#confidence loss
#hard negative mining来了
n_positives = positive_priors.sum(dim=1)
n_hard_negatives = self.neg_pos_ratio * n_positives
#找出所有的prior的loss
conf_loss_all = self.cross_entropy(predicted_scores.view(-1, n_classes), true_classes.view(-1))
conf_loss_all = conf_loss_all.view(batch_size, n_priors)
#我们已经知道哪个prior是positive
conf_loss_pos = conf_loss_all[positive_priors]
#我们要找出哪个prior是 hard negative
# conf_loss_neg torch.Size([N, 2278])
# hardness_ranks torch.Size([N, 2278])
# n_hard_negatives torch.Size([N])
#positive_priors([N, 2278])
conf_loss_neg = conf_loss_all.clone() #([N, 2278])
conf_loss_neg[positive_priors] = 0.
print(conf_loss_neg[positive_priors],conf_loss_neg)
conf_loss_neg, _ = conf_loss_neg.sort(dim=1, descending=True) #降序
hardness_ranks = torch.LongTensor(range(n_priors)).unsqueeze(0).expand_as(conf_loss_neg).to(device) #hardness_ranks torch.Size([N, 2278])
hard_negatives = hardness_ranks < n_hard_negatives.unsqueeze(1)
# hardness_ranks torch.Size([N, 2278])
# n_hard_negatives torch.Size([N])
conf_loss_hard_neg = conf_loss_neg[hard_negatives]
#这里按照论文中叙述,仅对positive priors进行平均,尽管同时计算 positive prior和 hard-negative prior。
conf_loss = (conf_loss_hard_neg.sum() + conf_loss_pos.sum()) / n_positives.sum().float()
# self.alpha是权重,论文里是1
return conf_loss + self.alpha * loc_loss

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 1
1 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)