
FastToG:广深快推理,社区检测划分知识图并进行局部搜索,图算法社区粗筛 + LLM对社区精剪
作者的“主动观察”:他们留意到了检索扩展的“宽度”与“深度”这两大主要矛盾点,并从已有文献和方法中发现了“节点级”推理难以兼顾效率和可解释性的症结。作者的“思维模型”在“社区”这种更高层次的图结构上做检索,可以用更少的步骤覆盖更多节点;双阶段剪枝配合社区描述转文本的方式,能减少噪声并保持较好可读性。作者的“提出假设”:基于社区划分的多跳检索路径,一定能在多跳问答场景下带来准确率与效率提升;通过合适
FastToG:广深快推理,社区检测划分知识图并进行局部搜索,图算法社区粗筛 + LLM对社区精剪
论文:Fast Think-on-Graph: Wider, Deeper and Faster Reasoning of Large Language Model on Knowledge Graph
代码: https://github.com/dosonleung/FastToG
论文大纲
├── 1 引言【提出研究背景与动机】
│ ├── 检索增强生成 RAG【背景】
│ │ ├── Naive RAG【RAG早期形态】
│ │ │ ├── 简单高效【优势】
│ │ │ └── 存在上下文不足、易幻觉【问题】
│ │ └── Graph RAG 的兴起【技术演进】
│ │ ├── 融合知识图谱【关键手段】
│ │ └── 实现更复杂推理【价值】
│ └── 研究目标【动机】
│ ├── 提升大模型的推理深度与精确性【目标之一】
│ └── 控制检索范围、提升效率【目标之二】
├── 2 Graph RAG 分类【对已有方法的总结】
│ ├── 1-w 1-d Graph RAG【窄且浅的检索】
│ │ ├── 单实体或单跳关系【特征】
│ │ └── 延续 Naive RAG 的局限【问题】
│ ├── n-w (宽) Graph RAG【更宽的检索范围】
│ │ ├── 采用社区检测或聚类【基本方法】
│ │ └── 为 LLM 提供更完整上下文【优势】
│ └── n-d (深) Graph RAG【更深的多跳推理】
│ ├── 多步链式推理【核心思路】
│ └── 需频繁调用LLM、计算成本高【问题】
├── 3 FastToG:宽与深的结合【核心方法】
│ ├── 总体思路【说明 FastToG 的本质】
│ │ ├── “community by community” 的推理流程【关键理念】
│ │ └── 同时兼顾宽度和深度【目标】
│ ├── Local Community Search (LCS)【子模块】
│ │ ├── 从局部子图检索社区【【子图搜索】关系】
│ │ ├── 社区检测算法(Louvain、GN等)【方法】
│ │ └── 最大社区大小、邻居采样【限制与策略】
│ ├── 社区修剪策略【社区级别的两阶段筛选】
│ │ ├── Modularity-based Coarse-Pruning【粗剪】
│ │ │ └── 基于模块度衡量社区紧密度【筛选标准】
│ │ └── LLMs-based Fine-Pruning【细剪】
│ │ └── 提示大模型对候选社区做最终选择【多选或单选】
│ ├── 社区转文本 (Community-to-Text)【文本化步骤】
│ │ ├── Triple2Text【逐三元组拼接】
│ │ └── Graph2Text【基于 T5 等模型的自然语言化】
│ └── Reasoning 阶段【最后的推理合成】
│ ├── 多条社区链合并【宽度维度】
│ ├── 分迭代调用LLM生成答案【深度维度】
│ └── 超过最大迭代后降级为内置知识推理【降级策略】
├── 4 实验与结果【实证分析】
│ ├── 数据集【使用的评测数据】
│ │ ├── CWQ、WebQSP等多跳问答【场景】
│ │ ├── ZSRE、TREx等槽填充【场景】
│ │ └── Creak常识推理【场景】
│ ├── 实验设计【对照方法】
│ │ ├── Inner-knowledge 直接生成/CoT/CoT-SC【无外部检索】
│ │ └── 各类 Graph RAG(1-d 1-w、n-d 1-w等)【对比项】
│ ├── 性能指标【精度与调用代价】
│ │ ├── 准确率(hit@1)【主要指标】
│ │ └── LLM调用次数或推理深度【效率指标】
│ └── 实验结果【结论】
│ ├── FastToG 在准确率方面优于基线【主要发现】
│ └── 社区检测及修剪提高推理效率【主要发现】
├── 5 进一步分析【补充与可视化】
│ ├── Ablation Study【模型各部分消融】
│ │ ├── 社区大小变化的影响【准确率与深度的平衡】
│ │ └── 不同社区检测算法的比较【精度差异】
│ ├── Case Study【案例详解】
│ │ ├── 大模型“社区级”思考路径【可视化图示】
│ │ └── 思路可解释性和可追溯性【用户理解】
│ └── Hallucination 分析【模型幻觉现象】
│ ├── Graph2Text 中的事实/逻辑不一致【常见问题】
│ └── 提示调整及社区规模控制可减轻幻觉【改进方向】
└── 6 结论与展望【总结研究贡献】
├── FastToG 在精度与效率上的综合平衡【核心贡献】
├── 它为 n-w n-d Graph RAG 提供可行策略【方法价值】
└── 后续工作【展望】
├── 融合更多语义与语法信息【优化空间】
└── 开发多层级社区检索及更优文本转换【未来方向】
核心方法:
├── 1 FastToG 核心方法【整体框架】
│ ├── 输入:查询 z【查询问题】
│ │ └── 输入一个查询问题,目标是通过图检索和推理生成准确的回答【查询目标】
│ ├── Local Community Search (LCS)【子模块:局部社区搜索】
│ │ ├── 输入:当前社区 c【当前社区】
│ │ ├── 输入:查询 z【查询问题】
│ │ ├── 处理过程【LCS 流程】
│ │ │ ├── 获取子图 g【获取当前社区附近的子图】
│ │ │ ├── 使用社区检测算法(如 Louvain)识别紧密的节点群体【社区检测】
│ │ │ └── 计算模块度,选择最佳社区【模块度优化】
│ │ ├── 输出:邻接社区 C【候选社区】
│ │ └── 输出解释:从查询问题中提取信息,并返回潜在相关的社区集合【社区候选集】
│ ├── 社区修剪策略【减少冗余和提升效率】
│ │ ├── 输入:候选社区 C【LCS 输出】
│ │ ├── 处理过程【修剪过程】
│ │ │ ├── 粗修剪:基于模块度计算,去除低质量社区【模块度粗修剪】
│ │ │ └── 细修剪:通过 LLM 提示对剩余社区做选择【细修剪】
│ │ └── 输出:精简社区集 C'【优化后的候选社区】
│ ├── 社区转文本 (Community-to-Text)【转换为 LLM 可理解的文本】
│ │ ├── 输入:社区 C'【精简后的候选社区】
│ │ ├── 处理过程【转换过程】
│ │ │ ├── Triple2Text:将三元组转换为文本【三元组转文本】
│ │ │ └── Graph2Text:用生成模型将图结构转换为自然语言描述【图转文本】
│ │ └── 输出:转换后的文本【LLM 输入格式】
│ ├── Reasoning 阶段【推理过程】
│ │ ├── 输入:查询 z 和转换文本【查询与文本描述】
│ │ ├── 处理过程【推理流程】
│ │ │ ├── 对多个社区链进行推理【多链推理】
│ │ │ ├── 对每条链进行细化修剪【链细化】
│ │ │ └── 在每条链中逐步选择相关社区【逐步推理】
│ │ └── 输出:最终答案【推理结果】
│ └── 输出:答案【最终推理结果】
│ ├── 如果推理链足够完整,返回准确答案【生成准确答案】
│ └── 如果超出最大迭代次数,则降级为内置知识推理【降级处理】
1. Why:要解决什么现实问题?
-
RAG(检索增强生成)在复杂场景下的不足
- 传统的检索增强生成(Naive RAG)多基于文档向量召回,容易出现低精度、低召回率以及难以解释的情况,无法很好地应对复杂查询。
- 当用户问题需要多跳检索或关系推理时,单纯的文本检索难以充分利用上下文和实体间的深层关联。
-
现有 Graph RAG 的挑战
- 宽度问题:许多方法只检索与目标节点一跳(或少量邻居节点)的信息,导致缺乏足够的上下文和全局视角。
- 深度问题:需要多步推理的场景下,即使图算法可以提供更多关系路径,LLM 反复“思考”每个节点或每条边会导致时间和计算成本过高。
- 结构匹配问题:知识图谱内的节点、边与大模型(LLM)的文本输入之间存在结构不匹配。如何在保证信息完整的同时,又不过度增加噪声,是一个难点。
Naive RAG 在简单问题上也许够用,但在高复杂、多跳关联以及极其重视准确性和可解释性的医疗领域,单纯的文本召回已远远不够。而 Graph RAG 虽然能在知识图谱上做更多关系分析,却面临宽度不足、深度过高、以及图—文本结构不匹配等挑战。真正的核心现实需求在于如何高效地在大规模医疗知识图谱中进行多跳推理,同时兼顾可解释性与检索效率。
这就呼应了论文讨论的内容:利用群落(社区)检测等图算法,将相关节点划分成多个紧密关联的子社区,在社区级层面进行检索、推理并将结构信息转换成自然语言,对于像“哮喘合并心血管风险患者用药”这样的复杂问题,将会显著提升检索准确度和可解释性,并减少巨量节点带来的计算开销。
当将医疗文献、药物与疾病的相互关系构建成医疗知识图谱之后,虽然能更好地表达“症状-疾病-药物-副作用-禁忌症”之间的关系,但仍面临以下问题:
-
宽度问题(Context 不够广)
- 某些 Graph RAG 方法只检索目标实体(如“哮喘”)的一跳邻居节点,比如“哮喘-常用药物”或“哮喘-相关症状”等,这远不足以回答“有心血管风险的哮喘患者可以使用哪些药物”这种复杂问题。
- 实际上,需要引入更多关联信息,如“心血管病变”相关节点、药物副作用与禁忌节点、慢阻肺/过敏等多种可能性;但若只在一跳之内找邻居,很可能遗漏关键信息。
-
深度问题(LLM 反复推理成本高)
- 在医疗知识图谱中,疾病—药物—副作用—其他并发症的链条通常很深,若要沿着图上多条路径“多跳”遍历以获得足够信息,LLM 需进行频繁的多轮推理:
- 找到“哮喘”可能关联的药物;
- 对每种药物再查是否有心血管高危患者禁忌;
- 若该药物是合并用药,需要看其它成分之间有没有冲突……
- 若是逐节点、逐边搜索,LLM 会陷入重复调用与推理链过长的困境,时间和计算代价较高。
- 在医疗知识图谱中,疾病—药物—副作用—其他并发症的链条通常很深,若要沿着图上多条路径“多跳”遍历以获得足够信息,LLM 需进行频繁的多轮推理:
-
结构匹配问题(KG 与 LLM 输入的不兼容)
- 知识图谱存储的是三元组结构,比如
(哮喘, 常用药物, 沙丁胺醇)、(沙丁胺醇, 禁忌症, 高血压并发心衰)。 - 但 LLM 处理的依然是自然语言输入,如何把大规模、复杂的图结构高效转化成可读文本,并保证不遗漏重要信息、不产生太多噪声,是个难点。
- 知识图谱存储的是三元组结构,比如
-
需解决的核心现实需求
- 在大规模知识图谱上,有效利用“群落”(社区)结构来减少噪声与搜索空间,以实现高效且可解释的多跳推理。
- 兼顾 宽度(聚合足够多的上下文实体)与 深度(跨越更多跳数)之间的平衡,同时避免超大规模图检索时的计算代价飙升。
2. What:核心发现或论点是什么?
-
提出“Fast Think-on-Graph (FastToG)”范式
- 将大模型在知识图谱上进行推理的过程设计为“按社区(群落)思考”而不是简单地逐节点或链式多跳推理。
- 通过社区检测 + 双阶段剪枝 + 社区转文本等关键步骤,能够在保证检索深度的同时,显著降低多余节点带来的干扰与计算成本。
-
核心观点
- Wider:在社区粒度做检索,能有效聚合更多相关实体,扩展上下文宽度。
- Deeper:采用多层的本地社区搜索(Local Community Search,LCS)+ 多次推理迭代,可覆盖远距离实体关联,提高复杂查询的召回。
- Faster:社区级检索减少了 LLM 推理迭代次数;引入基于模块度的粗剪 + LLM 精剪,使得社区规模得到有效控制,大幅降低推理时间。
-
论文主张
- FastToG 相比已有的图检索增强生成方法,能在准确率、推理速度、可解释性三方面取得显著提升。
- FastToG 中的“Graph2Text”与“Triple2Text”转换机制,可更好地将图数据与 LLM 的文本输入对接,从而降低“结构不兼容”导致的模型困扰。
3. How:研究方法与创新点,以及数据支持与反驳应对
3.1 前人研究的局限性
-
1-w 1-d 与 n-w 或 n-d 方法的不足
- 1-w 1-d:通常只抓取一个实体或一跳邻居;无法应对复杂查询,容易出现遗漏信息。
- n-w:扩大单次检索范围,但当图很大时,容易导致噪声激增;且只在宽度扩展,深度仍受限。
- n-d:能进行更深的多跳检索,但需要 LLM 反复逐节点地“思考”,计算开销过高且容易累积误差。
-
现有社区检测在 RAG 中的应用问题
- 仅用随机采样或全局社区进行检索时,社区粒度很难兼顾相关性和规模;部分方法因耦合紧密,导致效率低下或召回率不足。
3.2 创新方法/视角
-
社区级多跳推理框架
- 社区检测 + 本地社区搜索(Local Community Search, LCS):
- 在当前社区附近的 n 跳子图上做局部社区划分(避免对整个超大型知识图谱做全局划分)。
- 引入“双阶段剪枝”:
1)基于“模块度(Modularity)”的粗剪,过滤掉结构不紧密或与已有社区重复度高的部分。
2)由 LLM 通过 Prompt 进行精剪,选择最可能与问题相关的社区,兼顾准确度与速度。
- 社区检测 + 本地社区搜索(Local Community Search, LCS):
-
社区到文本的转化 (Community-to-Text)
- Triple2Text:将社区中的 RDF 三元组直接转成若干句子,保留原始信息,但会有一定冗余。
- Graph2Text:采用微调过的 T5 模型对社区进行自然语言描述,总结社区内多个三元组的要点,但可能引入幻觉(hallucination)。
- 通过这两种模式的对照试验,找出在“准确性”与“简洁性”之间的平衡。
-
“按社区思考”带来的好处
- (1)减少 LLM 推理步数:由于每一步“思考”的单位是一个社区而非一个节点,大幅缩短多跳推理的链路长度。
- (2)提升推理可解释性:对用户展示的检索路径是一个个紧密关联的社区,而非大量零散节点,逻辑更清晰。
3.3 关键数据支持
-
实验数据与指标
- 数据集:包括多跳问答(CWQ、WebQSP、QALD 等)、槽填充(ZSRE、TREx)以及常识推理(Creak)。
- 与现有方法的比较:对比 IO、CoT、CoT-SC、1-w 1-d、n-w、n-d 等范式,结果显示在准确率(Hit@1)和推理效率(LLM 调用次数)上均有提升。
-
消融试验与可视化案例
- 社区最大规模(Max Size) 对系统性能的影响:
- 设置不同的社区大小阈值,考察推理深度与准确率的权衡;发现社区过大时,虽然减少推理链长度,但也会引入更多噪声或幻觉。
- 不同社区检测算法的影响:Louvain、Girvan-Newman、Hierarchical、Spectral,结果表明非随机聚类的检测算法都能带来稳定收益。
- Graph2Text 幻觉出现率分析:社区过大时,幻觉率会升高,从而影响最终回答的准确率。
- 社区最大规模(Max Size) 对系统性能的影响:
3.4 可能的反驳及应对
-
反驳 1:社区检测本身计算量大,是否真正能提升整体速度?
- 应对:FastToG 采用在局部子图上的社区检测,且设置社区大小与半径等参数有效限制检索规模,整体效率仍优于传统多跳节点级检索。
-
反驳 2:社区转文本(特别是 Graph2Text)引入幻觉,可能降低准确度
- 应对:在论文中通过双模式(Triple2Text、Graph2Text)对照;在许多场景下,Graph2Text 易读性更好,并引入了后续的 LLM 精剪策略,能较大程度减少错误传播。
-
反驳 3:对超大规模知识图谱的适用性如何?
- 应对:本地社区搜索框架天然适合分块检索,可以结合并行处理或索引优化;同时提供了社区大小限制和重启机制,防止深层次搜索时的指数爆炸。
4. How Good:研究的理论贡献和实践意义
-
理论贡献
- 提出了一种“按社区思考”的新型 RAG 范式,兼顾宽度与深度,同时降低了多余推理开销。
- 在方法层面上,将“社区检测—双阶段剪枝—社区文本化”系统化整合,丰富了现有多跳知识图谱问答的技术栈。
-
实践意义
- 大模型在知识图谱场景的落地:FastToG 为产业界需要兼顾多跳推理与高效率的场景(如金融、医疗、法律等海量实体关系检索)提供了参考。
- 可解释性与可控性:基于社区的推理路径易于可视化展示,提升对大模型推理过程的可审计和可控制。
- 通用扩展性:不仅适用于问答,还可广泛应用于对话系统、推荐系统、信息抽取等需要知识支撑的场景。
设计思路
1. 作者的观察:在现有 RAG(检索增强生成)方法中发现的问题
-
Naive RAG 存在局限性
- 观察到的现象:
- 仅依赖文档切片和向量召回时,回答的准确率不足、对多跳(复杂)问题的召回率不够,且可解释性也偏弱。
- 在需要多级推理、复杂实体关系的场景下,单纯的文本检索或固定的“一跳查询”方式往往失效。
- 作者所关注的“变量”:
- 是否运用了知识图谱(KG);
- 是否采用了多跳推理;
- 检索到的上下文宽度和深度如何变化;
- 大语言模型(LLM)在回答时所需的推理链长度。
- 结论性观察:作者在综述前人工作时发现,宽度(n-w)和深度(n-d)这两个重要维度各自都面临权衡难题:“宽”会带来噪声,“深”会带来高成本。
- 观察到的现象:
-
图检索增强生成(Graph RAG)中的不足
- 观察到的现象:
- 如果单纯依赖节点级别的多跳 BFS/DFS,检索路径会过多,导致 LLM 推理迭代过多;
- 许多方法要么只在一跳范围内检索到少量关联(导致遗漏),要么在多跳范围内生成极多路径(导致冗余和时间消耗过大)。
- 作者所关注的“变量”:
- 图是否是稠密的;
- 多跳推理时,LLM 是否频繁调用;
- 检索过程中如何剔除冗余节点或不相关节点。
- 结论性观察:单纯扩大检索深度或宽度,都不足以有效提高效率,必须找到更“合适”的聚合方式。
- 观察到的现象:
2. 作者的假设:设计新的社区级推理范式(FastToG)
-
假设 1:
“如果我们把‘节点级思考’转换为‘社区级思考’,那么多跳推理将能减少不必要的节点遍历,既保证信息的覆盖,又减少 LLM 的推理负担。”
- 为什么产生此假设:
- 作者看到过往方法里,节点级的 n-hop 搜索导致路径太长、LLM 调用频次过多;若按“社区”汇总,能以更少的中间步骤到达所需信息。
- 与其他变量的关系:
- 需要在子图上做社区检测,才能把节点汇总为若干子团体;
- 需要控制社区大小,以免社区过大而产生噪声或文本幻觉。
- 为什么产生此假设:
-
假设 2:
“在社区检测过程中进行‘双阶段剪枝’(先基于模块度粗剪,再让 LLM 精剪),可以在保证准确率的同时,大幅减少冗余社区。”
- 为什么产生此假设:
- 传统的社区检测算法若一次性得到所有社区,仍然可能数量庞大、包含很多与查询无关的节点。
- 如果先用模块度(Modularity)做结构层面筛选,再由 LLM 结合查询文本做进一步精剪,就能把不相关的社区排除。
- 与其他变量的关系:
- 如果社区过于松散(模块度很低),对查询毫无帮助;
- 若让 LLM 直接选择过多社区,调用次数又会增大。
- 为什么产生此假设:
-
假设 3:
“采用 Community-to-Text(特别是 Graph2Text)可以更好地将社区结构信息整合为连贯文本,从而提升 LLM 的理解度和回答准确率。”
- 为什么产生此假设:
- LLM 的输入是自然语言,而知识图谱是三元组结构;
- 若三元组直接输出成纯文本(Triple2Text),可能缺少凝练;若借助微调后的 T5 模型把多条三元组概括成自然语言段落(Graph2Text),模型理解效率可能更高。
- 与其他变量的关系:
- Graph2Text 也引入了幻觉风险,需要在社区规模、文本简化和准确度之间做平衡。
- 为什么产生此假设:
3. 作者的验证:实验与数据支持
-
验证内容:
- 选取多套数据集(CWQ、WebQSP、QALD、ZSRE、TREx、Creak)进行问答测试;
- 比对已有方法(Naive RAG, CoT, CoT-SC, n-d 1-w, n-w 等)与所提出的 FastToG,在准确率(Hit@1)和推理效率(LLM 调用次数)上的表现。
- 分别尝试:
- 不同社区检测算法(Louvain、Girvan-Newman 等);
- 不同 MaxSize(社区最大节点数)设定;
- Triple2Text 与 Graph2Text 在不同条件下的差异。
-
数据与关键结果
- 准确率:FastToG 在所有数据集上均取得更好结果,尤其在需要多跳推理的场景中优势更明显。
- 推理效率:随着社区大小从 1 增加到一定阈值(如 4),LLM 的多轮推理深度明显降低,减少了重复调用。
- 可解释性案例:利用可视化展示了社区为单位的路径,让用户理解“从哪几个紧密社区跳到下一个社区”从而找到答案。
-
结论性验证
- 基于社区级思考的多跳检索框架(FastToG)能够在准确率和效率上优于基于节点级的深度或宽度扩展。
- 双阶段剪枝保证了在大图场景下也能快速找到最优候选社区;
- Graph2Text 确实带来一定幻觉,但在多数情形下依然提升了对复杂社区的聚合表达,为 LLM 提供了简洁且上下文丰富的输入。
4. 作者的元思路总结
- 作者的“主动观察”:他们留意到了检索扩展的“宽度”与“深度”这两大主要矛盾点,并从已有文献和方法中发现了“节点级”推理难以兼顾效率和可解释性的症结。
- 作者的“思维模型”:
- 在“社区”这种更高层次的图结构上做检索,可以用更少的步骤覆盖更多节点;
- 双阶段剪枝配合社区描述转文本的方式,能减少噪声并保持较好可读性。
- 作者的“提出假设”:基于社区划分的多跳检索路径,一定能在多跳问答场景下带来准确率与效率提升;通过合适的剪枝和文本转换,还可以应对图的稠密度问题和 LLM 可解释性问题。
- 作者的“验证过程”:采用多数据集、对照主流方法、做消融试验(不同社区检测算法、不同文本转换方式)等,从多角度印证了他们对“为什么更好”的回答。
从这些环节可以看到,作者的整体思路背后体现了典型的**“观察—假设—验证”**科学研究过程:
- 观察:锁定检索深度和宽度的矛盾;
- 假设:社区级思考可以更宽更深更快;
- 验证:用系统实验设计、评测指标、对照试验来证明该方法的有效性。
以上就是基于论文文本所展现的作者元思考方式:他们善于捕捉“不寻常”之处(Naive RAG 在多跳问题上的瓶颈),聚焦关键“变量”(图的宽度、深度、社区大小、LLM 调用次数等),并提出可操作的假设(社区级思考、双阶段剪枝、文本转换),再用多维度实验验证和细化,从而形成相对完备且具有可解释性的研究闭环。
全流程
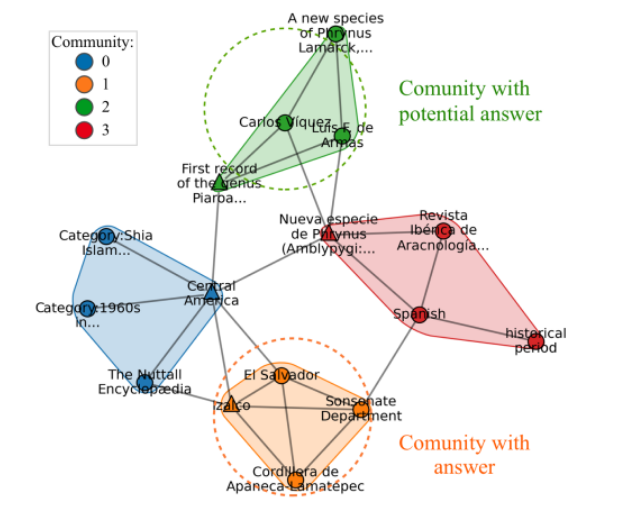
FastToG方法的总体流程,包括四个关键阶段:
-
(a) Community Detection on Subgraph(子图的社区检测):模型从**起始/头社区(Start/Header Community)**开始,通过图算法对邻域社区进行检测和提取,准备进一步处理。
-
(b) Modularity-based Coarse-pruning(基于模块度的粗修剪):在这一阶段,FastToG根据社区之间的模块度(modularity)进行初步的修剪,去除那些与查询无关或相关性较低的社区,从而减小搜索范围,提高推理效率。
-
© LLMs-based Fine-pruning(基于LLM的精修剪):此阶段进一步细化修剪过程,利用LLM对社区进行精修剪,精确地选择与问题最相关的社区。
-
(d) Reasoning(推理):最后,在经过粗修剪和精修剪后的社区集合中,FastToG开始推理,依据推理过程提供的答案来进行最终的回答。如果答案不确定,模型会重新开始,从新的社区链条出发进行推理。
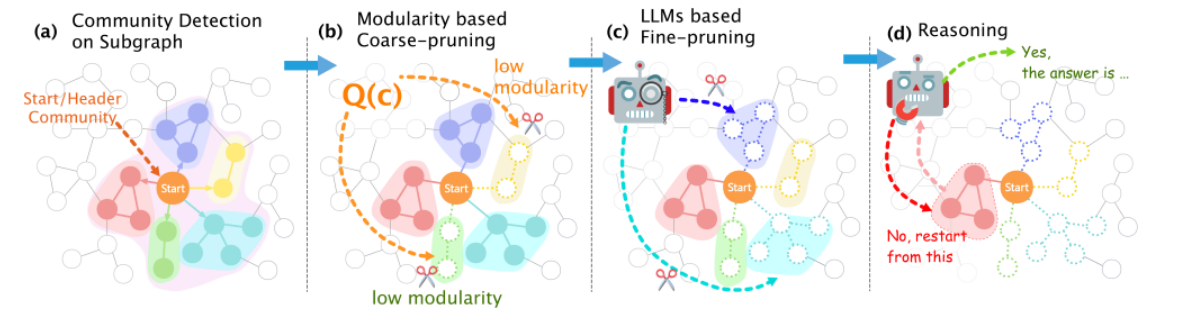
FastToG在实际图谱数据中如何进行社区检索。
图中,节点的颜色代表了不同的社区(0、1、2、3),每个社区内的节点紧密连接,社区之间的边表示可能的连接关系。
- 绿色社区代表最终找到的答案社区(Community with answer),即包含答案的社区。
- 橙色社区代表潜在答案社区(Community with potential answer),该社区包含一些可能相关的信息,虽然不能直接得出结论,但提供了有用的线索。
- FastToG模型通过检测图中的这些社区来缩小答案空间,逐步提高推理的效率和准确性。
提问
问题 1
FastToG 提出的「社区为单位」的检索思想,若知识图谱节点极其稀疏(即大部分节点只和少数邻居相连),是否会导致社区划分毫无意义?作者如何在论文中应对这种“几乎无社区可划分”的情况?
回答 1
论文虽然更多关注大型、相对稠密的知识图谱(如 Wikidata),但作者在“社区检测”一节中明确指出其方法也适用于各种结构的图,因为他们会在检索前局部构建子图 (local subgraph) 并进行社区划分。
若某些子图极度稀疏,则可通过设置较小的 max size 以及随机采样、重启等策略,使得系统在检测不到合适社区时会自动回退到“由 LLM 内部知识回答”的降级方案,从而避免“无社区”导致的整体检索失败。
问题 2
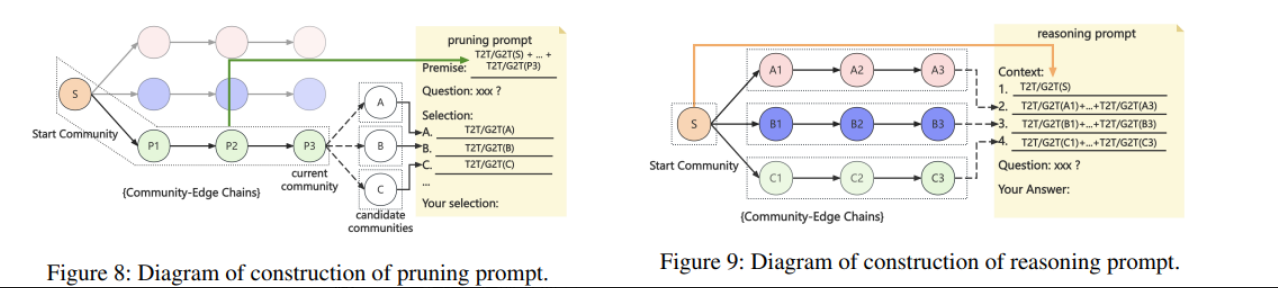
文中提到的 Modularity-based Coarse-Pruning(基于模块度的粗筛)要先计算社区的模块度 Q© ,然后再进行 Fine-Pruning。
若在 Fine-Pruning 阶段 Large Language Model 决定的排序与模块度排序相冲突,会如何处理?是否会产生不一致?
回答 2
作者在“Local Community Search”小节里阐述:Modularity-based Coarse-Pruning 先用模块度计算对社区进行初步筛减,只保留相对模块度最高的若干社区。Fine-Pruning 阶段则用 LLM 进行最终挑选。
若出现冲突,实际是因为 Fine-Pruning 阶段的目标函数与模块度不同,但作者并不强行统一,只要社区能通过粗筛保留下来,后续由 LLM 根据语义和上下文进行单选或多选,产生的结果就是最终决策。
因此并不存在“让 LLM 与模块度打架”的问题,因为粗筛已经先滤掉了一批明显不相关或过度噪声的社区。
问题 3
论文实验部分对比了 FastToG 与其他 RAG 方法的准确率。在 n-d 1-w(比如 ToG)与 n-w 1-d(如 KGP)之间,FastToG 被归类为 n-w n-d。
为何作者能宣称此类 “n-w n-d” 方法在复杂问答上显著优于传统 n-d 1-w?是因为单纯把社区当作“更大 hop”而已,还是另有核心思想?
回答 3
作者在图 1 与正文中有明确的阐述:
- 传统 n-d 1-w 通过一条长链(chain of entities/relations)层层递进,这会在图密集时爆发出大量路径;
- 传统 n-w 1-d 虽可并行检索很多节点,却只是一跳,无法深层推理;
- “n-w n-d” 核心在于:用社区做“思考步”,每个社区都包含若干实体与关系,使得大跨度的信息查询可以在较少“步数”下完成(因为每
一步走的“跨度”是一个社区,不是一个节点),从而既拥有宽度(多个社区并行)又拥有深度(社区内包含更长链条),因此对复杂问答有显著优势。
问题 4
在实验中,FastToG 的 Graph2Text(g2t)有时会因为“幻觉”导致文本中出现与原始三元组不一致的内容。
作者在文中或附录中是否量化了此“幻觉”对最终问答准确率的影响?如何保证 g2t 不会误导后续 LLM 的推理?
回答 4
作者在附录(Appendix B2)与部分图表中做了定性与定量分析。
他们统计了若干规模下的社区,经 g2t 转换为自然语言后的错误率随社区大小变化而攀升,并将其定义为“Hallucination Ratio”。
一旦转写文本中出现较多不实信息,就可能在后续推理阶段诱导 LLM 得到错误结论。
为缓解此问题,作者采用三种手段:
- 控制社区最大尺寸
max size,降低过大社区的噪声; - 在 coarse-pruning 时进一步剔除“低模块度”导致的潜在冗余边;
- 在出现严重冲突时,系统会进行多轮查询或最终退化为单纯依赖 LLM 内部知识的降级回答。
问题 5
FastToG 在推理阶段要多次调用 LLM 来完成“社区选择(单选或多选)”以及最后的回答生成,这在大规模实际应用中是否会因为 Token 消耗和调用次数太多而失去意义?
作者在文中是如何平衡推理效果和调用开销的?
回答 5
作者在“Performance on Efficiency”小节中指出,FastToG 需要约 2W*Dmax + Dmax + 2 次 LLM 调用(W 为社区链并行数量,Dmax 为最大迭代深度)。
他们通过以下手段控制开销:
- 在初始阶段只进行一次社区检测和一次粗筛,多选生成 W 条链;
- 后续更新时对每条链仅做单选;
- 提早终止策略:如果在某次推理就已足够回答,会停止继续迭代;
- 若超限仍无法回答,则直接采用 LLM 内部知识生成答案(对结果不再检索)。
这样做可减少不必要的推理轮数,并在难题上有清晰的“放弃”机制,缓解了调用成本过高的问题。
问题 6
作者在动机中提及传统知识检索(Naive RAG 或向量索引)面临的“多跳查询无能”与“解释性不足”等问题。
那么 FastToG 把知识图谱作为外部语义结构后,能否给出可视化的推理过程?
文中是否提供可视化来保证最终答案是“可解释”的?
回答 6
是的,作者在“Case Study”部分提供了针对真实问题在 Wikidata 上的可视化社区检索过程示例(图 6)。
他们展示了如何从起始社区不断筛选下一步社区,并把最终合并后的社区用图形或文本形式呈现给读者,帮助理解回答背后的路径。
作者特别指出,这种“社区为步”的检索流程在可视化时更简洁,也比逐点 BFS/DFS 式的可视化更具可读性。
问题 7
在社区划分算法的选择上,作者做了 Louvain、Girvan-Newman、层次聚类(Hier)、谱聚类(Spectral Clustering)以及随机划分(Rand)等测试。
既然结果显示它们差异并不是非常大,作者为什么最终仍推荐 Louvain,而不是更直观的 GN 或者更易实现的层次聚类?
回答 7
论文表 3 里比较了这几种算法的对照实验,发现只要不是随机划分,准确率都相差不大。
但 Louvain 具有典型的高效性与可伸缩性,尤其适合大规模图谱场景,而且在作者的实现中它能更好地和“模块度”这个衡量指标衔接。
此外 GN 算法对于大规模数据开销会更高,而层次聚类要反复合并/拆分子集,在超大图中相对慢一些,所以 Louvain 是平衡了准确率和性能的折中方案。
问题 8
文中给出的算法示例中,如果一个社区的所有节点都与问题 z 之间只存在极远的间接关联,那么它有可能在 coarse-pruning(基于模块度)时没被剔除,却在 fine-pruning 阶段再次被误保留,从而污染最终结果吗?
回答 8
作者对这一点有所解释:
- 粗筛阶段主要看社区与当前上下文社区之间的连接强度或“模块度”;
- Fine-Pruning 阶段由 LLM 根据问题 z 进行最后判断。
如果社区与问题 z 之间确实“极远”或几乎无关,Fine-Pruning 里 LLM 会自动给出低分或直接排除。在作者给出的伪代码中,也说明了“未选中的社区就不进入后续链条”。因此只要 LLM 不出现严重的理解错误,这类无关社区往往会被排除,污染度有限。
问题 9
对比“1-d n-w”的 KGP 方法,FastToG 自称“n-w n-d”,但它也还是要限制社区的最大大小 max size,避免太多节点塞进一个社区里。
这与单纯地把所有邻居一锅端有何本质区别?作者为什么坚称它的思路是“community-by-community”,而不只是“把所有 n-hop 邻居打包”?
回答 9
作者在“Community Detection on Subgraph”以及“Modularity-based Coarse-Pruning”里多次强调,核心在于先从结构上划分——不是把所有 n-hop 节点简单打包,而是要依赖图结构本身,找紧密相连的子群落(社区)。
这样做能过滤无关或只松散连接的节点,而不只是机械地采所有 n-hop 节点。
同时,限制 max size 是为了防止社区过大,在多人对话或噪声极多时,仍维持社区紧凑度,让 LLM 更准确地消化相关子图信息。两者有本质区别。
问题 10
若在实际落地中,知识图谱数据经过实时更新、或者遇到多模态(图像、视频)信息,FastToG 这种基于静态 RDF/Neo4j 的方法是否会失效?作者在结论中给出了哪些未来改进方向?
回答 10
作者在论文“Conclusion”与最后的展望部分指出:
- 本文关注静态文本知识图谱,但对于动态、多模态数据,“社区检测 + LLM”思路依然可行;
- 需进一步将语义、句法特征与“社区检测”融合,处理带有图片或音频的图谱;
- 在极大规模图或更频繁变动的场景,作者建议开发分层多级社区或在线更新算法,以减少每次重复划分社区的开销;
- 还提出继续改进 Graph2Text 模块,减少幻觉,提升在多模态知识场景下的准确率。
也就是说方法并未“完全失效”,而是还需要更丰富的功能拓展与适配方案。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 18
18 0
0- 0



 已为社区贡献111条内容
已为社区贡献111条内容

所有评论(0)