
【渗透测试】解决通过PDF文件进行XSS攻击
在日常开发的系统中,难免会遇到文件上传的功能。并非所有上传的文件都是安全的,比如用户上传PDF文件时在文件头中添加一些JS、脚本等恶意代码。通过浏览器浏览这些文件时会执行文件头中携带的脚本,非常的不安全。所以在系统文件上传时需要考虑这一风险点,避免系统遭受XSS攻击;
·
一、问题引入
在日常开发的系统中,难免会遇到文件上传的功能。并非所有上传的文件都是安全的,比如用户上传PDF文件时在文件头中添加一些JS、脚本等恶意代码。通过浏览器浏览这些文件时会执行文件头中携带的脚本,非常的不安全。所以在系统文件上传时需要考虑这一风险点,避免系统遭受XSS攻击;
二、如何让PDF文件携带XSS脚本
1、下载迅捷PDF编辑器
根据如下流程创建携带XSS脚本的PDF文件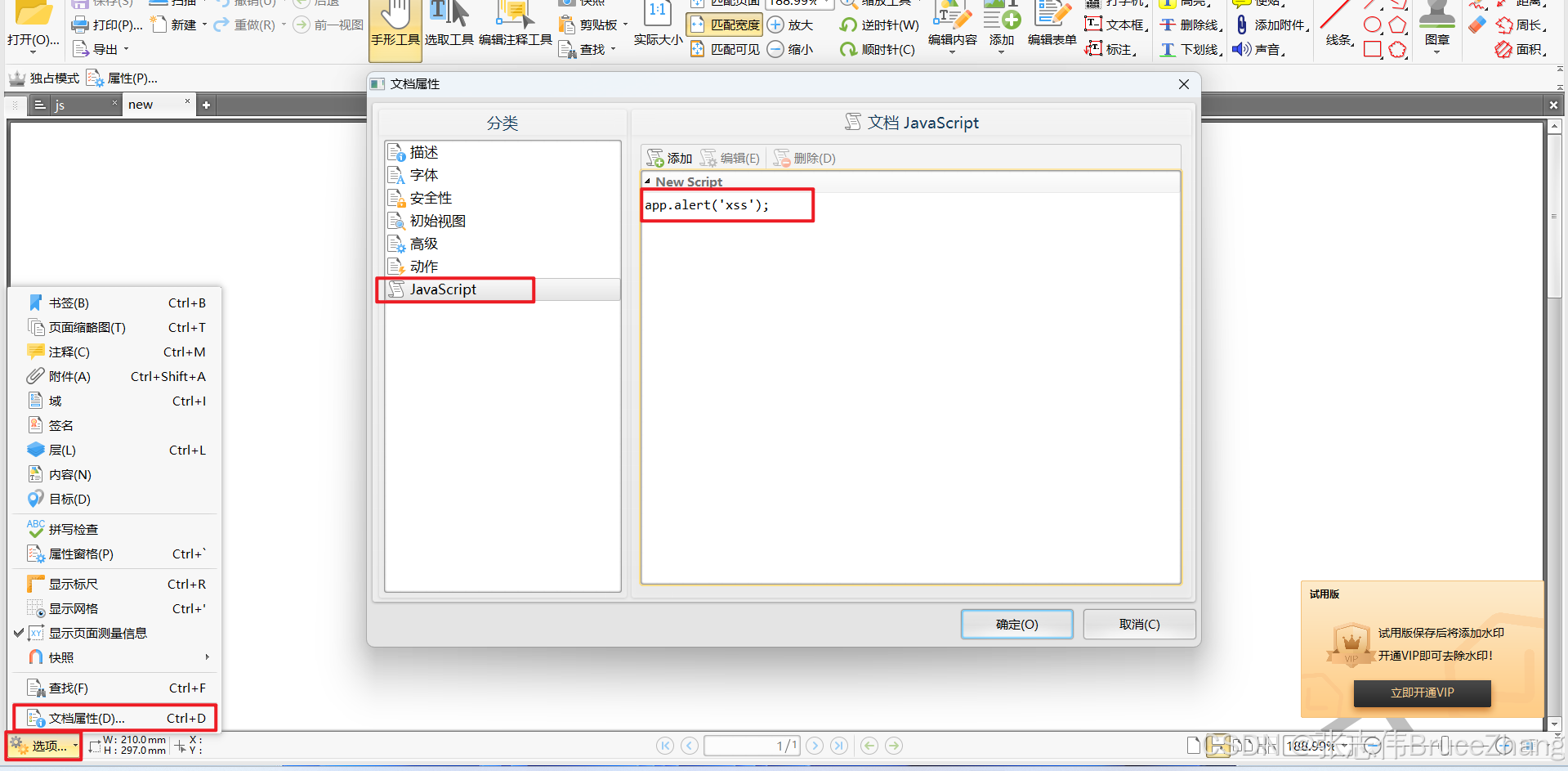
2、效果展示
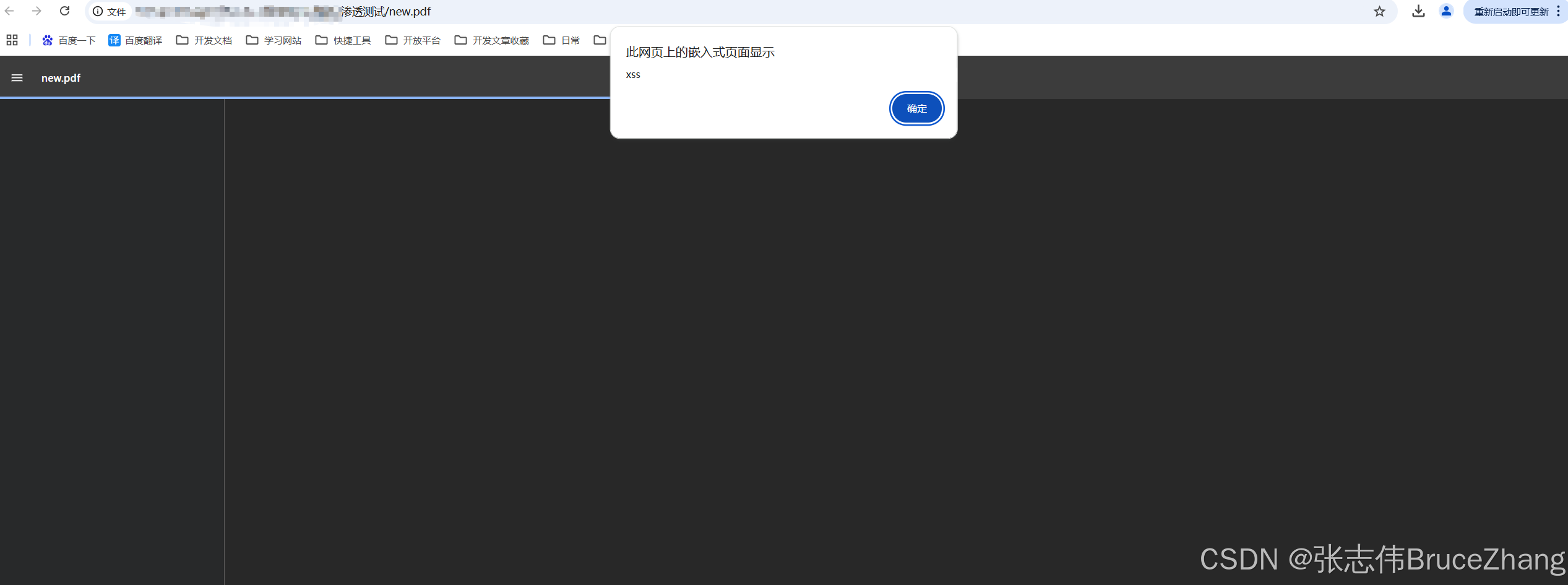
三、如何解决此问题
3.1、通过ClamAV解决
ClamAV是Linux操作系统一款免费的杀毒工具,通过命令执行病毒库升级、查找病毒和删除病毒;
如果系统有专门的文件存储服务,如:Minio推荐使用该方案;需要在Linux服务器中下载ClamAV。然后通过SpringBoot集成calmdAV实现文件上传时病毒检测;
具体操作步骤暂不叙述;
3.2、通过PDFBox解决
在文件上传时判断文件头类型,来判断文件是否是PDF文件。如果是PDF文件检测文件是否携带XSS脚本,存在拒绝上传文件服务器;
具体步骤
3.2.1、引入pom文件
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>3.0.4</version>
</dependency>
3.2.2、编写工具类
/**
* @author Zhang.zhiwei
* @date 2025/4/21 16:53
* @description: PDF文件检测工具类
*/
@Slf4j
public class PDFUtils {
/**
* PDF文件头类型
*/
private static final String PDF_HEADER = "%PDF-";
/**
* 文件头部-文件类型表示字节个数
*/
private static final int HEADER_BYTE_NUMBER = 5;
/**
* 解析PDF是否携带XSS脚本代码
* @param file
* @return
*/
public static boolean analysisPDF(MultipartFile file) {
log.info("PDF解析开始>>>>>>>>");
long start = System.currentTimeMillis();
try {
// 判断是否是pdf文件类型
if (isPDF(file)) {
// 判断文件XSS攻击
boolean haveJavaScript = PDFUtils.containsJavaScript(PDFUtils.multipartFileToFile(file));
if (haveJavaScript) {
return false;
}
}
} catch (IOException e) {
throw new ServiceException(500, "文件解析失败,失败原因:" + e.getMessage());
}
long end = System.currentTimeMillis();
log.info("PDF解析完毕>>>>>>>>耗时:" + (end - start) + "毫秒");
return true;
}
/**
* 根据文件头判断文件是否是PDF类型
* @param file
* @return
*/
public static boolean isPDF(MultipartFile file) {
// 文件非空校验
if (file == null || file.isEmpty()) {
return false;
}
// 读取文件头信息
InputStream inputStream = null;
try {
inputStream = file.getInputStream();
byte[] buffer = new byte[HEADER_BYTE_NUMBER];
if (inputStream.read(buffer) != HEADER_BYTE_NUMBER) {
return false;
}
String header = new String(buffer, 0, HEADER_BYTE_NUMBER);
return PDF_HEADER.equals(header);
} catch (IOException e) {
log.error("【PdfUtils工具类】:根据文件头判断文件是否是PDF方法异常,异常信息为:" + e.getMessage());
return false;
} finally {
try {
if (inputStream != null) {
inputStream.close();
}
} catch (IOException e) {
log.error("解析PDF文件时,关闭流失败!");
}
}
}
/**
* 获取不带扩展名的文件名
* @param filename
* @return
*/
public static String getFileNameNoSuffix(String filename) {
if ((filename != null) && (filename.length() > 0)) {
int dot = filename.lastIndexOf('.');
if ((dot > -1) && (dot < (filename.length()))) {
return filename.substring(0, dot);
}
}
return filename;
}
/**
* 获取文件扩展名
* @param filename
* @return
*/
public static String getSuffixNameName(String filename) {
if ((filename != null) && (filename.length() > 0)) {
int dot = filename.lastIndexOf('.');
if ((dot > -1) && (dot < (filename.length() - 1))) {
return filename.substring(dot + 1);
}
}
return filename;
}
/**
* File转MultipartFile
*
* @param mulFile 文件对象
* @return Multipart文件对象
*/
public static File multipartFileToFile(MultipartFile mulFile) throws IOException {
InputStream ins = mulFile.getInputStream();
String fileName = mulFile.getOriginalFilename();
String prefix = getFileNameNoSuffix(fileName) + UUID.randomUUID().toString();
String suffix = "." + getSuffixNameName(fileName);
File toFile = File.createTempFile(prefix, suffix);
OutputStream os = new FileOutputStream(toFile);
int bytesRead = 0;
byte[] buffer = new byte[8192];
while ((bytesRead = ins.read(buffer, 0, 8192)) != -1) {
os.write(buffer, 0, bytesRead);
}
os.close();
ins.close();
return toFile;
}
/**
* 校验PDF文件是否包含js脚本
*
* @param file
* @return
* @throws IOException
*/
public static boolean containsJavaScript(File file) throws IOException {
// 加载PDF文件
PDDocument pdDocument = Loader.loadPDF(file);
try {
// 获取文件文档目录中JavaScript,不存在直接校验通过
PDDocumentNameDictionary names = pdDocument.getDocumentCatalog().getNames();
if (Objects.isNull(names) || Objects.isNull(names.getJavaScript())) {
return false;
}
// 如果存在JavaScript目录,定义为存在恶意脚本
if (Objects.nonNull(names.getJavaScript())) {
return true;
}
// 兜底方案:全目录搜索JavaScript、JS
String CosName = pdDocument.getDocument().getTrailer().toString();
if (CosName.contains("COSName{JavaScript}") || CosName.contains("COSName{JS}")) {
return true;
}
} catch (Exception e) {
log.error("PDF效验异常:" + e.getMessage());
return true;
} finally {
pdDocument.close();
}
return false;
}
}
3.2.4、效果展示
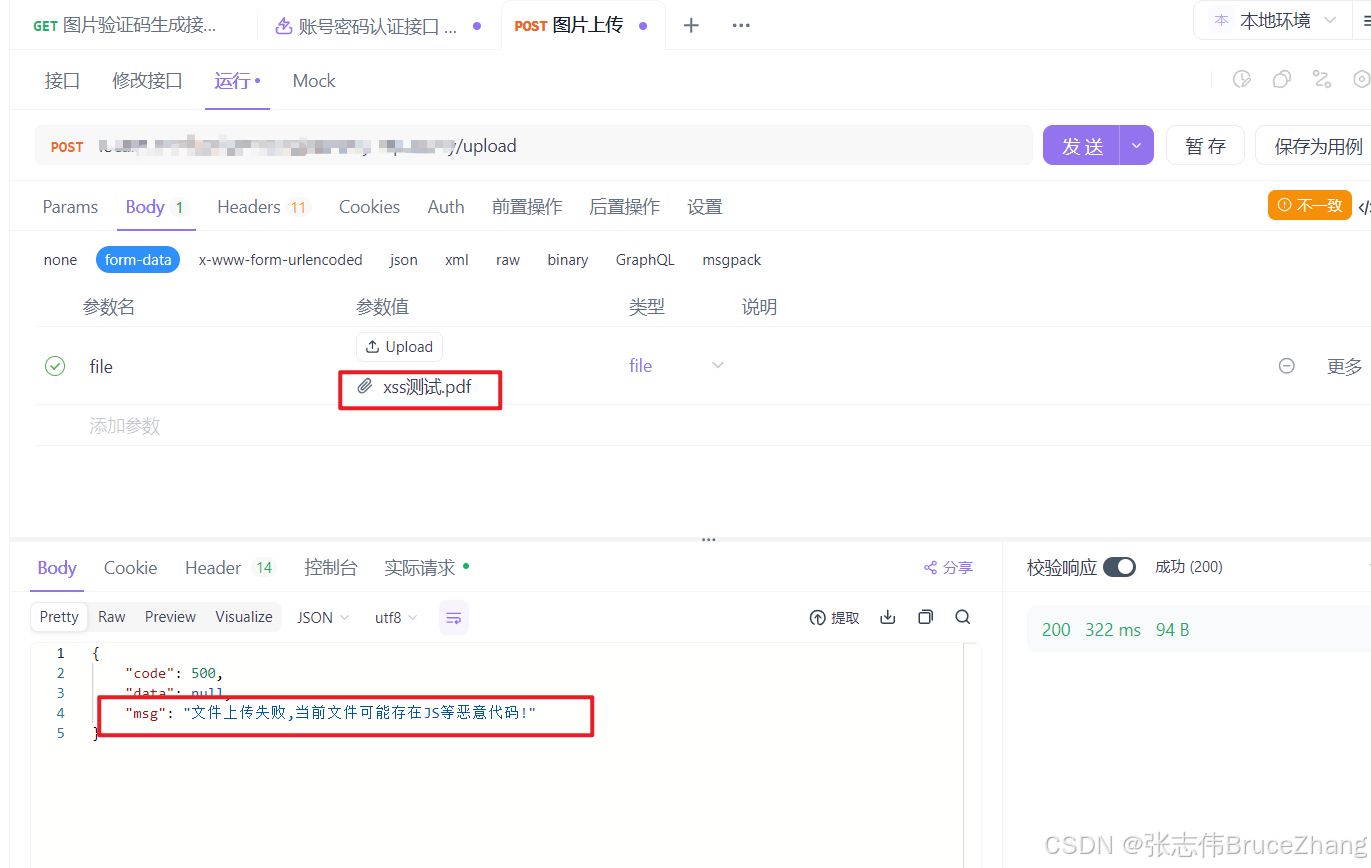

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)