
pysot单目标跟踪算法训练和测试过程中的问题记录及解决
VOT2018测试问题:AssertionError: D:\3.Object tracking\pysot-master\tools\../testing_dataset\VOT2018\ants1/color/00000001.jpg解决方法:将作者给定json文件里面的/color全部替换了,因为我的数据集里面的图片没有放在color文件夹里面AssertionError: D:\3.Obj
pysot单目标跟踪训练算法时,有时不能保存checkpoint_e20的原因:
在对pysot中的算法进行训练时,有时发现设定的epoch=20,但最后保存的权重只有epoch 1-19的,没有checkpoint_e20。自己在SiamCAR的issue中找到了解答:
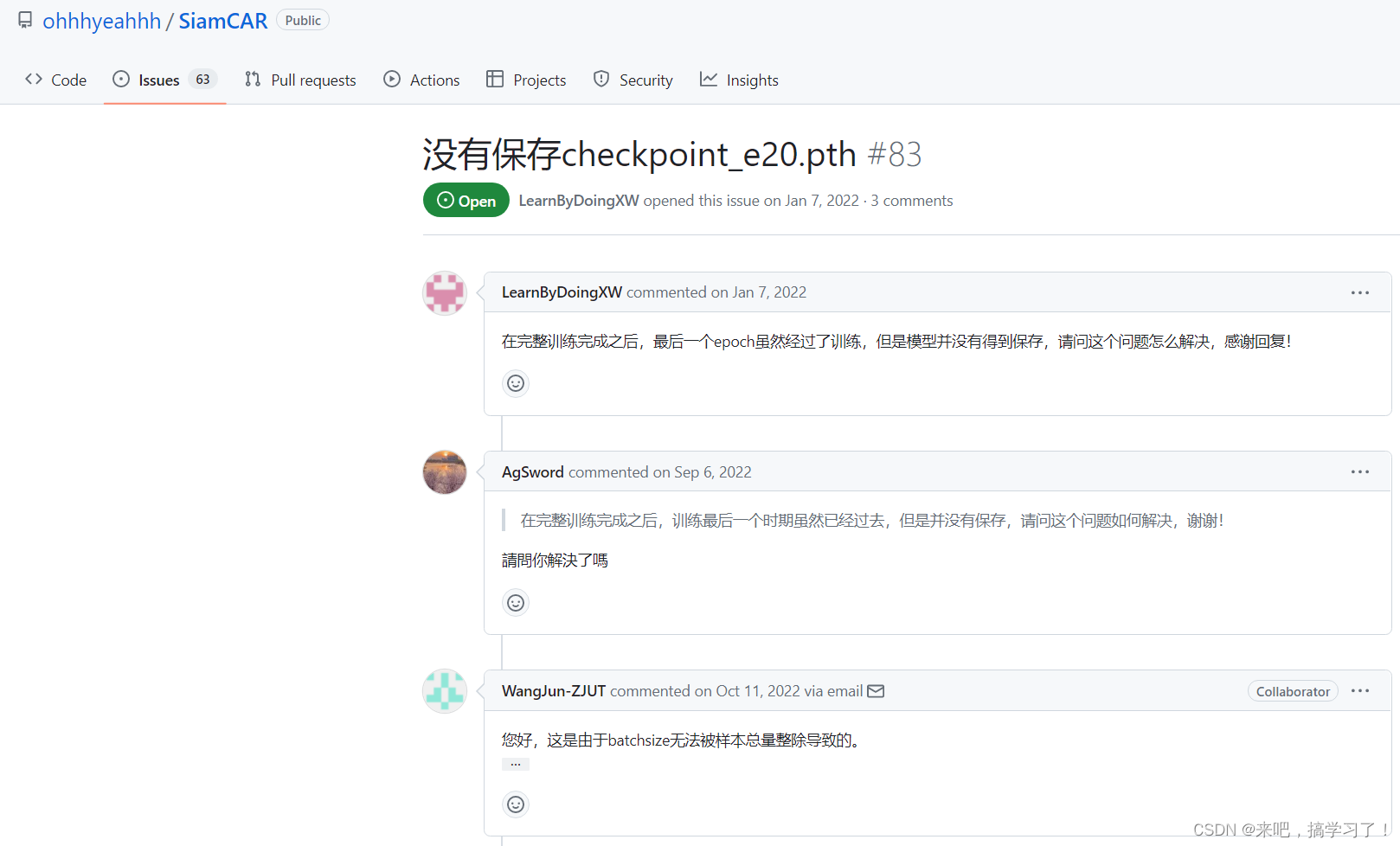
(没有保存checkpoint_e20.pth · Issue #83 · ohhhyeahhh/SiamCAR · GitHub)
具体的问题所在,如下:
我先总结一下,大概的原因在于:当实际的样本总数少于设定的理论总数时,按照理论值训练的每epoch的样本数量>实际的样本数量,所以每次epoch迭代的样本数量多了,epoch不需要20个就能训练完,因此导致少了epoch20的权重!!!
这也是为什么在SiamBAN中的NUM_USE都没有设为 -1 的,避免出现此类问题 !!
1.当设定的训练及数据集参数为:
epoch=20,batch_size=32,__C.DATASET.VIDEOS_PER_EPOCH = 800,000
__C.DATASET.VID.NUM_USE = 100,000,__C.DATASET.YOUTUBEBB.NUM_USE = -1,
__C.DATASET.COCO.NUM_USE = -1,__C.DATASET.DET.NUM_USE = -1
可以计算出dataset.py的:
train_loader 的相关参数:train_loader=500,000, batch_sampler=500,000, dataset=16,000,000
其中:
dataset = VIDEOS_PER_EPOCH * epoch,
batch_sampler = dataset / batch_size =train_loader
再按照train.py中:
num_per_epoch = len(train_loader.dataset) // cfg.TRAIN.EPOCH // (cfg.TRAIN.BATCH_SIZE * world_size),
可得:num_per_epoch=25,000 (单卡训练,双卡再除以2即可,为12500)
ps:关于参数的解释,b站up主有解释:

2.加载数据集
接下来根据上述的参数,基于dataset.py加载数据集
(1)dataset.py中 class TrkDataset(Dataset),加载数据集中的训练样本:
for name in cfg.DATASET.NAMES:
subdata_cfg = getattr(cfg.DATASET, name)
sub_dataset = SubDataset(
name,
subdata_cfg.ROOT,
subdata_cfg.ANNO,
subdata_cfg.FRAME_RANGE,
subdata_cfg.NUM_USE,
start
)
start += sub_dataset.num
self.num += sub_dataset.num_use
就在这里:是按照1.中的数据集参数来加载的:
__C.DATASET.VID.NUM_USE = 100,000,__C.DATASET.YOUTUBEBB.NUM_USE = -1,
__C.DATASET.COCO.NUM_USE = -1,__C.DATASET.DET.NUM_USE = -1
NUM_USE = 100,000表示加载该数据集的100,000个样本,若数量不够则重复加载
NUM_USE = -1 表示加载该数据集的全部样本
因此在这里加载的数据集样本总数为:
100,000(VID)+333,474(DET)+199,267(YT-BB)+117,266(COCO)= 750,007
(2)dataset.py中 class TrkDataset(Dataset),计算训练样本总数:
self.num = videos_per_epoch if videos_per_epoch > 0 else self.num self.num *= cfg.TRAIN.EPOCH # 计算总数的理论值
line 215 中: return pick[:self.num],返回的是理论样本总数
按理说实际训练的样本应该是 750,007 * 20 = 1500,0140,但是在这里计算需要训练的样本总数是按照理论的训练集样本总数 VIDEOS_PER_EPOCH = 800,000 来计算的,得到理论训练样本总数为 800,000 * 20 = 16,000,000 > 1500,0140
所以按照理论值训练的每epoch的样本数量>实际的样本数量,所以每次epoch迭代的样本数量多了,epoch不需要20个就能训练完,因此导致少了epoch20的权重
VOT2018测试问题:
AssertionError: D:\3.Object tracking\pysot-master\tools\../testing_dataset\VOT2018\ants1/color/00000001.jpg
解决方法:将作者给定json文件里面的/color全部替换了,因为我的数据集里面的图片没有放在color文件夹里面
AssertionError: D:\3.Object tracking\pysot-master\tools\../testing_dataset\VOT2018\pedestrian1/00000001.jpg
解决方法:将数据集里面的pedestrian1用报错的名字重命名了一下就好了!可能是数据集的名字多了个空格之类的东西

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)