
GD32使用FPU单元和dsp库测试
mcu使用FPU浮点计算单元和DSP库.
·
一般M4内核的MCU都带了dsp指令和FPU单元,在计算单精度浮点数时,打开fpu单元能加速运行速度。使用gd32f303测试FPU和不使用FPU的运行速度差异。
步骤一:执行10万次float乘法
static void float_run_test(void)
{
float a=1.1;
float b;
uint32_t cnt=100000;
printf("tick start =%d \r\n",getTimeStamp_tick());
while (cnt--)
{
b = b*a;
}
printf("tick stop =%d \r\n",getTimeStamp_tick());
}
不带FPU运行了22 tick。
步骤2:打开FPU
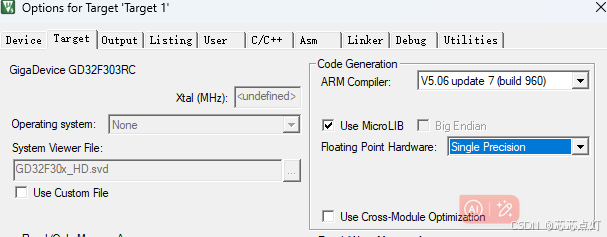
使用debug打断点查看有没有打开FPU,注意,打断点时,优化等级需要设置为0;带VMUL.F32代表的是打开了FPU ,如果没有的话,需要添加,__TARGET_FPU_VFP,ARM_MATH_CM4 宏
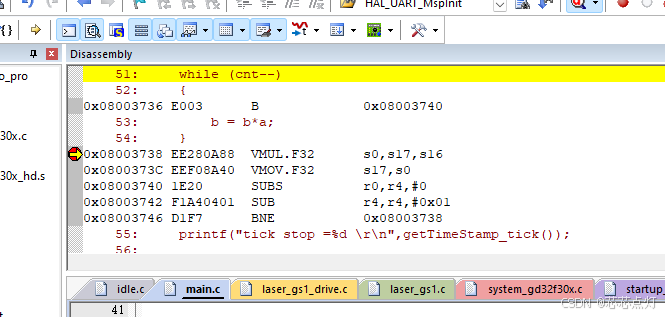

当打开FPU后,同样上面的代码只需要7tick.快了3倍以上,因为还运行了10万次while.
实验二、测试DSP库 的运行速度和标准库的速度。
static void float_run_test(void)
{
float angle = 1.1;
float result ;
uint16_t cnt =1000;
printf("tick start =%d \r\n",getTimeStamp_tick());
while(cnt--)
{
result = (float)sin(angle);
}
printf("tick start =%d \r\n",getTimeStamp_tick());
}实验代码,不带dsp库时,运行了1000次sin()函数用了28 Tick
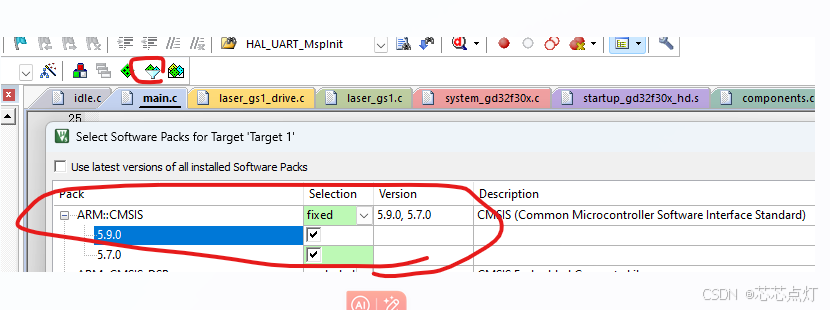
使用内置DSP库,用的CMSIS 5.9.0的dsp库。CMSIS选择版本设置
添加dsp库,这是带源码的
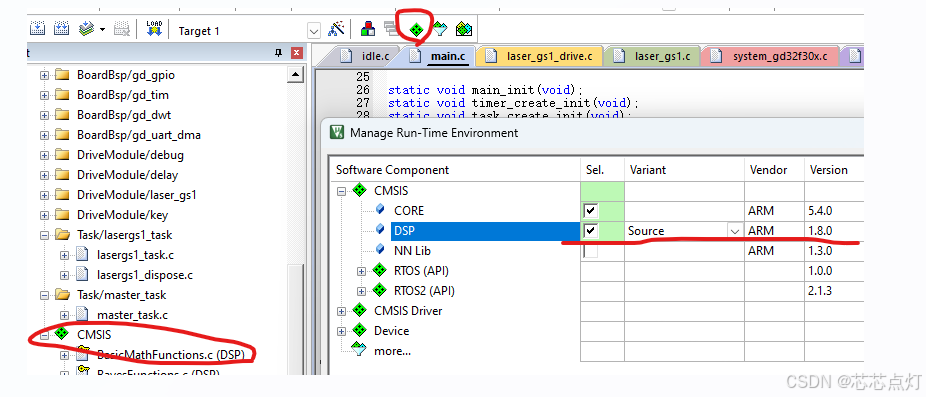
还可以用Lib连接库的
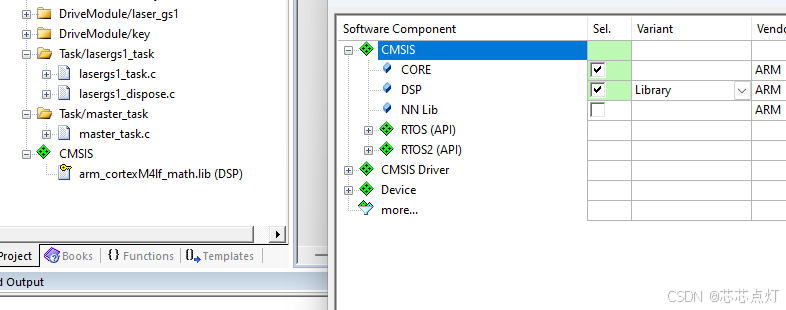
添加代码后就是配置调用函数了。
C/C++宏定义:USE_STDPERIPH_DRIVER, GD32F30X_HD,__TARGET_FPU_VFP,ARM_MATH_CM4,ARM_MATH_MATRIX_CHECK,ARM_MATH_ROUNDING
在需要调用dsp函数中添加头文件#include "arm_math.h"
static void float_run_test(void)
{
float angle = 1.1f;
float result_math ;
float32_t angle_dsp=1.1f;
float32_t result_dsp ;
uint16_t cnt =10000;
uint16_t cnt1 =10000;
printf("tick start =%d \r\n",getTimeStamp_tick());
while(cnt--)
{
result_math = (float)sin(angle);
}
printf("tick stop =%d \r\n",getTimeStamp_tick());
printf("result_math = %.3f",result_math );
printf("tick start =%d \r\n",getTimeStamp_tick());
while(cnt1--)
{
result_dsp = arm_sin_f32(angle_dsp);
}
printf("tick stop =%d \r\n",getTimeStamp_tick());
printf("result_dsp = %.3f",result_dsp );
}测试代码,执行10000次sin函数,math库和dsp对比。

math:366 Tick
dsp:7Tick
忽略while的影响,Dsp确实比C库快很多。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)