
Windows版FFmpeg使用及B站视频下载示例python源码
Windows版FFmpeg下载使用,及B站视频下载示例python源码
Windows版FFmpeg使用及B站视频下载示例python源码
FFmpeg介绍和下载
FFmpeg 是一个功能强大、灵活且广泛使用的多媒体处理工具,无论是在专业领域还是日常使用中,都能满足各种多媒体处理需求。FFmpeg 是一个开源项目,遵循 LGPL 或 GPL 许可。这意味着你可以免费使用、修改和分发它。组成:
ffmpeg:这是 FFmpeg 的核心工具,用于处理多媒体文件的转换、录制、播放等操作。
ffplay:一个简单的多媒体播放器,用于播放视频和音频文件。
ffprobe:用于分析多媒体文件的元数据,例如文件格式、编码信息、时长等。
FFmpeg 支持几乎所有常见的视频和音频格式,如 MP4、AVI、MKV、MOV、WAV、MP3、FLV 等。它还支持多种编解码器,如 H.264、H.265、AAC、MP3 等。
使用方式
FFmpeg 是一个命令行工具,可以通过命令行参数来执行各种操作。例如:
转换格式:ffmpeg -i input.mp4 -c:v libx264 output.avi
提取音频:ffmpeg -i video.mp4 -q:a 0 -map a audio.mp3
常用参数
输入输出相关
-i <input>:指定输入文件。
-f <format>:强制指定输入或输出文件格式。
-y:自动覆盖输出文件。
-n:禁止覆盖输出文件。
编码器和解码器
-c:v <codec>:指定视频编解码器。
-c:a <codec>:指定音频编解码器。
-c copy:直接拷贝流,不进行重新编码。
更多情况可见https://ffmpeg.org/ffmpeg.html#Trancoding
也可以通过编程接口(如Python、C/C++)调用其功能,方便集成到其他软件中。
Windows版本的FFmpeg下载
打开 FFmpeg 官网https://ffmpeg.org/,选择Download(下载)。

选择左边的 release builds(发布版本)
可以选择下载上面红色圈中的 release-full 版本,

选择带 shared 的还是不带 shared 的版本,其实都是可以的。
下载后,解压使用。解压进入 bin 目录
带 shared 的里面,多了 include、lib 目录。把 FFmpeg 依赖的模块包单独的放在的 lib 目录中。ffmpeg.exe,ffplay.exe,ffprobe.exe 作为可执行文件的入口,文件体积很小,他们在运行的时候,如果需要,会到 lib 中调用相应的功能。
不带 shared 的里面,bin 目录中有 ffmpeg.exe,ffplay.exe,ffprobe.exe 三个可执行文件,每个 exe 的体积都稍大一点,因为它已经把相关的需要用的模块包编译到exe里面去了。不带 shared 的版本,单文件可以方便使用。
python代码bilibili(B站)下载示例源码
下面给出bilibili(B站)上西游记精彩花絮
https://www.bilibili.com/video/BV1gX4y1P7Va/?spm_id_from=333.788.recommend_more_video.10
使用python及第三方模块requests实现
先介绍代码中使用的模块
requests模块。这个模块是用来发送HTTP请求的,比如GET、POST等,非常常用。方便与 Web API 进行交互。requests是第三方库,不是Python的标准库,需要额外安装,通常用pip install requests来安装。所以这个需要用户自己安装。
json模块。这个模块用于处理JSON数据,比如解析和生成JSON。例如将 Python 字典转换为 JSON 字符串,或将 JSON 字符串解析为 Python 对象。json是Python的内置库,从Python 2.6开始就存在了,所以不需要安装。
pprint模块,全称是Pretty Print,用于美化输出数据结构,比如字典和列表,使其更易读。这个也是Python的标准库,属于内置模块,不需要安装。
re模块,正则表达式模块,支持字符串匹配、搜索、替换等操作,常用于文本处理和模式匹配。。同样,这是Python内置的,无需安装。
os模块,提供了与操作系统交互的功能,比如文件和目录操作、环境变量等。是内置的,不需要额外安装。
subprocess模块,用于运行外部命令或程序。允许生成新的进程,连接输入/输出/错误管道,并获取返回码。是Python标准库的一部分,不需要安装。
sys模块,提供对Python解释器相关的操作,比如访问命令行参数、退出程序、获取模块路径等。属于内置模块,无需安装。
urllib.parse.urlparse。urllib.parse是用于处理URL的模块,urlparse是其中的一个函数,用来解析URL。urllib是Python的标准库,所以不需要安装。在Python 3中,urllib被分成了几个子模块,比如urllib.request、urllib.parse等。
代码逻辑如下:
发送HTTP请求获取网页内容。
从网页内容中解析出视频和音频的URL。
下载视频和音频文件。
使用FFmpeg工具合并视频和音频文件。
注意,该代码通用性极低,不能下载B站所有视频,仅能下载B站未加密、无分片(如.m3u8索引文件)、非会员/付费的公开视频。
源码如下:
import requests
import json
import pprint
import re
import os
import subprocess
import sys
from urllib.parse import urlparse
# 全局常量定义
SAVE_DIR = r'D:\bilibili' #视频存放路径设置
FFMPEG_PATH = r'D:\ffmpeg-7.1-full_build\bin\ffmpeg.exe' # 修改为实际路径
ILLEGAL_CHARS = r'[<>:"/\\|?*\x00-\x1F]'
def clean_filename(filename):
"""清理文件名中的非法字符"""
return re.sub(ILLEGAL_CHARS, '_', filename).strip()
def getResponse(url):
"""获取url响应体(带重试机制)"""
# 设置请求头以模拟浏览器访问
headers = {
'referer': 'https://www.bilibili.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'
}
try:
response = requests.get(url=url, headers=headers, timeout=20)
response.raise_for_status()
return response
except RequestException as e:
raise RuntimeError(f"网络请求失败: {str(e)}") from e
def parseResponse(url):
"""解析响应体"""
try:
# 验证域名
if 'bilibili.com' not in urlparse(url).netloc:
raise ValueError("非B站视频链接")
response = getResponse(url)
# 提取视频信息
html_data_match = re.search(r'<script>window\.__playinfo__=(.*?)</script>', response.text)
if not html_data_match:
raise ValueError("未找到视频数据")
try:
jsonData = json.loads(html_data_match.group(1))
except json.JSONDecodeError as e:
raise ValueError("视频数据解析失败") from e
# 提取标题
title_match = re.search(r'<title data-vue-meta="true">(.*?)</title>', response.text)
if not title_match:
raise ValueError("未找到视频标题")
videoTitle = clean_filename(title_match.group(0).split('>')[1].split('<')[0])
# 验证媒体流数据
try:
audioUrl = jsonData['data']['dash']['audio'][0]['baseUrl']
videoUrl = jsonData['data']['dash']['video'][0]['baseUrl']
except (KeyError, IndexError) as e:
raise ValueError("视频流信息不完整") from e
return {
'videoTitle': videoTitle,
'audioUrl': audioUrl,
'videoUrl': videoUrl,
}
except Exception as e:
raise RuntimeError(f"解析响应失败: {str(e)}") from e
def saveMedia(fileName, content, mediaType):
"""保存媒体文件"""
try:
os.makedirs(SAVE_DIR, exist_ok=True)
safe_name = f"{clean_filename(fileName)}.{mediaType}"
full_path = os.path.join(SAVE_DIR, safe_name)
with open(full_path, 'wb') as f:
f.write(content)
print(f"[√] {mediaType.upper()}保存成功: {safe_name}")
return full_path
except (IOError, OSError) as e:
raise RuntimeError(f"文件保存失败: {str(e)}") from e
def AvMerge(Mp3Path, Mp4Path, savePath):
"""合并音视频"""
try:
if not os.path.isfile(FFMPEG_PATH):
raise FileNotFoundError("FFmpeg路径不存在")
print("[!] 开始合并音视频...")
cmd = [
FFMPEG_PATH,
'-y', # 覆盖输出文件
'-i', Mp4Path,
'-i', Mp3Path,
'-c:v', 'copy',
'-c:a', 'aac',
'-strict', 'experimental',
savePath
]
try:
subprocess.run(
cmd,
check=True,
stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL
)
except subprocess.CalledProcessError as e:
raise RuntimeError(f"合并失败(错误码 {e.returncode})") from e
print(f"[√] 合并完成: {os.path.basename(savePath)}")
# 清理临时文件
for path in [Mp3Path, Mp4Path]:
try:
if os.path.exists(path):
os.remove(path)
print(f"[!] 已清理临时文件: {os.path.basename(path)}")
except Exception as e:
print(f"[!] 清理文件失败: {str(e)}")
except Exception as e:
raise RuntimeError(f"合并过程出错: {str(e)}") from e
def main():
try:
url = input("请输入B站视频url地址: ").strip()
if not url.startswith(('http://', 'https://')):
raise ValueError("请输入有效的URL地址")
videoInfo = parseResponse(url)
base_name = videoInfo['videoTitle']
# 下载音频
audio_content = getResponse(videoInfo['audioUrl']).content
mp3_path = saveMedia(base_name, audio_content, 'mp3')
# 下载视频
video_content = getResponse(videoInfo['videoUrl']).content
mp4_path = saveMedia(base_name, video_content, 'mp4')
# 合并文件
merged_path = os.path.join(SAVE_DIR, f'merged_{base_name}.mp4')
AvMerge(mp3_path, mp4_path, merged_path)
print(f"[√] 全部操作已完成!保存路径: {merged_path}")
except Exception as e:
print(f"[X] 程序运行出错: {str(e)}")
sys.exit(1)
if __name__ == '__main__':
main()
说明:
其中,代码行:FFMPEG_PATH = r"D:\ffmpeg-7.1-full_build\bin\ffmpeg.exe" # 修改为你的实际路径
若使用不带 shared 的版本,可将bin 目录中的 ffmpeg.exe文件,直接拷贝到这个程序的文件夹中,可将其改为:FFMPEG_PATH = r".\ffmpeg.exe" # 修改为你的实际路径
GUI界面美化改进版(优化)
下面使用Tkinter创建的GUI界面。运行截图:
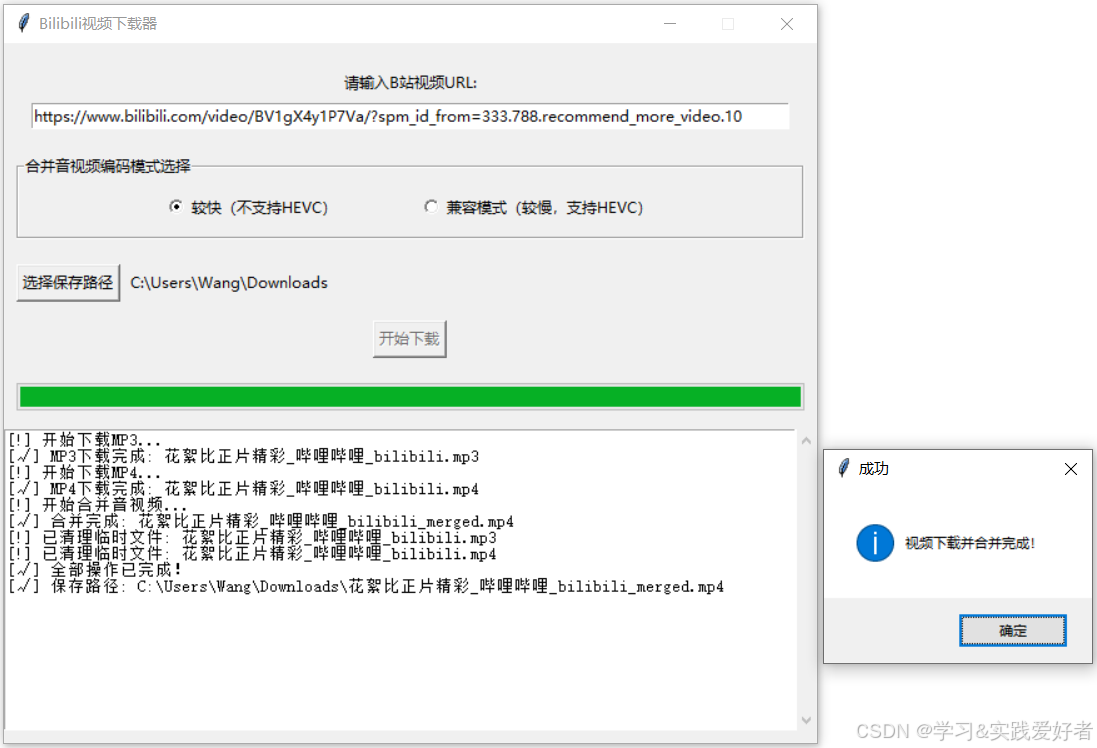
源码如下
import tkinter as tk
from tkinter import messagebox, filedialog, ttk
import requests
import json
import re
import os
import subprocess
import sys
import threading
import random
import time
from urllib.parse import urlparse
class BilibiliDownloader:
def __init__(self, master):
self.master = master
master.title("Bilibili视频下载器")
master.geometry("650x560")
master.resizable(False, False)
# 常量定义
self.FFMPEG_PATH = r'.\ffmpeg.exe'
self.ILLEGAL_CHARS = r'[<>:"/\\|?*\x00-\x1F]'
# 请求头
self.headers = {
'referer': 'https://www.bilibili.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
}
# 创建UI组件
self.create_widgets()
def create_widgets(self):
# 顶部Frame
top_frame = tk.Frame(self.master)
top_frame.pack(fill=tk.X, padx=10, pady=(20,5))
# URL输入区域
tk.Label(top_frame, text="请输入B站视频URL:").pack()
self.url_entry = tk.Entry(top_frame, width=86)
self.url_entry.pack(pady=5)
# 添加合并音视频编码模式选择
encode_frame = tk.LabelFrame(self.master, text="合并音视频编码模式选择", padx=10, pady=5)
encode_frame.pack(pady=10, fill='x', padx=10)
# 创建一个Frame来容纳单选按钮
radio_frame = tk.Frame(encode_frame)
radio_frame.pack(pady=5)
self.encode_mode = tk.StringVar(value="fast")
tk.Radiobutton(radio_frame, text="较快(不支持HEVC)", variable=self.encode_mode,
value="fast").pack(side='left', padx=30)
tk.Radiobutton(radio_frame, text="兼容模式(较慢,支持HEVC)", variable=self.encode_mode,
value="compatible").pack(side='left', padx=30)
# 中部Frame
mid_frame = tk.Frame(self.master)
mid_frame.pack(fill=tk.X, padx=10, pady=5)
# 选择保存路径按钮
path_frame = tk.Frame(mid_frame)
path_frame.pack(fill=tk.X, pady=5)
tk.Button(path_frame, text="选择保存路径", command=self.choose_save_directory).pack(side=tk.LEFT)
self.save_path_var = tk.StringVar(value=os.path.join(os.path.expanduser("~"), "Downloads"))
tk.Label(path_frame, textvariable=self.save_path_var).pack(side=tk.LEFT, padx=5)
# 下载按钮
self.download_btn = tk.Button(mid_frame, text="开始下载", command=self.start_download)
self.download_btn.pack(pady=10)
# 进度条
self.progress_var = tk.DoubleVar()
self.progress_bar = ttk.Progressbar(
self.master,
variable=self.progress_var,
maximum=100,
mode='determinate'
)
self.progress_bar.pack(fill=tk.X, padx=10, pady=5)
# 创建一个Frame来容纳文本框和滚动条
text_frame = tk.Frame(self.master)
text_frame.pack(pady=10, fill=tk.BOTH, expand=True)
# 先创建滚动条
scrollbar = tk.Scrollbar(text_frame)
scrollbar.pack(side=tk.RIGHT, fill=tk.Y)
# 创建文本框并设置滚动条
self.status_text = tk.Text(text_frame, height=12, width=60)
self.status_text.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
# 将文本框和滚动条关联
self.status_text.config(yscrollcommand=scrollbar.set)
scrollbar.config(command=self.status_text.yview)
def choose_save_directory(self):
directory = filedialog.askdirectory()
if directory:
self.save_path_var.set(directory)
def log_message(self, message):
self.status_text.insert(tk.END, message + "\n")
self.status_text.see(tk.END)
self.master.update_idletasks()
def clean_filename(self, filename):
"""清理文件名中的非法字符"""
return re.sub(self.ILLEGAL_CHARS, '_', filename).strip()
def random_delay(self):
"""随机延时,避免反爬"""
time.sleep(random.uniform(0.5, 2))
def getResponse(self, url):
"""获取url响应体(带重试机制)"""
max_retries = 3
for i in range(max_retries):
try:
self.random_delay() # 随机延时
response = requests.get(url=url, headers=self.headers, timeout=20)
if response.status_code == 403:
raise RuntimeError("访问被拒绝,请稍后重试")
response.raise_for_status()
return response
except requests.Timeout:
if i == max_retries - 1:
raise RuntimeError("请求超时,请检查网络连接")
except requests.RequestException as e:
if i == max_retries - 1:
raise RuntimeError(f"网络请求失败: {str(e)}")
self.log_message(f"[!] 第{i+1}次重试...")
raise RuntimeError("连接失败")
def download_with_progress(self, url, desc="下载中"):
"""带进度条的下载"""
response = requests.get(url, headers=self.headers, stream=True)
total = int(response.headers.get('content-length', 0))
block_size = 1024 # 1 KB
downloaded = 0
content = bytearray()
for data in response.iter_content(block_size):
downloaded += len(data)
content.extend(data)
if total:
progress = (downloaded / total) * 100
self.progress_var.set(progress)
self.master.update_idletasks()
return bytes(content)
def parseResponse(self, url):
"""解析响应体"""
try:
if 'bilibili.com' not in urlparse(url).netloc:
raise ValueError("非B站视频链接")
response = self.getResponse(url)
html_data_match = re.search(r'<script>window\.__playinfo__=(.*?)</script>', response.text)
if not html_data_match:
raise ValueError("未找到视频数据")
try:
jsonData = json.loads(html_data_match.group(1))
except json.JSONDecodeError:
raise ValueError("视频数据解析失败")
title_match = re.search(r'<title data-vue-meta="true">(.*?)</title>', response.text)
if not title_match:
raise ValueError("未找到视频标题")
videoTitle = self.clean_filename(title_match.group(1))
try:
audioUrl = jsonData['data']['dash']['audio'][0]['baseUrl']
videoUrl = jsonData['data']['dash']['video'][0]['baseUrl']
except (KeyError, IndexError):
raise ValueError("视频流信息不完整")
return {
'videoTitle': videoTitle,
'audioUrl': audioUrl,
'videoUrl': videoUrl,
}
except Exception as e:
raise RuntimeError(f"解析响应失败: {str(e)}")
def saveMedia(self, fileName, url, mediaType):
"""保存媒体文件"""
try:
save_dir = self.save_path_var.get()
os.makedirs(save_dir, exist_ok=True)
safe_name = f"{self.clean_filename(fileName)}.{mediaType}"
full_path = os.path.join(save_dir, safe_name)
self.log_message(f"[!] 开始下载{mediaType.upper()}...")
content = self.download_with_progress(url, f"下载{mediaType}")
with open(full_path, 'wb') as f:
f.write(content)
self.log_message(f"[√] {mediaType.upper()}下载完成: {safe_name}")
return full_path
except Exception as e:
raise RuntimeError(f"文件保存失败: {str(e)}")
def AvMerge(self, Mp3Path, Mp4Path, savePath):
"""合并音视频"""
try:
if not os.path.isfile(self.FFMPEG_PATH):
raise FileNotFoundError("FFmpeg路径不存在")
self.log_message("[!] 开始合并音视频...")
# 合并开始时设置进度条为10%
self.progress_var.set(10)
self.master.update_idletasks()
# 修改输出文件路径,添加 "_merged" 后缀
output_dir = os.path.dirname(savePath)
filename = os.path.basename(savePath)
name, ext = os.path.splitext(filename)
merged_path = os.path.join(output_dir, f"{name}_merged{ext}")
# 设置startupinfo以隐藏控制台窗口
startupinfo = None
if sys.platform == 'win32':
startupinfo = subprocess.STARTUPINFO()
startupinfo.dwFlags |= subprocess.STARTF_USESHOWWINDOW
startupinfo.wShowWindow = subprocess.SW_HIDE
if self.encode_mode.get() == "fast":
cmd = [
self.FFMPEG_PATH,
'-y',
'-i', Mp4Path,
'-i', Mp3Path,
'-c:v', 'copy', # copy模式,加快处理速度,但不支持HEVC视频扩展
'-c:a', 'aac',
'-strict', 'experimental',
merged_path
]
else:
cmd = [
self.FFMPEG_PATH,
'-y',
'-i', Mp4Path,
'-i', Mp3Path,
'-c:v', 'libx264', # 使用libx264编码器,支持编码器——HEVC视频扩展,但速度慢
'-preset', 'medium',
'-crf', '28', # 控制视频质量,范围0-51,数值越小质量越好
'-c:a', 'aac',
'-strict', 'experimental',
merged_path
]
subprocess.run(
cmd,
check=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
startupinfo=startupinfo
)
# 合并完成后,将进度条设置为100%
self.progress_var.set(100)
self.master.update_idletasks()
self.log_message(f"[√] 合并完成: {os.path.basename(merged_path)}")
# 清理临时文件
for path in [Mp3Path, Mp4Path]:
try:
if os.path.exists(path):
os.remove(path)
self.log_message(f"[!] 已清理临时文件: {os.path.basename(path)}")
except Exception as e:
self.log_message(f"[!] 清理文件失败: {str(e)}")
return merged_path
except Exception as e:
# 如果出错,重置进度条
self.progress_var.set(0)
self.master.update_idletasks()
raise RuntimeError(f"合并过程出错: {str(e)}")
def _download_task(self):
"""下载任务的具体实现"""
try:
url = self.url_entry.get().strip()
if not url:
raise ValueError("请输入视频URL")
if not url.startswith(('http://', 'https://')):
raise ValueError("请输入有效的URL地址")
# 禁用下载按钮
self.download_btn.config(state='disabled')
# 解析视频信息
videoInfo = self.parseResponse(url)
base_name = videoInfo['videoTitle']
# 下载音频和视频(每次下载前重置进度条)
self.progress_var.set(0)
mp3_path = self.saveMedia(base_name, videoInfo['audioUrl'], 'mp3')
self.progress_var.set(0)
mp4_path = self.saveMedia(base_name, videoInfo['videoUrl'], 'mp4')
# 合并文件
output_path = os.path.join(self.save_path_var.get(), f'{base_name}.mp4')
final_path = self.AvMerge(mp3_path, mp4_path, output_path)
self.log_message(f"[√] 全部操作已完成!\n[√] 保存路径: {final_path}")
messagebox.showinfo("成功", "视频下载并合并完成!")
except Exception as e:
self.log_message(f"[X] 错误: {str(e)}")
messagebox.showerror("错误", str(e))
finally:
# 重置进度条
self.progress_var.set(0)
# 重新启用下载按钮
self.download_btn.config(state='normal')
def start_download(self):
"""在新线程中启动下载任务"""
download_thread = threading.Thread(target=self._download_task)
download_thread.daemon = True
download_thread.start()
def main():
root = tk.Tk()
app = BilibiliDownloader(root)
root.mainloop()
if __name__ == '__main__':
main()
GUI界面早期版本
效果图:
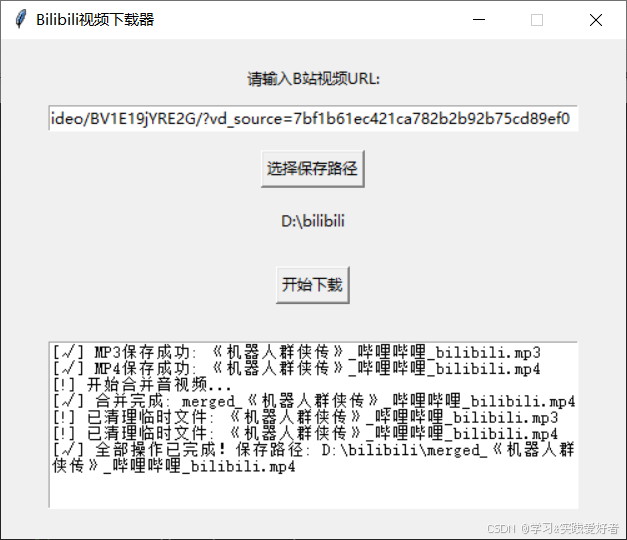
使用说明:
运行程序后,在URL输入框粘贴B站视频链接
可以单击“选择保存路径”自定义下载目录
单击“开始下载”即可下载并合并视频,状态文本框实时显示下载和处理进度
注意:
确保已安装requests库
需要和上例一样注意修改FFMPEG_PATH为您本地的FFmpeg路径
以下是改进后的代码:
import tkinter as tk
from tkinter import messagebox, filedialog
import requests
import json
import re
import os
import subprocess
import sys
from urllib.parse import urlparse
class BilibiliDownloader:
def __init__(self, master):
self.master = master
master.title("Bilibili视频下载器")
master.geometry("500x400")
master.resizable(False, False)
# 常量定义
self.FFMPEG_PATH = r'D:\ffmpeg-7.1-full_build\bin\ffmpeg.exe'
self.ILLEGAL_CHARS = r'[<>:"/\\|?*\x00-\x1F]'
# 创建UI组件
self.create_widgets()
def create_widgets(self):
# URL输入区域
tk.Label(self.master, text="请输入B站视频URL:").pack(pady=(20, 5))
self.url_entry = tk.Entry(self.master, width=60)
self.url_entry.pack(pady=5)
# 选择保存路径按钮
tk.Button(self.master, text="选择保存路径", command=self.choose_save_directory).pack(pady=10)
self.save_path_var = tk.StringVar(value=r'D:\bilibili')
self.save_path_label = tk.Label(self.master, textvariable=self.save_path_var)
self.save_path_label.pack(pady=5)
# 下载按钮
tk.Button(self.master, text="开始下载", command=self.start_download).pack(pady=20)
# 进度文本
self.status_text = tk.Text(self.master, height=10, width=60, state='disabled')
self.status_text.pack(pady=10)
def choose_save_directory(self):
directory = filedialog.askdirectory()
if directory:
self.save_path_var.set(directory)
def log_message(self, message):
self.status_text.configure(state='normal')
self.status_text.insert(tk.END, message + "\n")
self.status_text.configure(state='disabled')
self.status_text.see(tk.END)
self.master.update_idletasks()
def clean_filename(self, filename):
"""清理文件名中的非法字符"""
return re.sub(self.ILLEGAL_CHARS, '_', filename).strip()
def getResponse(self, url):
"""获取url响应体(带重试机制)"""
headers = {
'referer': 'https://www.bilibili.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'
}
try:
response = requests.get(url=url, headers=headers, timeout=20)
response.raise_for_status()
return response
except requests.RequestException as e:
raise RuntimeError(f"网络请求失败: {str(e)}")
def parseResponse(self, url):
"""解析响应体"""
try:
if 'bilibili.com' not in urlparse(url).netloc:
raise ValueError("非B站视频链接")
response = self.getResponse(url)
html_data_match = re.search(r'<script>window\.__playinfo__=(.*?)</script>', response.text)
if not html_data_match:
raise ValueError("未找到视频数据")
try:
jsonData = json.loads(html_data_match.group(1))
except json.JSONDecodeError as e:
raise ValueError("视频数据解析失败")
title_match = re.search(r'<title data-vue-meta="true">(.*?)</title>', response.text)
if not title_match:
raise ValueError("未找到视频标题")
videoTitle = self.clean_filename(title_match.group(0).split('>')[1].split('<')[0])
try:
audioUrl = jsonData['data']['dash']['audio'][0]['baseUrl']
videoUrl = jsonData['data']['dash']['video'][0]['baseUrl']
except (KeyError, IndexError) as e:
raise ValueError("视频流信息不完整")
return {
'videoTitle': videoTitle,
'audioUrl': audioUrl,
'videoUrl': videoUrl,
}
except Exception as e:
raise RuntimeError(f"解析响应失败: {str(e)}")
def saveMedia(self, fileName, content, mediaType):
"""保存媒体文件"""
try:
save_dir = self.save_path_var.get()
os.makedirs(save_dir, exist_ok=True)
safe_name = f"{self.clean_filename(fileName)}.{mediaType}"
full_path = os.path.join(save_dir, safe_name)
with open(full_path, 'wb') as f:
f.write(content)
self.log_message(f"[√] {mediaType.upper()}保存成功: {safe_name}")
return full_path
except (IOError, OSError) as e:
raise RuntimeError(f"文件保存失败: {str(e)}")
def AvMerge(self, Mp3Path, Mp4Path, savePath):
"""合并音视频"""
try:
if not os.path.isfile(self.FFMPEG_PATH):
raise FileNotFoundError("FFmpeg路径不存在")
self.log_message("[!] 开始合并音视频...")
cmd = [
self.FFMPEG_PATH,
'-y', # 覆盖输出文件
'-i', Mp4Path,
'-i', Mp3Path,
'-c:v', 'copy',
'-c:a', 'aac',
'-strict', 'experimental',
savePath
]
try:
subprocess.run(
cmd,
check=True,
stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL
)
except subprocess.CalledProcessError as e:
raise RuntimeError(f"合并失败(错误码 {e.returncode})")
self.log_message(f"[√] 合并完成: {os.path.basename(savePath)}")
# 清理临时文件
for path in [Mp3Path, Mp4Path]:
try:
if os.path.exists(path):
os.remove(path)
self.log_message(f"[!] 已清理临时文件: {os.path.basename(path)}")
except Exception as e:
self.log_message(f"[!] 清理文件失败: {str(e)}")
except Exception as e:
raise RuntimeError(f"合并过程出错: {str(e)}")
def start_download(self):
# 清空之前的状态
self.status_text.configure(state='normal')
self.status_text.delete('1.0', tk.END)
self.status_text.configure(state='disabled')
url = self.url_entry.get().strip()
if not url:
messagebox.showerror("错误", "请输入视频URL")
return
try:
if not url.startswith(('http://', 'https://')):
raise ValueError("请输入有效的URL地址")
videoInfo = self.parseResponse(url)
base_name = videoInfo['videoTitle']
# 下载音频
audio_content = self.getResponse(videoInfo['audioUrl']).content
mp3_path = self.saveMedia(base_name, audio_content, 'mp3')
# 下载视频
video_content = self.getResponse(videoInfo['videoUrl']).content
mp4_path = self.saveMedia(base_name, video_content, 'mp4')
# 合并文件
merged_path = os.path.join(self.save_path_var.get(), f'merged_{base_name}.mp4')
self.AvMerge(mp3_path, mp4_path, merged_path)
self.log_message(f"[√] 全部操作已完成!保存路径: {merged_path}")
messagebox.showinfo("成功", "视频下载并合并完成!")
except Exception as e:
self.log_message(f"[X] 程序运行出错: {str(e)}")
messagebox.showerror("错误", str(e))
def main():
root = tk.Tk()
app = BilibiliDownloader(root)
root.mainloop()
if __name__ == '__main__':
main()
附、Python网络爬虫入门 https://blog.csdn.net/cnds123/article/details/121868887
OK!

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 23
23 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)