
OCRmyPDF:让PDF文件轻松支持文字搜索与复制的神器
介绍一个强大的开源工具——OCRmyPDF,它可以为扫描版PDF添加OCR文本层,让文档变得可搜索、可复制,提升阅读和研究效率。
前言
相信大家都遇到过这样的情况:下载了一份扫描版的PDF文档,但是无法进行文字搜索和复制,阅读体验非常不好。特别是对于一些学习资料、研究论文或者电子书,如果不能搜索和复制,使用起来就非常不便。今天我要向大家介绍一个强大的开源工具——OCRmyPDF,它可以为扫描版PDF添加OCR文本层,让文档变得可搜索、可复制,提升阅读和研究效率。希望大家享用愉快!
目录
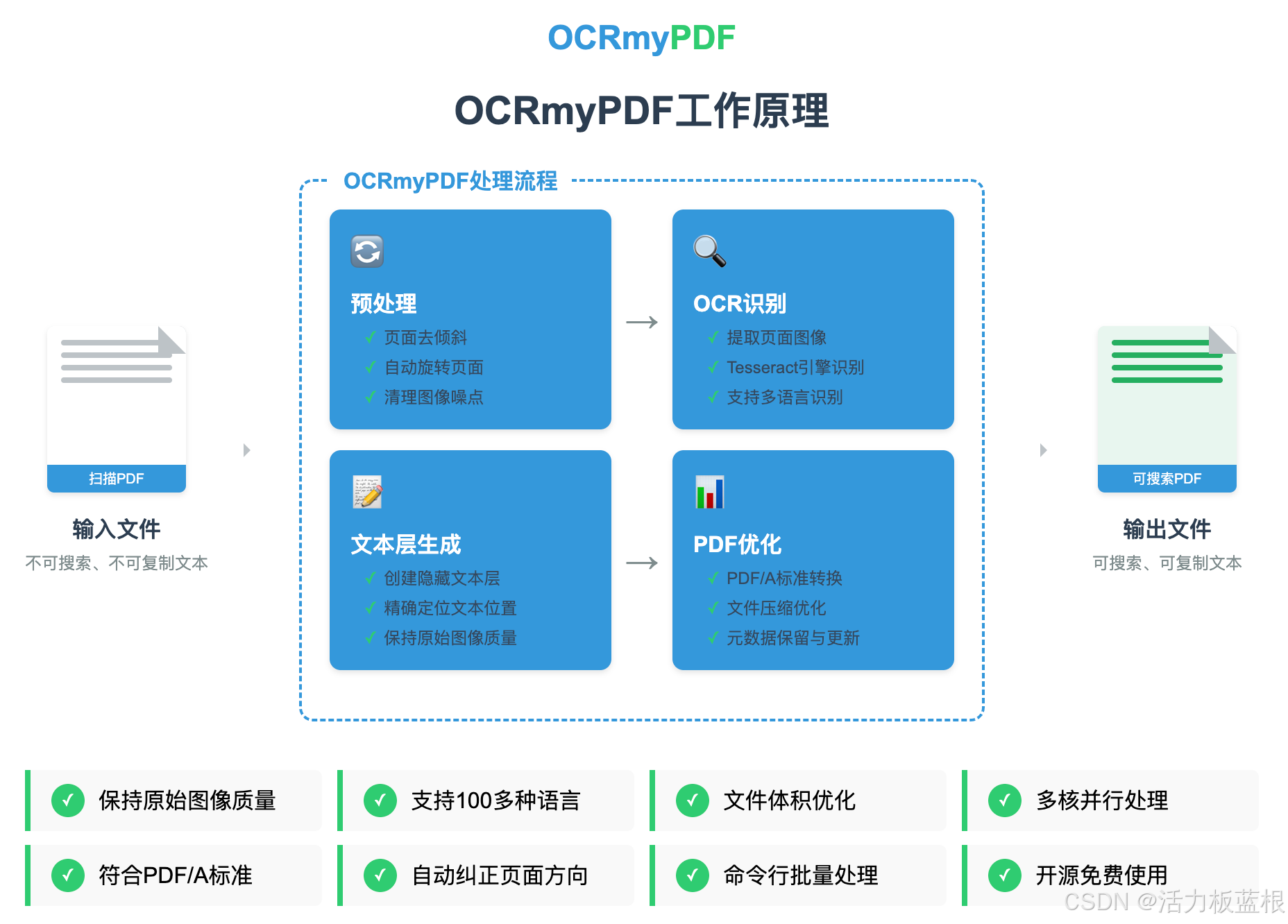
1. OCRmyPDF简介
OCRmyPDF是一个功能强大的开源命令行工具,它能够为扫描版PDF文件添加OCR(光学字符识别)文本层,使其变成可搜索、可复制文本的PDF文件。它的特点包括:
- 添加可搜索文本层:将不可搜索的PDF转换为可搜索的PDF/A文档
- 准确放置文本:OCR文本层准确放置在原图像下方,便于复制粘贴
- 保持原始分辨率:保持原始嵌入图像的精确分辨率
- 文件优化:通常生成比输入文件更小的文件
- 图像预处理:支持去倾斜、清理等预处理操作
- 多核处理:支持多核处理,提高处理速度
- 多语言支持:通过Tesseract OCR引擎支持100多种语言,包括中文
- 大文件处理:可以处理包含数千页的大型文件
2. 为什么选择OCRmyPDF?
目前市面上有很多PDF OCR工具,但OCRmyPDF有以下优势:
- 完全免费开源:不需要付费,没有功能限制
- 命令行操作:便于批量处理和自动化
- 高精度识别:基于Tesseract引擎,识别准确率高
- 多平台支持:支持Windows、macOS和Linux
- 活跃维护:项目活跃维护,不断更新
- 文件质量:输出符合PDF/A标准的高质量文档
3. 安装OCRmyPDF
下面我将详细介绍在不同系统上安装OCRmyPDF的方法,即使你是编程小白也能轻松上手!
3.1 macOS安装
方法一:使用Homebrew安装(推荐)
-
安装Homebrew
打开"终端"(可以通过Spotlight搜索"终端"或在应用程序/实用工具中找到),然后复制粘贴以下命令:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"按照提示输入密码(注意:输入密码时不会显示任何字符)
-
安装OCRmyPDF及其依赖
brew install ocrmypdf -
验证安装
ocrmypdf --version
方法二:使用Python的pip安装
如果你的Mac上已经安装了Python,也可以使用pip安装:
# 安装OCRmyPDF
pip install ocrmypdf
# 安装Tesseract OCR引擎
brew install tesseract
# 安装中文语言包
brew install tesseract-lang
3.2 Windows安装
方法一:使用Windows Subsystem for Linux (WSL)(推荐)
WSL允许你在Windows上运行Linux系统,这是最简单的安装方法。
-
安装WSL
以管理员身份打开PowerShell,输入以下命令:
wsl --install安装完成后重启电脑,会自动打开Ubuntu并设置用户名和密码。
-
在WSL中安装OCRmyPDF
sudo apt update sudo apt upgrade sudo apt install ocrmypdf -
安装中文语言包
sudo apt install tesseract-ocr-chi-sim -
验证安装
ocrmypdf --version -
如何在WSL中访问Windows文件
Windows文件位于
/mnt/c/目录下,例如访问桌面上的PDF:cd /mnt/c/Users/你的用户名/Desktop ocrmypdf input.pdf output.pdf
方法二:使用Docker
- 下载安装Docker Desktop for Windows
- 打开命令提示符,创建一个文件夹存放PDF文件:
mkdir C:\Users\你的用户名\Desktop\pdf_ocr cd C:\Users\你的用户名\Desktop\pdf_ocr - 使用Docker运行OCRmyPDF:
docker run --rm -i -v "%cd%:/tmp" jbarlow83/ocrmypdf --language chi_sim /tmp/input.pdf /tmp/output.pdf
3.3 Linux安装
Ubuntu/Debian
sudo apt update
sudo apt install ocrmypdf
sudo apt install tesseract-ocr-chi-sim # 安装中文支持
Fedora
sudo dnf install ocrmypdf
sudo dnf install tesseract-langpack-chi_sim # 安装中文支持
Arch Linux
sudo pacman -S ocrmypdf
sudo pacman -S tesseract-data-chi_sim # 安装中文支持
3.4 如何判断是否需要OCR?
在开始OCR之前,我们可以先判断PDF是否已经包含文本层:
-
使用PDF阅读器测试:打开PDF文件,尝试选择和复制文本。如果能够选择和复制文本,说明文档已经包含文本层。
-
使用pdfinfo工具:
pdfinfo 文档.pdf | grep "Text"如果显示"contains text",则表示文档已有文本层。
-
尝试搜索文本:在PDF阅读器中使用搜索功能(Ctrl+F),如果能搜到内容,则已有文本层。
3.5 安装常见问题
3.5.1 macOS上的常见问题
-
brew安装失败
Error: The following directories are not writable by your user解决方法:
sudo chown -R $(whoami) /usr/local/share /usr/local/lib -
Tesseract语言包下载慢
如果语言包下载速度慢,可以使用清华大学镜像:
# 临时使用 export HOMEBREW_BOTTLE_DOMAIN=https://mirrors.tuna.tsinghua.edu.cn/homebrew-bottles brew install tesseract-lang
3.5.2 Windows上的常见问题
-
WSL磁盘空间不足
WSL默认分配的磁盘空间有限,处理大型PDF可能会遇到空间不足的问题:
# 在PowerShell中查看WSL磁盘使用情况 wsl --system -d Ubuntu df -h # 优化WSL磁盘空间 wsl --shutdown Optimize-VHD -Path "C:\Users\用户名\AppData\Local\Packages\...Ubuntu...\LocalState\ext4.vhdx" -Mode Full -
WSL与Windows文件权限问题
如果遇到权限问题,可以在WSL的/etc/wsl.conf文件中添加:
[automount] options = "metadata,umask=22,fmask=11"然后重启WSL:
wsl --shutdown
4. 基本使用教程
安装完成后,让我们来学习如何使用OCRmyPDF处理PDF文件。
4.1 基本命令
最简单的使用方式是:
ocrmypdf 输入文件.pdf 输出文件.pdf
例如:
ocrmypdf scan.pdf searchable_scan.pdf
4.2 指定语言
OCRmyPDF默认使用英语识别,如果要处理中文文档,需要指定语言:
ocrmypdf -l chi_sim 中文文档.pdf 可搜索的中文文档.pdf
常用语言代码:
chi_sim:简体中文chi_tra:繁体中文eng:英语jpn:日语kor:韩语
如果文档包含多种语言,可以组合使用:
ocrmypdf -l chi_sim+eng 中英混合文档.pdf 输出文档.pdf
4.3 处理已有OCR的PDF
如果PDF已经包含文本(即已经做过OCR),OCRmyPDF会默认停止处理。可以使用以下选项处理这种情况:
-
跳过已有文本的页面:
ocrmypdf --skip-text input.pdf output.pdf -
强制重新OCR所有页面:
ocrmypdf --force-ocr input.pdf output.pdf -
改善现有OCR层:
ocrmypdf --redo-ocr input.pdf output.pdf
4.4 图像增强选项
OCRmyPDF提供多种图像增强选项,提高OCR质量:
# 自动旋转页面
ocrmypdf --rotate-pages input.pdf output.pdf
# 矫正倾斜页面
ocrmypdf --deskew input.pdf output.pdf
# 清理页面(去除噪点)
ocrmypdf --clean input.pdf output.pdf
# 清理并保留清理后的图像
ocrmypdf --clean-final input.pdf output.pdf
# 去除背景色
ocrmypdf --remove-background input.pdf output.pdf
你也可以组合使用这些选项:
ocrmypdf --deskew --clean --rotate-pages -l chi_sim input.pdf output.pdf
4.5 实际案例:一键处理文档
下面是一个处理中文文档的完整命令示例,包含了常用的增强选项:
ocrmypdf --deskew --clean --rotate-pages --redo-ocr -l chi_sim 原始扫描.pdf 可搜索文档.pdf
这个命令会:
- 矫正倾斜的页面
- 清理页面(去除噪点)
- 自动旋转页面(如果方向不正确)
- 使用中文识别引擎
- 如果已有OCR文本,则尝试改善它
4.6 实战案例解析
4.6.1 案例一:处理扫描版学术论文
假设我们有一篇扫描版的学术论文"paper.pdf",包含英文和数学公式:
ocrmypdf --deskew --clean --rotate-pages -l eng --pdf-renderer sandwich \
--optimize 2 --output-type pdfa paper.pdf paper_searchable.pdf
命令解析:
--deskew:矫正页面倾斜--clean:清理页面噪点--rotate-pages:自动旋转页面-l eng:使用英语识别--pdf-renderer sandwich:使用"sandwich"渲染器,适合处理有数学公式的文档--optimize 2:使用中等级别的优化--output-type pdfa:输出符合PDF/A标准的文档
4.6.2 案例二:处理中文古籍扫描件
对于质量较差的中文古籍扫描件:
ocrmypdf --deskew --clean-final --remove-background --oversample 600 \
--rotate-pages-threshold 5 -l chi_tra+chi_sim --redo-ocr \
--jpeg-quality 85 古籍扫描.pdf 古籍_可搜索.pdf
命令解析:
--clean-final:清理页面并保留清理后的图像--remove-background:去除背景色,提高对比度--oversample 600:增加图像分辨率到600dpi--rotate-pages-threshold 5:设置页面旋转的置信度阈值-l chi_tra+chi_sim:同时使用繁体和简体中文识别--jpeg-quality 85:设置较高的JPEG质量,保留更多细节
4.6.3 案例三:批量处理大量文档
假设我们有一个包含多个PDF文件的目录,需要批量处理:
#!/bin/bash
# 设置输出目录
mkdir -p processed_pdfs
# 遍历当前目录下的所有PDF文件
for pdf in *.pdf; do
echo "正在处理: $pdf"
# 获取文件名(不含扩展名)
filename=$(basename "$pdf" .pdf)
# 处理PDF文件
ocrmypdf --deskew --clean --rotate-pages --skip-text \
-l chi_sim+eng --output-type pdfa \
"$pdf" "processed_pdfs/${filename}_OCR.pdf"
# 检查处理是否成功
if [ $? -eq 0 ]; then
echo "✓ 成功处理: $pdf"
else
echo "✗ 处理失败: $pdf"
fi
done
echo "批量处理完成!"
将上述脚本保存为batch_ocr.sh,然后执行:
chmod +x batch_ocr.sh
./batch_ocr.sh
5. 高级功能
5.1 PDF优化
OCRmyPDF提供多级优化选项,可以控制输出文件大小:
# 0 - 不进行优化
ocrmypdf -O 0 input.pdf output.pdf
# 1 - 安全无损优化(默认)
ocrmypdf -O 1 input.pdf output.pdf
# 2 - 有损JPEG和JPEG2000优化
ocrmypdf -O 2 input.pdf output.pdf
# 3 - 更激进的有损优化
ocrmypdf -O 3 input.pdf output.pdf
还可以具体控制图像压缩:
# 设置JPEG质量(1-100,值越低文件越小,质量越差)
ocrmypdf --jpeg-quality 75 input.pdf output.pdf
# 启用JBIG2有损模式(更好的压缩)
ocrmypdf --jbig2-lossy input.pdf output.pdf
5.2 处理特定页面
如果只想处理文档中的特定页面:
# 只处理第1-5页、第10页和第15-20页
ocrmypdf --pages 1-5,10,15-20 input.pdf output.pdf
5.3 生成文本侧档
如果需要单独提取OCR识别的文本:
ocrmypdf --sidecar extracted_text.txt input.pdf output.pdf
5.4 设置PDF元数据
ocrmypdf --title "文档标题" --author "作者名" --subject "主题" --keywords "关键词1,关键词2" input.pdf output.pdf
5.5 批量处理
在Linux或macOS中,可以使用以下脚本批量处理一个文件夹中的所有PDF:
#!/bin/bash
for file in *.pdf; do
echo "处理文件: $file"
ocrmypdf -l chi_sim --deskew --clean "$file" "OCR_$file"
done
在Windows中,可以创建一个批处理文件(.bat):
@echo off
for %%i in (*.pdf) do (
echo 处理文件: %%i
ocrmypdf -l chi_sim --deskew --clean "%%i" "OCR_%%i"
)
5.6 进阶技巧
5.6.1 OCR指定区域
有时我们只想对PDF中的特定区域进行OCR,可以结合其他工具:
-
先使用
pdftoppm转换PDF为图像:pdftoppm -png -r 300 input.pdf page -
使用图像处理工具裁剪需要OCR的区域
-
对裁剪后的图像进行OCR,生成文本文件:
tesseract cropped.png output -l chi_sim -
使用
pdftotext提取原PDF的文本框架pdftotext -layout input.pdf layout.txt -
使用文本编辑器合并OCR文本和原文本框架
-
使用工具将合并后的文本嵌入PDF
5.6.2 使用自定义Tesseract配置
OCRmyPDF允许传递自定义配置给Tesseract,以提高特定场景下的识别率。
创建一个名为custom.cfg的文件:
tessedit_char_whitelist 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ
然后使用此配置运行OCRmyPDF:
ocrmypdf --tesseract-config custom.cfg input.pdf output.pdf
这对于只包含特定字符的文档(如数字表格、财务报表等)非常有用。
5.6.3 监视文件夹自动处理
可以创建一个脚本,自动监视某个文件夹并处理新添加的PDF文件:
#!/bin/bash
watch_dir="$HOME/待处理"
output_dir="$HOME/已处理"
mkdir -p "$output_dir"
inotifywait -m -e create -e moved_to "$watch_dir" |
while read path action file; do
if [[ "$file" =~ \.pdf$ ]]; then
echo "检测到新文件: $file"
ocrmypdf --deskew --clean -l chi_sim "$watch_dir/$file" "$output_dir/$file"
echo "处理完成: $file"
fi
done
使用前需安装inotify-tools:
sudo apt install inotify-tools # Ubuntu/Debian
6. 常见问题排查
6.1 找不到Tesseract
错误信息:
The program 'tesseract' could not be executed or was not found on your system PATH.
解决方法:
- 确保已安装Tesseract OCR引擎
- 检查系统PATH变量是否包含Tesseract安装路径
6.2 文件已有文本
错误信息:
PriorOcrFoundError: page already has text! - aborting
解决方法:
- 使用
--force-ocr强制重新OCR - 使用
--redo-ocr改善现有OCR层 - 使用
--skip-text跳过已有文本的页面
6.3 语言数据包缺失
错误信息:
Error: Invalid language 'chi_sim'
解决方法:
# Ubuntu/Debian
sudo apt-get install tesseract-ocr-chi-sim
# macOS
brew install tesseract-lang
# Fedora
sudo dnf install tesseract-langpack-chi_sim
# Arch Linux
sudo pacman -S tesseract-data-chi_sim
6.4 内存不足
对于大型PDF文件,OCR处理可能会消耗大量内存。如果遇到内存不足的问题:
# 减少并行作业数量(默认使用所有CPU核心)
ocrmypdf -j 2 input.pdf output.pdf
# 跳过特别大的页面
ocrmypdf --skip-big 20 input.pdf output.pdf
7. 最佳实践
-
提高OCR质量
- 总是使用
--deskew选项矫正倾斜页面 - 对于有噪点的扫描文档,使用
--clean选项 - 确保选择正确的语言
- 对于低质量扫描,使用
--oversample 600提高分辨率
- 总是使用
-
减小文件大小
- 对于主要是文本的文档,使用
-O 2或-O 3 - 对于带有图像的彩色文档,使用
--jpeg-quality 75 - 启用
--jbig2-lossy可获得更小的文件(但注意可能影响某些文字的质量)
- 对于主要是文本的文档,使用
-
批量处理大量文件
- 编写自动化脚本
- 考虑使用并行处理,但注意内存使用
- 对于超大PDF,先拆分成小文件,处理后再合并
-
保存常用命令
- 将常用命令保存为脚本或别名,方便重复使用
8. 实际应用场景
OCRmyPDF适用于多种场景:
- 学术研究:处理扫描版论文,使其变得可搜索,提高研究效率
- 文档归档:将纸质文档数字化并存档,支持全文搜索
- 电子书优化:优化扫描版电子书,便于阅读和检索
- 企业文档管理:提高文档管理系统的搜索能力
- 古籍数字化:将古籍扫描件转换为可搜索的数字资源
9. 总结
OCRmyPDF是一款功能强大、操作简单的PDF OCR工具,它能够帮助我们将扫描版PDF转换为可搜索、可复制文本的PDF文件,大大提升了PDF文档的使用体验。
虽然它是一个命令行工具,但通过本文的详细教程,相信大家已经掌握了基本使用方法。对于经常需要处理PDF文档的人来说,OCRmyPDF绝对是一个必备的工具。
如果你觉得这篇文章对你有帮助,请点赞、收藏并关注我,我会继续分享更多实用的技术工具和教程!
参考资料

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)